
LangChain 和 LlamaIndex 到底怎么选
做 LLM 应用时,很多人都会卡在一个问题上:LangChain 和 LlamaIndex 看起来都很强,但真正写项目时,到底该用哪个?
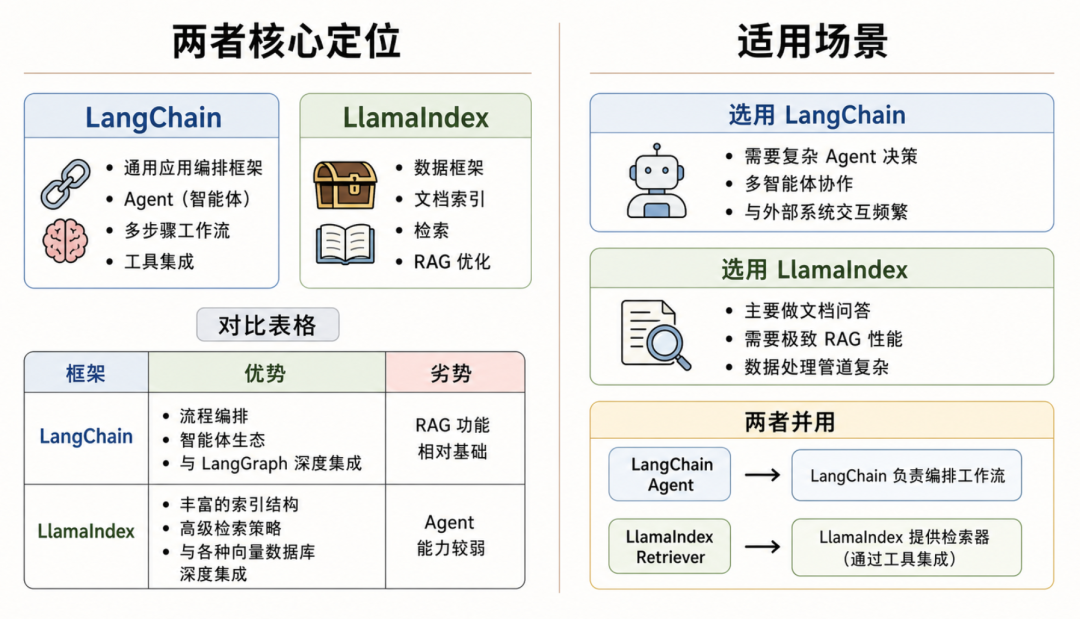
LangChain 更擅长 Agent、工作流编排和工具调用,适合把复杂任务一步步组织起来;LlamaIndex 更擅长文档索引、知识库检索和 RAG 优化,适合让模型更准确地“查资料”。两者不是简单的替代关系,而是各有分工。
这篇文章会用一条清晰的主线,把 LangChain 和 LlamaIndex 的核心定位、优势短板、适用场景讲明白,并通过一个实战例子演示:如何在 LangChain Agent 中接入 LlamaIndex 检索器。看完之后,你就能判断:什么场景该选 LangChain,什么场景该选 LlamaIndex,什么时候应该把两者组合起来使用。
一、先搞清楚:两者不是同一种框架
LangChain 和 LlamaIndex 经常被放在一起比较,但它们解决的问题并不完全相同。简单说,LangChain 更像“应用编排框架”,负责把模型、工具、记忆、Agent 和多步骤流程组织起来;LlamaIndex 更像“数据与检索框架”,负责把文档、索引、向量库和查询策略组织起来。
如果把一个 AI 应用看成一家公司,LangChain 更像项目经理:决定任务怎么流转、下一步调用哪个工具、多个 Agent 如何协作。LlamaIndex 更像资料管理员:把资料整理成可检索的结构,并在用户提问时快速找出最相关的内容。
二、LangChain:适合把复杂任务编排起来
LangChain 的强项不是单纯“查资料”,而是把一个任务拆成多个环节,并让模型在不同工具之间做选择。比如一个 Agent 既要查询数据库,又要调用搜索接口,还要根据结果继续追问或生成报告,这类场景就很适合 LangChain。
它的核心优势可以概括为四点:
-
通用应用编排:可以把模型、提示词、工具、记忆、输出解析等组件组合起来。
-
Agent 能力:适合让模型根据任务目标决定调用哪个工具、执行哪一步。
-
多步骤工作流:可以承载更复杂的业务流程,尤其适合需要反复判断和流转的任务。
-
工具生态丰富:更容易和外部系统、API、数据库、搜索服务等结合。
当然,LangChain 在 RAG 方向并不是没有能力,但如果你的核心目标是把大量文档处理成高质量知识库,并持续优化检索效果,单靠 LangChain 往往会显得偏基础。
三、LlamaIndex:适合把文档和知识库检索做好
LlamaIndex 的优势集中在数据层。它关心的是:文档怎么读取、怎么切分、怎么建立索引、怎么接入向量数据库、怎么用更好的检索策略把相关内容找出来。
所以,当项目主要围绕“文档问答”“知识库检索”“RAG 优化”展开时,LlamaIndex 会更顺手。它提供了更丰富的索引结构和更细的检索控制,适合对召回质量、数据管道和检索性能有要求的场景。
它的短板也比较明确:如果任务需要复杂 Agent 决策、多智能体协作,或者频繁和外部系统交互,LlamaIndex 自身的编排能力就不如 LangChain 灵活。
四、怎么选:看你的应用主线是什么
选型时不要只问“哪个框架更强”,而要先问“这个项目最核心的问题是什么”。如果核心问题是任务如何流转,优先考虑 LangChain;如果核心问题是资料如何被准确检索,优先考虑 LlamaIndex。

组合使用时,最自然的分工是:
