
Claude Opus 4.8:AI 开始卷“可靠性”
Claude Opus 4.8 发布,价格未变,却在 Agent 能力、效率与诚实性上明显升级。比起更强,一个更值得关注的变化是:AI 开始变得更可靠。
距离 Opus 4.7 发布只过了 41 天,Anthropic 又推出了 Claude Opus 4.8 。

价格一分没涨,标准模式依然是每百万输入 5 美元、输出 25 美元。

单看名字,你可能会觉得这是一次常规的小版本更新,但仔细看官方数据,无论是编程、人类最后考试(HLE),还是在智能体、计算机使用任务中,Opus 4.8几乎无可匹敌。
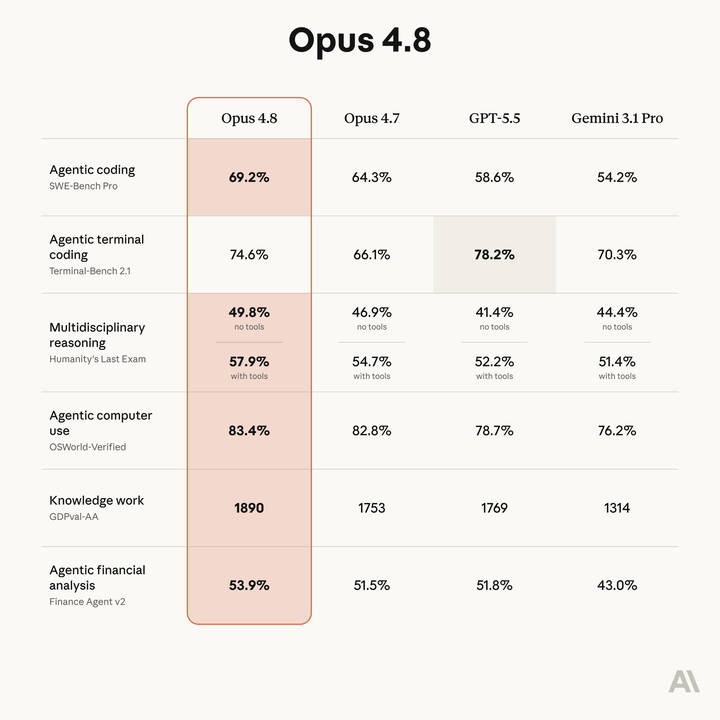
这次 Anthropic 的重点有点不一样,它反复强调的是长任务执行、复杂推理、工具调用稳定性,以及更低的错误率。简单理解就是它想解决的不是“会不会做”,而是“能不能持续做、稳定做、少翻车”。
在衡量真实世界 Agent 能力的硬核榜单 GDPval-AA 上,Claude Opus 4.8 拿下了 1890 Elo,直接断层第一。相比 Opus 4.7 提高了 137 分,也比 GPT-5.5 高出 121 分。按照榜单换算的胜率,面对同类任务,赢面接近 67%。
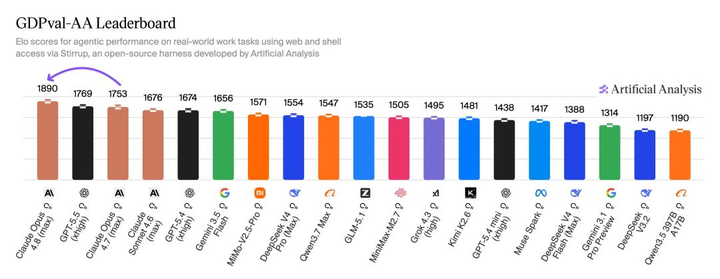
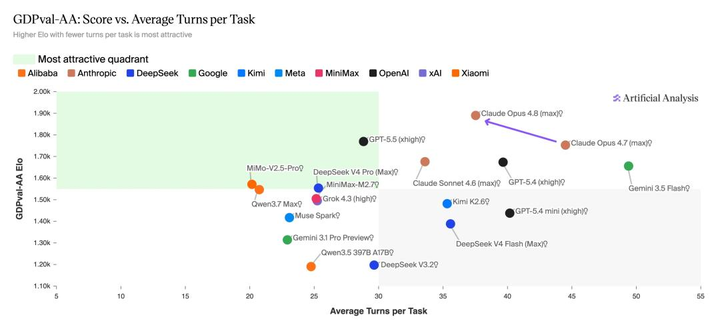
但我觉得,这次最值得关注的其实不是第一名,而是 Anthropic 在另一个指标上的变化——“Honesty(诚实性)”。
过去很多模型真正让人头疼的问题,不是不会,而是“装会”。代码有问题不提醒、数据逻辑不完整却一本正经输出,甚至明明上下文缺失,也能给你一种“事情已经做完”的错觉。这也是为什么很多开发者觉得 AI 写代码效率高,但又不敢完全托管。
而 Opus 4.8 这次明显在解决这个问题。
另外,官方公开了一项很有意思的数据:在“明明代码有缺陷却不提醒”的测试里,Opus 4.5 的问题率是 0.40,Opus 4.7 降到了 0.25,而 Opus 4.8 是 0.00。
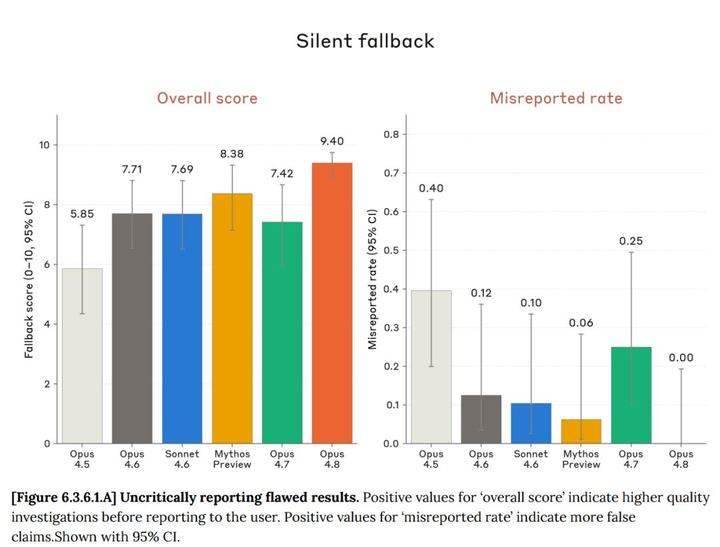
没看错,没有小数点后面的零头,就是 0。
与此同时,完成同样任务时,Opus 4.8 需要的步骤更少、输出 token 更低。官方数据显示,相比 Opus 4.7,它平均少用了约 15% 的步骤,输出 token 降低约 35%。这意味着它不仅更强,还更省。
X 上不少开发者的评价也很有意思。很多人的共同感受并不是“它突然变成了神”,而是“更像一个靠谱同事了”——更愿意承认不知道、更会主动停下来确认上下文,也更少出现一本正经瞎写的情况。

当然也有持有不同意见的网友
今天的大模型,尤其在 Coding Agent 场景里,能力差距已经不像去年那样巨大。真正决定体验的,越来越像一个高级同事的工作方式:会不会自查、会不会主动暴露问题、会不会在关键节点停下来确认,而不是一路硬着头皮把错误做完。
如果这个方向成立,那么未来模型竞争比拼的,也许不只是 benchmark,而是谁更值得被长期托付复杂任务。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)