
RAG +LLaMA-Factory+loRA微调+React+ollama 代码学习 主体代码实现
目录
很难实现。要下载很多包,存在依赖问题。windows环境实现不了。
项目页面展示
背景
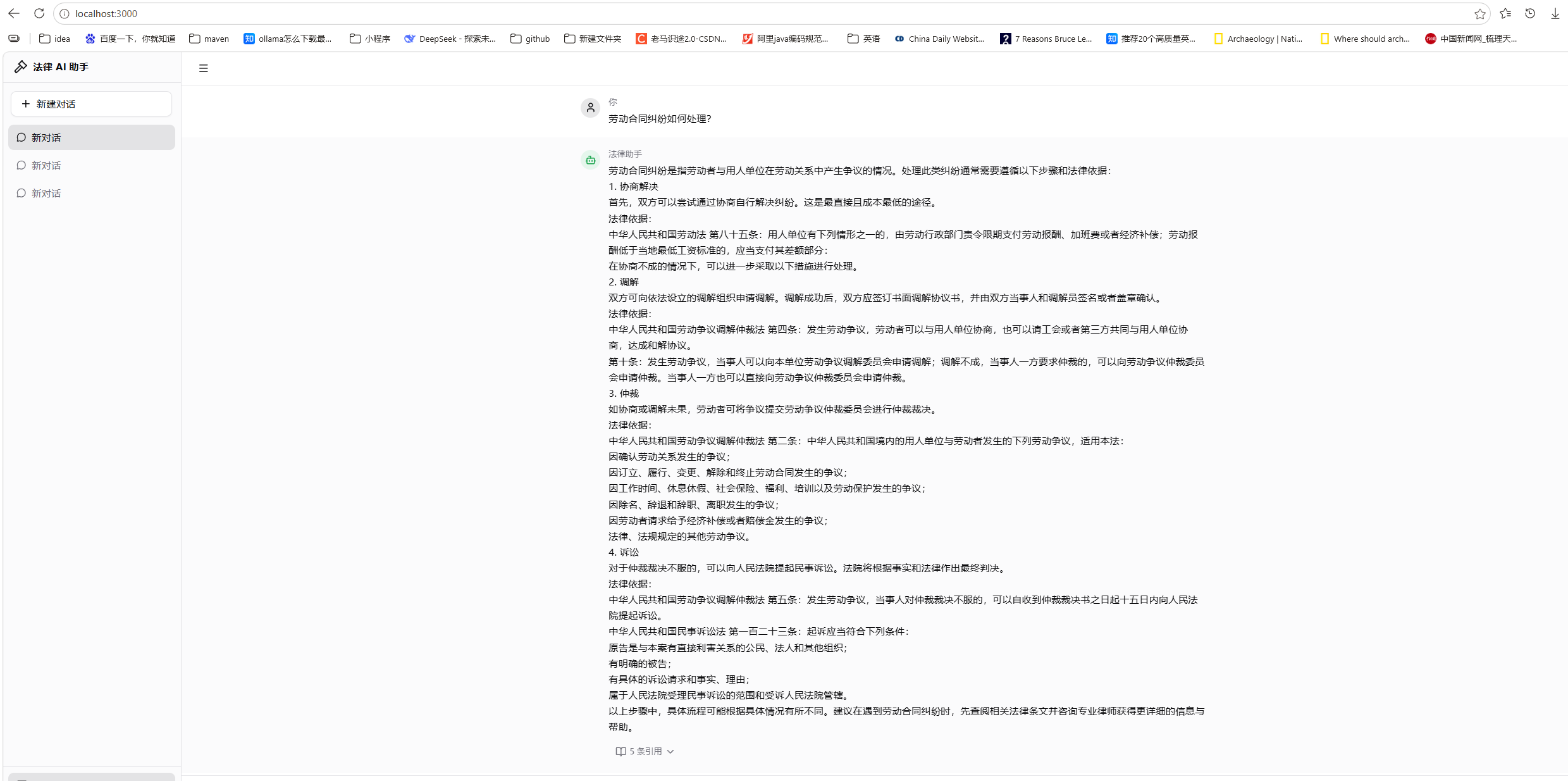
前面已经实现了大模型+embadding,实现调用ollama嵌入模型来做知识库的词向量运算了,实现了RAG。文章见:(Embedding + 向量数据库)RAG +React+ollama 代码学习 主题代码实现-CSDN博客
下面 我们开始使用做微调功能,把知识库融到大模型中。
整体概述
- 把我们数据整理成标准的问答格式,因为数据越干净,效果肯定也越好啊。
- 下载微调的工具客户端LLaMA-Factory (git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git)
- 下载量化工具库bitsendbytes,一个 Python 工具库,作用是让大模型能在 RTX 3060 上跑起来(通过 4bit 量化省显存)。
- 下载ollama模型,这里就用deepseek-r1:8b (前面已经下载了)
- 下载Hugging Face 微调大模型,这个很大比ollama的deepseek-r1:8b模型还大很多
- 然后把训练好的模型文件training.jsonl放到LLaMA-Factory\data目录下
- 执行LLaMA-Factory 客户端开始执行微调 最终会生成一个微调模型
- 合并微调模型和Hugging Face 微调大模型
- 安装 llama.cpp(用于转换 GGUF),把合并后的微调模型转成ollama的GGUF格式
- 上次合并后的模型测试
命令备用:
步骤 1:环境准备(一次性)--------------------------------------------------
# 1.1 安装 LLaMA-Factory(国内 Gitee 镜像)
cd D:\workplace
git clone --depth 1 https://gitee.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
# 1.2 验证安装
llamafactory-cli version
# 1.3 安装 Windows 专用依赖(bitsandbytes,用于 QLoRA 量化)
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
