
《CodeBuddy领航》学习笔记(3):从能跑到好用,Linku灵库的迭代实战
继续我的Datawhale组队学习之旅,进入了Task3阶段——深入第三章的项目实战。按照学习任务,本应完成ToDo List项目并体验完整的“需求→提示词→代码→运行→修改”闭环。但延续上一阶段的思路,我依然选择在自己的项目Linku灵库上进行实践。
如果说Task2是“从零到一,把项目跑起来”,那么Task3就是“从能跑到好用”——对UI界面进行优化、增加核心功能、拉取更强的模型,让这个个人知识库助手真正变得可用、好用。
一、这一阶段做了什么
1. UI界面优化
MVP阶段的项目界面偏“能用就行”,这一阶段我花了不少精力在前端体验上。主要优化包括:
- 整体布局重构:采用更清晰的切换分栏,让文档导入、智能问答和文档管理三个核心场景切换更自然
- 文章阅读器升级:之前只是简单的文本展示,现在增加了阅读视图,阅读体验更像一个真正的“知识库”
- 视觉风格统一:调整配色、字体、间距,让整个应用看起来更协调
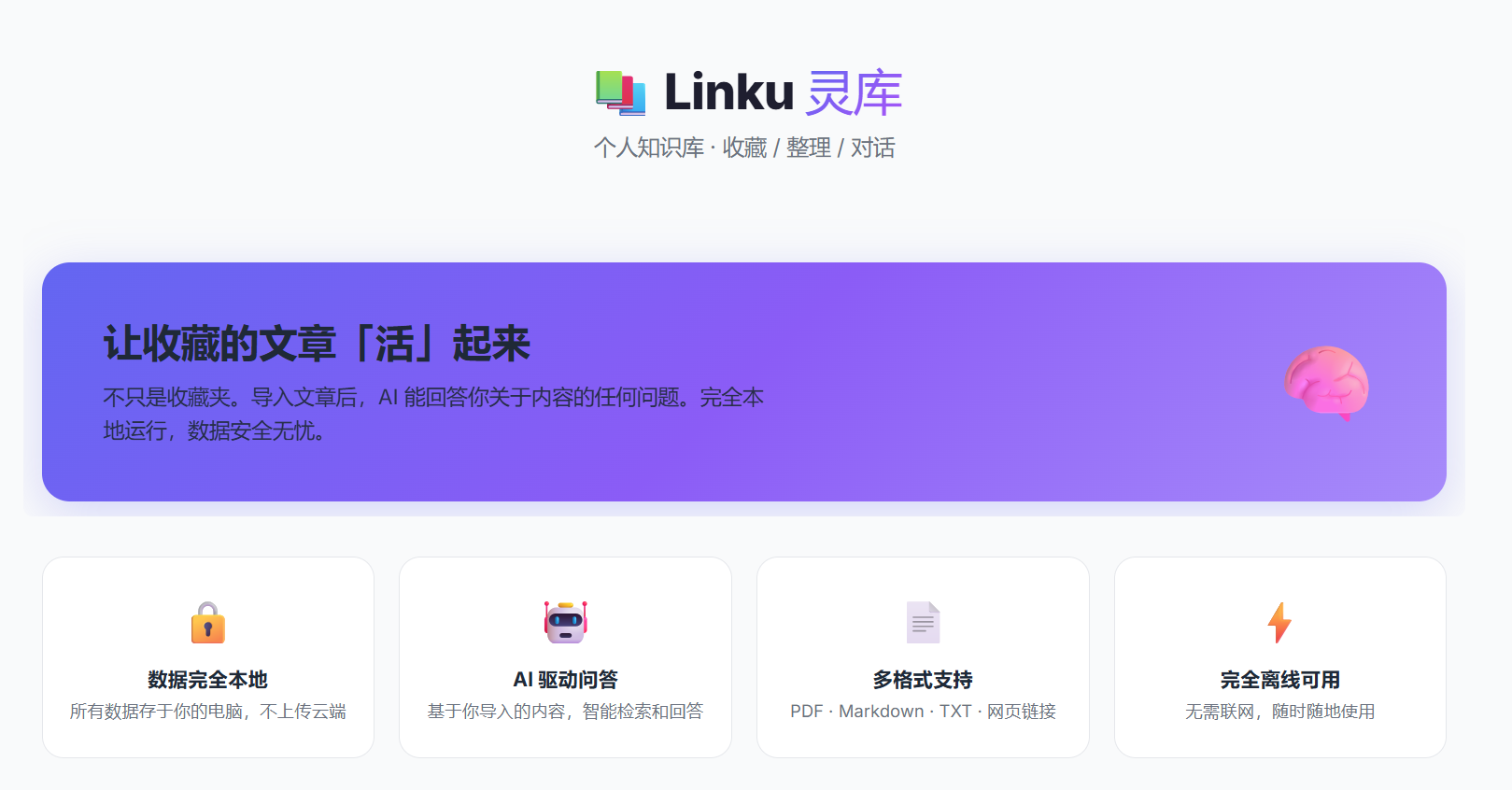
Linku主界面
体感:界面优化看起来是“面子工程”,但对于一个知识管理工具来说,阅读舒适度直接影响使用意愿:改完之后用户自己也许会更愿意用Linku去整理和回顾文章。
2. 文章阅读器 + 批注/笔记/标签功能
这是本次迭代最核心的功能新增。之前Linku能做的事情是“导入文档→AI问答”,但文档本身是不可交互的静态内容。现在增加了一套完整的阅读与标注系统:
