
LangChain 刚刚发布了 Deep Agents —— 它改变了你构建 AI 系统的方式
大多数人仍在 LangGraph 中手动构建代理循环。Deep Agents 提供了一个更高级的解决方案 —— 它比你预期的更有指导性。
大多数人仍在 LangGraph 中手动构建代理循环。Deep Agents 提供了一个更高级的解决方案 —— 它比你预期的更有指导性。
1.1 Deep Agents 的实际应用
我注意到几乎每个认真构建代理的团队都会重复一个模式。
首先,他们尝试 LangChain 的 chains(链)。对于简单的流水线,这种方式效果不错。但任务变得复杂时 —— 需要调用工具、需要循环、需要处理可变长度的输出 —— chains 就不够用了。于是他们转向 LangGraph,突然间,他们在真正处理问题之前,就已经开始编写状态 schema、条件边以及图编译逻辑。
并不是说 LangGraph 不好,它非常强大。但它只是一个运行时 —— 一个低级原语 —— 大多数人却把它当作应用框架来使用。LangChain 注意到了这一点,而 Deep Agents 就是他们的解决方案。
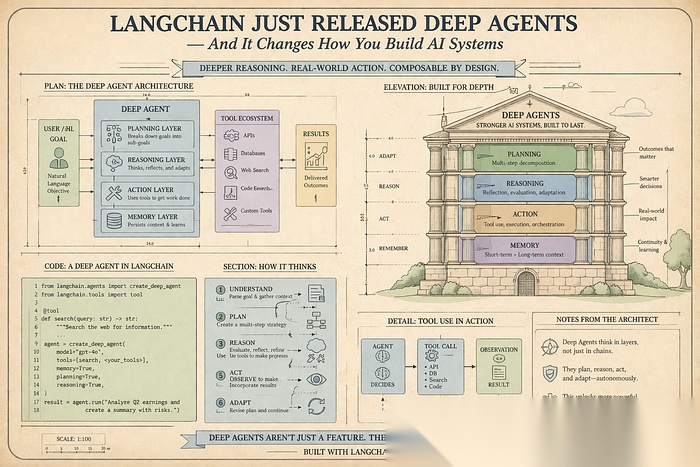
Deep Agents 究竟是什么
让我具体说明一下,因为“deep agents”听起来可能指任何东西。
Deep Agents 是一个独立的 Python 库 —— 可以通过 pip install deepagents 安装 —— 它构建在 LangChain 和 LangGraph 之上。LangChain 文档将其描述为“代理框架(agent harness)”:它提供了与其他框架相同的核心工具调用循环,但内置了一系列功能,让你无需重新发明轮子。
核心函数是 create_deep_agent()。最简单的形式如下:
from deepagents import create_deep_agent
def get_weather(city: str)-> str:
"""Get weather for a given city."""
return f"It's always sunny in {city}!"
agent = create_deep_agent(
tools=[get_weather],
system_prompt="You are a helpful assistant",
)
agent.invoke(
{"messages":[{"role":"user","content":"What is the weather in Mumbai?"}]}
)
就这么简单。仅仅一个函数。在底层,这个库处理了 LangGraph 图、状态管理、流式传输以及上下文窗口管理 —— 所有这些你都无需手动操作。
但真正值得关注的是,库默认内置了哪些功能。
让 Deep Agents 与众不同的五大能力
1. 内置规划
每个 deep agent 自动拥有 write_todos 工具。当面对复杂任务时,代理会使用它将工作拆分为离散步骤,跟踪其状态(待处理、进行中、已完成),并在任务发展过程中动态调整计划。
这很重要,因为这不仅仅是一个提示技巧 —— 待办事项会保存在代理状态中。代理可以随时回到它,更新它,并在整个会话周期中参考它。你无需手动提示模型“逐步思考”,这个结构已经内置在框架中。
2. 虚拟文件系统
这是最让我惊讶的功能。Deep agents 默认带有一套文件系统工具:ls、read_file、write_file、edit_file、glob 和 grep。
为什么代理需要文件系统?为了上下文管理。
大型语言模型(LLM)的上下文窗口是有限的。当代理执行长时间的研究任务、运行代码或处理大量工具输出时,对话历史可能迅速膨胀。Deep agents 通过将大内容卸载到虚拟文件系统来解决这个问题,而不是把所有内容都保存在上下文窗口中。
当工具结果超过 20,000 个 token 时,库会自动将其保存到配置的后端,并在上下文中用文件路径引用和 10 行预览替代。代理在真正需要内容时可以使用 read_file 或 grep 来读取该文件。这是一种智能上下文压缩 —— 不是分块,也不是截断,而是有目的的卸载,并按需检索。
文件系统的后端可以是内存状态(默认)、本地磁盘、LangGraph Store(用于跨线程持久化)或沙箱环境如 Modal 或 Daytona。后端是可插拔的。
3. 子代理生成
框架内置了一个任务工具,让主代理可以为独立子任务生成专门的子代理。
这比听起来重要得多。在一个长时间的研究任务中,如果单个代理处理所有事情,它的上下文会被中间步骤、搜索结果和部分输出填满。子代理优雅地解决了这个问题:主代理将特定子任务委派给一个全新的代理实例,该实例拥有自己的干净上下文。子代理自主运行,完成工作,并将一个总结结果返回给主代理。主代理的上下文保持干净。
你可以为子代理配置自定义工具和系统提示:
from deepagents import create_deep_agent,Subagent
