
11.LangChain框架3-模型(model)五种调用大模型的方式(在线模型和本地模型).
LangChain 大模型 API
内容参考于:图灵AI大模型全栈
LangChain支持三种模型:大语言模型、聊天模型、文本嵌入模型(向量模型)
大语言模型:纯文本生成的就是大语言模型
聊天模型:向chatGPT、Deepseek、豆包就是聊天模型,就是说带chat的就是聊天模型不带chat的就是大语言模型
文本嵌入模型:用于转换成向量的模型
之前我们都是使用的opanAI调用的大模型,除了使用opanAI还可以使用langchain的模型
from langchain.chat_models import init_chat_modellangchain官网:
官⽅⽂档:https://reference.langchain.com/python/langchain/
中文文档: https://langchain.ichuangpai.com/
如下图Langchain的模型,注意网页的页面可能会有改动,这里只能是做参考,具体以官网为准
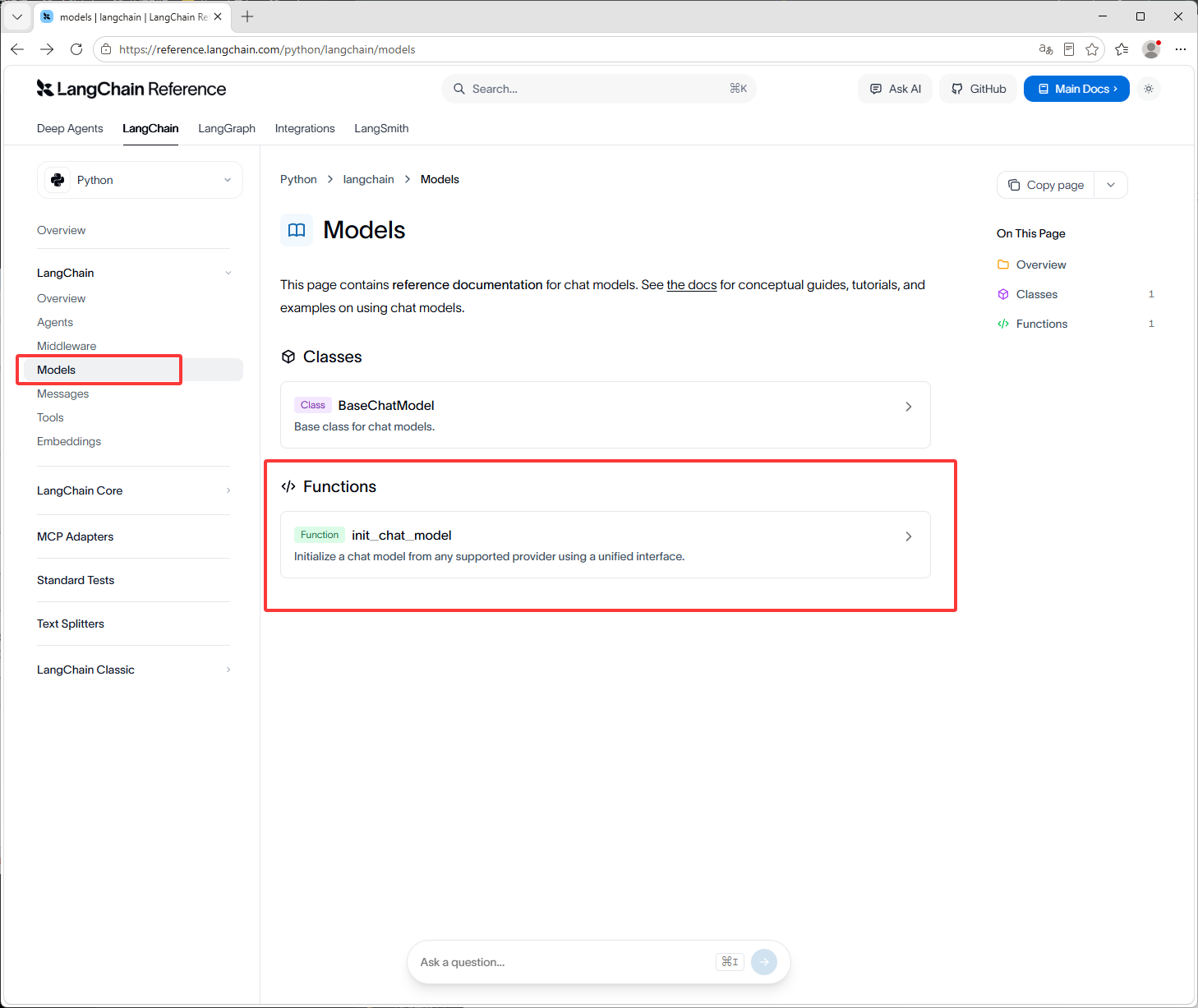
如下图它的导入模型的方式
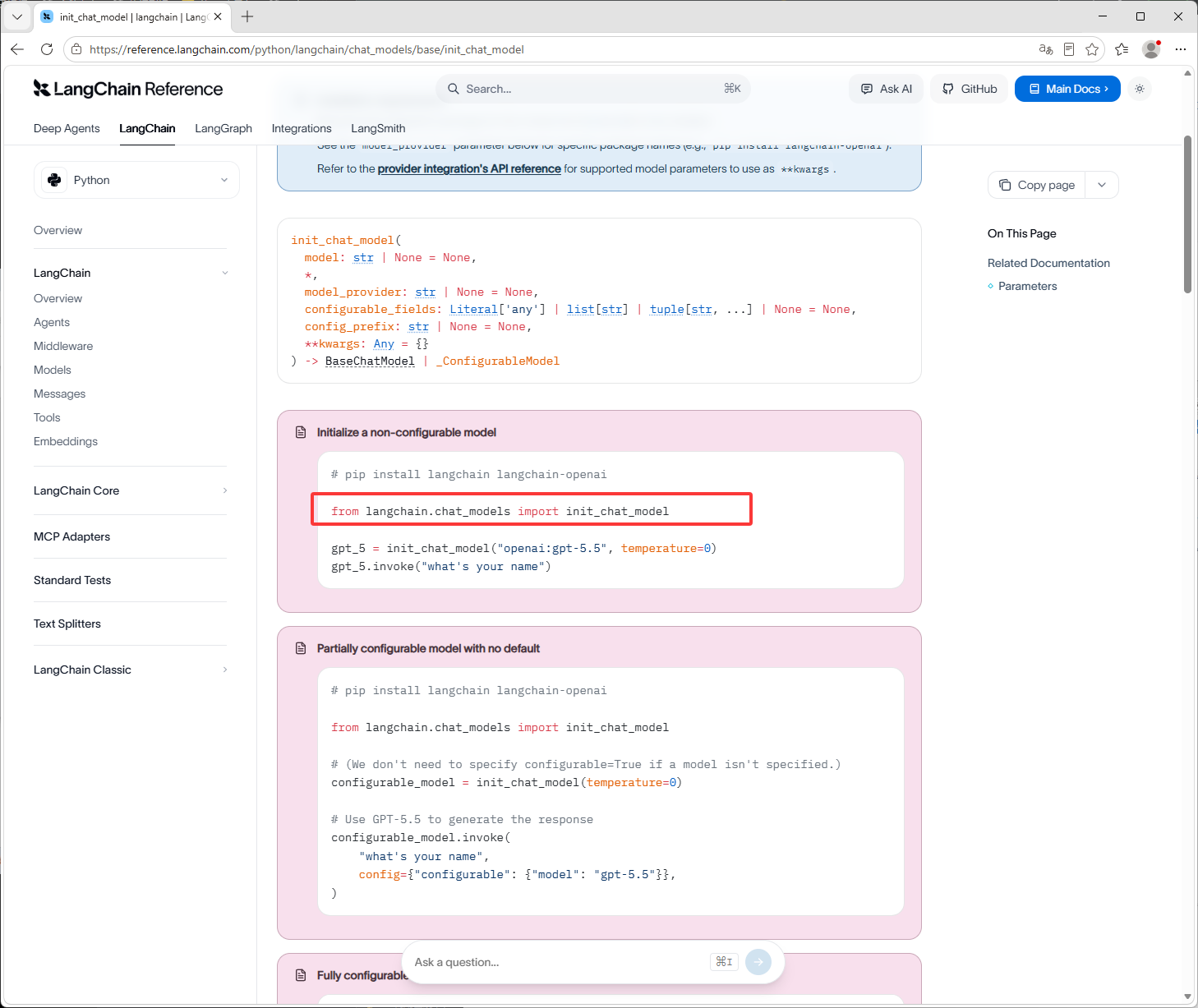
还有一种是厂商提供的SDK
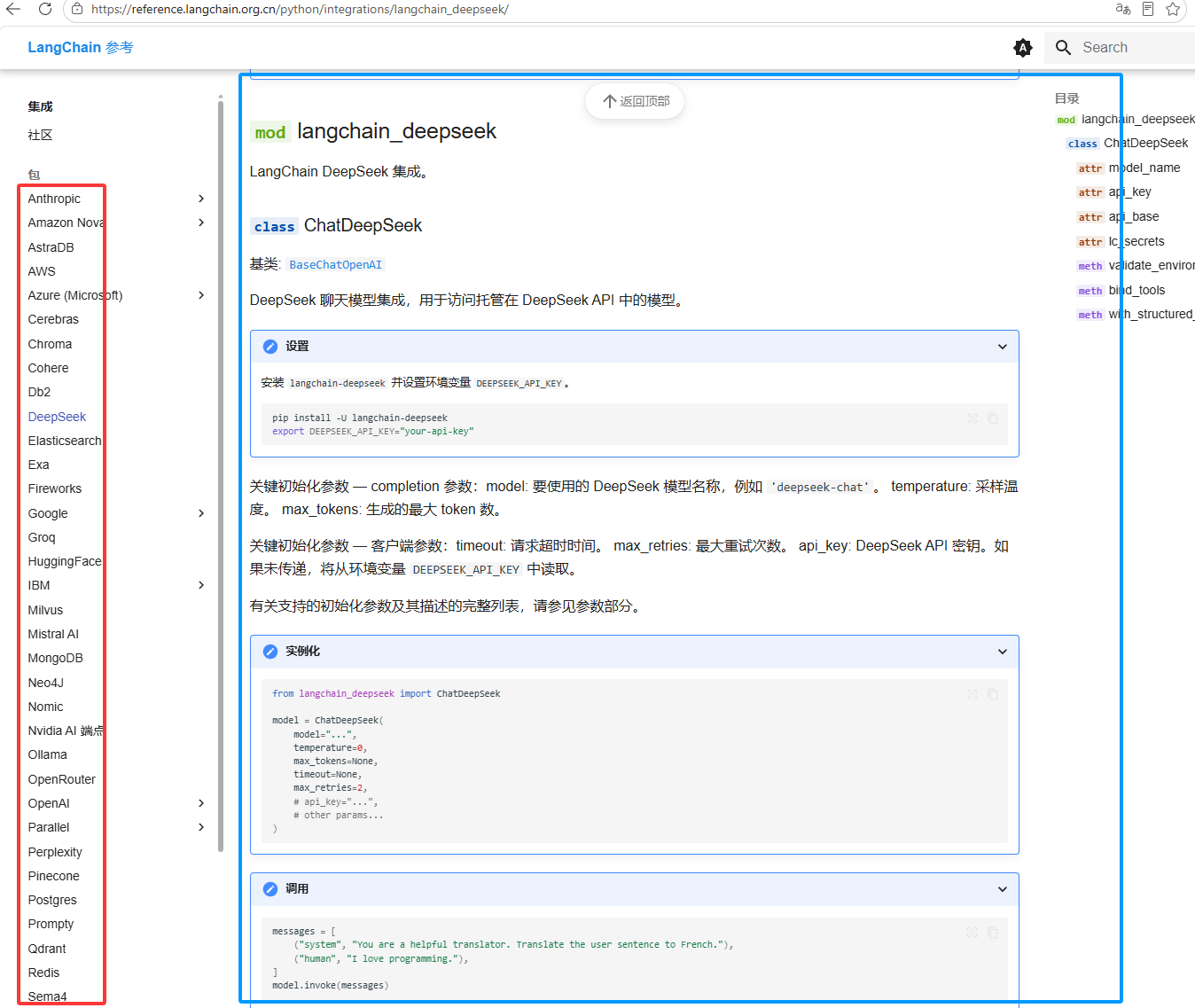
型厂商自己封装的模型调用方法,SDK调用方式,这个链接里国内只有DeepSeek的,其它的大模型去它们的官网里找SDK方式调用相关,如果找不到就说明没有
https://reference.langchain.org.cn/python/integrations/langchain_deepseek/
根据下图红框找厂商,然后根据下图蓝框找调用方式
下图是百炼平台自己提供的LangChain的SDK,它在LangChain的社区库中
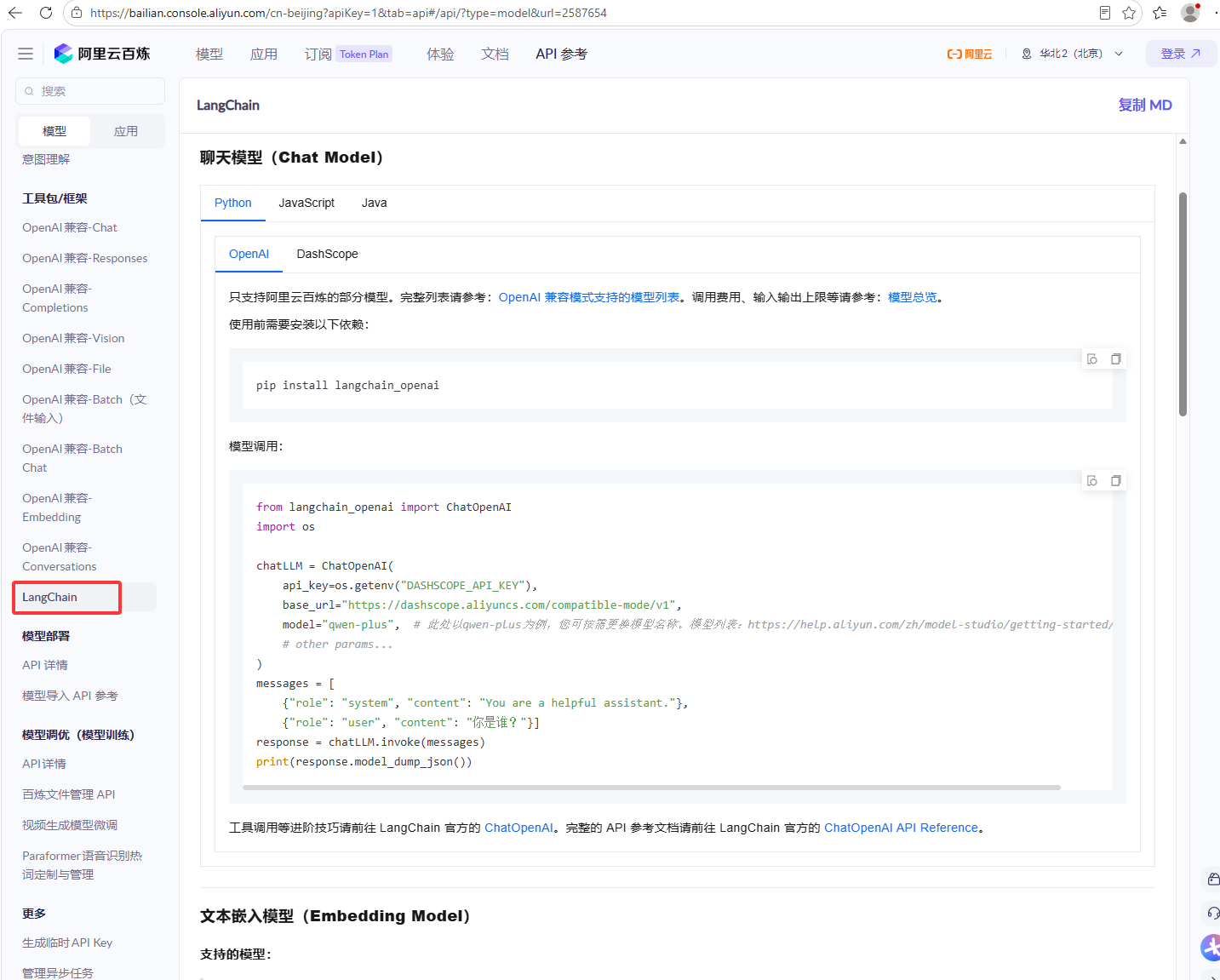
然后点击下图红框
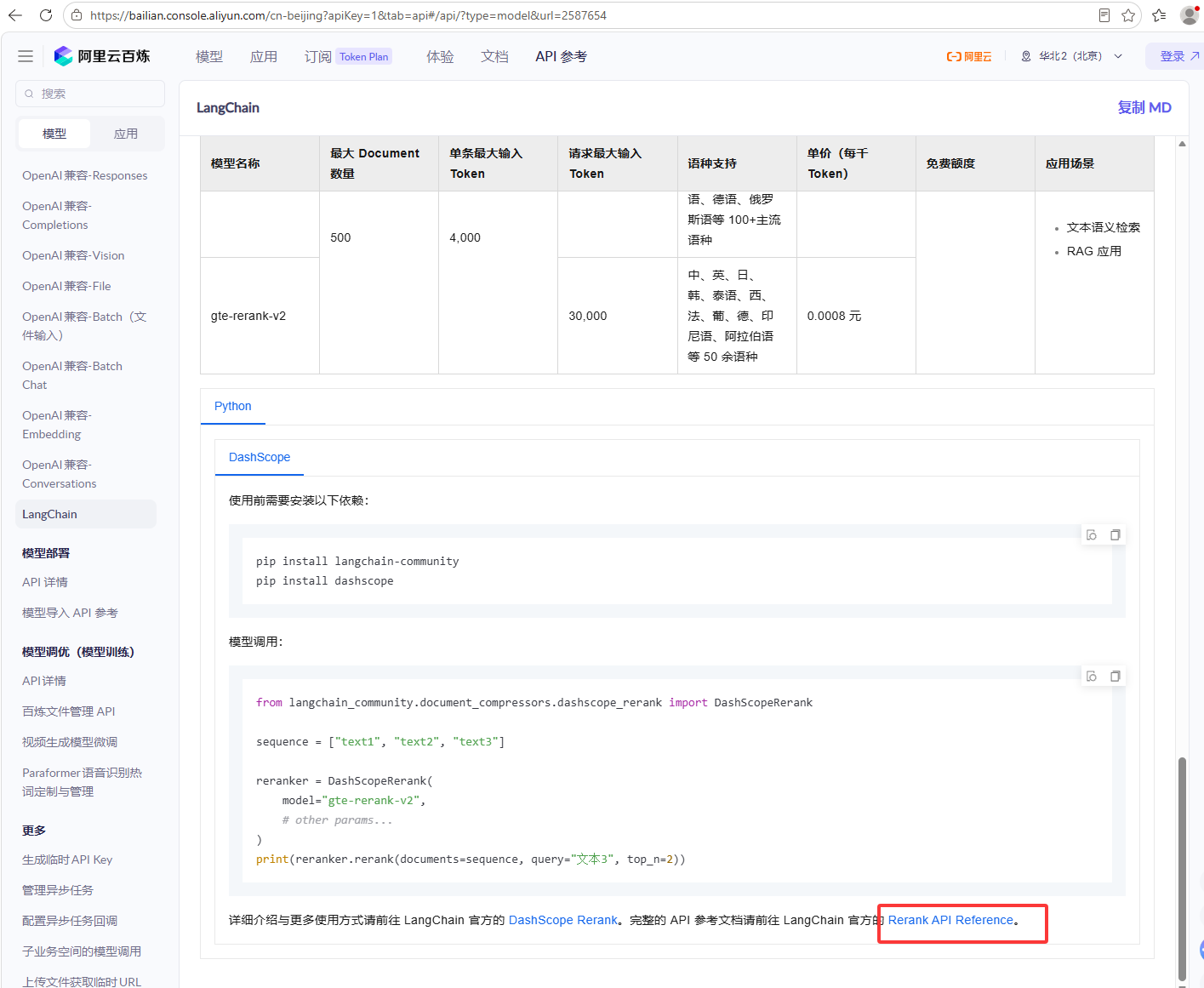
然后点击下图红框
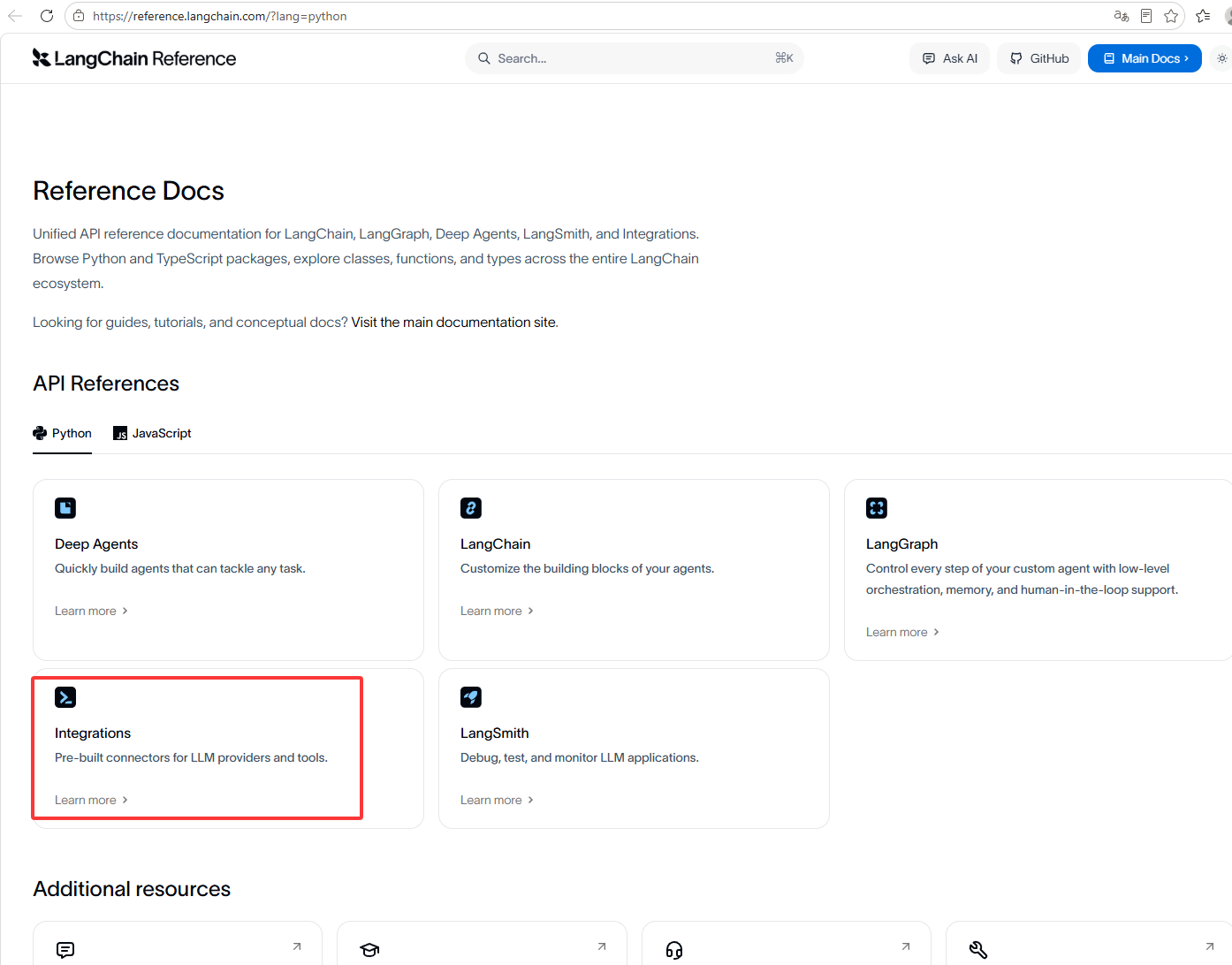
然后点击下图红框
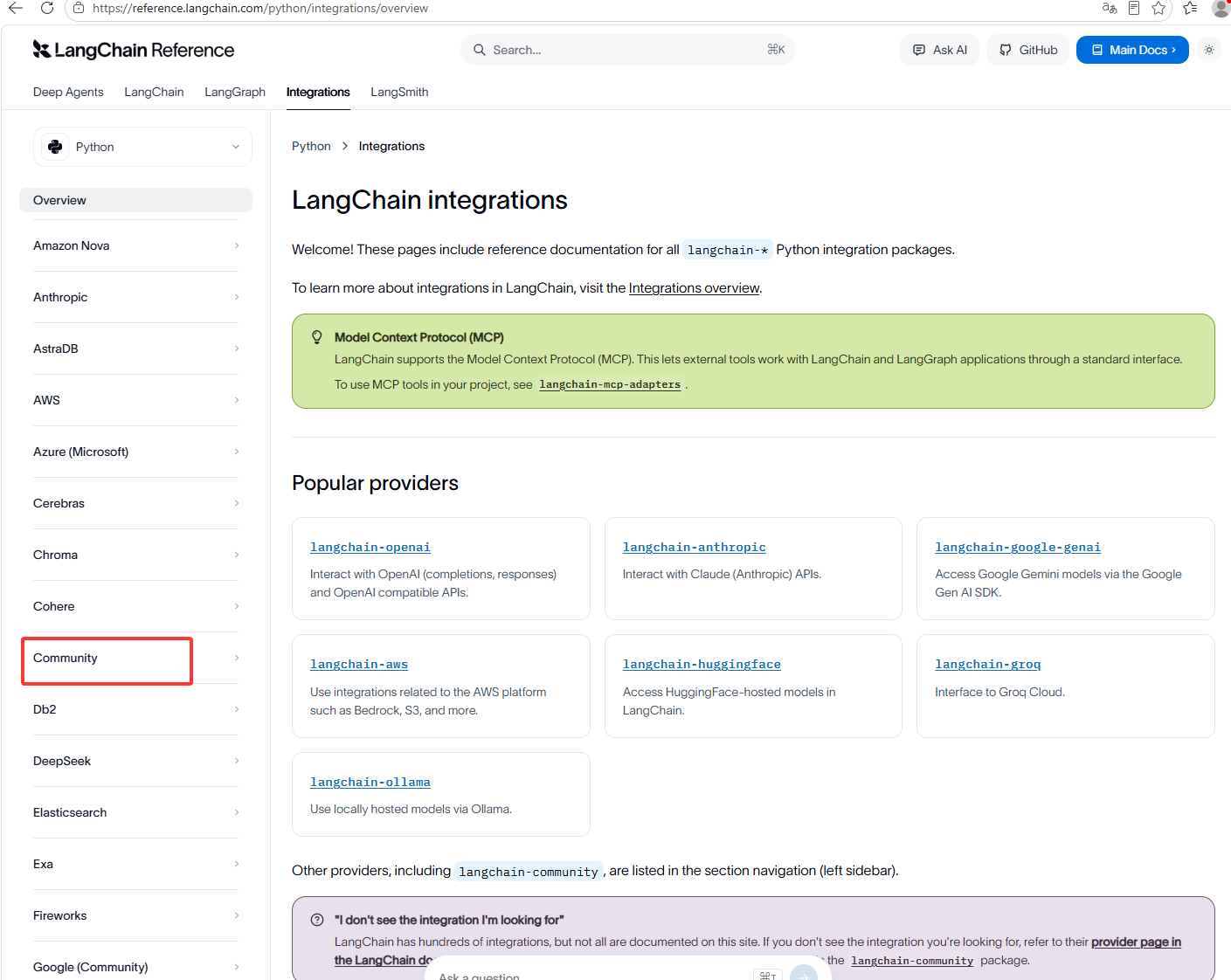
如下图红框就可以看到阿里的大语言模型了,也就是通义
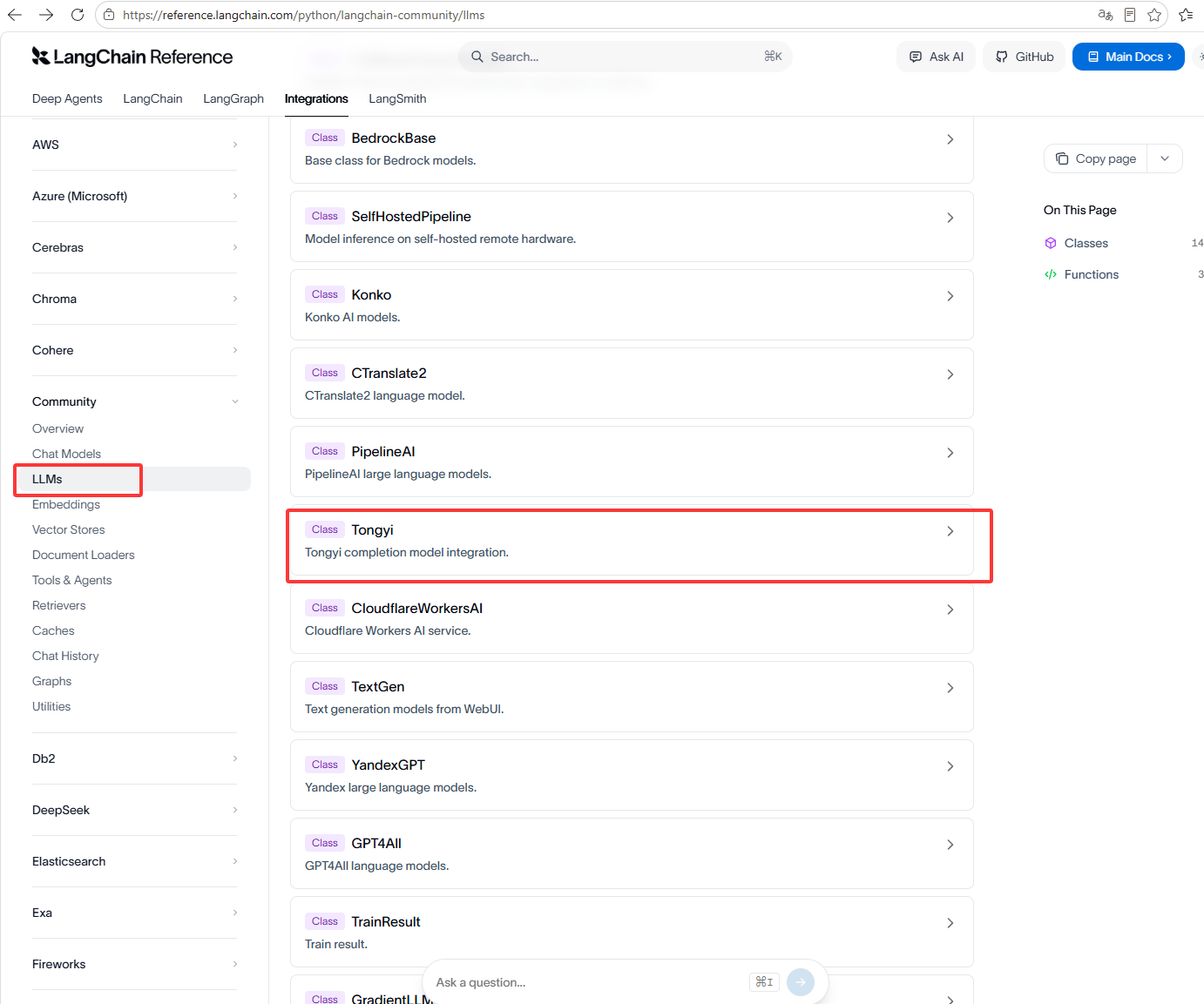
