
拒绝 Token 裸奔:从 LangChain 到 LangGraph,如何用工业级状态机驯服 Agent 的“不确定性”?
最近和几个大厂的架构师朋友聊天,大家普遍有一个深深的焦虑:去年靠写几个 Prompt、套个 LangChain 外壳就能融到资或者在公司立项的日子,彻底结束了。
很多人唱衰 LangChain,觉得它重、臃肿、抽象过度。但真正带团队做过两三个降本增效项目、或者把 Agent 推进到生产环境落地的同学心里都清楚:不是 LangChain 不行了,而是我们对 AI 工程化的认知,已经从最初的“尝鲜”走向了残酷的“深水区”。
今天不聊任何官方文档上的 API 拼凑,也不讲怎么用三行代码跑一个 Hello World。我想以一个在一线踩过无数坑的 AI 工程人员的视角,聊聊从 LangChain 到 LangGraph 的演进本质,以及企业级 AI 架构到底该怎么搭。
一、 被误解的 LangChain:它从来就不是一个“开发框架”
很多人对 LangChain 的第一印象,可能还停留在 PromptTemplate、Ollama 或者 ChatOpenAI 的简单包装上。网上也有不少声音说:“这不就是把 HTTP 请求封装了一下吗?我自己用 Python 写几行 requests 不是更轻量?”
说实话,如果你只是做个单轮对话的 Demo,或者写个脚本跑批处理,确实没必要用 LangChain。但很多人其实忽略了 LangChain 诞生的底层逻辑:它是为了解决 LLM 异构和标准碎片化而生的生态底座。
真正做企业级开发时,你面临的现实环境往往是极其割裂的:
-
业务线 A 签了微软的 Azure OpenAI。
-
业务线 B 因为合规原因,必须在私有化机房里部署 Qwen-2.5 或者 DeepSeek。
-
向量数据库今天用 Milvus,明天架构组开会说要统一换成 PGVector。
如果全靠手写原生代码,你的项目中会充斥着大量的胶水代码和各种模型的 API 适配层。LangChain 的真正价值,在于它通过 LCEL (LangChain Expression Language) 抽象出一套声明式的统一接口。
Python
# 别只看到可读性,LCEL 背后是统一的 Stream、Async、Batch 和 Fallback 机制
chain = prompt | model.with_fallbacks([backup_model]) | output_parser
# 在生产环境中,这意味着你一行代码就能同时支持同步、异步和流式响应
await chain.ainvoke({"input": "企业级问题"})
LCEL 的本质,是把所有的组件(Prompt、Model、Parser、Retriever)都抽象成了满足 Runnable 协议的组件,并在上层组装成有向无环图(DAG)。它帮你把并发控制、异步流式传输(Streaming)、容错降级(Fallback)以及统一的 Trace 监控(LangSmith)全都在底层默默做掉了。
后来我越来越发现,嫌弃 LangChain 难用的人,大部分是在用写 Imperative(命令式)代码的思维,去硬套 LCEL 的 Declarative(声明式)架构。 但是,LCEL 也有其局限性。当我们的业务逻辑从“线性链(Chain)”走向带有循环逻辑的“复杂图(Graph)”时,LangChain 曾经引以为傲的链式抽象,反而成了最大的绊脚石。
二、 RAG 的幻灭与 Agent 的工程深水区
在谈 LangGraph 之前,我们必须直面一个行业共识:单纯的、线性的 RAG(检索增强生成)已经触及了天花板。
去年大家都在做 RAG,架构千篇一律:用户提问 -> Embedding 检索 -> 拼入 Prompt -> 丢给大模型。真正到了企业落地(比如客服、财报分析、法律合规审核),这种简单的 Pipeline 报错率高得吓人。
-
检索噪音:向量检索出来的 Top-K 文档里,经常夹杂着大段不相关甚至误导性的信息。
-
单次成败陷阱:模型只要一次没回答好,整个流程就死掉了,缺乏自我纠错和重试机制。
企业级 AI 工程正在经历一个剧烈的转型:从 Prompt 工程退潮,全面走向 Workflow(工作流)化。 过去我们试图通过写长达 2000 字的“完美提示词”来教大模型做人,现在我们发现,把复杂的任务拆解成确定性强的工程流,才是唯一的解法。
这时候,大家开始搞 Agent,开始搞 Tool Calling(工具调用)。
在真实的企业项目里,一个标准的 Tool Calling 闭环通常长这样:
[User Input] -> [LLM] -> 决定调用工具 (Tool_A) -> 执行本地代码/API -> 得到 Result -> [LLM 再次思考] -> 输出或继续调用
这看起来很简单对吧?但在生产环境中,这个循环里充满了“不确定性”:
-
如果工具调用超时怎么办?
