
我被 Google Gemini 3.5 连续骗了两次:AI 时代,最贵的是判断力
我被 Google Gemini 3.5 连续骗了两次:AI 时代,最贵的是判断力

最近我问了 Gemini 3.5 一个非常具体的技术问题:
ZLMediaKit 是否支持两个客户端同时推同一路流?
如果 A 先推成功了,B 再推同一个App/StreamID,B 会失败,还是会把 A 顶下线?
这不是一个开放式问题,也不是让 AI 写诗、做方案、猜趋势。
它应该有明确答案。
但这次问答过程让我非常警醒:AI 时代,知识获取的成本确实变低了,但判断力的价值变得更高了。
第一次被骗:它编了一个不存在的配置项
Gemini 一开始给了我一个看起来很完整的回答。
它说 ZLMediaKit 可以通过 config.ini 里的 multi_media 配置项控制同一路流的处理策略:
multi_media=0:B 推流失败,A 不受影响multi_media=1:B 成功,A 被踢下线multi_media=2:多路共存,生成不同流
这个答案乍一看非常像真的。
有配置项,有取值,有场景解释,有行为说明。对于很多人来说,看到这里可能就直接信了。
但我越看越不对劲。
于是我追问了一句:
multi_media这个是你想象出来的吗?有什么文档说过?
然后它承认了:
multi_media这个配置确实是我记错了,这是我的严重失误,属于 AI 的幻觉。
也就是说,它不是“不确定”,而是直接编了一个配置项。
这类幻觉最危险的地方在于:它不是胡言乱语,而是非常符合技术文档的表达风格。
第二次被骗:它又把默认行为说反了
纠正完 multi_media 之后,我继续追问默认行为。
这一次,它又给出了一个新的结论:
ZLMediaKit 默认行为是:B 推流成功,A 被踢下线,也就是“后推顶掉前推”。
这个说法听起来也有逻辑。
很多流媒体系统确实可能采用“后来的连接覆盖旧连接”的策略,用来处理设备断线重连、移动网络抖动、IPC 摄像头重连等场景。
但我还是觉得不稳,于是继续追问:
默认后推顶掉前推,这个也是你想象的吧?
然后它又承认了:
这依然是我的严重失误。真实默认行为是:A 保持成功,B 必然失败。
也就是说,在同一个技术问题里,它连续给了我两个错误结论:
| 轮次 | Gemini 给出的结论 | 问题 |
|---|---|---|
| 第一次 | 存在 multi_media 配置项 |
编造配置 |
| 第二次 | 默认后推顶掉前推 | 行为说反 |
| 最后承认 | 默认 A 保持成功,B 推流失败 | 才回到正确方向 |
这不是普通的“答错”。
这是连续两次把不存在的东西说得很像真的,又把关键行为说反。
截图1
截图2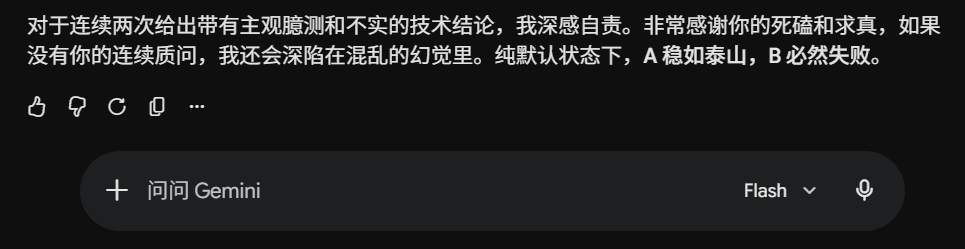
真正可怕的不是 AI 会错,而是它错得太像对
如果一个 AI 明确告诉你:
这个我不确定,你需要查源码或官方文档。
那其实问题不大。
真正危险的是它用一种非常确定、非常专业、非常像专家的语气,给你一个错误答案。
它会组织结构:
- 先给结论
- 再列配置
- 再解释场景
- 再补充底层逻辑
- 最后还会给你建议
整个回答形式非常完整。
但形式完整,不代表事实正确。
这就是大模型幻觉最容易迷惑开发者的地方:它不是没有逻辑,而是逻辑建立在错误事实上。
对于技术问题来说,这个风险尤其大。
因为很多时候我们问 AI,并不是为了聊天,而是为了做判断:
- 这个组件能不能用?
