
CLAUDE.md 爆火背后:AI 协同编程的底层逻辑
摘要:Andrej Karpathy 吐槽 AI 编程痛点并由社区提炼出 CLAUDE.md 规则库,在 GitHub 狂揽 16 万 Star。本文深入拆解其背后的 4 大核心原则,探讨如何通过精细化“行为约束”治好 AI 的自作聪明。
在当下的 AI 辅助编程浪潮中,开发者们正频繁遭遇一种隐性的效率陷阱:要求 AI 修复简单的格式问题,它却过度延伸,重写了整个文件;寄希望于其快速实现一个数据导出功能,它却顺手设计出一整套复杂的抽象接口。这些看似全能的 AI 助手,在实际研发链路中往往扮演着一个“过度自信的初级工程师”角色。这种盲目的代码增量,不仅未能转化为实际生产力,反而大幅抬高了代码审查(Code Review)的边际成本。
2026 年 1 月,OpenAI 联合创始人、前特斯拉 AI 负责人 Andrej Karpathy 在社交媒体上发表了一篇长文,痛陈大语言模型在编程时的各种坏毛病。随后,有开发者将这些槽点转化为了一份不到 70 行的规则文件:CLAUDE.md。令人惊叹的是,这个几乎没有代码的纯文本项目在短短几个月内斩获超过 16 万个 Star,迅速冲上 GitHub Trending 榜单。
为什么在百亿参数模型横行的今天,一个不到 70 行的 Markdown 文本文件能产生如此惊人的效果?它又是如何精准切中 AI 编程的致命痛点的?
痛点观察:AI 编程的三大顽疾
在这份文件的背后,实际上直接承载了 Andrej Karpathy 在日常 AI 协同编程实践中总结出的深刻槽点。我们往往以为 AI 写不好代码是因为“智商不够”,而 Karpathy 的观察却直指其在行为逻辑上的三大顽疾,并分点揭示了这些常态化的“翻车现场”:
1. 隐性假设与沟通缺失
大模型在接收到模糊指令时,极少会主动停下来理清疑惑。相反,它们非常擅长自作主张,替开发者做出不合理的底层假设。它们不管理自己的混乱,不寻求澄清,不暴露矛盾,甚至在逻辑不通时也从不主动推敲或拒绝(Push Back)。这种单向的“盲目狂奔”,使得最终生成的代码方向往往与真实的工程意图大相径庭。
2. 过度复杂化
AI 程序员天具备一种对“过度设计”的迷恋。Karpathy 吐槽道,它们极度喜欢把原本极其简单的单次调用或辅助工具复杂化,盲目增加设计模式、冗余抽象层和单次使用下的泛型设计。它们宁可构建一个包含 1000 行庞大架构的复杂逻辑,也想不起用最简单、直白的 100 行轻量代码来精简解决,且写完后从不主动清理死代码(Dead Code)。
3. 擅自改动无关代码
在修改某段特定功能时,大模型经常会犯一些让人啼笑皆非的“顺带修改”错误。比如它们在未能充分理解原有逻辑的前提下,会作为副作用强行改动、甚至删去邻近无关区域的注释和代码。更糟糕的是,它们常会在无关代码行里“顺手”重写一遍不属于本次任务的格式与缩进,导致在进行版本合并(Git Diff)时出现大量的邻近行污染。
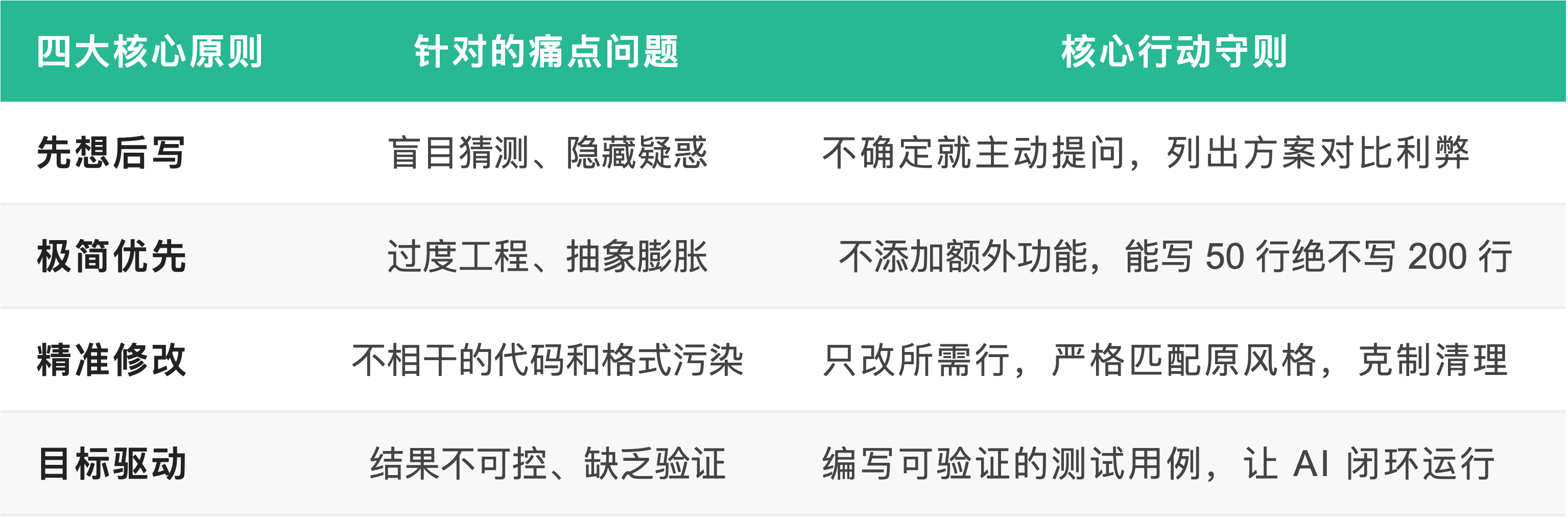
规则拆解:CLAUDE.md 的四大原则
爆火的 CLAUDE.md 之所以见效极快,是因为它直接针对 Karpathy 总结的痛点,精炼出了 4 条直击要害的行为准则。
1. 先想后写(Think Before Coding)
