
(三)DeepSeek v2 原理
论文标题:DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
论文地址:https://arxiv.org/pdf/2405.04434
Github地址:https:////github.com/deepseek-ai/DeepSeek-V2
DeepSeek V2的改进点:
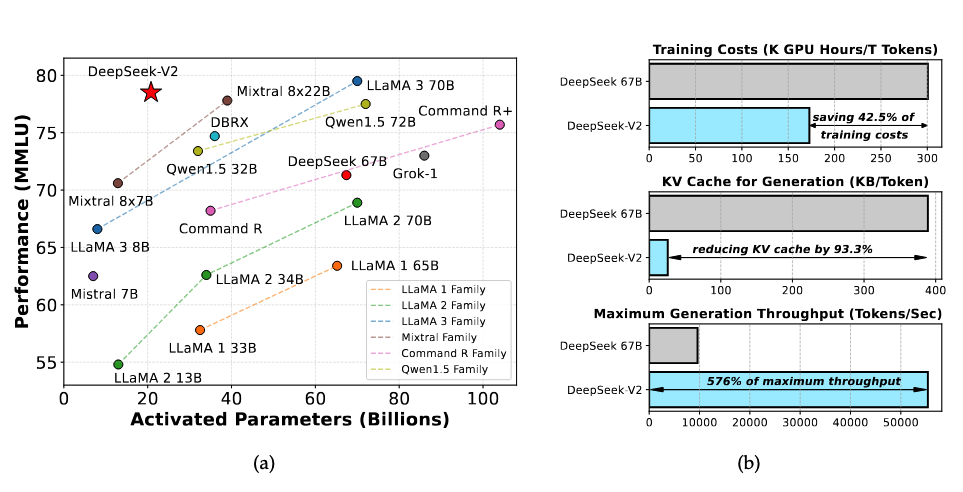
1.集成DeepSeek v1,并改进: 由GQA迭代为MLA, 减少93.3%的KV缓存.
2.集成DeepSeek Moe,并改进:多了通信平衡损失 和 令牌丢弃等策略。
两种技术带了DeepSeek-v2强大性能,高效的推理吞吐量。
一、MLA
是一种类似秩压缩的注意力机制。
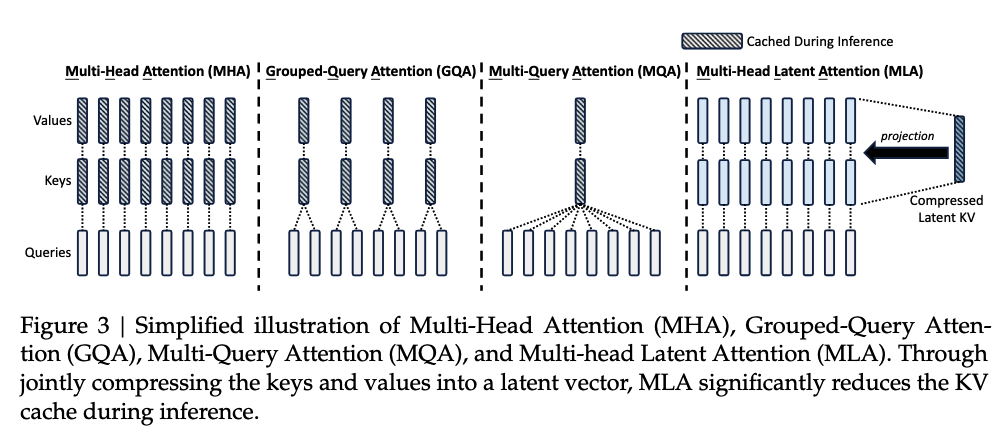
MHA需要保存N个头的K,V缓存,效果好;
GQA保存M个组的K,V缓存,效果较好;
MQA保存一个头的K,V缓存,效果一般;
MLA则是将 Key-Value (KV) 缓存压缩为潜在向量,使用时进行映射,效果好。
1.1 MHA结构
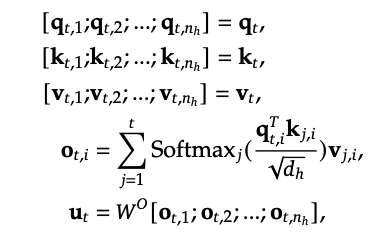
为了方便计算,每次都需要保存K-V缓存。
1.2 MLA结构