LangChain是国外的所以我们国内的一些模型它不支持导入,它支持DeepSeek,这里就用DeepSeek作为示例
来的DeepSeek官网,点击下图红框
然后点击接口文档
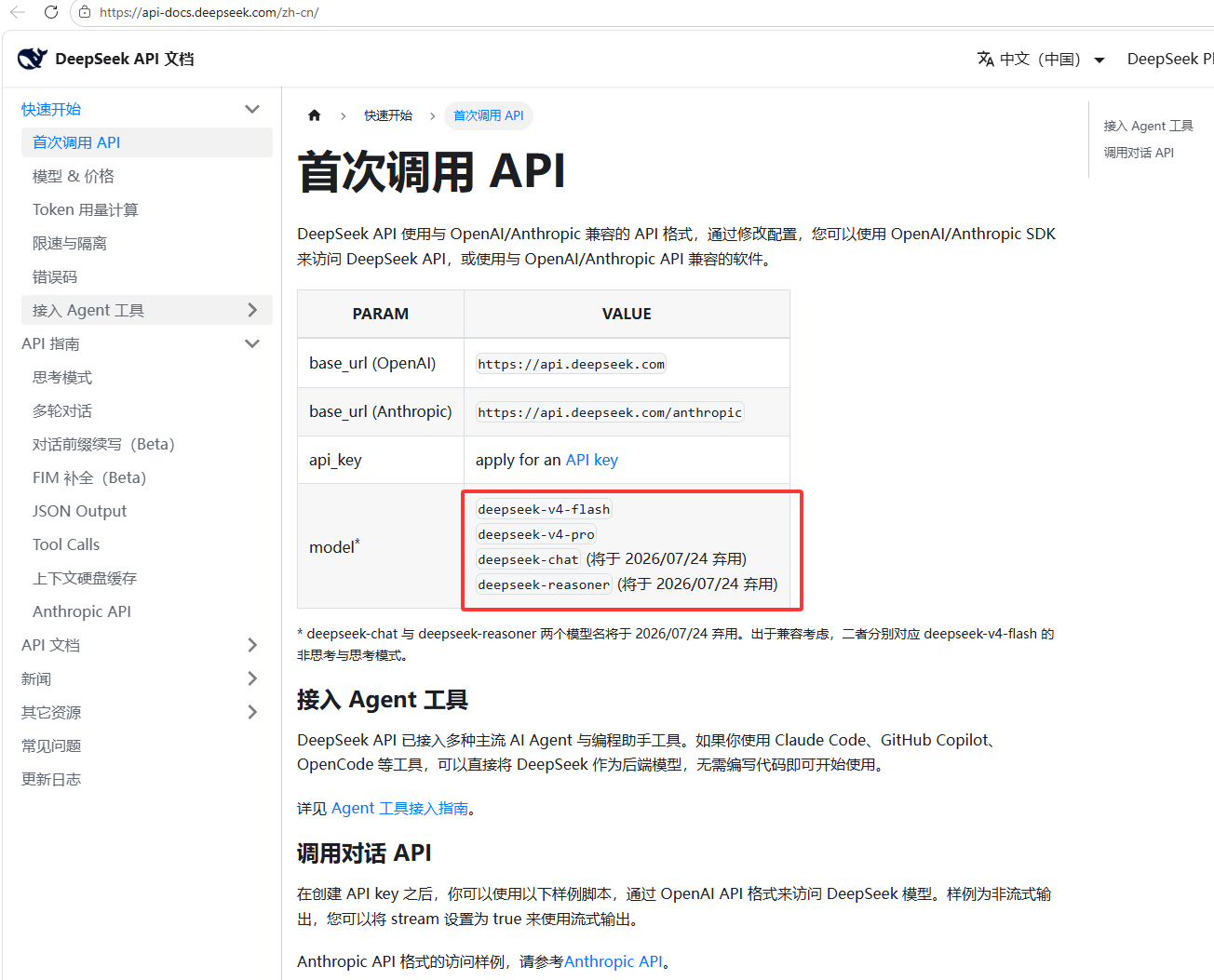
然后如下图红框,可以看到模型名和api请求链接
然后下图红框DeepSeek发布的这些模型,可以直接调用
开始调用,LangChain有三种调用模型的方式,下方是区别
效果图:init_chat_model方式调用如下图红框它是有返回思考过程的
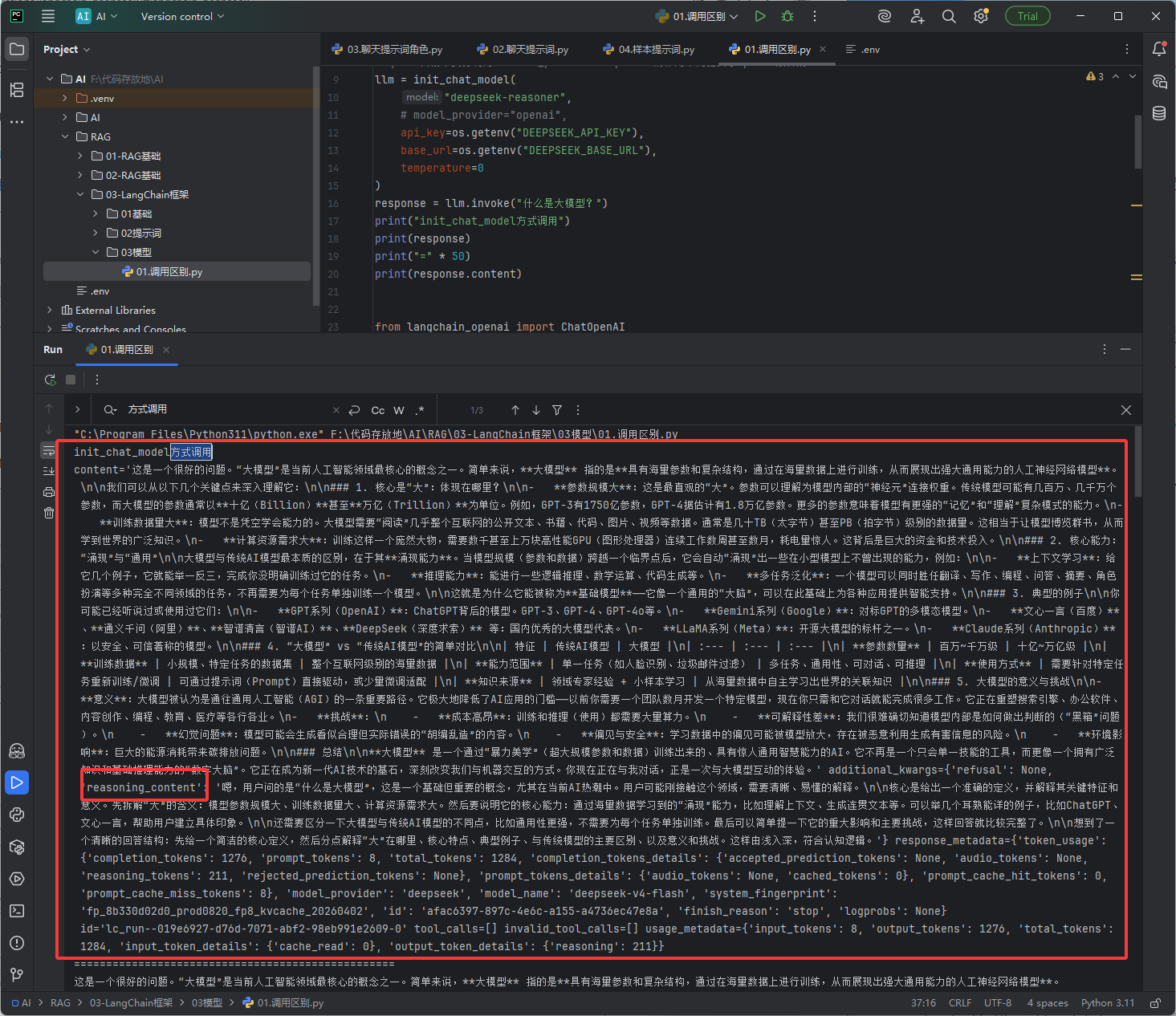
效果图:OpenAI方式,它没有思考过程,它只是不返回思考过程,但是它还是会思考
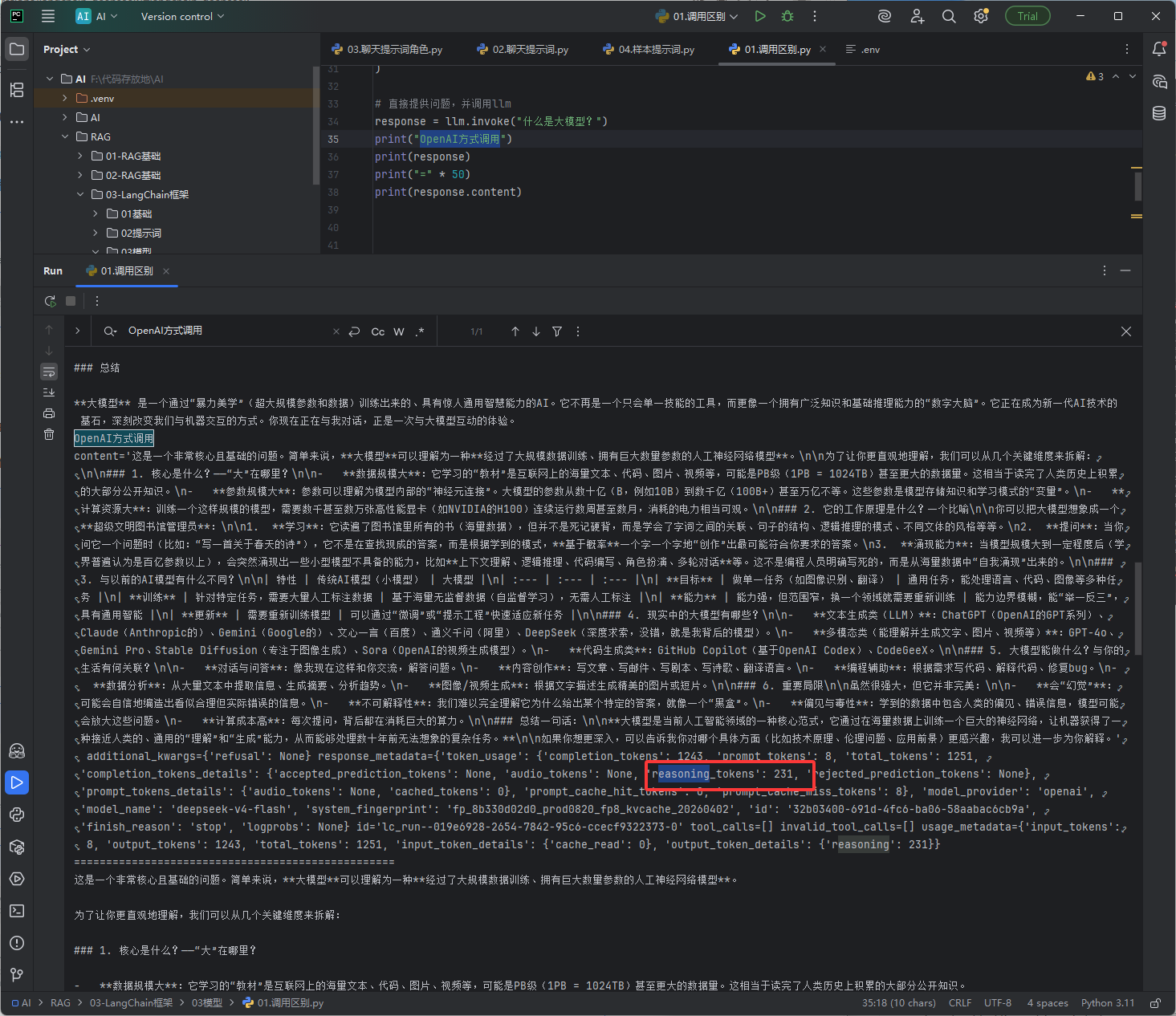
效果图: 厂商SDK方式,它也是有思考过程的
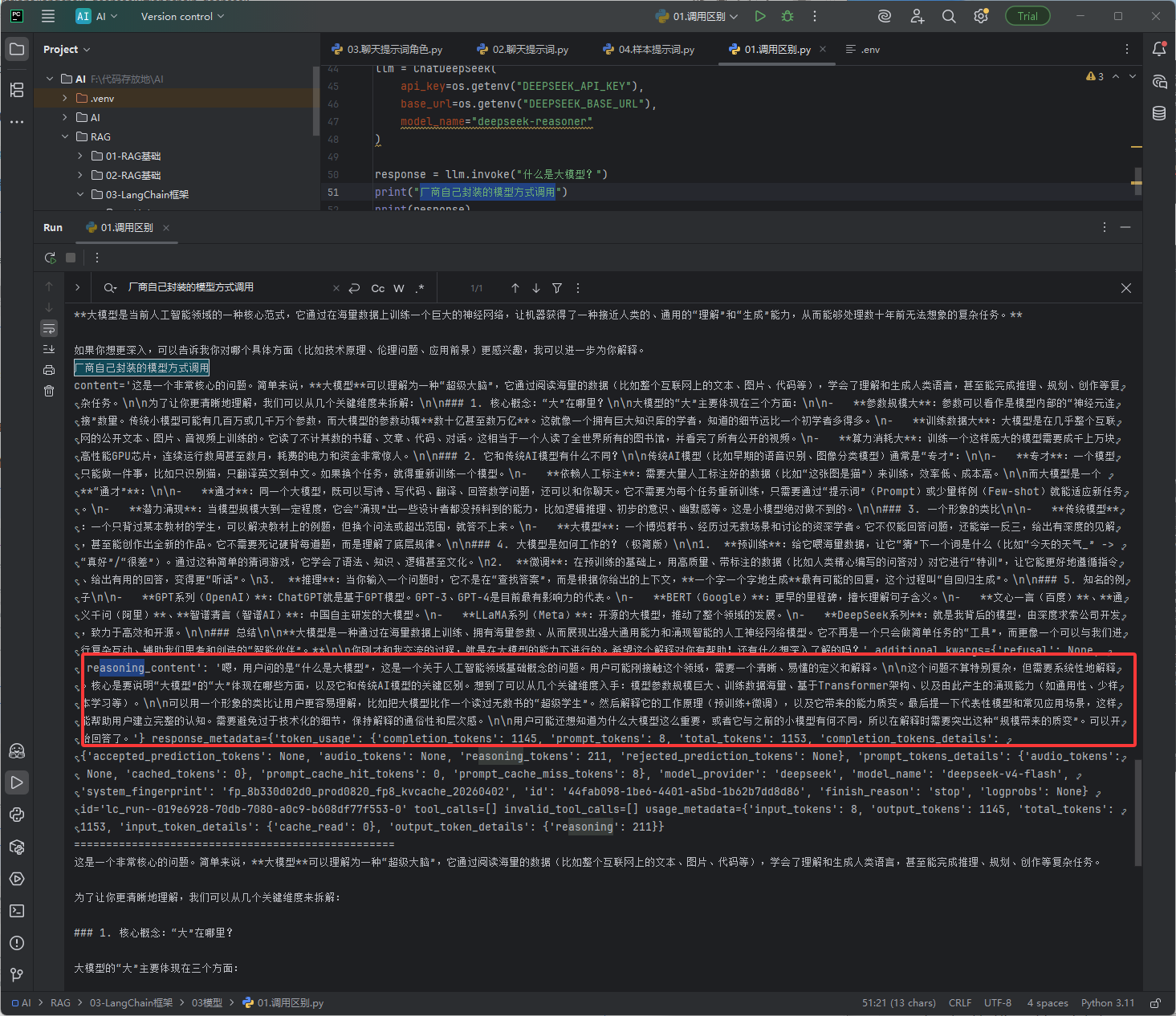
三种调用模型的区别
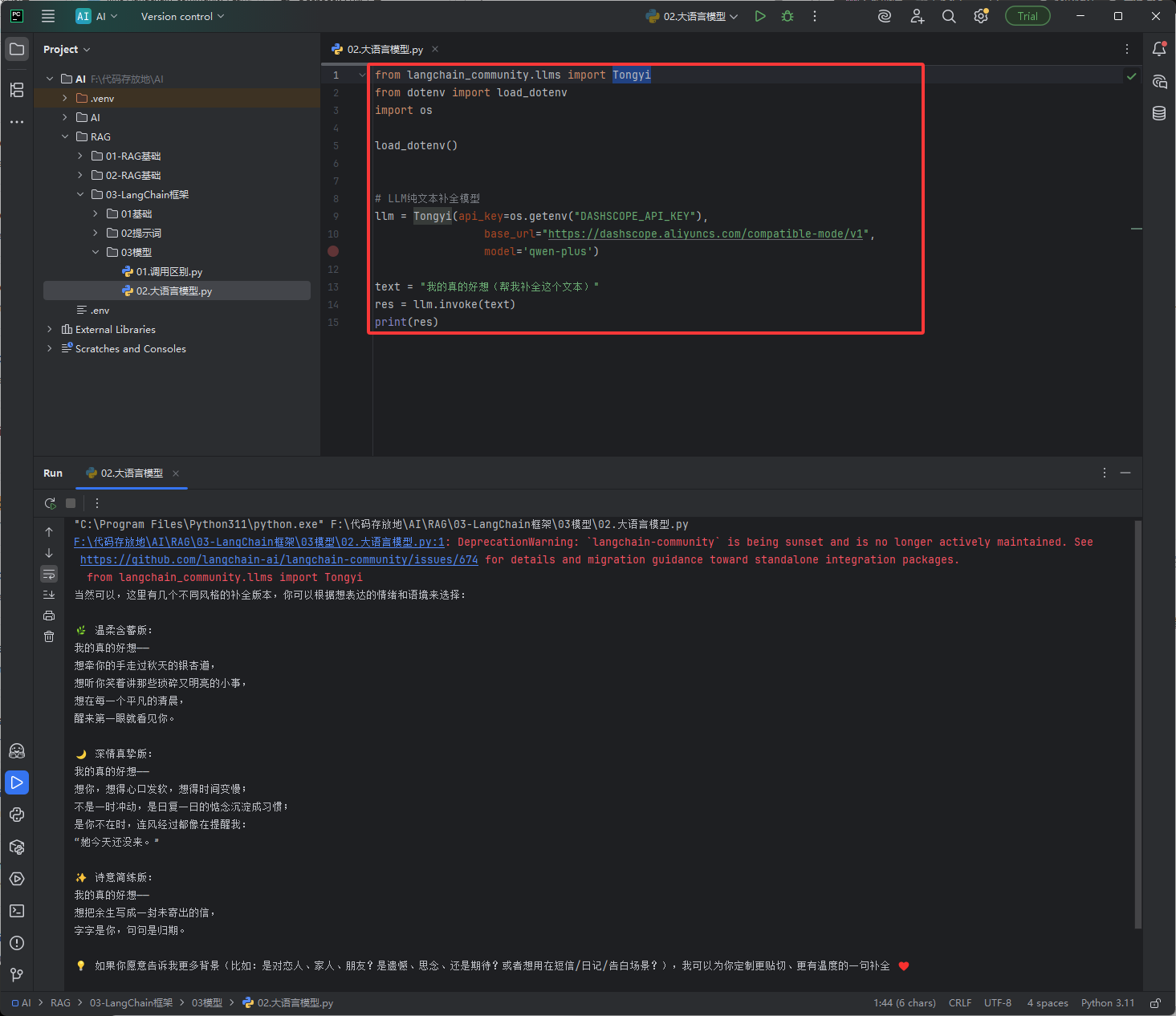
# 导入系统环境变量工具,读取.env文件配置 import os # 导入加载.env配置文件的工具(存放API密钥、接口地址) from dotenv import load_dotenv # 导入LangChain官方统一封装的 模型初始化方法(通用版) from langchain.chat_models import init_chat_model # 加载项目根目录的.env文件,读取密钥和配置 load_dotenv() # ====================== 方式1:LangChain统一封装方法 init_chat_model ====================== # langchain自己封装的模型调用方法 # qwen 目前不支持调用 model_provider="openai"的作用:千问提供了OpenAI兼容的API # 作用:LangChain官方通用初始化函数,支持所有主流大模型,无需记不同厂商的类名 llm = init_chat_model( "deepseek-reasoner", # 模型名称(必填):要调用的深度求索模型名 # model_provider="openai", # 模型提供商:指定协议类型,openai代表兼容OpenAI格式 api_key=os.getenv("DEEPSEEK_API_KEY"), # 