
Gemini Omni Flash:全模态 AI video generator 的输入管线拆解
Gemini Omni Flash 是谷歌上周发布的全模态视频模型。 这个词听起来有点抽象,换成更直白的话说,
所谓全模态,就是除了以前常见的 Text to Video、Image to Video 和 Video to Video 以外,还可以把音频、角色资产等素材也作为输入,参与视频生成或视频编辑。
模型不再只看一段文字或一张图,而是可以同时参考文字说明、图片里的角色、视频里的动作、音频里的节奏或声音线索,再生成一个带画面和声音的视频结果。它更像是把过去分散在不同视频生成、视频编辑、音频同步、角色参考里的能力,放到同一个视频工作流里。
对用户来说,理想体验仍然应该尽量简单:上传素材,写提示词,选择模型,然后生成。但如果把 Gemini Omni Flash 放进一个 AI video generator 产品里,真正麻烦的不是“模型支不支持”,而是如何把这些输入整理成用户能理解、系统能校验、后端能提交的生成管线。这个按钮背后至少要处理五件事:输入资产归一化、任务模式判断、模型能力校验、成本与排队、结果回看和二次编辑。
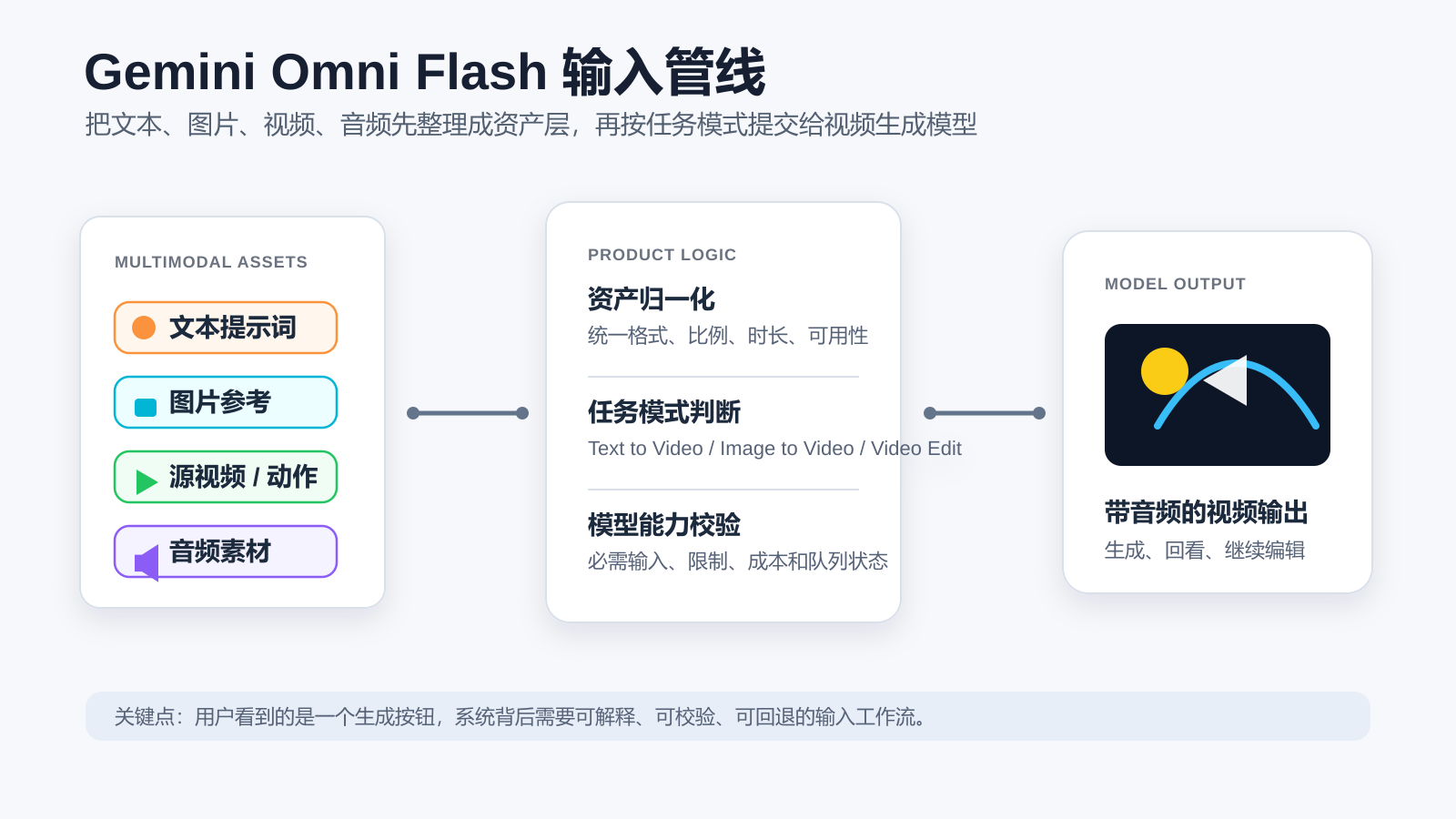
第一层:输入资产不要直接等同于表单字段
Gemini Omni Flash 的官方模型卡里,输入类型包括文本、图片、音频和视频,输出是带音频的视频。听起来像是“给用户四个上传框”就结束了,但实际产品里最好不要这样做。
更稳的做法是先把输入抽象成资产层:
- 文本:主提示词、补充说明、负面限制、编辑指令。
- 图片:首帧、角色参考、风格参考、场景参考。
- 视频:源视频、动作参考、镜头运动参考、待编辑视频。
- 音频:节奏、声音素材、可能参与同步的音频线索。
- 元数据:时长、比例、分辨率、是否带音频、模型选项和任务成本。
