
10.LangChain框架2-提示词
langchain ai 大模型 ren
·
内容参考于:图灵AI大模型全栈
提示词有字符串提示词和聊天提示词和样本提示词三种
字符串提示词就是单一纯文本格式,就是问一次就结束了
聊天提示词会带着上下文,有角色和内容区分
样本提示词(少量样板提示词)它让模型模仿示例格式、风格、规则回答新问题,大模型的回答是不确定的是未知的是不可控的,通过样本提示词可以限制大模型回答的结果,这样可以让大模型的回答比较可控
字符串提示词,一般用来文本生成场景
效果图:
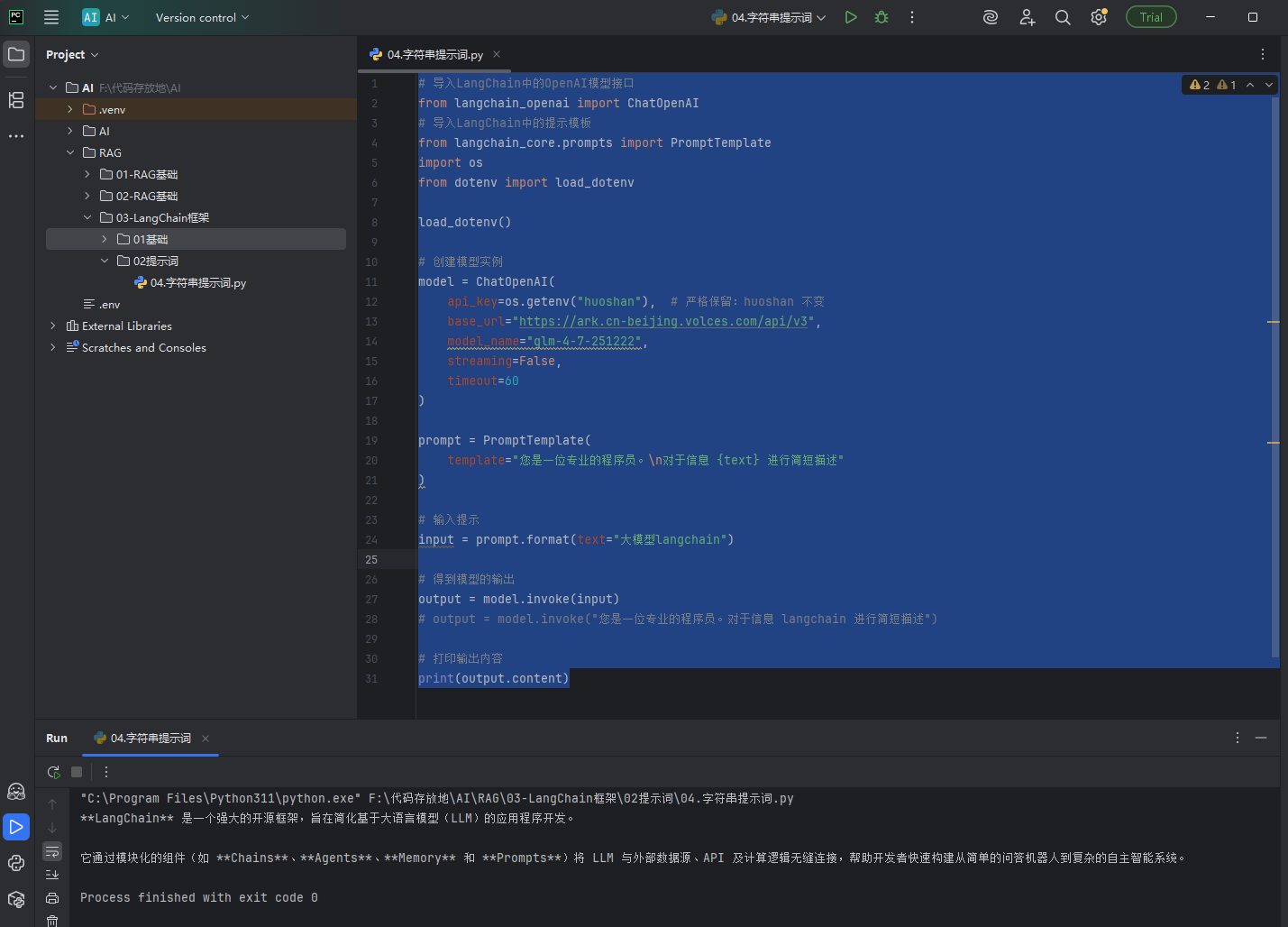
# -------------------------- 1. 导入需要用到的工具包 -------------------------- # 导入LangChain对接OpenAI格式大模型的接口(火山方舟兼容这个接口) from langchain_openai import ChatOpenAI # 导入LangChain的提示词模板工具(用来固定提示词格式,方便替换变量) from langchain_core.prompts import PromptTemplate # 导入系统环境变量工具(用来读取电脑/项目里的配置信息) import os # 导入.env配置文件读取工具(专门读取存密钥、配置的.env文件) from dotenv import load_dotenv # -------------------------- 2. 加载配置文件 -------------------------- # 读取项目根目录下的.env文件,把里面的密钥、配置加载到系统中 load_dotenv() # -------------------------- 3. 创建大模型连接实例 -------------------------- """ ChatOpenAI:LangChain封装好的、对接大模型的核心类 作用:创建一个和火山方舟大模型对话的"客户端" """ model = ChatOpenAI( # 【入参1:api_key】必填 → 大模型的身份密钥(相当于登录密码) # os.getenv("huoshan"):从.env文件中读取变量名为huoshan的密钥(严格保留huoshan) api_key=os.getenv("huoshan"), # 【入参2:base_url】必填 → 火山方舟大模型的接口地址(固定不变) base_url="https://ark.cn-beijing.volces.com/api/v3", # 【入参3:model_name】必填 → 要调用的模型名称(火山方舟的glm-4模型) model_name="glm-4-7-251222", # 【入参4:streaming】可选 → 是否开启流式输出 # True:打字机效果,边思考边输出文字;False:一次性输出完整结果 streaming=False, # 【入参5:timeout】可选 → 请求超时时间(单位:秒) # 60秒内模型没响应,就自动停止请求,避免卡死 timeout=60 ) # -------------------------- 4. 