LangChain Agent 负责理解用户目标、决定是否调用工具;
LlamaIndex Retriever 负责从文档库中找出相关内容。这样既保留了 Agent 的灵活性,也能让 RAG 检索质量更稳定。
五、实战:在 LangChain Agent 中使用 LlamaIndex 检索器
下面的例子会把 LlamaIndex 构建出来的文档检索器包装成 LangChain 工具,再交给 LangChain Agent 使用。这样用户问问题时,Agent 可以主动调用这个工具,从本地文档中检索相关信息。
1. 安装依赖
先安装 LlamaIndex 以及和 LangChain、DashScope Embedding 相关的依赖:
pip install llama-index llama-index-embeddings-langchain llama-index-embeddings-dashscope2. 准备本地文档
在项目根目录创建一个 data 文件夹,并在里面创建 langchain_intro.txt。示例内容如下:
LangChain 是一个用于构建 LLM 应用的框架。核心优势模块化设计,易于组合丰富的工具生态系统支持多种 LLM 提供商内置 Agent 框架强大的链式调用能力LangChain 适合需要灵活编排多个组件的复杂应用场景。
这份文档很短,但已经足够演示完整流程:读取文档、生成向量索引、创建检索器、封装为工具、交给 Agent 调用。
3. 构建 LlamaIndex 检索器
第一段代码负责读取 data 目录下的文档,并使用 DashScope 的 text-embedding-v3 模型构建向量索引。这里的关键对象是 VectorStoreIndex,它会把文档转成可检索的向量结构;as_retriever 则把索引转换成检索器。
import os
from langchain.agents import create_agent
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.core.base.embeddings.base import similarity
if not os.getenv("DASHSCOPE_API_KEY"):
raise Exception("Please set DASHSCOPE_API_KEY environment variable")
documents = SimpleDirectoryReader("./data").load_data()
# 初始化向量模型
embeddings = DashScopeEmbeddings(model="text-embedding-v3", dashscope_api_key=os.getenv("DASHSCOPE_API_KEY"), )
#创建 向量索引
index = VectorStoreIndex.from_documents(documents, embed_model=embeddings)
#转换为 检索器
retriever = index.as_retriever(similarity_top_k=3)similarity_top_k=3 表示每次检索时取最相关的 3 个片段。这个参数可以根据文档长度和回答质量调整:太小可能漏信息,太大则可能把不相关内容也带进上下文。
4. 把检索器包装成 LangChain 工具