这样做的好处是,前端不需要把所有输入都当成孤立字段,后端也可以根据任务模式决定哪些资产进入请求、哪些只是辅助预览、哪些需要提示用户删除或替换。
第二层:先判断任务模式,再判断输入是否足够
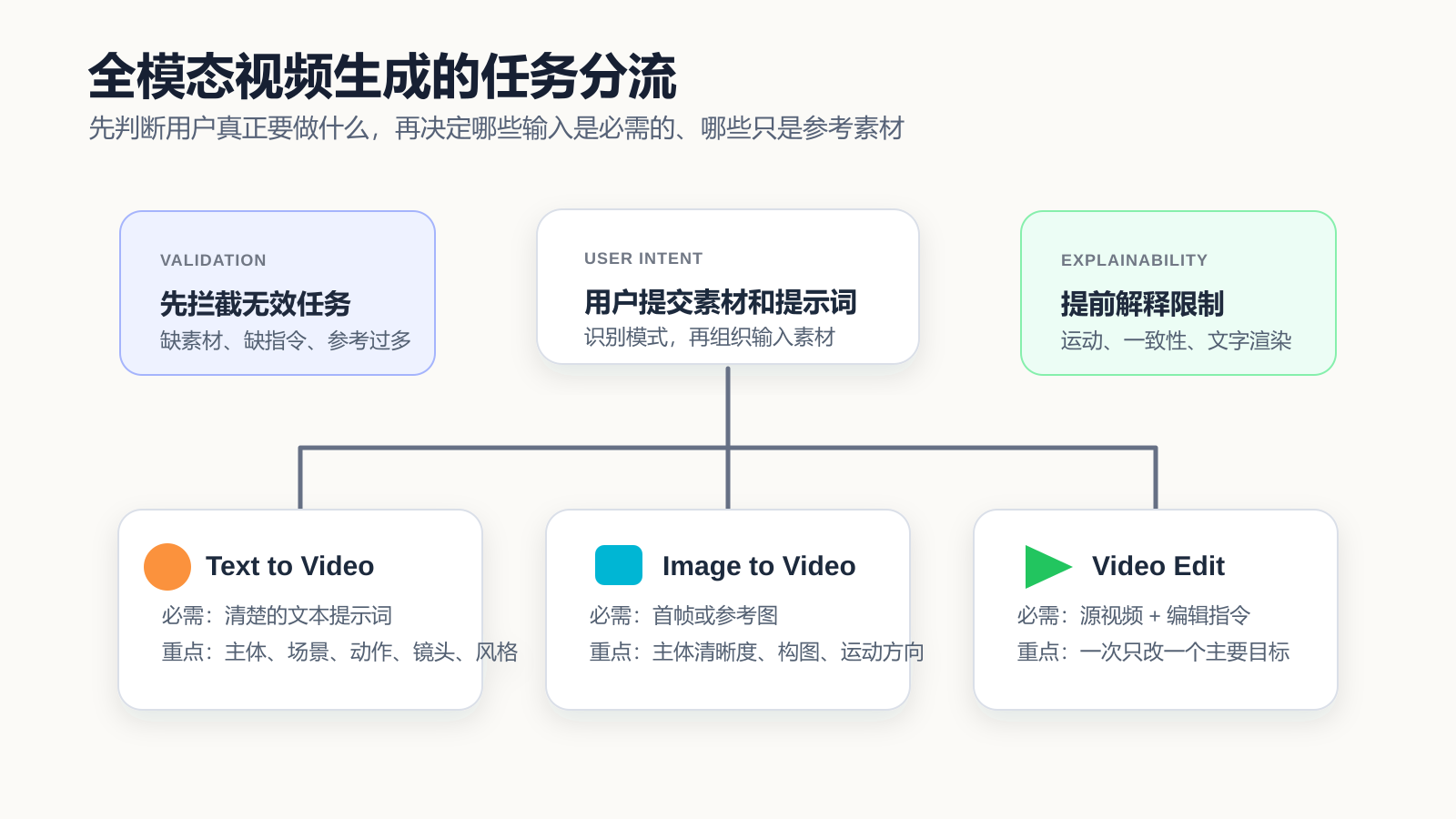
全模态模型的问题是能力范围很宽,但用户的任务通常很具体。一个视频生成页面至少要区分三类常见模式。
第一类是 Text to Video。用户只有提示词,没有图片或源视频。这种模式下,系统要重点检查提示词是否足够明确,比如主体、场景、动作、镜头和风格有没有表达出来。
第二类是 Image to Video。用户有一张或多张图片,希望让静态画面动起来。这时图片质量、主体清晰度和首帧构图会比长提示词更重要。
第三类是 Video Edit。用户已经有源视频,希望改变动作、风格、环境、对象或局部效果。这里最关键的是源视频和编辑指令之间的关系,而不是简单地把一堆参考素材都塞进去。
所以实现上应该先判断模式,再做输入校验。比如没有源视频时,不应该进入 video edit;有源视频但没有编辑指令时,也不应该让用户提交一个含义不清的任务。
第三层:把“全模态”写成可解释的规则
“任何输入到视频”是模型能力,但产品里需要把它翻译成更具体的规则。否则用户会不知道自己上传的图片、音频或视频到底在影响什么。
比较清楚的写法是:
- 图片参考主要影响角色、风格、构图或首帧。
- 视频参考主要影响动作、镜头、节奏或待编辑内容。
- 音频素材更适合和节奏、氛围、同步效果相关的任务。
- 文本提示词负责解释目标、变化方式和最终画面。
这类说明看起来像文案,但其实也是产品逻辑的一部分。它能减少无效任务,也能让用户在生成失败或不理想时知道该改哪个输入。
第四层:需要提前暴露限制,而不是生成后才解释