创建提示词模板 -------------------------- """ PromptTemplate:提示词模板工具 作用:把固定的提示词写成模板,只需要替换变量部分,不用每次写完整句子 """ prompt = PromptTemplate( # 【入参:template】必填 → 提示词模板内容 # {text}:变量占位符,后面会替换成我们要描述的文字 template="您是一位专业的程序员。\n对于信息 {text} 进行简短描述" ) # -------------------------- 5. 填充模板,生成最终提示词 -------------------------- # prompt.format():给模板的占位符赋值,生成完整的提示词 # 【入参text】→ 要替换进模板的实际内容(这里是"大模型langchain") input_text = prompt.format(text="大模型langchain") # -------------------------- 6. 调用大模型,获取回答 -------------------------- # model.invoke():核心方法 → 把提示词发给模型,等待模型返回结果 # 入参:格式化后的完整提示词 output = model.invoke(input_text) # 注释掉的代码:直接写完整提示词调用模型(和上面效果一样,只是没有用模板) # output = model.invoke("您是一位专业的程序员。对于信息 langchain 进行简短描述") # -------------------------- 7. 打印模型返回的结果 -------------------------- # output.content:模型返回的纯文字回答(去掉多余的格式信息) print(output.content)
聊天提示词,一般用来沟通,有来有回的需要进行对话的场景
聊天提示词分模板和角色
聊天提示词模板:
效果图:
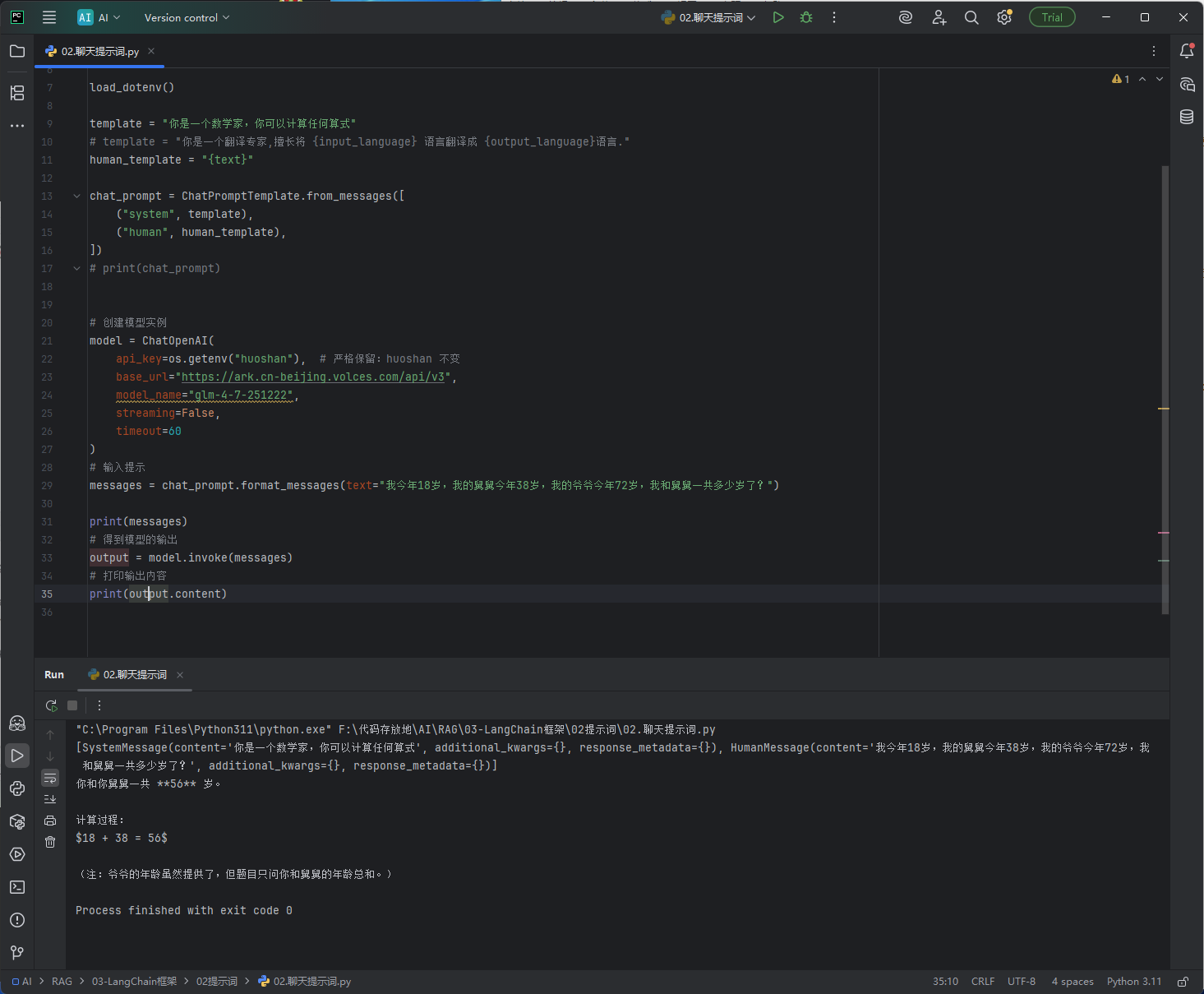
它里面有一个占位符的概念,就是用{xxx}这样写好之后,在调用format_messages函数拼接提示词的时候可以这样写,比如现在有一个提示词模板是 我爱{am},然后调用format_messages时这样写format_messages(am="机王"),发给大模型的就会使 我爱机王 这样的提示词,它就是通过{xxx}来实现角色的