模型API密钥(从.env读取) base_url=os.getenv("DEEPSEEK_BASE_URL"),# 模型接口地址(从.env读取) temperature=0 # 温度参数:0=回答最严谨、固定;1=最随机、有创意 ) # 调用模型,传入问题 response = llm.invoke("什么是大模型?") # 打印调用方式标识 print("init_chat_model方式调用") # 打印模型完整返回结果(包含元数据、内容、角色等所有信息) print(response) print("=" * 50) # 只打印模型返回的纯文本回答(最常用) print(response.content) # ====================== 方式2:通用OpenAI兼容接口 ChatOpenAI ====================== from langchain_openai import ChatOpenAI # 通过langchain_openai调用千问模型 # 市面模型兼容OpenAI能让开发者无缝切换 # 作用:标准OpenAI协议调用类,**所有支持OpenAI格式的模型都能用**(通义千问、DeepSeek、火山方舟等) llm = ChatOpenAI( api_key=os.getenv("DEEPSEEK_API_KEY"), # 模型密钥 base_url=os.getenv("DEEPSEEK_BASE_URL"), # 模型接口地址 model_name="deepseek-reasoner" # 模型名称 ) # 直接提供问题,并调用llm response = llm.invoke("什么是大模型?") print("OpenAI方式调用") print(response) print("=" * 50) print(response.content) # ====================== 方式3:模型厂商官方专用封装 ChatDeepSeek ====================== # 用模型厂商自己封装的模型调用方法的优势, 调用返回的结果会更加细腻 from langchain_deepseek import ChatDeepSeek # 作用:DeepSeek官方为LangChain定制的调用类,**专属优化**,最贴合模型特性 llm = ChatDeepSeek( api_key=os.getenv("DEEPSEEK_API_KEY"), base_url=os.getenv("DEEPSEEK_BASE_URL"), model_name="deepseek-reasoner" ) # 调用模型 response = llm.invoke("什么是大模型?") print("厂商自己封装的模型方式调用") print(response) print("=" * 50) print(response.content)还有一种就是,上方写了,如果链接里没有就去官网里找SDK,这种调用是在LangChain的社区库里,如下图,通过from langchain_community.llms import Tongyi引入Tongyi的大语言模型也就是llms
现在知道了四种调用模型的方式(init_chat_model官网提供、OpenAI、langchain_deepseek厂商自己提供、llms 社区提供),接下来开始整体,也就是大语言模型、聊天模型、文本嵌入模型
大语言模型
可以看到给invoke的入参只有一个字符串(文字),然后大模型给我们返回文本
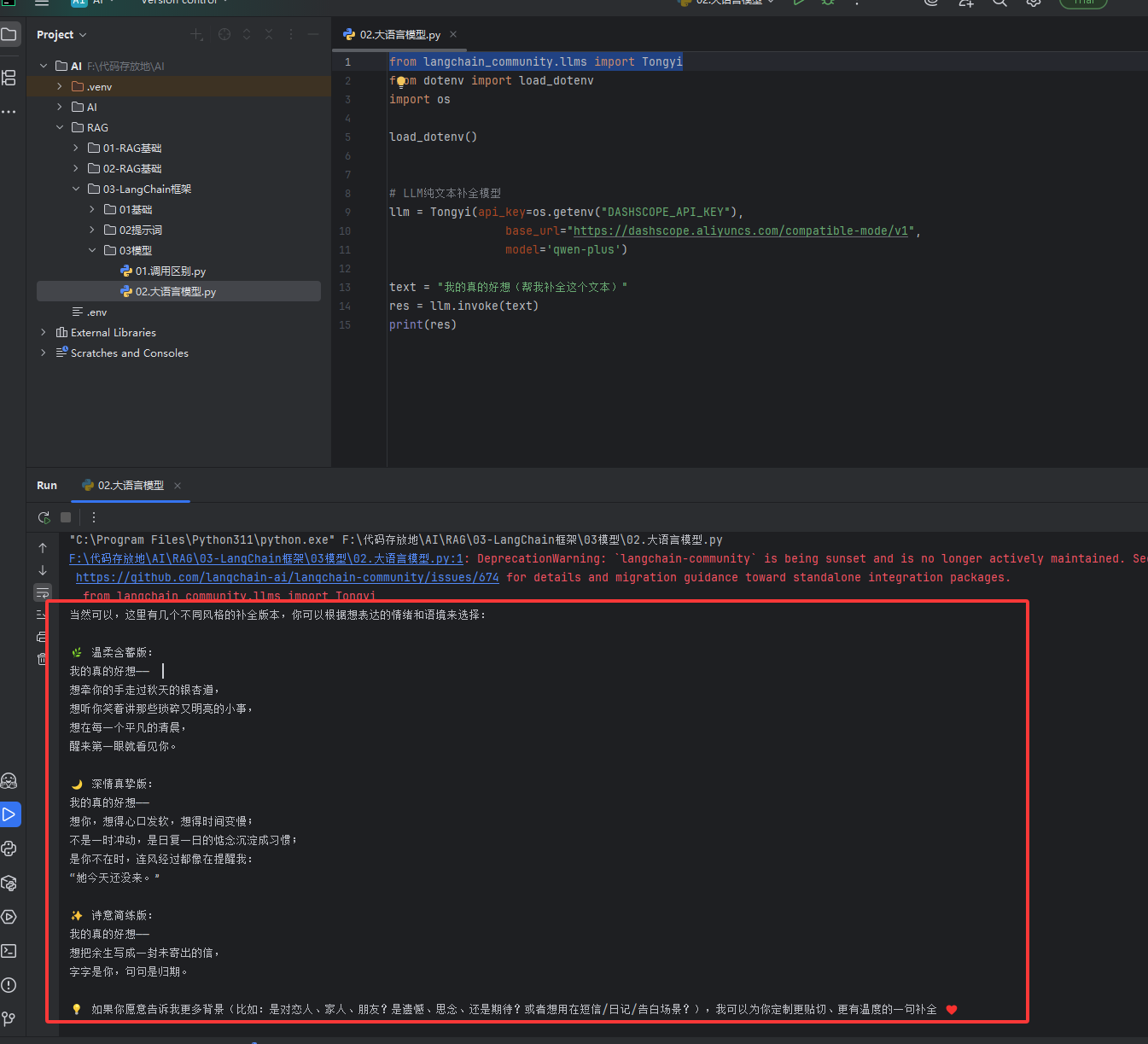
注意下图的from langchain_community.llms import Tongyi里的Tongyi是在上方的官网文档中找到的,Tongyi就是class
# 导入LangChain社区版的 通义千问(阿里) 纯文本大模型接口 # 注意:这是【纯文本补全模型】,不是聊天模型,专门用来续写、补全文字 from langchain_community.llms import Tongyi # 导入加载.env配置文件的工具(读取API密钥) from dotenv import load_dotenv # 导入系统环境变量工具 import os # 加载项目根目录的.env文件,获取阿里云通义千问的API密钥 load_dotenv() # ====================== 初始化通义千问 纯文本补全模型 ====================== # LLM纯文本补全模型:核心功能是【文字续写、补全】,和聊天模型功能不同 llm = Tongyi( # 【必填】API密钥:从.env文件读取阿里云通义千问的密钥 api_key=os.getenv("DASHSCOPE_API_KEY"), # 【必填】接口地址:阿里云通义千问兼容模式的固定接口地址 