步骤 2:准备训练数据--------------------------------------------------------
# 2.1 启动法律 AI 助手项目(确保 Ollama 和数据库都在运行)
cd D:\workplace\Kimi_Agent_Embedding_RAG\app
npm start
# 2.2 生成训练数据(从 memory_queue + 知识库 自动生成)
# 新打开一个 PowerShell 窗口执行:
curl "http://localhost:3000/api/memory/training-data?outputPath=D:\workplace\training.jsonl"
步骤 3:配置数据集------------------------------------------------------------
# 3.1 在 LLaMA-Factory 中注册数据集
cd D:\workplace\LLaMA-Factory
# 编辑 data/dataset_info.json,添加:
# "legal_training": {
# "file_name": "training_data.jsonl",
# "formatting": "sharegpt",
# "columns": {
# "messages": "messages"
# }
# }
# 3.2 复制训练数据到 LLaMA-Factory 数据目录
copy D:\workplace\training.jsonl data\training.jsonl
步骤 4:执行 LoRA 微调----------------------------------------------------------
cd D:\workplace\LLaMA-Factory
# RTX 3060 推荐配置(QLoRA 4bit 量化)
python -m llamafactory-cli train `
--stage sft `
--do_train True `
--model_name_or_path D:\workplace\hf_models\deepseek-ai\DeepSeek-R1-Distill-Qwen-7B `
--dataset training `
--dataset_dir D:\workplace\LLaMA-Factory\data `
--finetuning_type lora `
--lora_rank 16 `
--lora_alpha 32 `
--lora_dropout 0.05 `
--lora_target all `