# 导入 LangChain 聊天专用提示模板(区分系统角色、用户消息) from langchain_core.prompts.chat import ChatPromptTemplate # 导入对接火山方舟大模型的接口 from langchain_openai import ChatOpenAI # 读取环境变量(密钥) import os # 读取 .env 配置文件 from dotenv import load_dotenv load_dotenv() # ====================== 一、占位符 {xxx} 核心说明(小白必看) ====================== # {变量名} 叫【占位符】,作用:后面用 format_messages 给它赋值,实现灵活替换 # 变量名只能:英文、数字、下划线,不能中文、空格、特殊符号 # 所有 {xxx} 都要和 format_messages(变量名=值) 一一对应 # 如果问题是{text}需要写成{{text}}这样用两个大括号转义一下 # 写法1:系统词固定,用户消息用1个变量 {text} template = "你是一个数学家,你可以计算任何算式" human_template = "{text}" # 单个占位符:{text} # 【补充注释】{text}:通用用户输入占位符,接收用户的问题、需求、计算内容等核心信息 # 写法2:系统词+用户词 同时用多个占位符(示例,可替换上面) # template = "你是翻译专家,擅长把 {in_lang} 翻译成 {out_lang}" # 【补充注释】{in_lang}:输入语言占位符,指定要翻译的源语言;{out_lang}:输出语言占位符,指定翻译后的目标语言 # human_template = "翻译这句话:{content}" # 【补充注释】{content}:待翻译的文本内容占位符,接收需要翻译的具体文字 # 写法3:变量放在句子任意位置(开头/中间/结尾/换行) # human_template = "帮我分析:{text},要求:{require}" # 【补充注释】{text}:分析对象占位符,指定要分析的内容;{require}:需求要求占位符,指定分析的规则、格式、风格等 # 写法4:系统词里也能放占位符 # chat_prompt = ChatPromptTemplate.from_messages([ # ("system", "你是{role},擅长{skill}"), # 【补充注释】{role}:模型角色占位符,自定义大模型的身份(如数学家、翻译官、程序员) # 【补充注释】{skill}:模型能力占位符,自定义大模型擅长的技能(如计算、翻译、编程) # ("human", "{text}"), # 【补充注释】{text}:用户问题占位符,接收用户的具体提问内容 # ]) # 组装聊天提示:system=角色设定,human=用户问题模板 chat_prompt = ChatPromptTemplate.from_messages([ ("system", template), ("human", human_template), ]) # 创建大模型连接实例 model = ChatOpenAI( api_key=os.getenv("huoshan"), # 火山方舟密钥,固定huoshan base_url="https://ark.cn-beijing.volces.com/api/v3", model_name="glm-4-7-251222", streaming=False, # 是否流式输出:False一次性返回 timeout=60 # 超时时间,单位秒 ) # ====================== 二、占位符传参规则 ====================== # format_messages(变量名="实际内容") # 变量名必须和 {xxx} 里面名字完全一样! # 1个变量:text="xxx" # 多个变量:in_lang="中文", out_lang="英文", content="你好" # 【补充注释】传参对应规则: # {role} → format_messages(role="数学家") # {skill} → format_messages(skill="快速计算") # {require} → format_messages(require="只输出计算结果") # {in_lang} → format_messages(in_lang="中文") # {out_lang} → format_messages(out_lang="英文") # {content} → format_messages(content="你好") messages = chat_prompt.format_messages( text="我今年18岁,我的舅舅今年38岁,我的爷爷今年72岁,我和舅舅一共多少岁了?" ) # 打印组装好的消息(调试用) print(messages) # 调用模型,传入组装好的消息 output = model.invoke(messages) # 打印模型回答 print(output.content)
聊天提示词角色,它与聊天提示词模板一样,只是写法不一样
效果图:
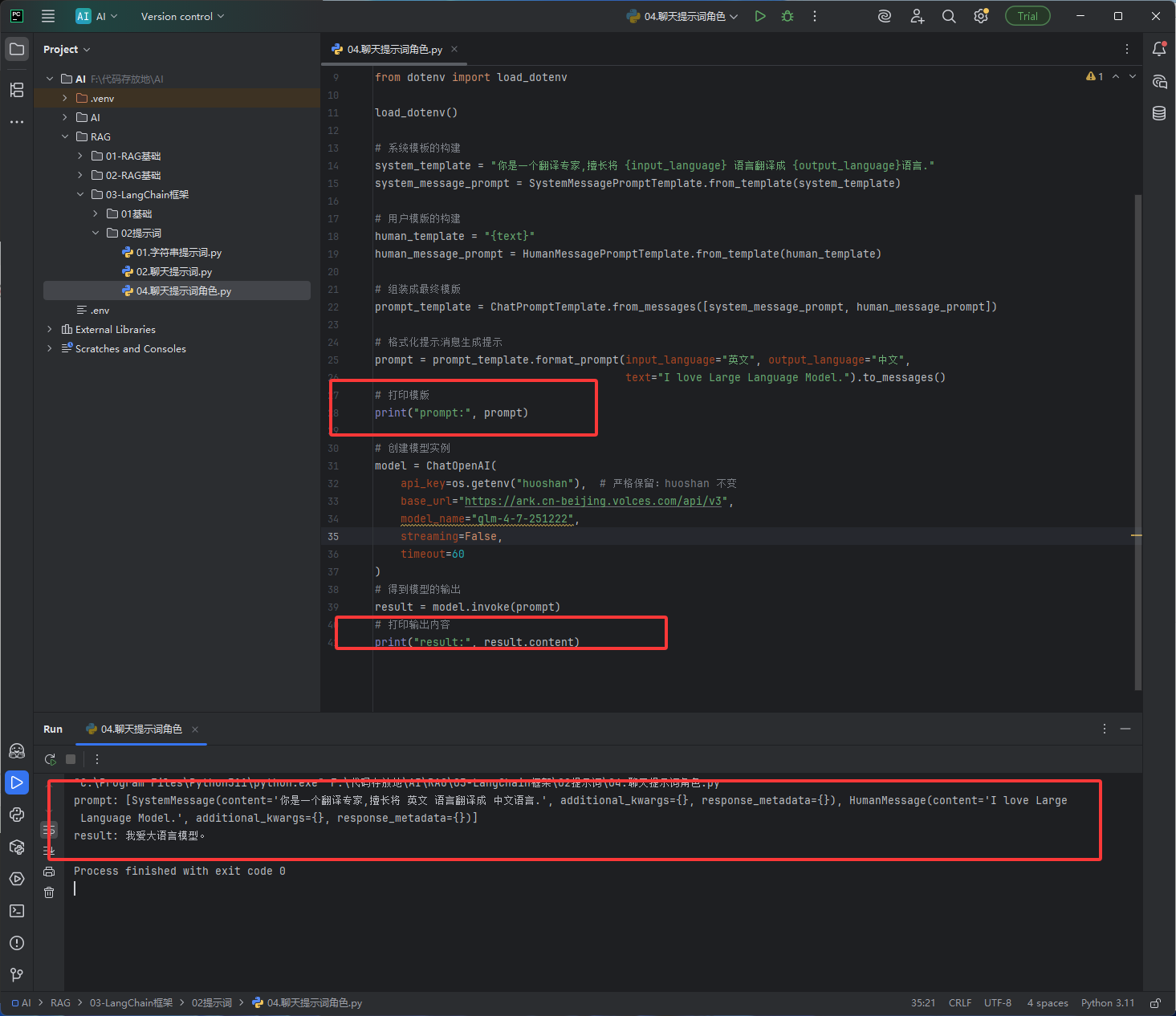
它是通过from_template先确定角色,就是告诉大模型你是什么什么专家什么什么人,聊天提示词模板是直接用的from_messages来拼接的,没有使用from_template