-
如果大模型生成的 JSON 格式坏掉了(缺少闭合括号),你怎么在代码里拦截并让它自动重试纠错?
-
最核心的问题:状态(State)怎么管理? 如果这个 Agent 包含 5 个步骤,需要连续调用 3 个不同的外部系统(比如先查 ERP,再查 CRM,最后写入钉钉),中间任何一步失败了,如何回滚?如何让用户介入(Human-in-the-loop)进行中途审批?
原生的 LangChain 试图用 AgentExecutor 来解决这个问题。但用过 AgentExecutor 的同学应该都经历过那种痛苦——它是个完全的黑盒。你很难去精细控制它内部的 Loop 逻辑,更无法在第 N 次循环时强行插入一段自定义的业务校验。
这就是为什么 LangGraph 会彻底火起来的根本原因。 行业已经看清了:Agent 的本质不是魔法,而是分布式系统中的状态机。
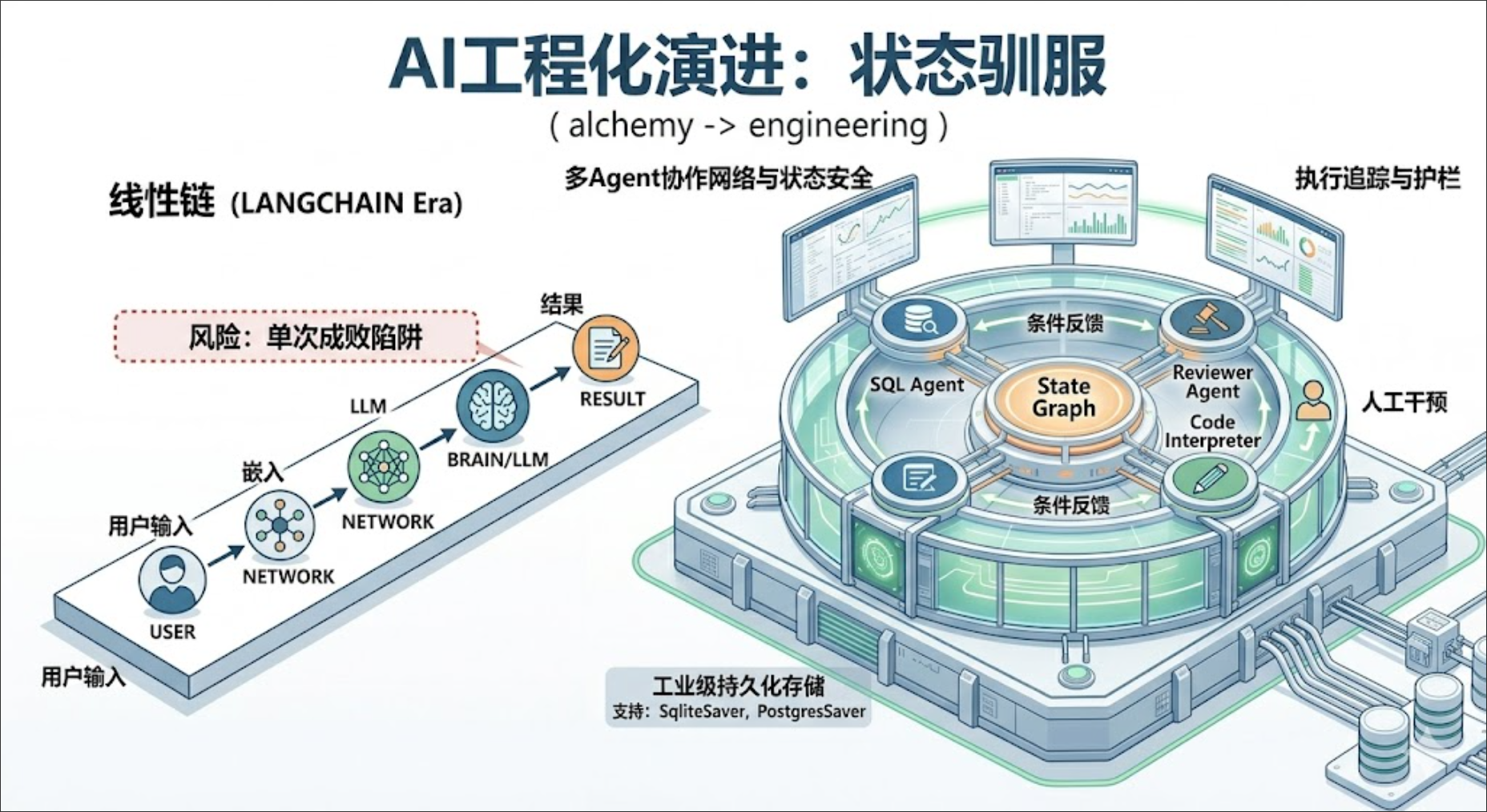
三、 LangGraph:从“链”到“图”的状态机革命
如果说 LangChain 的核心概念是 Chain(线性的、单向的),那么 LangGraph 的核心就是 Graph(循环的、网络状的)。
LangGraph 抛弃了把所有东西都看作“链”的执念,直接把底层重构在了一个带状态的图(StateGraph)之上。它有三个最核心的概念:
-
Node(节点):普通的 Python 函数(或者 LCEL Chain),负责接收当前状态,执行业务逻辑,然后返回更新后的状态字典。
-
Edge(边):定义了节点之间的流转方向。可以是确定性的边,也可以是根据上一步输出动态决定的条件边(Conditional Edge)。
-
State(状态):图的灵魂。它是一个在所有节点之间流转、共享且支持多版本追加的上下文对象。
光看概念挺抽象,我们直接来看一个在企业里非常经典的“报告多轮修正与自动审核”工程架构代码片段。
Python
from typing import TypedDict
from langgraph.graph import StateGraph, END
# 1. 定义全局状态。每个节点都可以读取并修改这个状态
class AgentState(TypedDict):
input: str
draft: str
critique: str
revision_count: int