--output_dir D:\workplace\legal-lora-v1 `
--per_device_train_batch_size 2 `
--gradient_accumulation_steps 4 `
--num_train_epochs 3 `
--learning_rate 5e-5 `
--max_grad_norm 0.5 `
--warmup_ratio 0.03 `
--lr_scheduler_type cosine `
--logging_steps 10 `
--save_steps 100 `
--template qwen `
--dataloader_num_workers 0 `
--fp16 True `
--quantization_bit 4
步骤 5:合并模型(LoRA + 基础模型) 就生成了专业版的大模型了
cd D:\workplace\LLaMA-Factory
llamafactory-cli export `
--model_name_or_path deepseek-r1:8b `
--adapter_name_or_path D:\workplace\legal-lora-v1 `
--finetuning_type lora `
--export_dir D:\workplace\legal-merged `
--export_size 2 `
--export_device cpu `
--template deepseek3
步骤 6:转换为 Ollama 格式
# 6.1 安装 llama.cpp(用于转换 GGUF)
cd D:\workplace
git clone --depth 1 https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# 6.2 转换 HuggingFace 模型为 GGUF
python convert_hf_to_gguf.py D:\workplace\legal-merged --outfile D:\workplace\legal-v1.gguf
# 6.3 创建 Ollama Modelfile 设置默认的提示词和合适的参数
FROM D:\workplace\legal-v1.gguf
SYSTEM """你是一位专业的中国法律顾问,精通宪法、民法典、刑法、劳动法、商法等各领域的法律法规。你已通过大量法律条文和案例进行了专业训练,能够为用户提供准确、权威的法律咨询服务。回答时请引用具体法条,保持客观严谨。"""
PARAMETER temperature 0.6
PARAMETER top_p 0.9
