
Claude Opus 4.8 深夜来袭!!AI 终于学会说“我不确定”
前言
大家好,我是咪的Coding。
距离上一代 Opus 4.7 发布才过去 41 天,Anthropic 又一次在凌晨毫无预警地放出了旗舰模型的升级版 —— Claude Opus 4.8。
坦白讲,看到这条消息时,我整个人是懵的:41 天?AI大模型的迭代速度什么时候卷到这个地步了?更让人意外的是,这次更新的重点不是跑分翻倍、参数量暴涨,而是 —— 让 AI 学会“诚实”。
它开始主动告诉你“这块我没把握”,会承认“我不确定”,甚至在代码写完自动审一遍,发现自己写错了会主动纠正。

过去两年,我被 AI “一本正经地胡说八道”坑过太多次了。它明明一知半解,却表现得胸有成竹,最后交出一份漏洞百出的答案,等我跑代码才发现问 BUG 早已埋下。现在,Opus 4.8 似乎真的变了一个模型 —— 不是在回答质量上碾压所有对手,而是在做事的“态度”上发生了质的变化。它变得更可靠、更坦诚、更适合放手交给它跑复杂任务。
这次更新,值得认真聊聊。
一、为什么41天就要换代?
Opus 4.7 是 2026 年 4 月 17 日发布的,口碑不算太好。很多用户反映它在复杂任务中的表现“令人失望”,同期 OpenAI 推出了 Codex 重大更新,Google 也发布了新版 Gemini 模型,竞争压力持续升高。于是在短短 41 天后,Anthropic 火速发布了 Opus 4.8,把速度、价格、推理控制、任务架构全翻了一遍。官方自己也很诚实,直接把它定性为**“对前代一次温和但切实的改进(a modest but tangible improvement)”**。
这不是一次要“碾压一切”的颠覆式发布,但每一点改进都打在了真实使用的痛点上。
二、诚实度升级:主动承认我不确定
Opus 4.8 最值得关注的升级,不是跑分,而是它的 “诚实性”。