# 2. 定义各个节点(Nodes)
def writer_node(state: AgentState):
print("--- 执行:生成/修改节点 ---")
current_count = state.get("revision_count", 0)
# 模拟大模型根据 critique(如果存在)进行内容修正
return {"draft": "这是优化后的企业报告内容...", "revision_count": current_count + 1}
def critic_node(state: AgentState):
print("--- 执行:审核节点 ---")
# 另一个模型或者规则引擎负责挑刺,给出评估意见
return {"critique": "报告缺乏数据支撑,需要补充具体的财务对比。"}
# 3. 定义条件边(Conditional Edge)的路由逻辑
def should_continue(state: AgentState):
# 容错:超过 3 次强制通过,防止死循环烧 Token
if state["revision_count"] >= 3:
return "accept"
if "满意" in state.get("critique", ""):
return "accept"
return "reject"
# 4. 构建 StateGraph 拓扑结构
workflow = StateGraph(AgentState)
# 注册节点
workflow.add_node("writer", writer_node)
workflow.add_node("critic", critic_node)
# 设置起点和常规边
workflow.set_entry_point("writer")
workflow.add_edge("writer", "critic")
# 设置条件边:从 critic 节点出来后,走哪个方向?
workflow.add_conditional_edges(
"critic",
should_continue,
{
"accept": END, # 结束流程
"reject": "writer" # 驳回,让打字机节点重新写
}
)
# 编译图
app = workflow.compile()
为什么说这种架构才是真正的工程化?