base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 【必填】模型名称:指定使用的通义千问具体模型版本 model='qwen-plus-2025-07-28' ) # 定义需要补全的文本(给模型一个开头,让模型续写后面的内容) text = "我的真的好想(帮我补全这个文本)" # 调用模型的invoke方法,传入待补全的文本,执行补全/续写 res = llm.invoke(text) # 打印模型返回的补全结果 print(res)
聊天模型
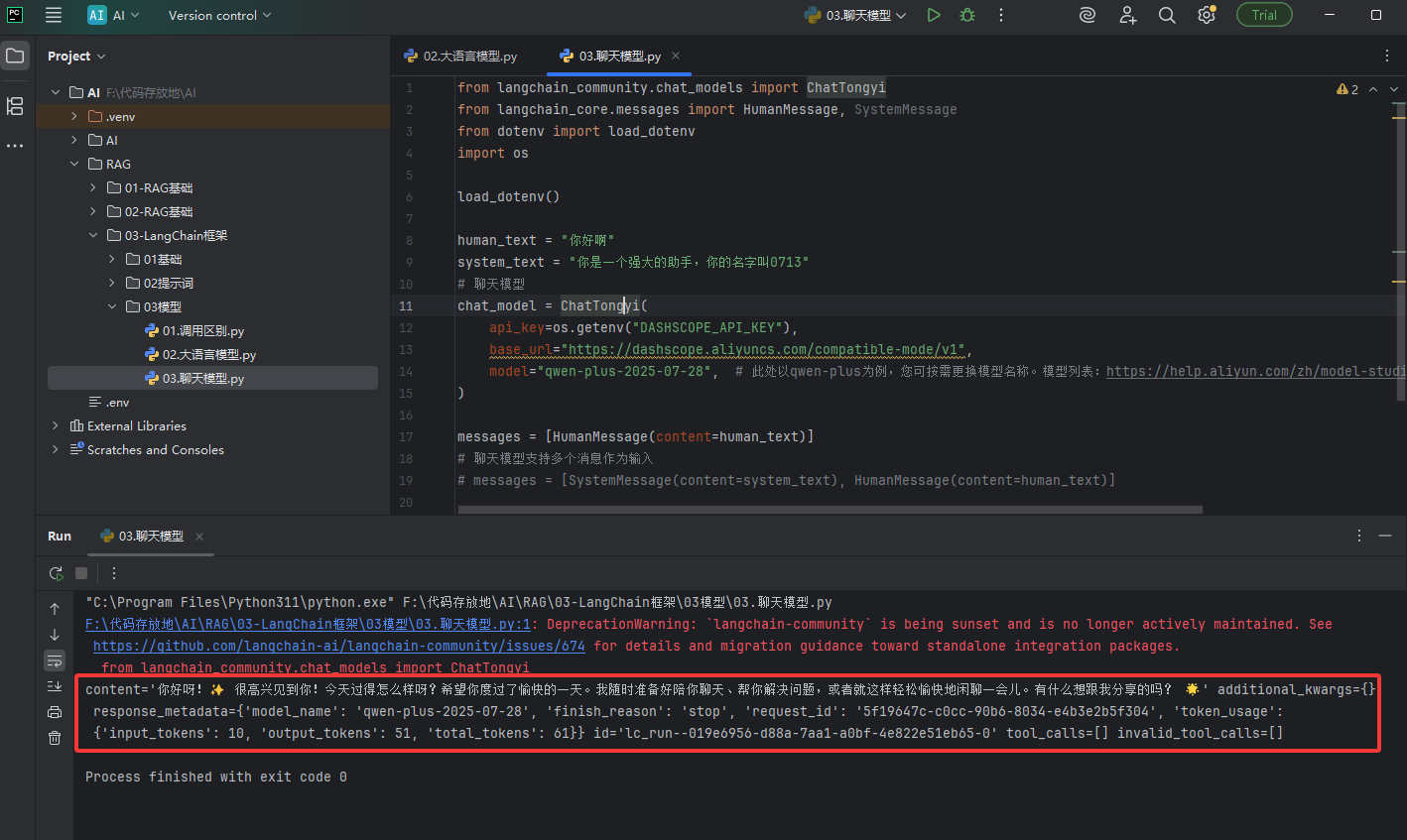
如下图它的返回值有包含了更多的信息,并不是只有简单的文本了
如下图红框,它可以传递多个参数,如果硬要把大语言模型搞成这样的也可以只是比较费劲,如下图几行代码就可以了,如果通过大预言模型你需要记录很多东西
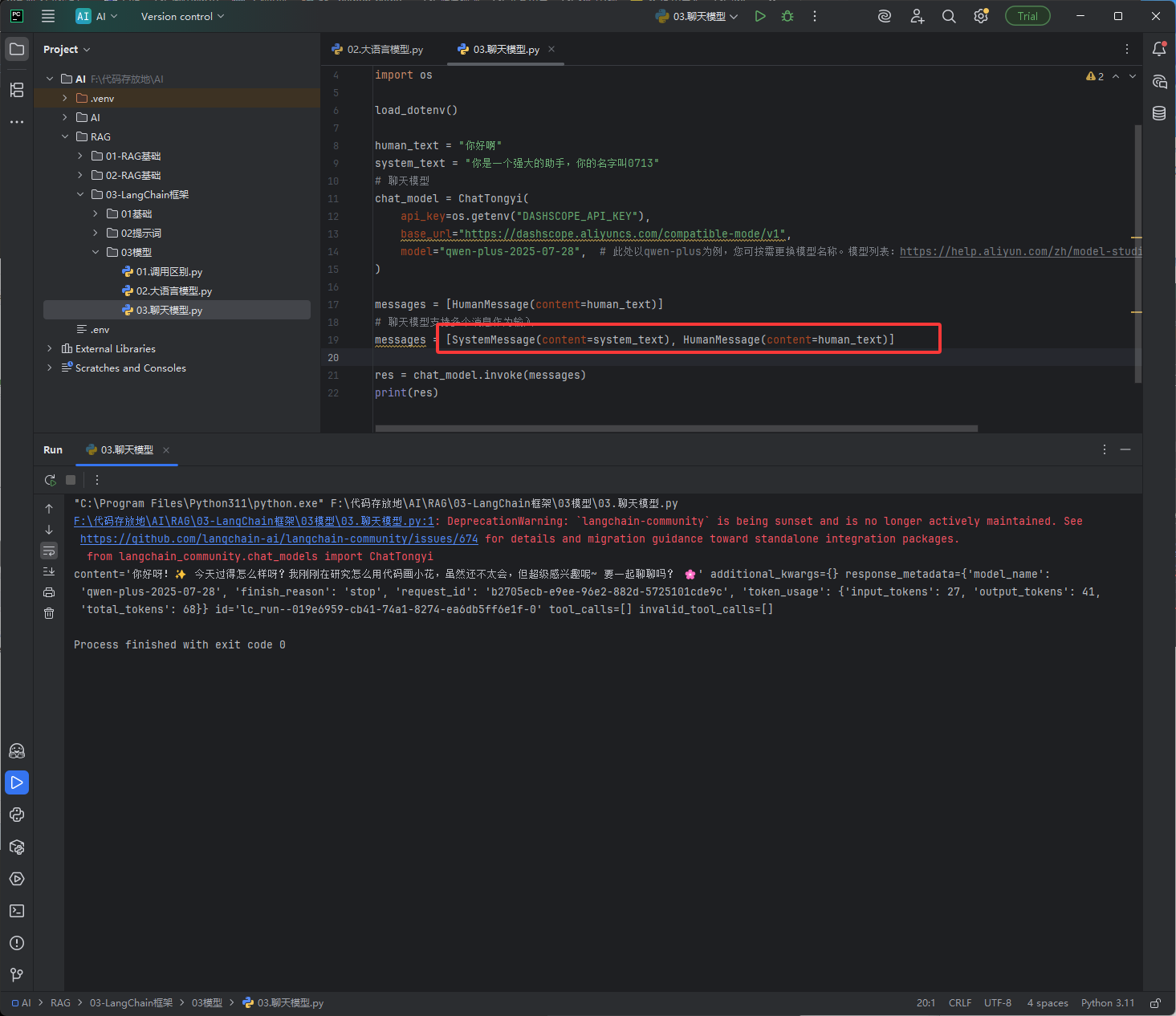
# 导入阿里通义千问的【聊天模型】(专门用于对话交互,区别于纯文本补全模型) from langchain_community.chat_models import ChatTongyi # 导入消息类:用户消息、系统消息(聊天模型专用的消息格式) from langchain_core.messages import HumanMessage, SystemMessage # 导入加载.env配置文件的工具 from dotenv import load_dotenv # 导入系统环境变量工具,读取API密钥 import os # 加载.env文件中的配置(通义千问API密钥) load_dotenv() # 定义用户输入的对话内容(用户对模型说的话) human_text = "你好啊" # 定义系统提示词:给模型设定身份、规则、名字 system_text = "你是一个强大的助手,你的名字叫0713" # ====================== 初始化通义千问 聊天模型 ====================== # 聊天模型:支持多轮对话、角色设定,是最常用的大模型交互方式 chat_model = ChatTongyi( # API密钥:从.env文件读取阿里云通义千问的密钥 api_key=os.getenv("DASHSCOPE_API_KEY"), # 接口地址:通义千问兼容模式的固定请求地址,无需修改 base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 