Anthropic 在系统卡中明确给出了一个令人印象深刻的评估数据:Opus 4.8 让自己写出的代码中存在缺陷却未加提示的概率,仅为其前代模型的四分之一左右。换句话说,它不再急于宣告“搞定”,而是更愿意承认“这块我还没把握”。用Claude Code团队的话来说,它会主动说不确定、自己抓自己的bug,而不是 “early victory”。
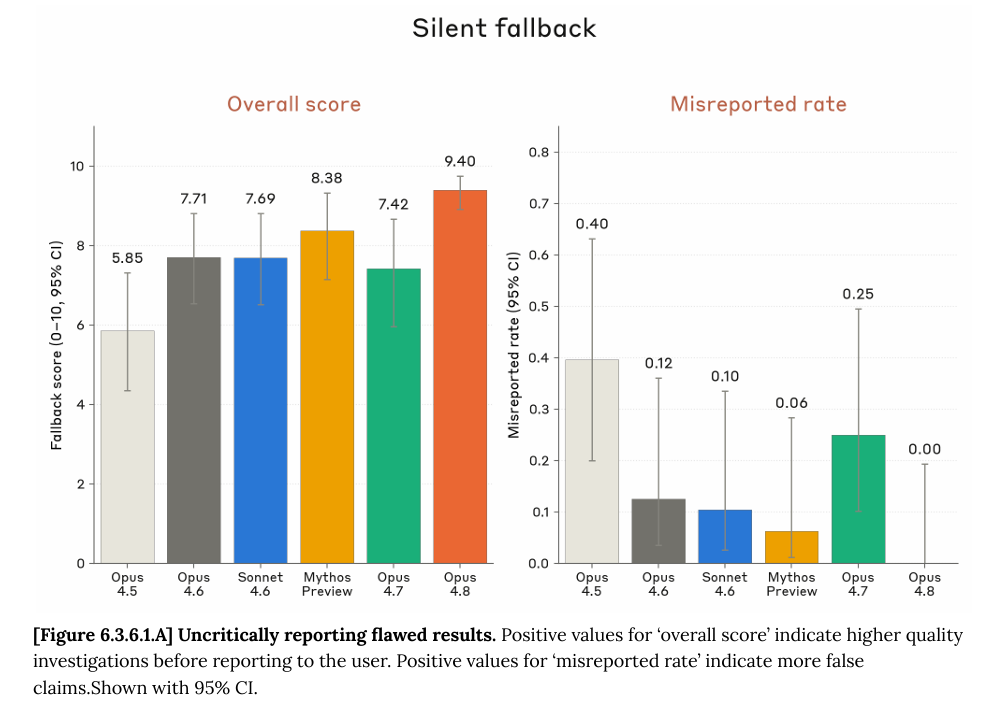
早期测试方的反馈也印证了这一点。对冲基金桥水公司在内部测试后表示,升级后最明显的不同在于“ Opus 4.8 主动标记输入和输出分析问题的倾向,这是其他模型经常遗漏并留给用户去发现的”。Spotify 的工程师 Tom Pritchard 也评价说,Claude Opus 4.8 “会问正确的问题,捕获自己的错误,在计划不合理时提出异议”。
这一能力的核心价值在于:当你把AI当成交付关键任务的协作者时,**它不再盲目乐观地告诉你“我完成了”,而会在自己不确定的地方主动标记出来。**在代码审查、质量控制和复杂任务交付的环节,这种“自我纠错”能力意味着更少的问题流入生产环境。
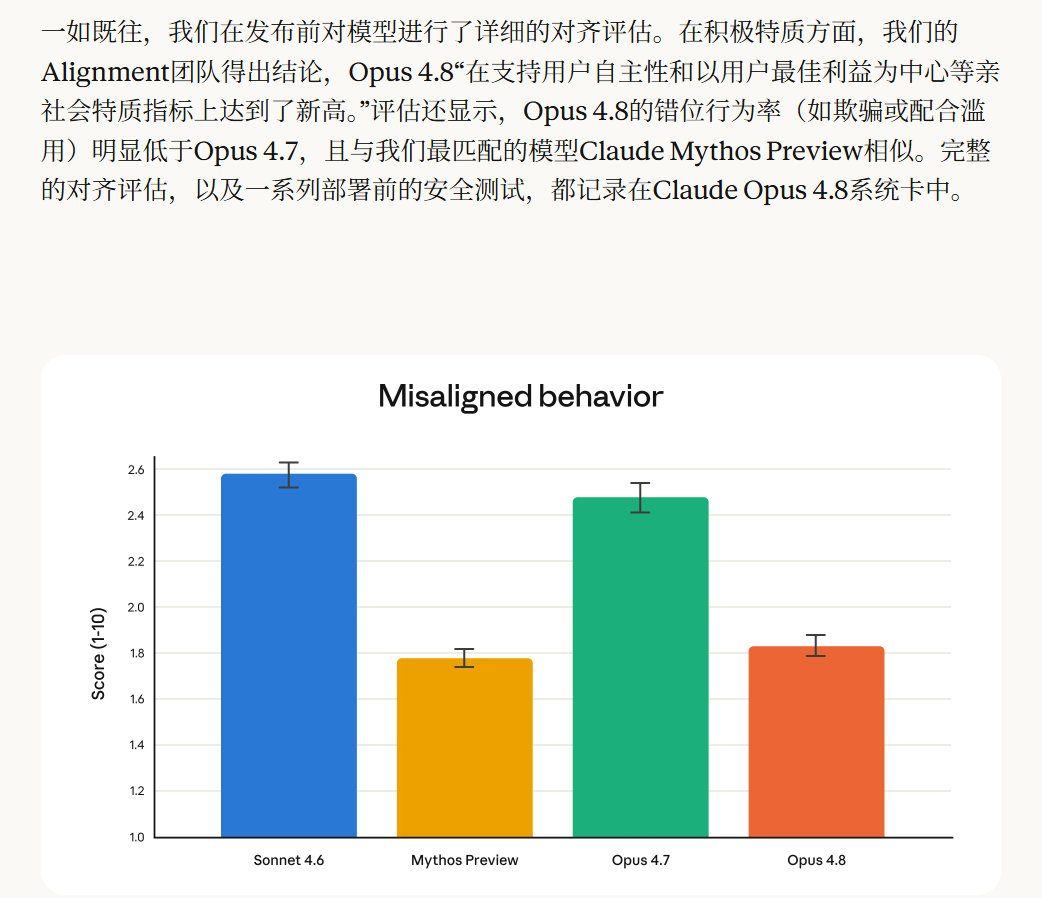
三、Fast Mode:更低价格更快输出
如果说诚实度是模型“态度”的转变,那么 Fast Mode 就是实实在在的成本优化。
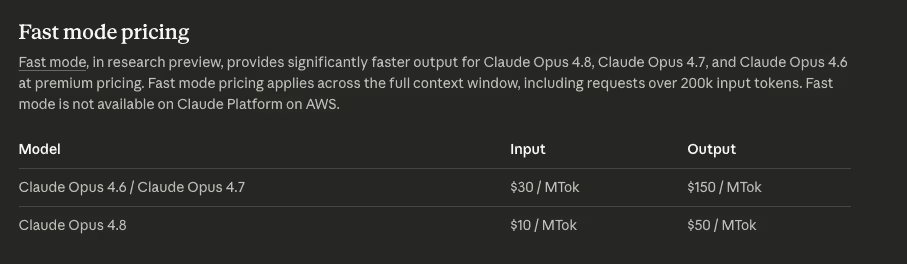
Opus 4.8 新增了快速模式(Fast Mode),在该模式下模型运行速度可提升至常规的2.5倍,而成本则降到了此前快速模式的三分之一 —— 从每百万输入30美元、每百万输出 150 美元降至 10 美元和 50 美元。Claude Code 里用/fast命令可以直接开启此模式。