Gemini Omni Flash 的模型卡也提到,一些问题仍然有挑战,例如多轮编辑中的一致性、复杂运动、准确文字渲染等。把这些限制提前放进产品流程,比在生成失败后再解释更好。
例如:
- 如果用户要求复杂运动,可以提示“动作越复杂,越需要清晰的视频或图片参考”。
- 如果用户要求连续多轮编辑,可以提示“尽量一次只改一个主要目标”。
- 如果画面里需要准确文字,应该提醒文字结果需要人工检查。
- 如果用户上传了太多参考素材,可以让他选择一个主参考,而不是默认全部使用。
对开发者来说,这些不是单纯的提示语,而是输入校验、任务拆分和失败预防的一部分。
第五层:一个页面示例
如果要看一个实际页面如何把 Gemini Omni Flash 放进 AI video generator 工作流,可以参考这个开源的模型页:Vivify Gemini Omni Flash workflow。
这个链接放在这里不是为了证明某个平台“接入了模型”,而是因为这类页面要解决的问题比较典型:用户进入页面时,需要快速知道 Gemini Omni Flash 适合哪些输入、能做哪些视频生成或编辑任务、哪些素材会影响结果,以及什么时候应该换成其他视频模型。
小结
Gemini Omni Flash 的重点不只是“支持文本、图片、音频和视频输入”。对 AI video generator 来说,更重要的是把全模态能力整理成一条清楚的输入管线:
- 先把素材抽象成资产。
- 再按任务模式组织输入。
- 提前校验哪些输入是必需的。
- 用简单规则解释不同素材的作用。
- 在生成前暴露限制和成本。
- 生成后保留二次编辑入口。
用户看到的可以是一个生成按钮,但系统背后最好是一套可解释、可校验、可回退的工作流。全模态模型越强,这层产品和实现上的整理就越重要。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)