为了减少K-V缓存,采用低秩键值联合压缩(对键与值进行低秩联合压缩来减少KV缓存), 中D是降维,
中U是升维。
公式40中 QUERY 由
和
两部分组成
公式44中 KEY 由
和
两部分组成,
公式45中 VALUE 等于
,可以理解为先降维得到K和V的压缩隐向量,然后升维。
当前只需要保留上图蓝色框住的两个向量就能映射多个K,V,避免缓存K-V对,减少显存占用。
中涉及的
*
可以提前计算好。
涉及的
*
可以提前计算好。
- 基于矩阵乘法结合律,因此无需为每个查询单独计算键与值。通过此优化,我们避免了在推理过程中重新计
和
下图和上面的公式能一一对应。
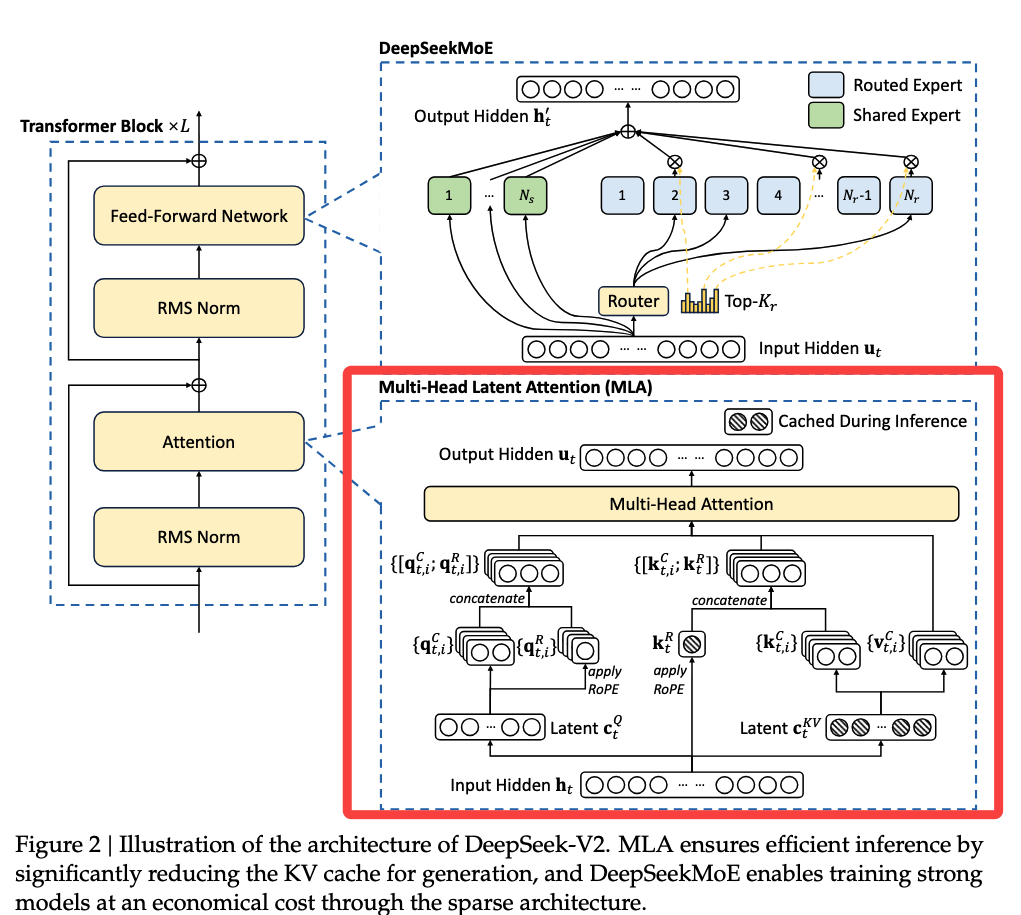
二、Moe
采用DeepSeekMoE架构(Dai等人,2024),该架构通过细粒度专家分割和共享专家隔离,为专家专业化提供了更高潜力。
moe原理、专家级平衡损失、设备级平衡损失 可以参考:DeepSeekMoE 原理-CSDN博客
2.1 通信平衡损失



2.2 Token-dropping strategy

三、整体架构、量化和精度优化等

推理效率。为高效部署DeepSeek‐V2提供服务,我们首先将其参数转换为FP8精度。此外,我 们还对DeepSeek‐V2实施KV缓存量化(Hooper等人,2024;Zhao等人,2023),将其KV 缓存中每个元素进一步平均压缩至6比特。
HAI‐LLM框架
- 16路zero-bubble流水线并行
- 8路专家并行
- ZeRO-1 数据并行
- FlashAttention-2
四、参考

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)