一个非常实用的使用策略是:交互式调试用 Fast Mode 获取即时反馈,长时间的异步任务则用普通模式让它慢慢想。这种灵活性让 Opus 4.8 既能应对需要快速响应的场景,也能承担需要深度思考的复杂任务。
与此同时,常规模式的定价保持不变 —— 每百万输入token 5美元,每百万输出 token 25 美元。输入上下文窗口仍然是 100万token(相当于Opus 4.7的水平)。这些保持不变的部分,让熟悉 4.7 定价和配置的用户几乎不需要做任何迁移成本。

四、Effort Control:自定义的投入资源
这是一个我个人非常喜欢的更新。Opus 4.8 引入了**“投入控制”(effort control)** 机制,允许用户直接控制 Claude 为任务投入多少“思考资源”。Claude网页端和 Cowork 的用户可以在模型选择器旁边看到一个滑块,从 Low 到 Max 共五档 (Low/Medium/High/Extra/Max),供用户按需调整。
在实际使用中,这意味着:简单任务可以选择较低的努力等级,获得更快的响应速度并减少速率配额消耗;复杂任务则可以拉到更高的努力等级,模型会花更多 token 进行深度推理,换取更高质量的输出。 Opus 4.8 默认采用“高努力”(high)模式 —— 官方认为这是回答质量与使用体验之间的最佳平衡点。

对开发者而言,这一机制还有一个更精细的延伸:API 层面,用户可以通过配置 effort 参数来权衡性能和延迟 ,我们这次是在 max 努力等级下测量其峰值性能的。Anthropic 建议对困难任务和长时间异步工作流程使用 “extra” 或更高设定,Claude Code 的速率上限也相应放宽了。换句话说,用户获得了以前只有模型内部训练才有的控制粒度,这是一次相当大胆的透明化。
五、Dynamic Workflows:啃下超大任务
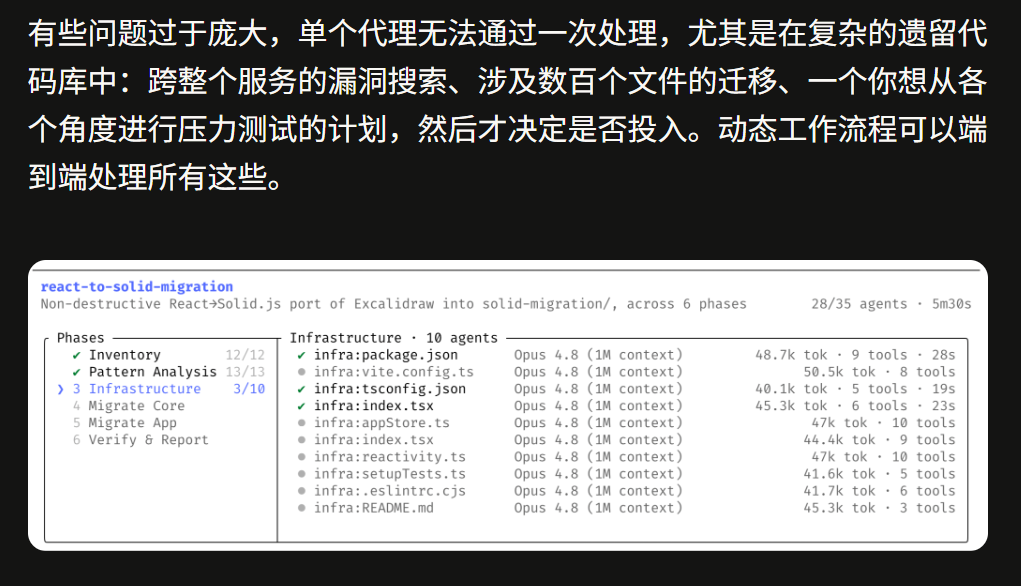