- 文章阅读器:支持Markdown和纯文本的优雅渲染,带给用户更舒适的文章阅读体验
- 标注功能:在阅读过程中可以选中文本添加标注,标记用户觉得重要的部分
- 写笔记:每篇文章可以单独记录自己的阅读笔记,文思泉涌随时写下
- 打标签:支持为文档添加自定义标签,用于文档管理分类筛选和检索
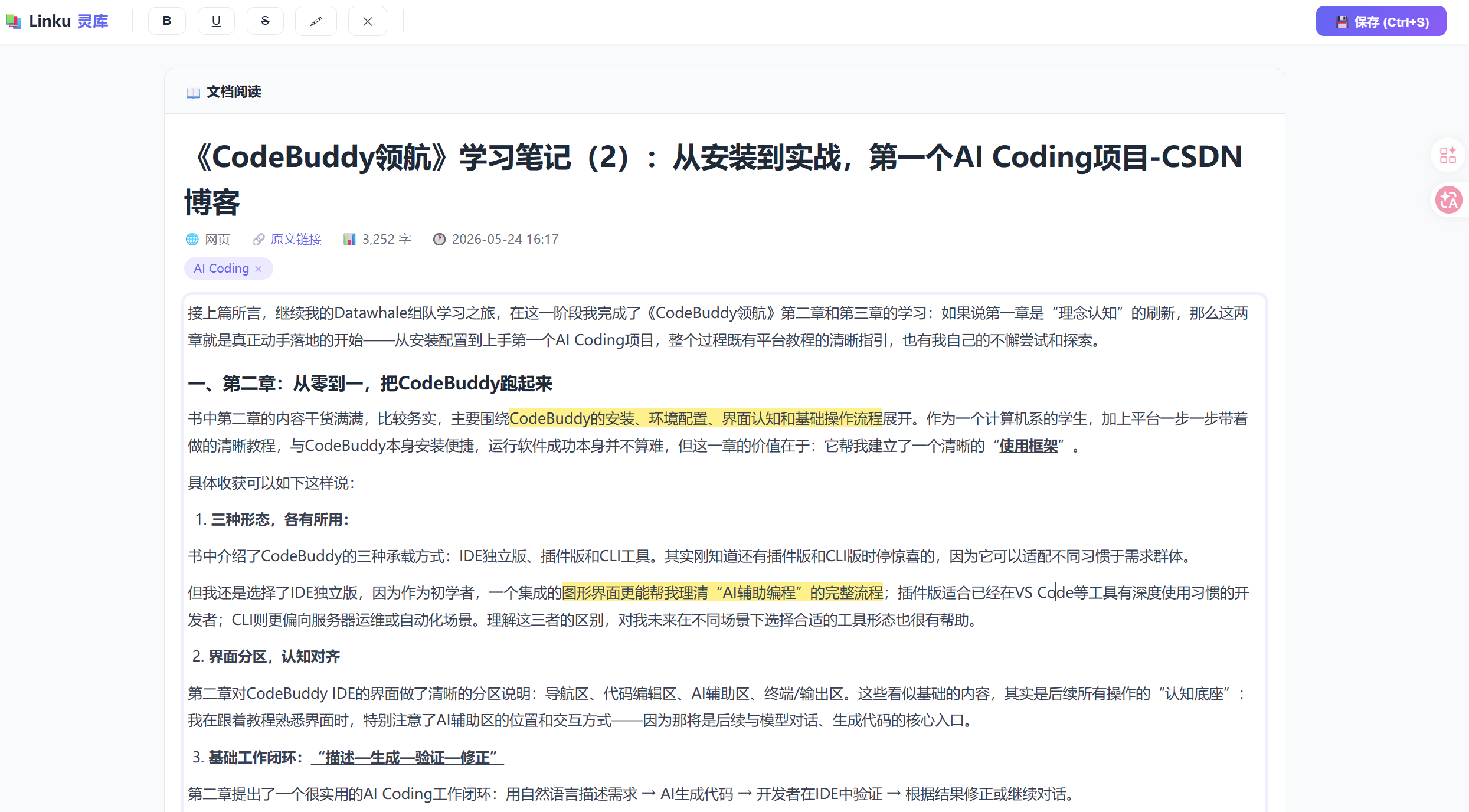
笔记阅读器
体感:这一组功能让Linku从一个“AI问答工具”真正变成了“知识管理工具”。用户不再只是被动地和AI对话,而是可以主动地在知识库中留下自己的思考和标记。
3. 智能问答模块优化
- 提示词优化:之前回答质量不稳定,尤其是要求“基于知识库回答、不要编造”时,模型偶尔会“自由发挥”。我重新设计了系统提示词,明确了角色定位、回答规范、引用要求和拒绝回答的边界条件,对话顺畅度明显提升
- 模型升级:从qwen2.5:1.5b升级到qwen2.5:7b。1.5b模型适合快速测试,但回答质量和上下文理解能力有限;7b模型在语义理解、逻辑推理和中文表达上都明显更强,虽然推理速度慢了一些,但实际使用体验好很多
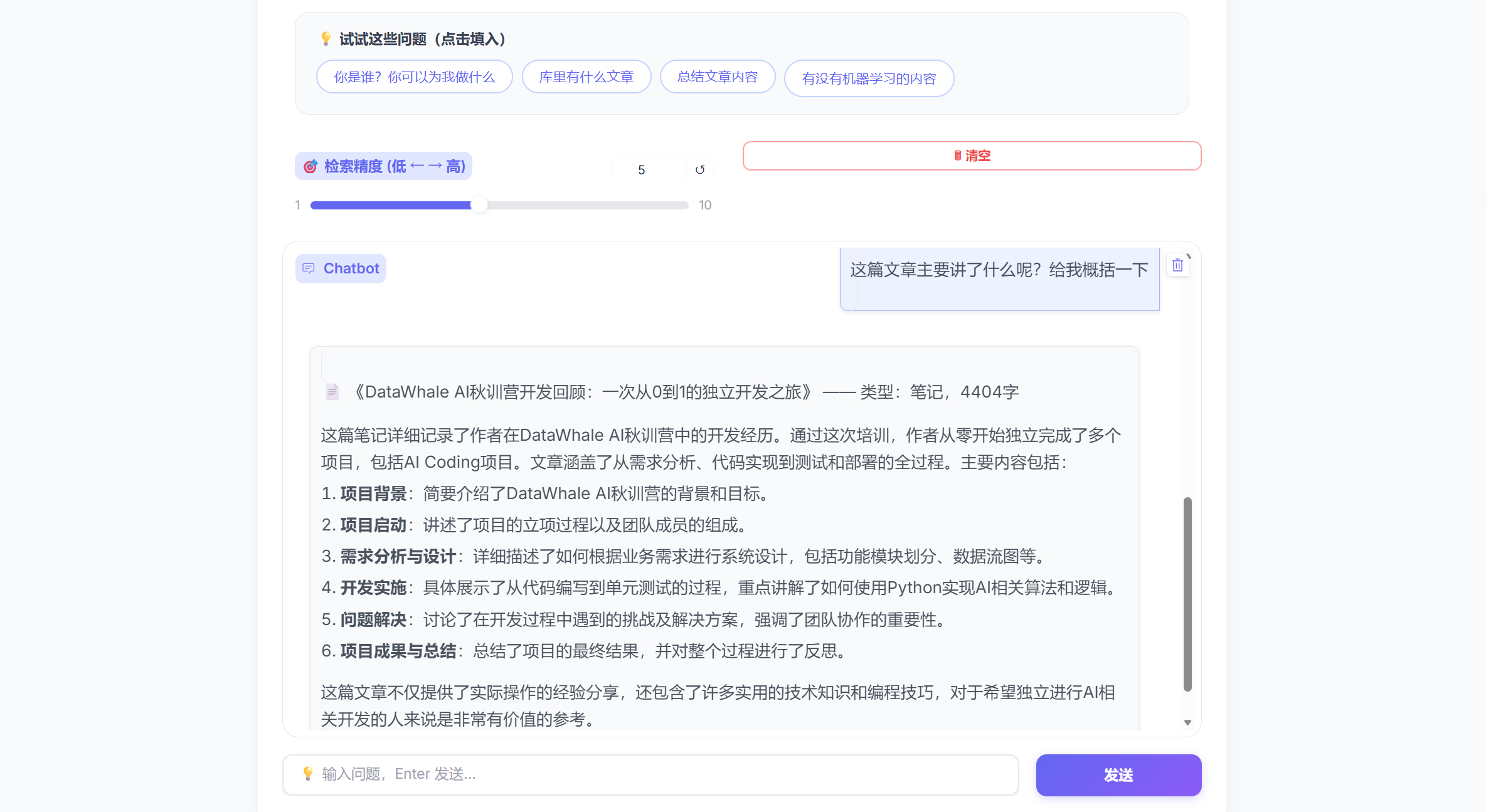
智能问答界面
体感:模型的选择直接影响产品的“能力”。1.5b像是和一个不太聪明的机器对话,7b则更像一个真正理解你问题的助手;而对于知识库问答场景,模型能力也是体验的重要影响。
