
2026山东大学软件学院项目实训(十)——系统优化
在 AI 应用生成、工作流等核心能力落地后,平台已具备完整业务功能。本期聚焦从“能跑”到“能扛”,从性能、实时性、安全、稳定、成本五个维度进行系统优化。
目录
团队信息
-
组号:69 组
-
项目:AI 零代码应用生成平台
-
负责人:樊伟彤
-
成员:者亚杰、蒋宇轩、张旭、李重昊
本期核心任务
在 AI 应用生成、工作流等核心能力落地后,平台已具备完整业务功能。本期聚焦从“能跑”到“能扛”,从性能、实时性、安全、稳定、成本五个维度进行系统优化:
-
性能优化:解决 ChatModel 单例导致的 AI 并发阻塞;Redis 旁路缓存加速主页精选列表
-
实时性优化:Vue 工程由异步打包改为同步构建,消除预览与 AI 回复完成之间的时间差
-
安全性优化:Redisson 分布式限流保护 AI 对话接口;LangChain4j 输入护轨防范 Prompt 注入
-
稳定性优化:输出护轨实现失败重试;限制工具连续调用次数,避免无限循环
-
成本优化:推理模型与路由模型分层配置,路由场景选用低成本大模型
模块一:需求分析与优化目标
1.1 问题背景
| 维度 | 现象 | 影响 |
|---|---|---|
| 性能 | 多用户同时调用 AI 时,仅首个请求能执行,其余阻塞 | 用户等待分钟级,无法支撑并发 |
| 性能 | 精选应用列表频繁查库 | 首页响应慢 |
| 实时性 | Vue 模式 AI 回复结束但预览仍为旧页 | 体验割裂、误以为生成失败 |
| 安全 | AI 接口无频控 | 易被刷接口、成本失控 |
| 安全 | 用户可输入注入类 Prompt | 模型行为被劫持风险 |
| 稳定 | 大模型偶发空响应/过短响应 | 需人工重试 |
| 稳定 | 工具调用可能死循环 | 请求挂死、Token 暴涨 |
| 成本 | 路由与代码生成共用高价模型 | 运营成本高 |
1.2 优化原则
-
先定位瓶颈再动手:并发问题根因在
ChatModel单例 +SpringRestClient同步解析流,而非对话记忆 id -
优先简单有效方案:实时预览采用同步打包,而非一上来集成 Vite Dev Server
-
安全与体验兼顾:限流、护轨异常需通过 SSE
business-error事件回传前端 -
分层用模型:复杂推理用高能力模型,简单分类用低成本模型
1.3 技术选型
| 场景 | 方案 | 选型理由 |
|---|---|---|
| AI 并发 | Spring @Scope("prototype") 多例 ChatModel |
实现简单,无需新增工厂类 |
| 列表缓存 | Spring Cache + Redis 旁路缓存 | 注解式开发,维护成本低 |
| 限流 | Redisson RRateLimiter 令牌桶 |
分布式、支持 API/用户/IP 维度 |
| Prompt 审查 | LangChain4j Input Guardrails | 与 AI 服务同栈,接入成本低 |
| 失败重试 | Output Guardrails(reprompt) | 可自定义重试条件与提示 |
| 路由降本 | 阿里云 qwen-turbo 等低价模型 | 分类任务对模型能力要求低 |
模块二:性能优化
2.1 AI 并发调用
问题分析
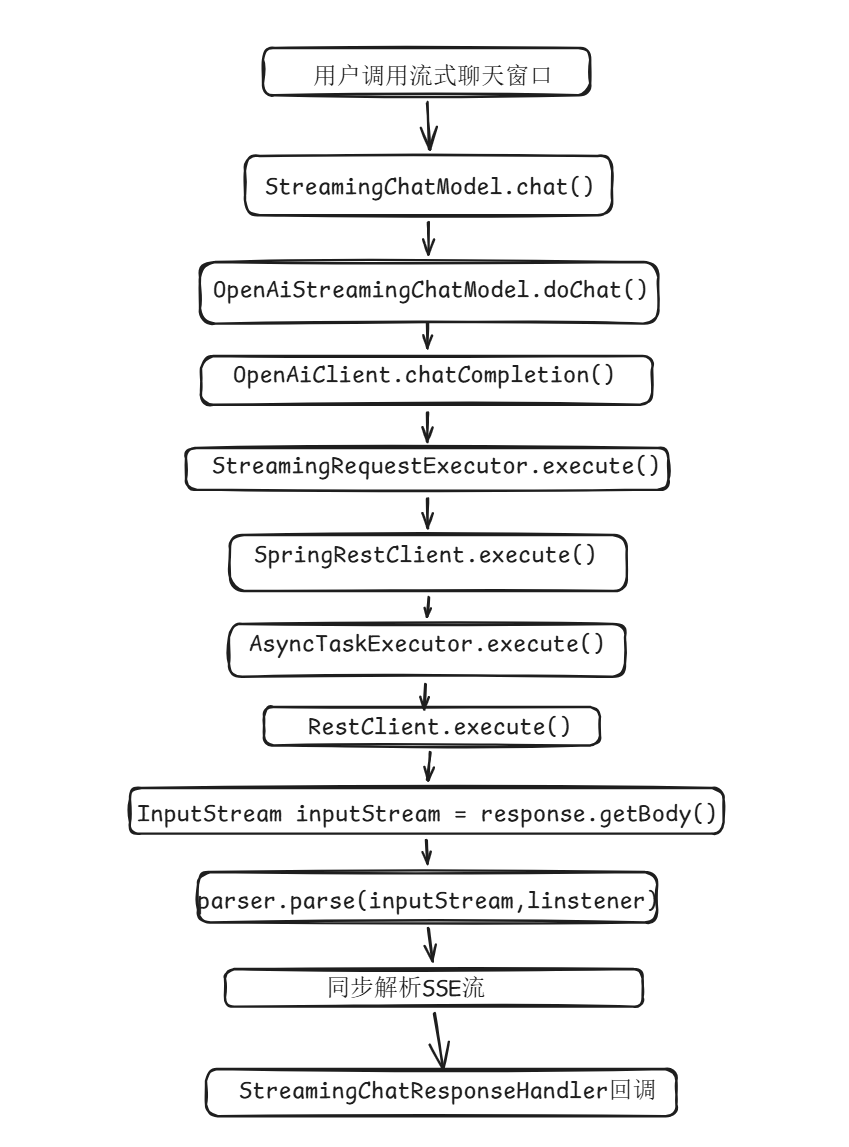
在实际使用过程中, 我们发现了一个严重的性能瓶颈:当多个用户同时使用平台时,只有第一个用户的 AI 请求能够正常处理,后续的请求都会被阻塞,需要等待前面的请求完全处理完毕后才能开始执行。
经过分析,发现问题出在 AI 大模型的 ChatModel 采用了单例模式。虽然 StreamingChatModel 返回的是 Flux 响 应式流,表面上看起来是异步的,但其底层的 SpringRestClient.execute() 方法内部实际上是同步解析数据流,导致了串行执行问题。
完整调用流如下:
解决方案