# 导入LangChain聊天模板核心类(拆分式写法,更清晰) # ChatPromptTemplate:总模板,负责把系统消息+用户消息组装在一起 # SystemMessagePromptTemplate:系统消息模板,给大模型设定身份、规则 # HumanMessagePromptTemplate:用户消息模板,存放用户的提问内容 from langchain_core.prompts import ( ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate, ) # 导入对接火山方舟大模型的接口 from langchain_openai import ChatOpenAI # 读取系统环境变量,用于获取API密钥 import os # 加载.env配置文件中的密钥信息 from dotenv import load_dotenv # 加载.env文件中的配置(API密钥) load_dotenv() # ====================== 1. 构建系统消息模板 ====================== # 系统提示词:定义大模型的身份(翻译专家)和能力 # 【占位符说明】 # input_language:自定义变量名 → 源语言(要翻译的原始语言) # output_language:自定义变量名 → 目标语言(翻译后的语言) # 变量名可以自定义(比如in_lang/out_lang),用完整单词更易懂,这是行业通用写法 system_template = "你是一个翻译专家,擅长将 {input_language} 语言翻译成 {output_language}语言." # 将字符串模板转换为【系统消息模板对象】,固定格式要求 system_message_prompt = SystemMessagePromptTemplate.from_template(system_template) # ====================== 2. 构建用户消息模板 ====================== # 用户提示词:用户需要翻译的具体内容 # 【占位符说明】 # text:自定义变量名 → 存放需要翻译的文本内容 human_template = "{text}" # 将字符串模板转换为【用户消息模板对象】 human_message_prompt = HumanMessagePromptTemplate.from_template(human_template) # ====================== 3. 组装完整的聊天模板 ====================== # 把系统模板 + 用户模板 合并成一个完整的对话模板 prompt_template = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt]) # ====================== 4. 