二、Linku灵库项目现状
一句话定位:Linku是一个运行在你电脑上的个人知识库助手——收藏文章、智能问答、永不遗忘。
项目核心价值之 痛点&Linku的解决方案 :
- 收藏几百篇文章,从不回头看 & AI帮你记住,你只管提问
- 想找之前看过的一篇文章,只记得大概内容 & 用自然语言搜索
- 文章太长不想读 & AI帮你总结核心观点
- 担心数据上传云端泄露隐私 & 完全本地运行,数据不出你的电脑
功能亮点:
- 导入知识:支持PDF、Markdown、TXT、网页链接抓取、手动粘贴文本
- 智能问答:自然语言提问,AI基于知识库回答,附带来源引用,流式输出
- 文档管理:查看、搜索、删除文档,查看导入状态和分块统计
- 文章阅读器:优雅渲染文档内容
- 批注/笔记/标签:在阅读过程中留下自己的思考和标记
技术栈:FastAPI + ChromaDB + Ollama + Gradio
项目状态:MVP已完成,可正常使用;本次迭代后UI更友好、功能更完整、问答质量明显提升
三、这一阶段的核心收获
1. “需求→提示词→代码→运行→修改”闭环的真实体感
书中第三章强调的五个步骤,在实际迭代中感受非常真切。以“增加批注功能”为例:
- 需求:我想在阅读文章时可以选中一段文字添加标注
- 提示词:描述清楚标注的形式(加粗/荧光笔/下划线)
- 代码:AI生成基础实现,我根据项目架构进行调整
- 运行:测试发现批注没有正确关联到段落位置