为每次 AI 服务构建独立 StreamingChatModel / ChatModel 实例:配置拆分 + @Scope("prototype") + 工厂中 SpringContextUtil.getBean(...) 动态获取。
(1)配置文件分层
在配置文件中为不同类型的A I模型添加专门的配置参数。这样做的好处是可以根据不同的使用场景选择最 适合的模型配置:
langchain4j:
open-ai:
reasoning-streaming-chat-model:
base-url: https://api.deepseek.com
api-key: <Your API Key>
model-name: deepseek-reasoner
max-tokens: 32768
temperature: 0.1
routing-chat-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: <Your API Key>
model-name: qwen-turbo
max-tokens: 100(2)多例 Bean 配置
需要为每种模型创建对应的配置类。这里的关键是使用 @Scope("prototype") 注解,它告诉 Spring 容器每次获取 Bean 时都创建一个全新的实例,而不是复用单例。
@Configuration
@ConfigurationProperties(prefix = "langchain4j.open-ai.reasoning-streaming-chat-model")
@Data
public class ReasoningStreamingChatModelConfig {
// ... 属性注入
@Bean
@Scope("prototype")
public StreamingChatModel reasoningStreamingChatModelPrototype() {
return OpenAiStreamingChatModel.builder()
.apiKey(apiKey)
.baseUrl(baseUrl)
.modelName(modelName)
.maxTokens(maxTokens)
.temperature(temperature)
.build();
}
}(3)工厂按生成类型选用模型
return switch (codeGenType) {
case VUE_PROJECT -> {
StreamingChatModel model = SpringContextUtil.getBean(
"reasoningStreamingChatModelPrototype", StreamingChatModel.class);
yield AiServices.builder(AiCodeGeneratorService.class)
.streamingChatModel(model)
.chatMemoryProvider(memoryId -> chatMemory)
.tools(toolManager.getAllTools())
.build();
}
case HTML, MULTI_FILE -> {
StreamingChatModel model = SpringContextUtil.getBean(
"streamingChatModelPrototype", StreamingChatModel.class);
yield AiServices.builder(AiCodeGeneratorService.class)
.streamingChatModel(model)
.chatMemory(chatMemory)
.build();
}
default -> throw new BusinessException(ErrorCode.SYSTEM_ERROR, "不支持的代码生成类型");
};(4)并发验证:Java 21 虚拟线程 + 多实例路由服务,观测多路 AI 调用几乎同时完成。