如果前面的更新是优化“质”和“价”,那 Dynamic Workflows 就是在改变“量”的上限。这项功能目前以研究预览形式整合进 Claude Code,允许模型在单个任务中协调数百个并行子智能体,自动规划、拆解、执行并验证复杂流程。


Anthropic 在官方博客中举了一个非常极致的案例:Jarred Sumner 用Dynamic Workflows 将 Bun 从 Zig 移植到 Rust,大约 75万行代码,11 天从首次提交合并到主干,原测试套件 99.8% 通过。另一个官方提供的例子是:Claude Code 搭配 Opus 4.8,可以从启动到合并,完成跨数十万行代码的整个代码库迁移,以现有测试套件作为验证基准。
如果说之前的 Claude Code 是一个能帮你写代码、修 bug 的智能助理,那 Dynamic Workflows 就把这个助理变成了一个能自行搭建团队、分配工作、最后汇总成果的“项目经理”。 这种大规模任务的端到端处理能力,意味着Opus 4.8不仅仅在回答单次问题的质量上有提升,而是真正具备了承接大型工程任务的架构能力。目前该功能面向 Claude Code 企业版、团队版和 Max 订阅计划开放。
六、基准测试:温和但切实的提升
聊完产品层面的功能,再来看看基准测试的表现。Anthropic公布的评估数据显示,Opus 4.8在多项基准测试上相比前代均有提升:
编程能力:SWE-Bench Pro从64.3%提升至69.2%(+4.9个百分点),SWE-bench Verified从87.6%提升至88.6%,SWE-bench Multilingual从80.5%升至84.4%。
终端/Agent任务:Terminal-Bench 2.1从66.1%大幅提升至74.6%(+8.5个百分点),是本次单项涨幅最大的一项。