- 修改:补充段落索引的逻辑,重新生成并集成
这个闭环跑了不止一轮,有的时候没显现有的时候漏了效果,每一次循环都在逼近“理想实现”。AI编程确实不是一次生成就结束了,而是持续对话、持续迭代的过程。
2. 结构化提示词的边界和灵活性
上一阶段我学会了“写结构化提示词”,这一阶段我发现:提示词不是死的模板,而是要根据任务类型灵活调整。
对于UI调整类任务(如“把按钮颜色改成蓝色”),提示词可以很简洁;对于功能新增类任务(如“增加标注功能),需要详细描述数据结构、交互流程、前后端接口;对于Bug修复类任务(如“问答输出不流畅”),需要提供错误现象、日志信息、期望行为
实现关键是:你要清楚自己想让AI做什么,以及AI需要哪些信息才能做好。
3. 模型升级带来的体验跃升
从1.5b到7b,不只是参数量的变化,更是产品“可用性”的质变。1.5b版本的问答经常答非所问,或者明明是知识库里有答案却回答“不知道”;7b版本明显更能理解问题意图,回答也更贴合知识库内容。
这让我意识到:在RAG应用中,检索质量和生成模型能力是两条腿,缺一条都走不远。之前我花了很多时间优化分块和检索,但模型能力本身就是天花板。升级模型后,同样的知识库、同样的检索结果,回答质量上了一个台阶。
4. 从“能跑”到“好用”是一个系统工程
MVP阶段的目标是“让它能跑起来”,这一阶段的目标是“让它好用起来”。两者之间的差距体现在很多细节上:界面是否直观?用户需不需要看教程就知道怎么用?交互是否流畅?还是卡顿、反馈不明确?回答质量是否稳定?还是偶尔“抽风”?