填充变量,生成最终的对话消息 ====================== # format_prompt:给所有占位符赋值,替换变量 # 传参必须和模板中的占位符 名称完全一致! # to_messages():将填充后的模板转换成大模型能识别的消息格式 prompt = prompt_template.format_prompt( input_language="英文", # 对应 {input_language} 源语言 output_language="中文", # 对应 {output_language} 目标语言 text="I love Large Language Model." # 对应 {text} 待翻译内容 ).to_messages() # 打印最终发送给大模型的完整消息 print("prompt:", prompt) # ====================== 5. 创建大模型连接实例 ====================== model = ChatOpenAI( api_key=os.getenv("huoshan"), # 从.env读取火山方舟API密钥,固定变量名 base_url="https://ark.cn-beijing.volces.com/api/v3", # 火山方舟接口地址(固定) model_name="glm-4-7-251222", # 调用的大模型名称 streaming=False, # 关闭流式输出,一次性返回结果 timeout=60 # 请求超时时间(秒) ) # ====================== 6. 调用大模型,获取翻译结果 ====================== # 传入组装好的对话消息,获取模型返回结果 result = model.invoke(prompt) # 打印模型返回的翻译内容 print("result:", result.content)
样本提示词(少量样板提示词)
效果图:传递的是2乘以5结果是10,然后大模型回答是乘法运算,这样就比较可控了
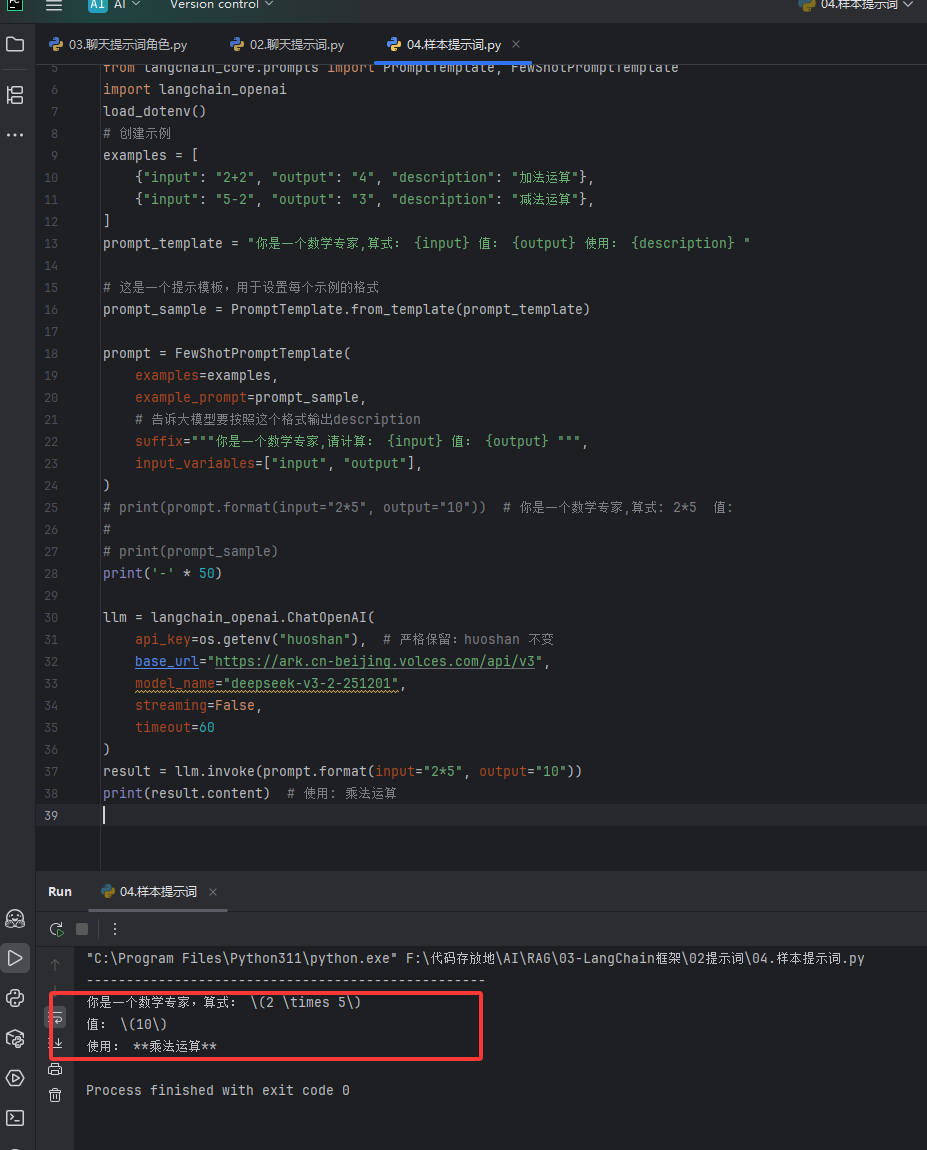
少量提示词给的模板不要太多,如果太多了大模型会抓不住重点,一般5个左右
# 创建提示模板,配置一个提示模板,将一个示例格式化为字符串 import os from dotenv import load_dotenv # 导入基础提示模板、少样本提示模板(核心:给大模型举例子用的) from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate import langchain_openai # 加载.env文件中的API密钥 load_dotenv() # ====================== 1. 定义参考示例(少样本学习核心) ====================== # 给大模型看的【参考例子】,让模型模仿这个格式回答问题 examples = [ # 第一个示例:加法运算 {"input": "2+2", "output": "4", "description": "加法运算"}, # 第二个示例:减法运算 {"input": "5-2", "output": "3", "description": "减法运算"}, ] # 