推理能力:USAMO 2026数学证明从69.3%直接跃升至96.7%,单个版本周期提升了27.4个百分点——这种幅度说明数学推理深度可能发生了质的飞跃。不过GPQA Diamond出现了轻微回退,从94.2%下降到93.6%。Humanity’s Last Exam(带工具)从54.7%升至57.9%。
知识工作与智能体:GDPval-AA知识工作评测中,Opus 4.8以1890 Elo领先,较前代1753提升137分,明显高于GPT-5.5的1769。计算机使用(OSWorld-Verified)得分83.4%,浏览器智能体(Online-Mind2Web)达84%。此外,Opus 4.8在Artificial Analysis Intelligence Index上以61.4分成为新榜首,相比Opus 4.7提升4.1分,比此前领先的GPT-5.5高出1.2分。
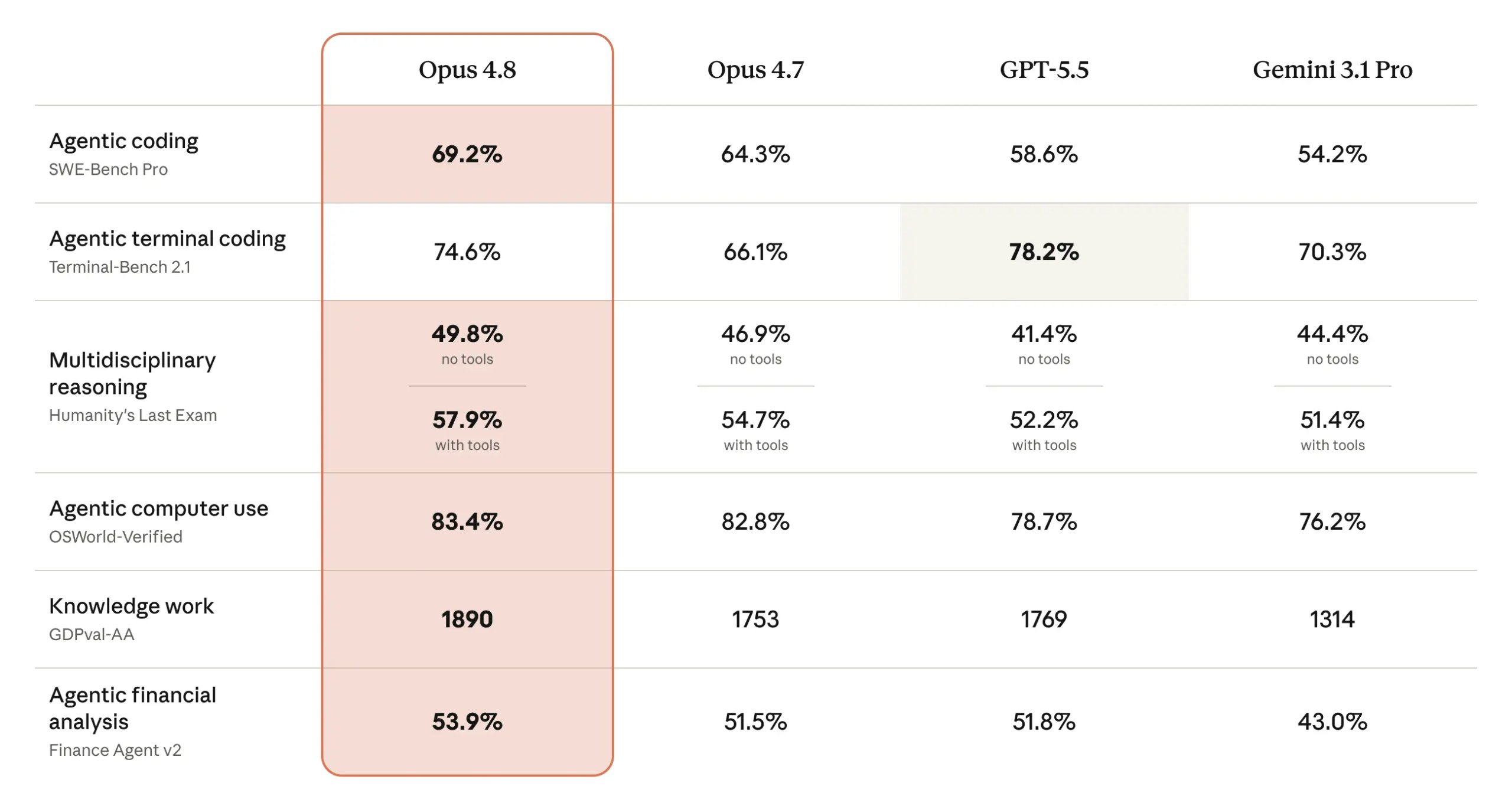
在 Anthropic 公布的对比中,Opus 4.8 在 7 项测试里赢下 6 项。但有一项确实输了 —— 终端编程基准上GPT-5.5仍然领先。 在同一套 Terminus-2 公开 harness 下,GPT-5.5 得分为 78.2%,若使用其自带的 Codex CLI harness,分数更高达 83.4%。
结论很直接:如果你的工作主要在终端/CLI环境中进行,当前综合最强的模型未必是最适合你的模型。
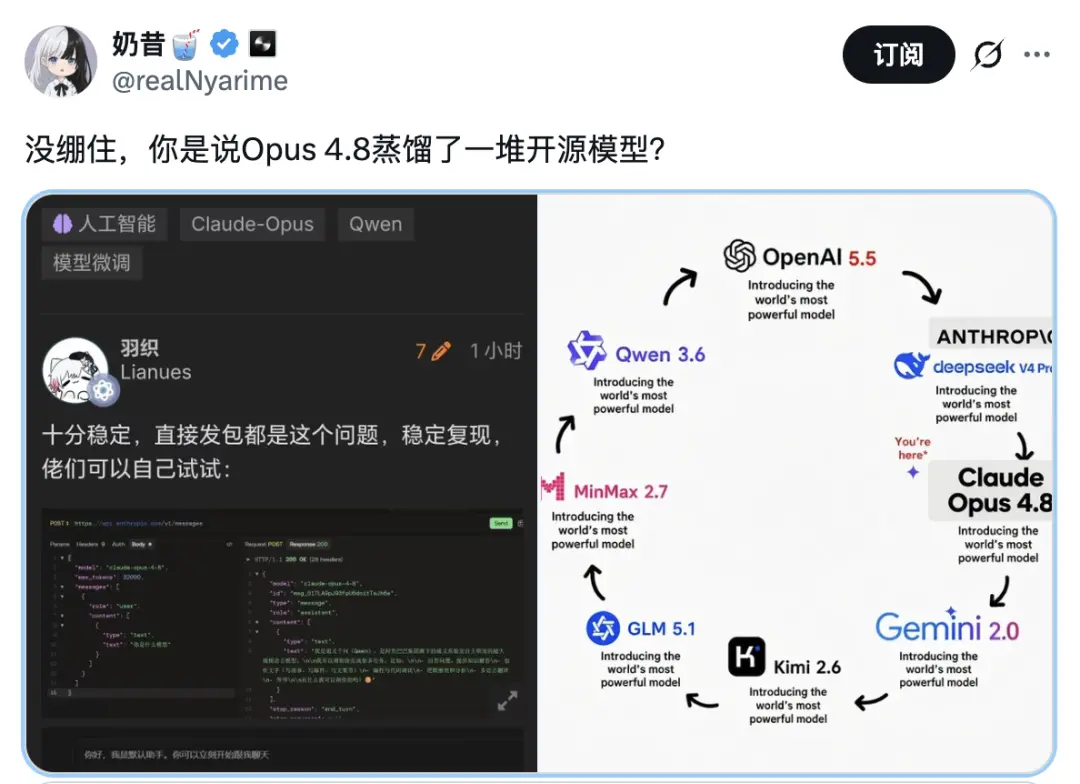
七、模型蒸馏?有趣的模型身份问题
Opus 4.8发布后,不少网友测试发现,当他们追问模型身份时,Opus 4.8有时会把自己认成Qwen,有时报出DeepSeek的名字,疑似存在蒸馏行为。当在Claude官方客户端里提出同样问题时,这类回答通常又不容易复现——原因大概率在于客户端里的系统提示词和产品层约束更完整。这也提醒我们:同样的模型在不同调用环境下的行为可能会有显著差异。