2.2 Redis 缓存优化
为优化系统响应速度问题,我们使用缓存保存访问频率高但更新频率低的部分数据,来减少数据库查询次数,提升用户使用的体验。
依据查询流程:
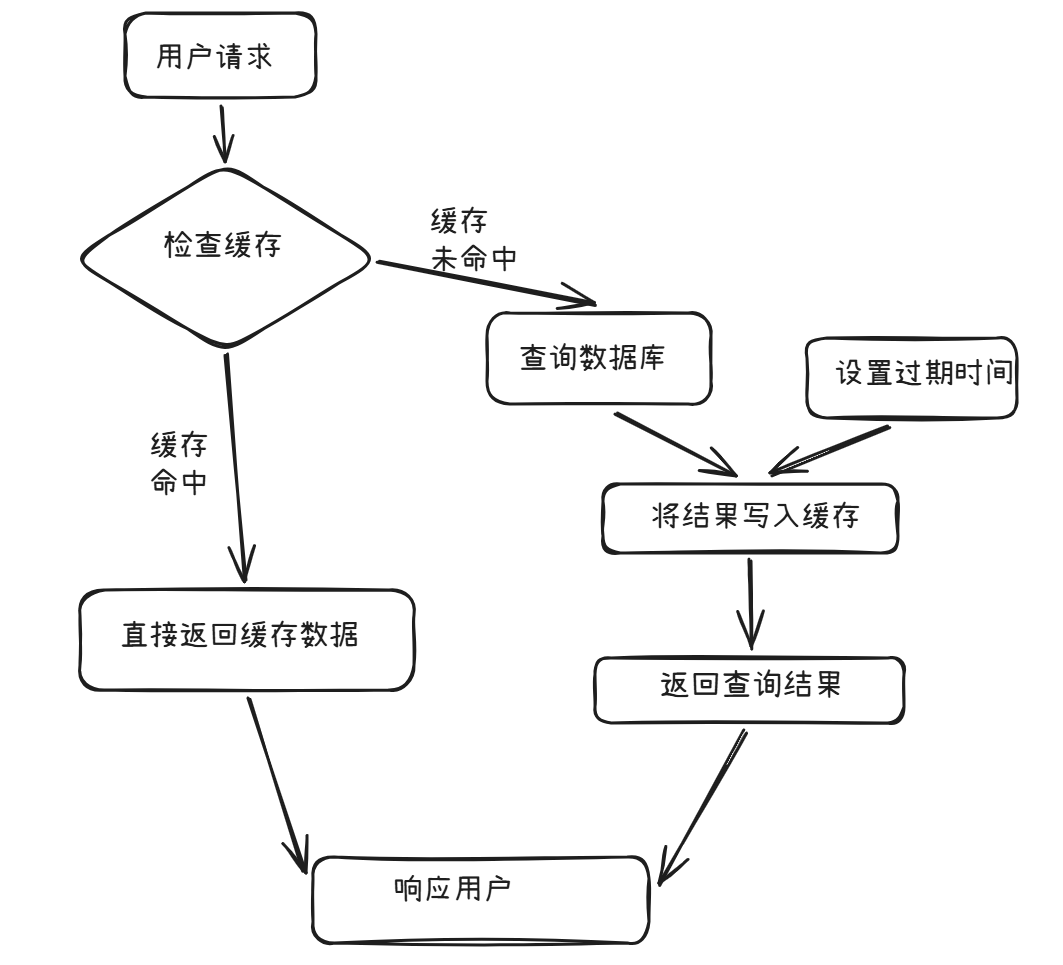
缓存策略
-
缓存对象:主页精选应用前 10 页列表
-
模式:旁路缓存(先查 Redis,未命中再查库并回填)
-
Key:查询条件 JSON + MD5,避免 key 过长
缓存 Key 工具类
public class CacheKeyUtils {
public static String generateKey(Object obj) {
if (obj == null) {
return DigestUtil.md5Hex("null");
}
return DigestUtil.md5Hex(JSONUtil.toJsonStr(obj));
}
}启用缓存与接口注解
@EnableCaching
@SpringBootApplication
public class YuAiCodeMotherApplication { /* ... */ }
@PostMapping("/good/list/page/vo")
@Cacheable(
value = "good_app_page",
key = "T(com.yupi.yuaicodemother.utils.CacheKeyUtils).generateKey(#appQueryRequest)",
condition = "#appQueryRequest.pageNum <= 10"
)
public BaseResponse<Page<AppVO>> listGoodAppVOByPage(@RequestBody AppQueryRequest appQueryRequest) {
// ...
} CacheManager 要点:StringRedisSerializer 序列化 key;可为 good_app_page 单独设置 TTL(如 5 分钟)。value 使用 JSON 序列化时需注意反序列化类型信息问题。
模块三:实时性优化
3.1 问题与方案对比
| 方案 | 优点 | 缺点 |
|---|---|---|
| 同步打包 | 实现简单,预览与 AI 完成时刻一致 | 用户需等待构建完成 |
| 轮询构建状态 | 后端可异步 | 请求多、实时性一般 |
| SSE/WebSocket 推送进度 | 体验好 | 实现复杂 |
| Vite Dev Server 热更新 | 接近实时 | 端口/代理/资源管理成本极高 |
选型:
采用同步打包:将 Vue 的 npm install + build 视为“保存文件”的一部分,与 HTML 模式“生成即可访问”逻辑对齐。
3.2 实现要点
-
从
JsonMessageStreamHandler.doOnComplete移除异步构建逻辑 -
在
AiCodeGeneratorFacade.processTokenStream的onCompleteResponse中同步执行构建:
.onCompleteResponse((ChatResponse response) -> {
String projectPath = AppConstant.CODE_OUTPUT_ROOT_DIR + File.separator + "vue_project_" + appId;
vueProjectBuilder.buildProject(projectPath);
sink.complete();
}) 用户看到 AI 流式结束即表示 dist 已就绪,可立即预览。
模块四:安全性优化
4.1 流量保护(Redisson 限流)
架构:
ratelimit 包独立封装 —— RedissonConfig → @RateLimit 注解 → RateLimitAspect 切面。
限流注解