这些都不是“加一个功能”就能解决的,而需要持续的打磨和测试:AI辅助编程可以加速功能实现,但产品体验的打磨仍然需要人的判断和耐心。
四、下一步计划
Linku不止步于此,会继续与广大用户链接,探寻更广的能力,或许未来的我们会这样:
- 检索质量优化:调整分块策略和embedding模型,提高检索准确率
- 推广应用:探索浏览器插件、移动端应用形式,拓宽未来场景
- 网页剪藏优化:更好地处理不同网站的正文提取
- 性能优化:大模型推理速度和检索延迟还有优化空间
写在最后
这一阶段的学习让我对AI Coding有了更深入的理解。如果说Task2是“学会和AI对话”,那么Task3就是“学会和AI一起做产品”。To Do List也好,Linku也罢,项目本身不是目的,真正有价值的是在这个过程中建立的工作流和思维方式:
- 把模糊的想法变成结构化的提示词
- 在“生成—运行—发现问题—修正”的闭环中快速迭代
- 理解AI的能力边界,知道什么时候该用AI、什么时候该自己写
- 不盲信生成结果,始终保持对代码和产品的判断力
Linku灵库还在路上,还会继续迭代。
但经过这一阶段,我对“如何用AI辅助做一个真正的产品”有了更清晰的地图。如果你也在做个人知识库相关的东西,或者对AI辅助编程感兴趣,欢迎交流~封面由AI辅助生成~

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)