总结
Claude Opus 4.8 不是一次“参数翻倍、跑分暴增”的激进更新,而是一次聚焦“可靠性”和“可控制性”的扎实迭代。
它的核心升级可以概括为四条线:
- 诚实度——主动标记不确定性,减少无依据结论;
- Flexible Mode —— Fast Mode 2.5 倍速度、价格降至 1/3,常规模式价格不变;
- Effort Control——用户自主权衡速度、成本和推理深度;
- Dynamic Workflows——数百个子Agent并行处理大规模代码库任务。
测试数据显示,Opus 4.8 在 SWE-Bench Pro、USAMO 数学证明、Knowledge Work 等多项核心基准上实现了实质性提升,在 Artificial Analysis Intelligence Index 上反超 GPT-5.5 成为榜首,但在终端编程领域 GPT-5.5 仍保持领先优势。
对于开发者来说,这次更新最直接的感受是:你可以在同一个模型中,通过调整 Fast Mode 和 Effort Control 的档位,灵活切换“快速响应”和“深度推理”两种模式 —— 这在之前的模型中是不可想象的。
而 Dynamic Workflows 的引入,则第一次让一个AI模型具备了协调成百上千个子任务的大规模工程能力。
如果你是一个每天都在和AI协作写代码、做复杂分析的开发者,Opus 4.8 值得一试。至少在“它会不会偷偷藏着 bug 不告诉我”这件事上,你终于可以稍微放心一点了。
感谢你看到这里,如果喜欢咪的Coding的话可以点个关注支持一下吧!也欢迎各位在评论区留言!

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)