模型名称:指定使用的通义千问模型版本,可在阿里云官网更换 model="qwen-plus-2025-07-28", ) # 写法1:仅发送用户消息(无角色设定) messages = [HumanMessage(content=human_text)] # 写法2:先发送系统消息(设定角色),再发送用户消息(推荐标准写法) messages = [SystemMessage(content=system_text), HumanMessage(content=human_text)] # 调用聊天模型,传入组装好的消息列表 res = chat_model.invoke(messages) # 打印模型完整返回结果(包含角色、内容、元数据等信息) print(res)
文本嵌入模型(向量模型)
如下图向量模型和上方大语言模型调用方式一样,只是名字不一样向量模型叫init_embeddings,大语言模型叫init_chat_model
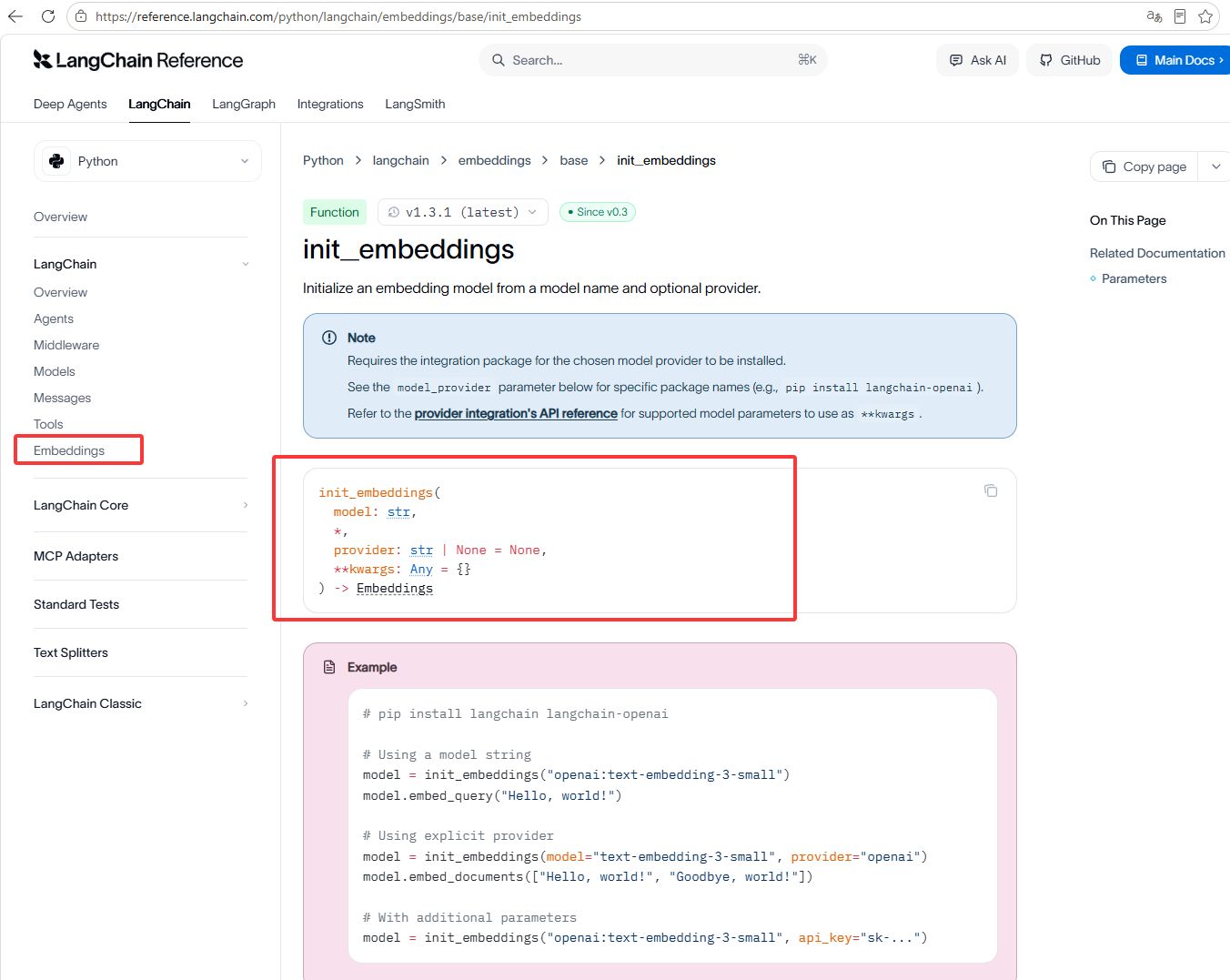
很遗憾它也对于国内的大模型支持的不多,这里使用社区提供的阿里千问,如下图是阿里的向量模型
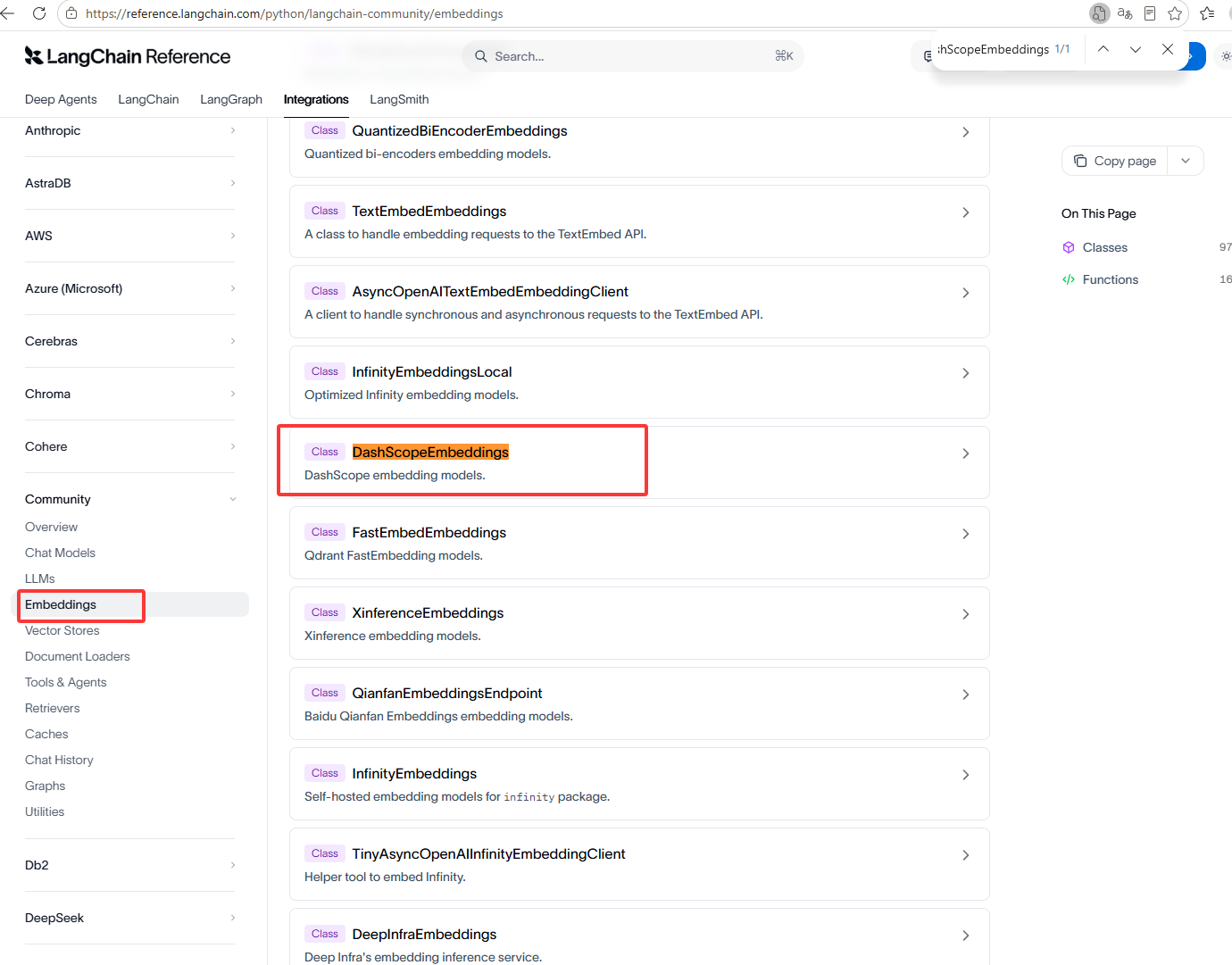
效果图:
# 导入系统环境变量工具,用于读取API密钥 import os # 导入阿里云通义千问的 文本向量嵌入模型(DashScope专属) # 作用:把文字转换成计算机能识别的数字向量(Embedding) from langchain_community.embeddings import DashScopeEmbeddings # 导入加载.env配置文件的工具 from dotenv import load_dotenv # 加载.env文件中的阿里云API密钥 load_dotenv() # ====================== 初始化向量嵌入模型 ====================== # DashScopeEmbeddings:通义千问官方的文本向量化工具 # 核心功能:将中文/英文文本 转换为 高维数字向量(用于检索、相似度匹配) embeddings = DashScopeEmbeddings( # 【必填】阿里云通义千问的API密钥(从.env文件读取) dashscope_api_key=os.getenv("DASHSCOPE_API_KEY"), # 【必填】向量模型名称:text-embedding-v3 