code_reviewer =Subagent(
name="code-reviewer",
system_prompt="You are an expert code reviewer. Analyze code for bugs, style, and performance.",
tools=[read_file_tool],
)
agent = create_deep_agent(
tools=[internet_search],
subagents=[code_reviewer],
system_prompt="You are a research and engineering assistant.",
)
默认子代理 —— 一个带有文件系统工具的通用子代理 —— 始终可用,无需额外配置。
4. 自动上下文压缩与摘要
这是该库在长时间运行任务中真正体现价值的地方。
当代理的上下文达到模型上下文窗口限制的 85%,且无法再将内容卸载到文件系统时,框架会触发自动摘要。LLM 会生成一个结构化摘要,涵盖发生的所有内容 —— 会话意图、创建的成果、下一步计划 —— 并用该摘要替代工作内存中的完整对话历史。原始消息会保存到文件系统中作为规范记录,这样代理在需要时可以恢复特定细节。
这样一来,deep agents 就可以在复杂任务上无限期运行而不会触碰上下文限制 —— 这是使用原始 LangGraph 手动实现的复杂工程。
5. 跨会话的长期记忆
默认情况下,代理状态只存在于单线程中。但当你配置 CompositeBackend 并使用 LangGraph Store 时,代理可以在会话和线程之间持久化记忆。
存储在 /memories/ 路径(或你配置的其他位置)的文件可以在代理重启后继续存在,并可从任何会话线程访问。这就是构建一个能够记住你的偏好、代码规范或多日研究项目进展的代理的方式。
from deepagents import create_deep_agent
from deepagents.backends importCompositeBackend,StateBackend,StoreBackend
from langgraph.store.memory importInMemoryStore
store =InMemoryStore()
backend =CompositeBackend(
routes={"/memories/":StoreBackend(store=store)},
default=StateBackend(),
)
agent = create_deep_agent(
tools=[...],
backend=backend,
memory=["path/to/AGENTS.md"],# persistent context file
)
它在 LangChain 生态系统中的定位
这一点容易让人混淆,所以值得明确说明。
•LangChain 提供构建模块:模型、工具、提示、链条。它是基础层。•LangGraph 是用于持久化、有状态、基于图的代理执行的运行时。它处理持久化、流式传输、中断和复杂条件流程。它是引擎。•Deep Agents 是建立在两者之上的框架。它不是 LangGraph 的替代品 —— 底层一切仍依赖 LangGraph。它提供的是一个更高级的 API 和有指导性的默认设置,因此你无需每次从零构建规划器、文件系统层、上下文压缩和子代理基础设施。
可以这样理解:LangGraph 给你一个引擎和传动装置,Deep Agents 给你一辆车。
对于简单代理,LangChain 的 create_agent 可能就足够了。但对于复杂、长时间运行、需要多步操作且上下文要求大的任务,这正是 Deep Agents 发挥其抽象价值的地方。
构建一个研究代理:快速入门示例
下面是一个实际示例 —— 一个可以搜索网络并生成结构化报告的研究代理:
import os
from typing importLiteral
from tavily importTavilyClient
from deepagents import create_deep_agent
tavily_client =TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
def internet_search(
query: str,
max_results:int=5,
topic:Literal["general","news","finance"]="general",
include_raw_content:bool=False,
):
"""Run a web search and return results."""
return tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
research_instructions ="""You are an expert researcher.