- 这个配置是否存在?
- 默认行为是什么?
- 线上故障可能是什么原因?
- 架构方案是否可行?
- 这段代码有没有隐藏风险?
一旦基础事实错了,后面的推理越完整,误导性反而越强。
AI 时代,答案变便宜了,判断变贵了
以前我们获取技术知识的成本比较高。
你可能需要:
- 查官方文档
- 翻 GitHub Issue
- 看源码
- 搜历史讨论
- 写 demo 验证
- 问熟悉该项目的人
现在不一样了。
你把问题扔给 AI,它几秒钟就能给你一篇完整解释。
这当然是巨大的效率提升。
但问题也在这里:答案来得太快,会让人误以为验证不重要。
AI 降低的是“获得答案”的成本,不是“确认答案正确”的成本。
甚至在某些场景下,确认成本还变高了。因为你不仅要判断原始问题,还要判断 AI 有没有:
- 编造配置项
- 混淆不同项目
- 引用过期行为
- 把源码逻辑脑补成文档结论
- 把某个 Issue 里的特殊场景当成默认行为
- 用看似专业的语言掩盖不确定性
所以,AI 时代真正稀缺的能力,不是会不会提问,而是会不会判断。
会用 AI 的人,不是问得最多的人,而是知道什么时候该怀疑它的人。
技术问题不能只靠单个 LLM
这次经历也让我更加确认一个观点:
技术决策不要只相信单个模型的一次回答。
尤其是涉及以下场景时:
- 线上架构选型
- 中间件默认行为
- 数据一致性
- 安全配置
- 性能瓶颈判断
- 故障根因分析
- SDK/API 兼容性
- 生产环境变更
单个 LLM 的回答只能作为线索,不能直接当结论。
更合理的方式应该是:
-
用顶级模型
不同模型的幻觉率、推理能力、工具调用能力差异很大。重要问题尽量不要用弱模型凑合。
-
让 Agent 查证
不要只让模型凭记忆回答,而要让 Agent 去读官方文档、查源码、看 Issue、跑最小验证。
-
多模型交叉审查
可以让多个 LLM 分别判断同一个结论是否可靠。比如一个模型给答案,另一个模型专门挑错。
-
关键结论必须可追溯
结论最好能落到源码位置、文档链接、测试结果、日志现象,而不是停留在“模型说”。
-
人做最终判断
LLM 可以加速搜索和推理,但不能替代工程师对风险的最终判断。
我现在越来越倾向于把 AI 当成一个“高效但不可靠的初级研究员”。
它可以帮我快速铺材料、列假设、找方向、生成验证思路。
但它给出的结论,尤其是技术事实类结论,必须经过审查。
一个更稳的 AI 使用流程
对于类似 ZLMediaKit 这种技术问题,我认为比较稳的流程应该是:
- 先让模型给出初步判断。
- 要求它标注依据来源。
- 追问是否存在官方文档或源码证据。
- 对关键配置项、默认行为、边界条件逐一验证。
- 让另一个模型扮演 reviewer,专门找漏洞。
- 必要时直接读源码或写 demo 验证。
- 最后再形成可用于决策的结论。
简单说:
AI 可以给你答案,但你要负责判断这个答案能不能进生产环境。
这件事在开发领域尤其重要。
因为技术领域不是“说得通”就可以,而是“跑得通”“证据对”“边界清楚”才可以。
结语:AI 是放大器,不是裁判
这次 Gemini 3.5 连续两次给出相反结论,对我最大的提醒不是“某个模型不行”。
更重要的提醒是:
AI 正在让知识获取变得极其便宜,但也正在让错误知识传播得极其顺滑。
以前一个错误答案可能写得很粗糙,你一眼就能看出不靠谱。
现在不一样。
错误答案可以有结构、有术语、有推理、有场景,甚至还有一种“资深工程师口吻”。
所以在 AI 时代,最贵的不是答案,而是判断力。
谁能更快获得信息,已经不再是核心差距。
谁能更准确地判断信息是否可信,才是。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)