接下来用 @tool 把 LlamaIndex 的检索能力包装成 LangChain Agent 可以调用的工具。Agent 并不需要知道底层是怎么建索引的,它只需要知道有一个 query_docs 工具可以根据问题返回相关文档内容。
@tool
def query_docs(query:str) ->str:
"""从文档中检索相关信息"""
nodes = retriever.retrieve(query)
if not nodes:
return "没有相关文档"
return "\n".join([node.text for node in nodes])这一步就是两者结合的关键:LlamaIndex 专心做检索,LangChain 把这个检索器当作一个可调用工具纳入 Agent 工作流。
5. 创建 Agent 并发起提问
最后创建模型和 Agent,把 query_docs 作为工具传入。用户提问时,Agent 会根据问题判断是否调用文档检索工具,并基于返回内容组织回答。
#模型
model = ChatOpenAI(
model="qwen3.5-plus",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
#agent
agent = create_agent(model=model, tools=[query_docs])
response = agent.invoke({"messages": [("user", "LangChain核心优势是什么?")]})
print(response["messages"][-1].content)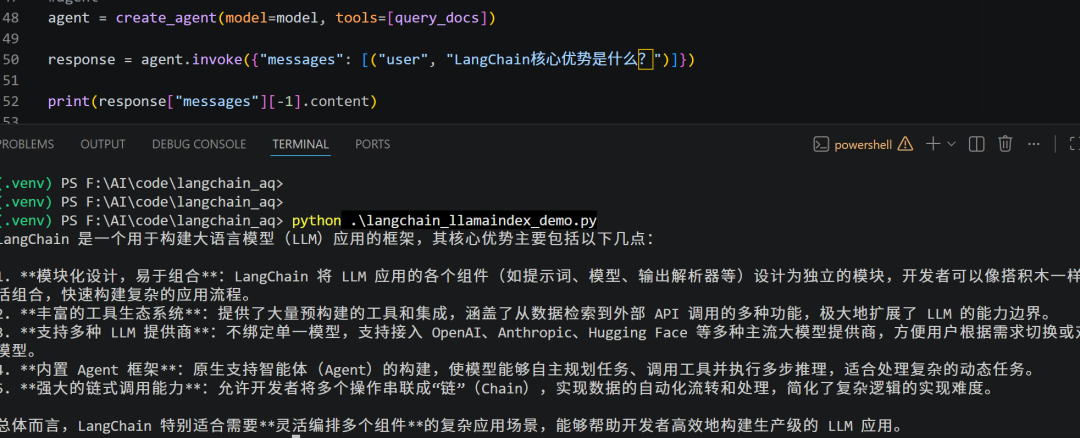
这段代码跑通后,问题“LangChain 核心优势是什么?”就不会只依赖模型记忆,而是会从 langchain_intro.txt 中检索出相关内容,再由 Agent 生成回答。对于真实业务来说,这就是最常见的组合方式:业务流程交给 LangChain,知识检索交给 LlamaIndex。
六、把这个例子放到真实项目里该怎么扩展
示例里只有一个 txt 文件,但思路可以直接扩展到更完整的知识库应用。比如你可以把 data 目录换成产品文档、制度文件、课程资料或客服知识库,再根据效果调整切分策略、向量模型、top_k 数量和检索后处理。
如果后续任务只是“问文档、答问题”,可以继续强化 LlamaIndex 这一层;如果后续任务变成“先查资料,再调用接口,再生成方案,再让另一个角色复核”,就应该把 LangChain 的 Agent 和工作流能力加进来。
因此,新项目可以按这个思路判断:
·以对话、任务执行、工具调用为主,首选 LangChain。
·以文档检索、知识库问答为主,优先考虑 LlamaIndex。
·既需要复杂流程,又需要高质量 RAG,就把两者结合起来。
总结
LangChain 和 LlamaIndex 不是非此即彼的关系。LangChain 更适合做 LLM 应用的流程编排,尤其是 Agent、多步骤任务和工具集成;LlamaIndex 更适合做文档索引、检索和 RAG 优化。
真正落地时,可以记住一句话:LangChain 负责“下一步该做什么”,LlamaIndex 负责“相关资料在哪里”。当项目既要会做事,又要查得准,把 LangChain Agent 和 LlamaIndex Retriever 组合起来,往往就是更稳的方案。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)