PARAMETER num_ctx 4096
PARAMETER repeat_penalty 1.1
# 6.4 导入 Ollama
ollama create my-legal-v1 -f D:\workplace\Modelfile
# 6.5 验证
ollama list
ollama run my-legal-v1 "劳动合同试用期最长多久?"微调命令讲解
python -m llamafactory-cli train `
--stage sft `
--do_train True `
--model_name_or_path D:\workplace\hf_models\deepseek-ai\DeepSeek-R1-Distill-Qwen-7B `
--dataset training `
--dataset_dir D:\workplace\LLaMA-Factory\data `
--finetuning_type lora `
--lora_rank 16 `
--lora_alpha 32 `
--lora_dropout 0.05 `
--lora_target all `
--output_dir D:\workplace\legal-lora-v1 `
--per_device_train_batch_size 2 `
--gradient_accumulation_steps 4 `
--num_train_epochs 3 `
--learning_rate 5e-5 `
--max_grad_norm 0.5 `
--warmup_ratio 0.03 `
--lr_scheduler_type cosine `
--logging_steps 10 `
--save_steps 100 `
--template qwen `
--dataloader_num_workers 0 `
--fp16 True `
--quantization_bit 4
需要调整的几个配置:
1.微调大模型的地址 --model_name_or_path D:\workplace\hf_models\deepseek-ai\DeepSeek-R1-Distill-Qwen-7B
2,--dataset training 我们前面训练数据的文件名,其实是有后缀的,只是默认是.jsonl。 这个名称需要到D:\workplace\LLaMA-Factory\data (换成你安装LLaMA-Factory的目录),修改dataset_info.json文件,把如下配置追加到文件中
"training": {
