
DeepSeek降价75%,OpenClaw多模型切换实战
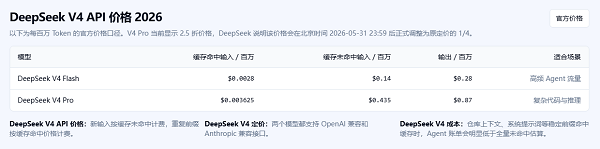
DeepSeek V4-Pro API已于2026年5月31日结束限时优惠后永久调整为原定价的1/4,缓存命中输入低至0.025元/百万Token。 相信你也考虑不会只绑定一家API——通过OpenClaw部署助手配置多模型路由,可以实现DeepSeek、Kimi、通义千问等服务商的智能切换,哪家便宜用哪家,哪家稳定切哪家,把单次降价的"限时红利"变成长期可控的"成本策略"。

一、为什么降价后反而需要多模型管理?
DeepSeek此次降价确实激进,但单一供应商依赖存在隐性风险:
1、价格回弹风险:此次是"永久降价",但未来硬件成本、政策变化都可能导致调价。
2、服务波动风险:高峰期排队、区域性限速是常态,没有备用方案等于把业务押在一条船上。
3、能力边界风险:DeepSeek擅长代码和推理,但多模态、特定领域知识库可能不如其他家。
4、合规与出海风险:不同客户对数据驻留、模型来源有硬性要求,需要灵活切换。
二、DeepSeek V4-Pro降价后的真实成本对比
| 服务商 | 模型 | 输入(缓存命中) | 输出 | 上下文 |
| DeepSeek | V4-Pro | 0.025元/百万Token | 6元 | 1M |
| OpenAI | GPT-5.5 | ~15元 | ~216元 | 256K |
| Anthropic | Claude Opus 4.6 | ~105元 | ~525元 | 200K |
| 智谱 | GLM-4 | 免费额度+付费 | 付费 | 128K |
| 月之暗面 | Kimi K2.6 | 按量计费 | 按量计费 | 200K |
数据来源:DeepSeek官方API文档及公开市场信息
DeepSeek的价格优势是碾压级的,但代码生成用DeepSeek、长文档总结用Kimi、创意写作用Claude的组合策略,往往比单模型效果更好。
三、用OpenClaw配置多模型
OpenClaw部署助手的AI模型管理模块支持同时接入多家服务商,并为不同场景分配最优模型。以下是配置多模型fallback的核心步骤:
第一步:接入多家API,集中管理密钥
1、打开OpenClaw控制面板,进入"AI模型"→"模型管理";
2、添加需要配置的服务商,比如DeepSeek。
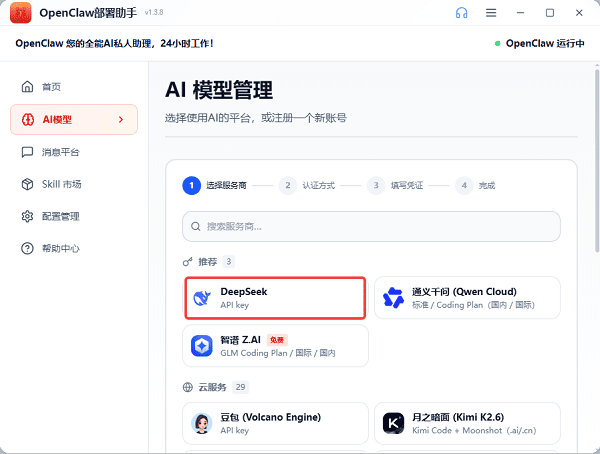
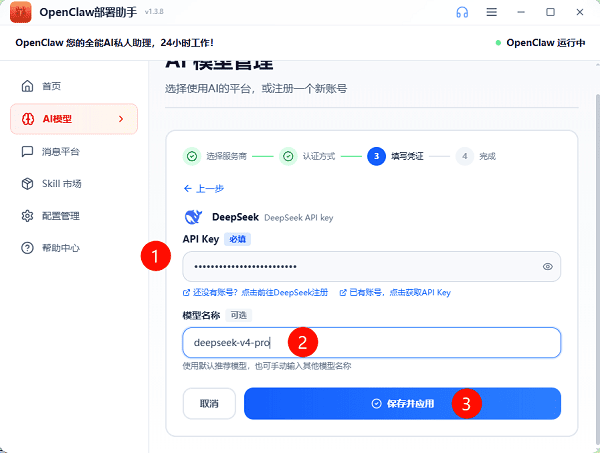
3、选择后填入获取到的API Key(首次输入需要到官网进行注册)。