该原则强制要求 AI 在动手前理清思路,拒绝盲目奔跑。面对不确定的需求,AI 被禁止凭空猜测,必须主动提问。若存在多种可行的实现方案,AI 需要主动列出方案的权衡利弊(Trade-offs)并交给开发者来做选择,遇到疑惑时必须立刻停下澄清。
2. 极简优先(Simplicity First)
针对大模型盲目追求架构完美的毛病,这条守则给出了严厉的限制:绝不增加未被要求的额外特性。严禁为单次使用的代码做过度抽象;严禁编写没有明确要求的多余配置项。如果 50 行代码能完美解决问题,绝对不要写成 200 行。它的衡量标准非常简单:如果一个资深架构师看到这段代码觉得繁琐,那它就必须被精简。
3. 精准外科手术式修改(Surgical Changes)
这是一项对 Diff 污染的极限防御:AI 只能触碰解决问题所必须的代码行。不得顺便优化邻近的代码格式、多余注释或重构不相关的逻辑。AI 的改动风格必须与现有代码库保持完全一致,即使它自己觉得旧风格并不完美。它只负责清理自己带来的负面产物(如未被使用的导入或变量),绝不主动清理旧代码库自带的历史遗留死代码。
4. 目标驱动执行(Goal-Driven Execution)
这一原则深刻挖掘了大模型“擅长在循环中迭代直到通过特定校验”的特性。它要求将原本模糊的、指令式的任务,转化为明确的、可验证的声明式目标。例如,不要对 AI 说“写个验证邮箱的函数”,而是要说“先针对邮箱验证的边界场景写出 5 个测试用例,然后不断运行和修复代码直到这些测试全部通过”。强大的测试环路比人类的口头要求更能帮助 AI 稳定发挥。
底层逻辑:“行为约束”为何更有效
随着大模型步入深水区,行业正陷入一个思维盲区——将 AI 辅助编程的所有翻车现场简单归咎于模型推理能力不足。然而,CLAUDE.md 的爆火向我们揭示了另一个截然不同的真相:当前 AI 协同工具的最大瓶颈往往不是模型的能力极限,而是其失控的执行行为。
从本质上讲,大模型的设计逻辑是“以概率输出生成最流畅、最符合技术完美的代码”。但是在软件工程的实际协作中,这反而成了缺点。人类项目的代码库是一套处于微妙平衡中的有机体。比起生成 10 个新的完美架构,代码库往往更需要最少的代码变动和最严格的风格契合。
通过在项目根目录放置一个 CLAUDE.md 文件,AI 编程工具在启动或执行任何指令之前,都必须被强制加载并解析这份规则。这就相当于在 AI 执行的上下文顶层强制安装了一个行为过滤器。它不需要复杂的框架配合,直接以极低的系统开销将一个浮躁、爱炫技的 AI 对话助手,驯化为一个谨慎、干练、严守纪律的一线资深工程师。
写在最后
CLAUDE.md 的现象级爆火给所有的 AI 开发者上了极为重要的一课。在底层大模型智力演进趋缓、而日常开发节奏高度依赖 AI 辅助的当下,如何通过极简的行为约束(Actions Constraint)和明确的可测试环路,将模型从不受限的代码拼图机器,引导为能完美适配人类既有系统的高级工程师,是实现高效协同的关键。
未来,随着研发团队对代码品质和维护成本要求的提升,在项目根目录下放置类似 CLAUDE.md 风格的行为规约文件,可能会成为一种常态化的工程实践。如何有效建立起人机协同的日常行为规范,也正在成为研发团队提升长期交付品质的一个务实选择。
相关资源

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)