"file_name": "training.jsonl",
"formatting": "alpaca",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
}当然了 我们的训练文件也要放到D:\workplace\LLaMA-Factory\data目录下。
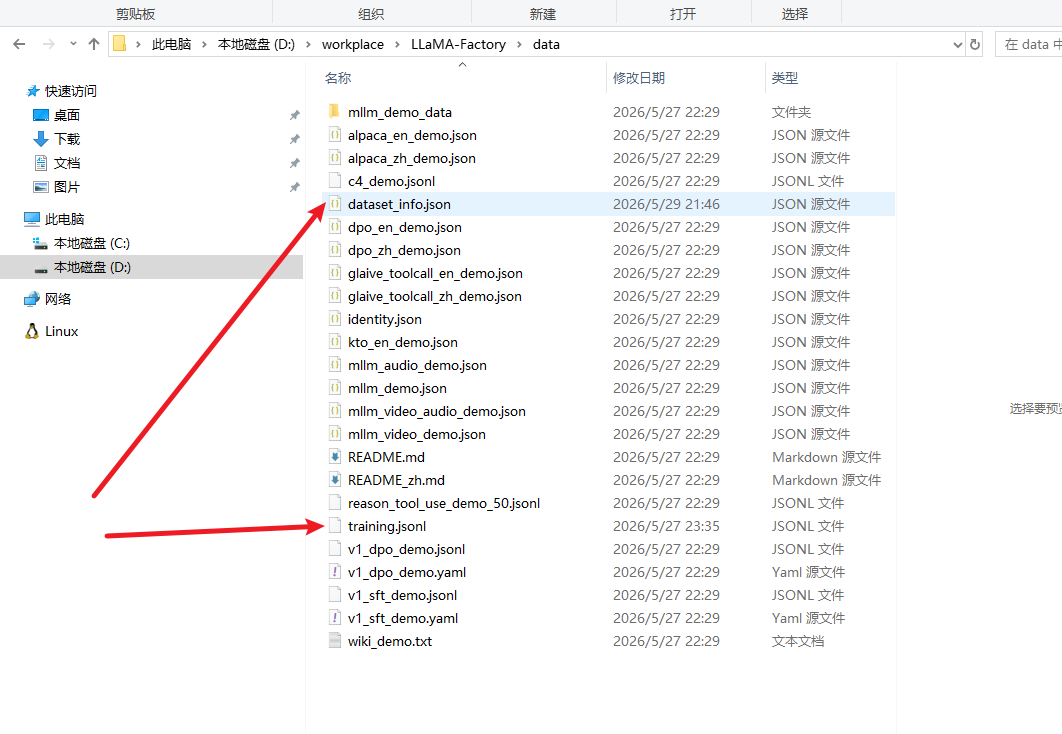
3,训练工具LLaMA-Factory的安装目录: --dataset_dir D:\workplace\LLaMA-Factory\data `
4,生成的微调模型输出目录,可以不用管:--output_dir D:\workplace\legal-lora-v1
5, --template qwen ` 这里是千问,跟前面的微调大模型一致即可
下载 Hugging Face 模型
ModelScope 国内镜像(推荐,速度快)
cd D:\workplace
# 1. 安装 ModelScope
pip install modelscope
# 2. 下载 DeepSeek-R1-Distill-Qwen-7B
python -c "
from modelscope import snapshot_download
snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', cache_dir='D:/workplace/hf_models')
"
# 3. 找到实际下载路径(通常是 cache_dir + 子目录)
dir D:\workplace\hf_models\deepseek-ai\微调
首先就是正常的RAG方式,我们启动项目随便对话,问一条非知识库中的内部,可以看到无法回答。
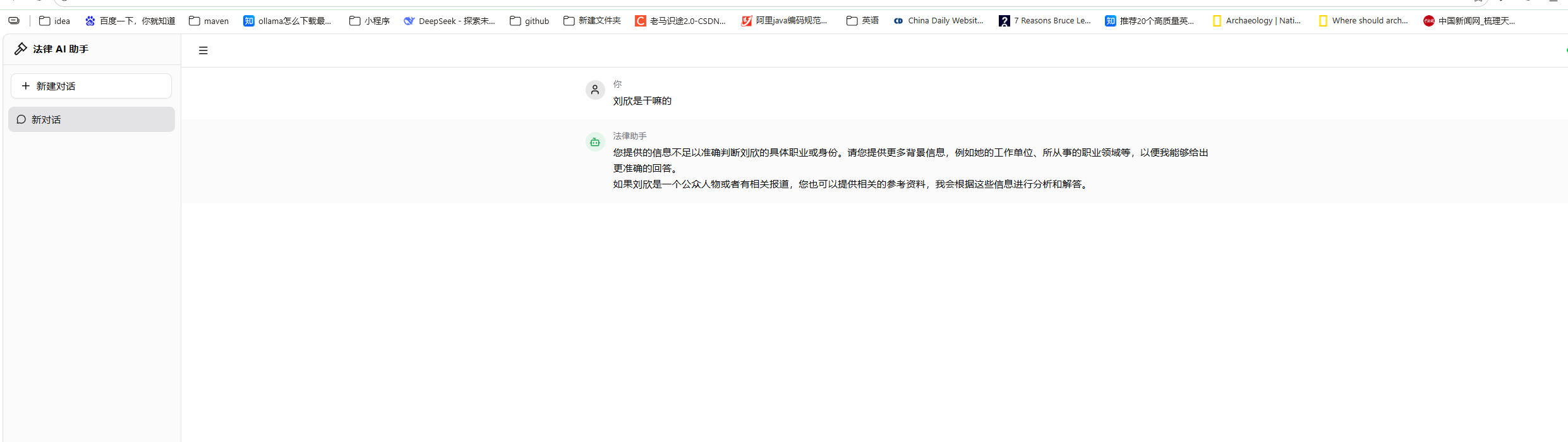
然后,我们现在知识库中加一条很私密的话,就是用现有大模型不知道,回答不出来的。比如说,我加了个“刘欣是软件开发 18岁,永远年轻快乐”
然后调训练接口还是训练。
训练好的数据长这样:
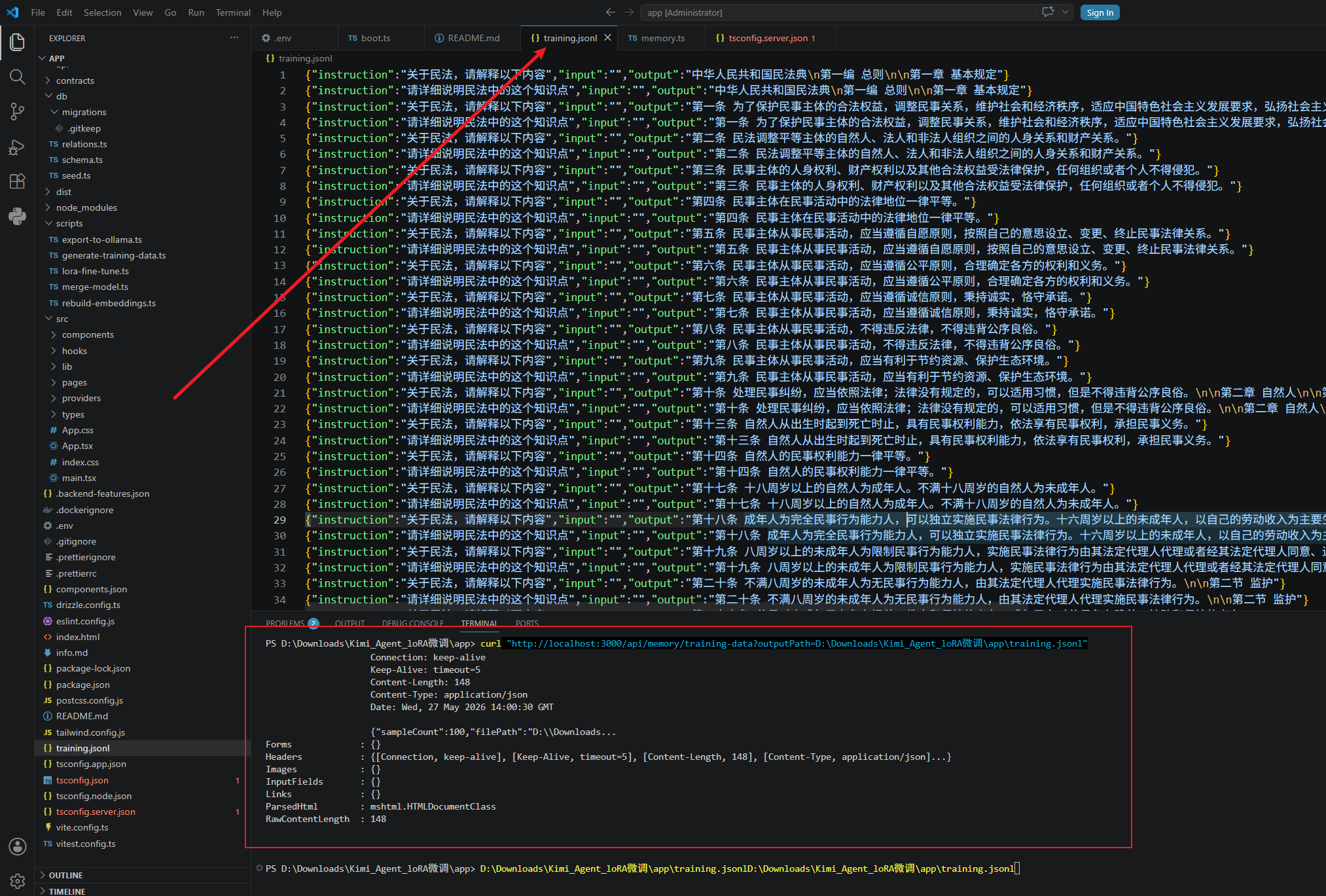
接着安装上面的步骤一个个执行吧。
代码路径:https://download.csdn.net/download/csdnliuxin123524/92923375
先记录一个清包命令:
-
Remove-Item -Recurse -Force node_modules

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)