Your job is to conduct thorough research andthen write a polished report.
Use internet_search to gather information.
Write your findings to files as you go to avoid losing context.
Use write_todos to plan your research steps before starting.
"""
agent = create_deep_agent(
model="anthropic:claude-sonnet-4-6",# default model
tools=[internet_search],
system_prompt=research_instructions,
)
result = agent.invoke({
"messages":[{
"role":"user",
"content":"Research the current state of agentic AI frameworks in 2025 and write a structured report."
}]
})
print(result["messages"][-1].content)
运行该代理会发生什么:
1.代理调用 write_todos 来规划研究步骤。2.代理执行搜索,并自动将大型结果卸载到虚拟文件系统。3.如果任务复杂,它会生成子代理来处理特定部分。4.代理根据需要读取相关文件,并综合生成最终报告。5.在整个过程中,框架会管理上下文,使模型永远不会达到上下文窗口限制。
你无需编写这些基础设施 —— 这一切都是框架自带的。
Deep Agents 命令行工具(CLI)
还有一点值得注意:Deep Agents 还提供了基于同一 SDK 的命令行代理。
pip install deepagents
deepagents # 启动交互式 CLI 代理
这是一个可以在终端运行的编程代理 —— 可以把它想象成 Claude Code 或 Aider,但它基于 Deep Agents SDK 构建。它支持交互模式、非交互式管道模式(使用 -n 标志进行脚本化)、自定义技能以及持久化记忆。你可以教它你的项目规范,它会在多个会话中记住这些内容。
这意味着,同一个 SDK 不仅能驱动你的生产级研究代理,还能开箱即用地变成一个可用的开发者工具。
何时应使用(以及不应使用)Deep Agents
适合使用 eepagents的情况:
•你的任务需要规划并分多个步骤完成•工具结果很大,需要在长时间会话中管理•你希望使用子代理委派,而无需自己搭建基础设施•你需要跨会话线程的持久化记忆•你正在构建编程代理或自主研究系统
适合使用 LangChain 的 create_agent 或原生 LangGraph 的情况:
•你的代理很简单:仅调用一两个工具,响应较短•你需要对图拓扑进行非常细粒度的控制•你已经深入使用自定义 LangGraph 工作流,不希望使用有指导性的默认设置
该库在文档中也明确指出:对于简单代理,应使用更简单的工具。
为什么这比另一个框架发布更重要
这里有一点值得注意的时机背景。
Agentic AI 正处于一个拐点。基本模式 —— 工具调用、ReAct 循环、简单 RAG —— 已经被充分理解。行业目前正在探索的是如何让代理在长周期任务中可靠运行:需要规划、大量上下文、持久化和任务委派的任务。
每个构建生产级代理的团队都必须从零开始设计这些问题的解决方案。上下文管理策略、子代理模式、记忆架构 —— 这些在各组织中总是以略微不同的形式被不断重新发明。
deepagents 是 LangChain 的一次押注:认为这些解决方案足够普遍,可以被标准化。代理框架的概念 —— 有指导性的默认设置、内置基础设施、可插拔后端 —— 是试图将讨论从“我们如何构建底层管道?”转向“我们真正希望代理做什么?”
它是否成功取决于默认设置在生产环境中的表现。但作为设计方向,这是正确的选择。
入门指南
安装依赖:
pip install deepagents tavily-python
设置你的 API 密钥:
export ANTHROPIC_API_KEY="your-key"
export TAVILY_API_KEY="your-key"
export LANGSMITH_TRACING=true# 可选,用于调试
export LANGSMITH_API_KEY="your-key"
完整文档 —— 包括后端、子代理、沙箱环境、人类在环流程以及 CLI —— 可查阅 ocs.langchain.com/oss/python/deepagents[1]
如果你现在正在使用代理构建任何重要项目,花一个下午了解 deepagents 在你的技术栈中的定位是值得的 —— 即使你不打算立即使用它。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 6
6 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)