第一,状态的显式管理。在整个图的运行过程中,AgentState 是唯一事实来源(Single Source of Truth)。你可以清晰地看到每一步谁修改了什么,告别了隐式全局变量导致的雪崩。
第二,彻底解决了死循环和幻觉失控。你可以像我在 should_continue 里写的那样,极其优雅地加入确定性的工程计数器(如 revision_count >= 3)。大模型再怎么幻觉,也逃不出工程逻辑给你画的边界。
第三,天然支持持久化与断点重启(Checkpointing)。这是企业级应用最核心的痛点。如果一个跨国供应链的 Agent 任务要跑半个小时,中间因为 network 抖动挂了,在 LangGraph 里,你可以配置 SqliteSaver 或 PostgresSaver,直接通过 Thread ID 从上一个成功的 Node Checkpoint 恢复执行,而不需要从头开始烧 Token。
四、 现代企业级 AI 架构的通用范式
现在行业里真正成熟的 AI 架构,早已不是一个单独的 Python 脚本,而是一个分层明确的分布式系统。结合我个人的落地经验,一个标准的现代企业级 AI 架构通常包含以下几个层级:
| 架构层级 | 核心组件 / 技术栈 | 在体系中的真实职责 |
| 接入与网关层 | API Gateway, Kong, OneAPI | 负责多模型分发、Token 熔断限流、企业内部鉴权、敏感词过滤(Guardrails)。 |
| 多 Agent 编排层 | LangGraph, MetaGPT | 负责复杂业务流状态机管理、跨部门 Agent 协同、Human-in-the-loop 审批流挂起(Thread Breakpoints)。 |
| 原子能力层 (RAG/Tools) | LangChain (LCEL), LlamaIndex | 提供标准化的组件能力。比如统一的 Tool Calling 接口、向量检索 Pipeline、文档切分与多模态解析。 |
| 数据与存储层 | Milvus, PGVector, Redis | 负责向量数据的秒级检索,以及 Agent 长期/短期记忆(Memory)与节点 Checkpoint 的持久化存储。 |
| 可观测性监控层 | LangSmith, Langfuse | 生产环境的“黑匣子”。监控每一个 Token 的消耗、每一个 Tool 的延迟、LLM 产出的幻觉率与准确率分析。 |
在这个体系里,LangChain 和 LangGraph 的定位非常清晰:LangChain 往下走,做实做稳原子能力的组件库;LangGraph 往上走,做强做大复杂业务的编排器。
这也是为什么现在很多大厂的面试官在面 AI 架构师时,不再问你“什么是 Temperature”或者“怎么写 System Prompt”,而是盯着以下这些硬核的工程细节问:
-
“在高并发场景下,多个并发请求读写同一个 Thread ID 时,如何保证 LangGraph 状态存储的线程安全?”
-
“当 Tool Calling 返回的数据量超过 LLM 的 Context Window(上下文窗口)时,你的动态截断与重构策略是什么?”
-
"在前后端分离架构中,如何将 LangGraph 的中途挂起状态(
interrupt_before)序列化到数据库,并通过 Webhook 唤醒实现人工审批?"
这些问题,如果没有真正写过生产环境的 Graph,是根本答不上来的。
五、 行业观察与避坑指南:写给正在转型的工程师
最后,抛开技术细节,聊聊我这两年在这个行业里看到的一些趋势和教训。
1. 放弃对“全能通用 Agent”的幻觉
别再试图做一个能帮你干所有事的老板助理 Agent 了。在企业内部,多 Agent 协同(Multi-Agent Team)才是正解。让一个 Agent 专门做数据查询(SQL Agent),一个专门做图表生成(Code Interpreter Agent),一个专门做合规风控(Reviewer Agent)。用 LangGraph 把它们串联起来,彼此之间通过严格定义的 Schema 通信。把复杂问题拆小,是软件工程几十年不变的真理,对 AI 同样适用。
2. 拥抱本地小模型 + 领域工作流
很多企业天天盯着顶级闭源大模型望洋兴叹,觉得算力成本吃不消。但实际上,通过合理的工作流拆解,利用 LangGraph 把复杂的推理步骤拆散,在很多特定节点上,经过微调(Fine-tune)的本地小模型,配合上确定性的 Tool Calling 和严格的边界定义,其业务表现完全不输高昂的闭源大模型。
3. Trace(链路追踪)比什么都重要
很多团队在开发阶段觉得玩得很嗨,一上线就两眼一抹黑。用户反馈“AI 胡说八道了”,你根本不知道是哪一步的 Vector 没查出来,还是哪一步的 Agent 走错了条件分支。在写第一行编排代码之前,先把 LangSmith 或者 Langfuse 接入进来。 看不见的系统是无法优化的。
结语
AI 工程化正在从“炼丹”走向“筑路”。
从 LangChain 的线性管道,到 LangGraph 的状态图机,技术演进的背后,是整个行业对大模型局限性的务实妥协,也是软件工程对不确定性系统的强力驯服。
作为工程师,我们不需要去神化 Agent,也不用悲观地认为大模型只是个高级的外包。把 LLM 当成一个具有概率特性的特殊状态机节点,用严谨的图结构去约束它、包容它、驾驭它。这,就是现代 AI 工程化的必经之路。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)