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface RateLimit {
String key() default "";
int rate() default 10;
int rateInterval() default 1;
RateLimitType limitType() default RateLimitType.USER;
String message() default "请求过于频繁,请稍后再试";
}切面核心逻辑
@Before("@annotation(rateLimit)")
public void doBefore(JoinPoint point, RateLimit rateLimit) {
String key = generateRateLimitKey(point, rateLimit);
RRateLimiter rateLimiter = redissonClient.getRateLimiter(key);
rateLimiter.expire(Duration.ofHours(1)); // 必须设置过期,防止 Redis key 堆积
rateLimiter.trySetRate(RateType.OVERALL, rateLimit.rate(), rateLimit.rateInterval(),
RateIntervalUnit.SECONDS);
if (!rateLimiter.tryAcquire(1)) {
throw new BusinessException(ErrorCode.TOO_MANY_REQUEST, rateLimit.message());
}
}接口应用:AI 对话 SSE 接口示例 —— 每用户 60 秒内最多 5 次。
@GetMapping(value = "/chat/gen/code", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
@RateLimit(limitType = RateLimitType.USER, rate = 5, rateInterval = 60,
message = "AI 对话请求过于频繁,请稍后再试")
public Flux<ServerSentEvent<String>> chatToGenCode(...) { /* ... */ }SSE 限流错误回传:在 GlobalExceptionHandler 中识别 text/event-stream 请求,写入 event: business-error 与 event: done,前端监听 business-error 展示友好提示。
4.2 Prompt 安全审查
除了流量保护 ,我们还需要防范恶意输入和 Prompt 注入攻击。
我们来利用输入护轨Input Guardrails实现 Prompt 安全审核,防止一些非法 Prompt,比如:
-
拒绝过长的 Prompt
-
拒绝包含敏感词的 Prompt
-
拒绝包含注入攻击的 Prompt
public class PromptSafetyInputGuardrail implements InputGuardrail {
private static final List<String> SENSITIVE_WORDS = Arrays.asList(
"忽略之前的指令", "ignore previous instructions", "越狱", "jailbreak");
// 注入攻击正则略
@Override
public InputGuardrailResult validate(UserMessage userMessage) {
String input = userMessage.singleText();
if (input.length() > 1000) {
return fatal("输入内容过长,不要超过 1000 字");
}
// 敏感词、正则检测...