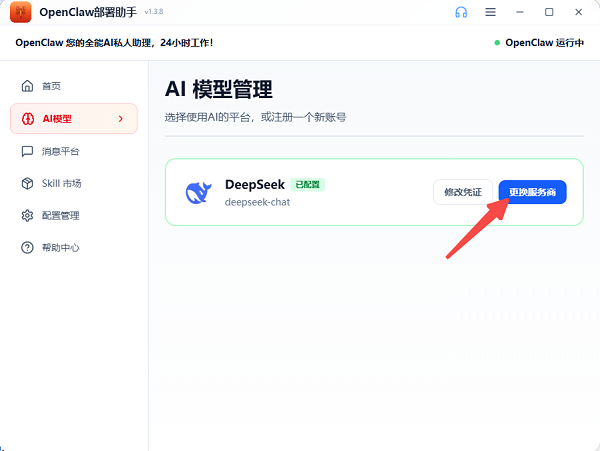
4、如果需要切换其它模型(Kimi/通义/智谱等),也可以点击“更换服务商”进行更新。
第二步:按场景分配模型,精细化控费
不是所有任务都需要最强模型。在OpenClaw的Skill市场或消息平台中,可以为不同Agent指定不同模型:
| 使用场景 | 推荐模型 | 配置理由 |
| 代码生成/Debug | DeepSeek V4-Pro | 推理强,价格最低 |
| 长文本摘要 | Kimi K2.6 | 200K上下文,中文理解好 |
| 创意写作/翻译 | Claude Sonnet | 文风自然,多语言强 |
| 实时客服/快速响应 | DeepSeek V4-Flash | 速度优先,成本更低 |
四、多模型策略的进阶玩法
玩法一:A/B测试自动选优
同一任务同时发给DeepSeek和Kimi,对比输出质量后自动选择更好的结果返回。OpenClaw的多Agent配置支持为不同实例绑定不同模型,通过消息平台并行调用。
玩法二:分级计费,用户分层
面向客户的SaaS产品,可用OpenClaw管理后台模型路由:
免费用户:走DeepSeek V4-Flash(成本最低)
付费用户:走DeepSeek V4-Pro(质量优先)
企业用户:走私有化部署或Claude(合规优先)
五、避坑提醒:多模型不是越多越好
1、密钥管理成本:每多一家服务商,就多一套密钥轮换、余额监控、发票对接的工作量,建议控制在3-4家核心供应商。
2、输出风格差异:不同模型回答风格不同,频繁切换可能导致用户体验不一致,建议同一对话会话内锁定模型。
3、缓存策略:DeepSeek的"缓存命中"价格极低(0.025元),但前提是重复调用相同前缀提示词。设计系统提示词时尽量标准化,才能吃到缓存红利。
DeepSeek V4-Pro的永久降价是国产大模型生态成熟的标志,但真正的成本高手不会"把鸡蛋放在一个篮子里"。通过OpenClaw部署助手搭建多模型路由,你既能享受DeepSeek的极致低价,又能在服务波动时无缝切换到Kimi、通义或智谱,把API调用从"单一采购"变成"动态调度"。
OpenClaw部署助手![]() https://www.160.com/qddownload/3007/openclawtool-windows.exe
https://www.160.com/qddownload/3007/openclawtool-windows.exe

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)