定义【单个示例】的格式化字符串 # 占位符说明: # {input} = 数学算式(必填) # {output} = 算式结果(必填) # {description} = 运算类型描述(必填) prompt_template = "你是一个数学专家,算式: {input} 值: {output} 使用: {description} " # 把字符串模板,转换成LangChain可识别的模板对象 prompt_sample = PromptTemplate.from_template(prompt_template) # ====================== 2. 创建少样本提示模板 ====================== prompt = FewShotPromptTemplate( examples=examples, # 传入我们定义的参考示例 example_prompt=prompt_sample,# 每个示例按照这个模板格式化 # suffix:后缀提示词,示例展示完后,最后告诉模型要做什么 # 占位符:{input} 新的算式,{output} 新的结果 suffix="""你是一个数学专家,请计算: {input} 值: {output} """, # 声明模板中用到的【所有占位符】,必须和模板里的名字完全一致 input_variables=["input", "output"], ) # 测试打印格式化后的提示词(可取消注释查看) # print(prompt.format(input="2*5", output="10")) # 你是一个数学专家,算式: 2*5 值: # print(prompt_sample) print('-' * 50) # ====================== 3. 初始化大模型 ====================== llm = langchain_openai.ChatOpenAI( api_key=os.getenv("huoshan"), # 严格保留:huoshan 不变 base_url="https://ark.cn-beijing.volces.com/api/v3", model_name="deepseek-v3-2-251201", streaming=False, timeout=60 ) # ====================== 4. 调用模型 ====================== # 给少样本模板传入新的参数,生成完整提示词,发送给模型 result = llm.invoke(prompt.format(input="2*5", output="10")) # 模型会模仿示例,输出:乘法运算 print(result.content)


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)