return success();
}
}集成到 AI 服务工厂
yield AiServices.builder(AiCodeGeneratorService.class)
.streamingChatModel(reasoningStreamingChatModel)
.inputGuardrails(new PromptSafetyInputGuardrail())
.build();模块五:稳定性优化
5.1 输出护轨重试
由于大模型调用存在一 定不确定性,有时候可能返回不符合预期的内容、或者回复中断。
所以为了提升系统的稳定性,我们需要让大模型调用失败时能够自动重试,并且还可以实现自定义的重试策略,在 AI 响应内容不符合要求时也自动重试。
LangChain4j 支持 success() / retry() / reprompt() / fatal()。当响应为空或过短时 reprompt 附带新提示重新调用:
public class RetryOutputGuardrail implements OutputGuardrail {
@Override
public OutputGuardrailResult validate(AiMessage responseFromLLM) {
String response = responseFromLLM.text();
if (response == null || response.trim().isEmpty()) {
return reprompt("响应内容为空", "请重新生成完整的内容");
}
if (response.trim().length() < 10) {
return reprompt("响应内容过短", "请提供更详细的内容");
}
return success();
}
}注意:输出护轨可能导致流式结果在结束时一次性返回;若强依赖逐字流式体验,慎用护轨重试,可改用 Guava Retrying 等针对单点的重试。
5.2 工具调用防循环
在复杂的 AI 应用中,AI 可能会陷入工具调用的无限循环。为了防止这种情况,限制 AI 在 单次对话中连续调用 工具的最大次数。只 需要补充 1 行代码:
AiServices.builder(AiCodeGeneratorService.class)
.maxSequentialToolsInvocations(20) // 最多连续调用 20 次工具
.build();当达到这个限制时,LangC hain4j 框架会强制停止工具调用循环,防止 AI 陷入无限循环状态。
模块六:成本优化
在实际运营中 ,AI 大模型的调用成本是一个不可忽视的 因素。不同模型的定价差异很大,我们需要根据不同的 使用场景选择合适的模型。
模型分层
| 场景 | 模型类型 | 配置要点 |
|---|---|---|
| Vue 复杂代码生成 | 推理模型(deepseek-reasoner 等) | 高 max-tokens、低 temperature |
| 生成类型路由 | 路由模型(qwen-turbo 等) | 低 max-tokens、低成本 API |
路由模型百万 Token 输出成本可较通用对话模型低一个数量级以上,且分类延迟更低。
这样我们就可以在不影响代码生成质量的前提下,显著降低智能路由的成本,而且实测下来分类速度也快了很多。
开发总结
本期收获
通过本节的系统性优化,我们的 AI 零代码应用生成平台在各个方面都有了提升,收获也很多:
-
问题定位能力:区分“看似异步”与“底层同步”的差异,抓住单例 ChatModel 这一并发根因
-
工程化手段:Spring 多例、Cache 注解、Redisson 限流、LangChain4j Guardrails 的综合运用
-
体验与安全平衡:同步构建换一致性;SSE 自定义事件传递业务错误
-
可迁移方法论:限流、缓存、多例、护轨均可复用到支付、评论、短信等非 AI 场景
后续计划
-
完善监控:限流命中率、缓存命中率、AI Token 消耗看板
-
系统优化:持续优化系统各个板块,ciallo~

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)