是通义官方最新的通用向量模型 model='text-embedding-v3' ) # 定义要转换为向量的文本 text = '大模型' # ====================== 方法1:将文档转换为向量 ====================== # embed_documents:专门用来处理【文档/批量文本】 # 入参:列表格式(可以放多个文本),返回:多个文本的向量列表 doc_res = embeddings.embed_documents([text]) # 打印文档向量结果 print(doc_res) print("===============") # ====================== 方法2:将查询问题转换为向量 ====================== # embed_query:专门用来处理【用户查询/单个问题】 # 入参:单个字符串,返回:单个文本的向量 # 注:底层逻辑和embed_documents几乎一致,只是用途区分(文档/查询) res = embeddings.embed_query(text) # 打印查询向量结果 print(res)
本地模型调用:
使用HuggingFaceBgeEmbeddings
# 安装模块 pip install sentence_transformers下载modelscope Embedding的模型
from modelscope import snapshot_download # maidalun/bce-embedding-base_v1 模型名字 cache_dir:下载位置 # model_dir = snapshot_download('maidalun/bce-embedding-base_v1', cache_dir="D:\LLM\Local_model")加载本地模型,注意它的加载会放到内存里,如果加载大模型会占用很大的内存,向量模型会很小一般就两三个G,所以加载到内存里没问题
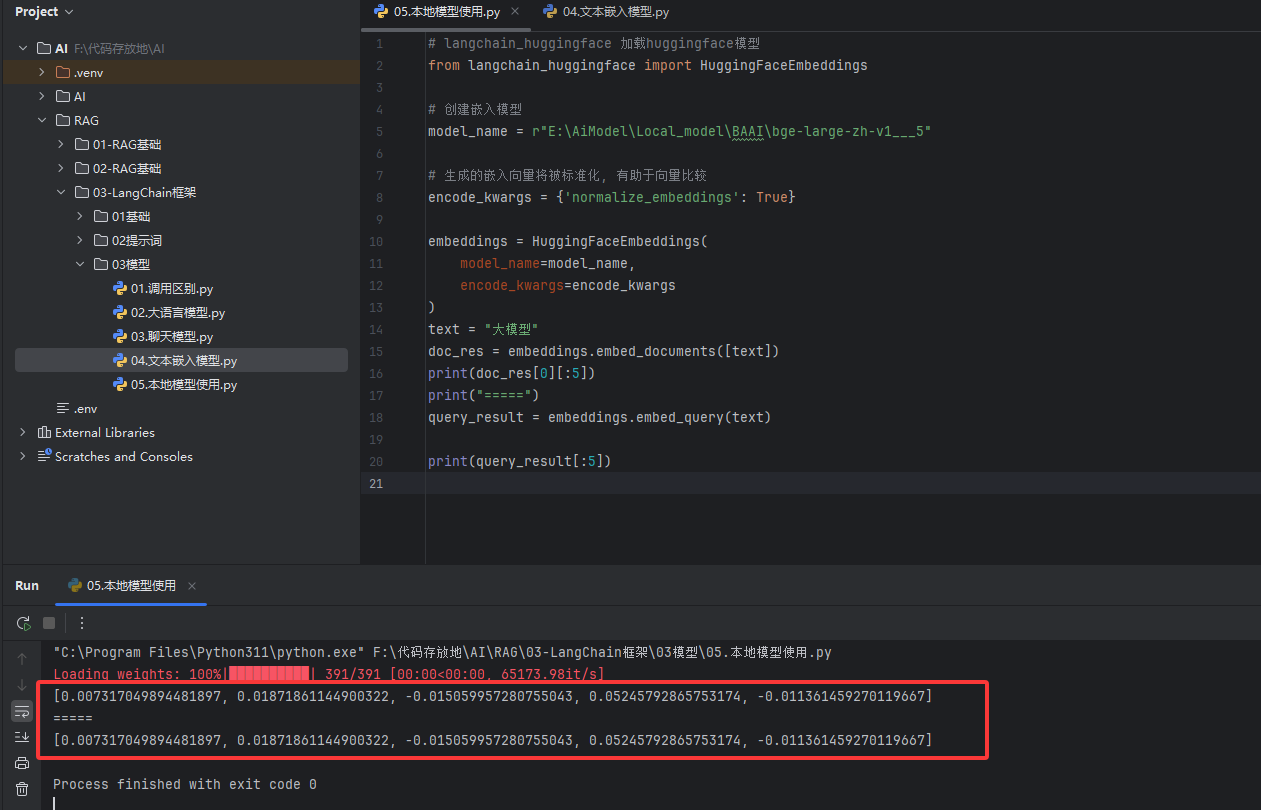
# langchain_huggingface 加载huggingface模型 # 导入LangChain对接 HuggingFace 开源本地向量模型的工具 # 作用:加载电脑本地已经下载好的中文向量模型,离线使用、免费 from langchain_huggingface import HuggingFaceEmbeddings # 创建嵌入模型 # 本地向量模型的【绝对存储路径】 # r"" 原生字符串:Windows系统专用,防止路径中的反斜杠 \ 被程序转义报错 model_name = r"E:\AiModel\Local_model\BAAI\bge-large-zh-v1___5" # 生成的嵌入向量将被标准化, 有助于向量比较 # 模型编码参数配置:固定写法 # normalize_embeddings=True:向量归一化(让所有向量长度一致,计算相似度更精准) encode_kwargs = {'normalize_embeddings': True} # 初始化本地向量模型实例 embeddings = HuggingFaceEmbeddings( model_name=model_name, # 指定本地模型的路径 encode_kwargs=encode_kwargs # 配置向量归一化参数 ) # 定义需要转换为向量的文本 text = "大模型" # ====================== 方法1:文档向量化(批量/列表格式) ====================== # embed_documents:专门处理【文档/批量文本】 # 入参必须是【列表】:[文本1, 文本2, ...] doc_res = embeddings.embed_documents([text]) # 打印结果:doc_res是二维列表,取第一个文本的向量,只打印前5个数字(完整向量太长) print(doc_res[0][:5]) print("=====") # ====================== 方法2:查询向量化(单个文本/问题) ====================== # embed_query:专门处理【单个用户问题/查询】 # 入参直接是字符串,无需列表包裹 query_result = embeddings.embed_query(text) # 打印单个向量的前5个数字 print(query_result[:5])效果图:
全国在线模型平台huggingface,它里面有很多很多模型,可以下载下载来在本地运行
官网地址:https://huggingface.co/models
如下图,这些都可以下载的


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 6
6 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)