
* LangChain4j 中的RAG 核心 API
上一篇文章我们通过 langchain4j-easy-rag 快速实现了 RAG,但“内存版”的简易方案难以直接用于生产——服务重启数据丢失、重复向量化浪费 tokens、检索精度不够。本文将深入 LangChain4j 的 RAG 核心 API,把文档加载、解析、分割、向量模型、向量数据库全部升级为更适合实际业务的配置,让你的 AI 知识库既稳又准。
回顾 RAG 存储流程,五大核心 API 浮出水面

无论多复杂的 RAG 管线,存储过程都可拆解为以下几个步骤:
-
加载文档 —— 使用 Document Loader 将 PDF、Word 等文件加载进内存。
-
解析内容 —— 使用 Document Parser 提取纯文本。
-
分割文本 —— 使用 Document Splitter 将长文档切割成适合检索的小片段。
-
向量化 —— 使用 Embedding Model 把文本片段转成向量。
-
存入向量数据库 —— 使用 EmbeddingStore 持久化向量与原文。
在之前的快速入门中,EmbeddingStoreIngestor 把这五步封装成了一个黑盒。现在,我们就逐一拆解每个环节的 API,看看如何将它们替换为更强大的方案。
一、文档加载器:不止 ClassPath 一种选择
LangChain4j 提供了多个文档加载器,覆盖常见的读取场景:
-
ClassPathDocumentLoader:从类路径加载。 -
FileSystemDocumentLoader:从磁盘绝对路径加载。 -
UrlDocumentLoader:从网络 URL 加载。
如果你想指定一个绝对路径来加载文档,将之前的 ClassPathDocumentLoader 替换成 FileSystemDocumentLoader 即可:
/**
* 加载文档到向量数据库
*/
@RequestMapping("/loadDocuments")
public void loadDocuments() {
//1.加载文档进内存
//List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
List<Document> documents = FileSystemDocumentLoader.loadDocuments(
"C:\\Users\\Administrator\\ideaProjects\\consultant\\src\\main\\resources\\content"
);
//2.构建一个EmbeddingStoreIngestor对象,完成文本数据切割,向量化, 存储
EmbeddingStoreIngestor embeddingStoreIngestor = EmbeddingStoreIngestor.builder()
.embeddingStore(embeddingStore)
.build();
embeddingStoreIngestor.ingest(documents);
}这样一来,你就可以自由选择文档的来源,不必局限于 resources 目录。
二、文档解析器:让 PDF 解析更专业
文档解析器就是用于解析文档中的内容,把原本非纯文本数据转化成纯文本。比如初始的文档是pdf格式的,它的内容就不是纯文本的,此时需要借助于文档解析器将非纯文本数据转化成纯文本。在LangChain4j中提供了几个常用的文档解析器:
-
TextDocumentParser,解析纯文本格式的文件
-
ApachePdfBoxDocumentParser,解析pdf格式文件
-
ApachePoiDocumentParser,解析微软的office文件,例如DOC、PPT、XLS
-
ApacheTikaDocumentParser(默认),几乎可以解析所有格式的文件
默认情况下,LangChain4j 使用 ApacheTikaDocumentParser,它几乎能解析所有格式(PDF、Word、PPT 等),是一个“万金油”方案。但具体到 PDF 文件,Tika 可能不如专有解析器精准或轻便。于是,我们可以换成 ApachePdfBoxDocumentParser,专门解析 PDF。
2.1引入 PDF 解析依赖
<!-- Source: https://mvnrepository.com/artifact/dev.langchain4j/langchain4j-document-parser-apache-pdfbox -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
<version>1.15.0-beta25</version>
</dependency>2.2在加载文档时指定解析器
List<Document> documents = ClassPathDocumentLoader.loadDocuments(
"content", new ApachePdfBoxDocumentParser()
);3.3 记得将 content 目录下的《西北大学.md》替换为《西北大学.pdf》,让 PDF 解析器真正派上用场。
三、文档分割器:让每个片段都“讲得清”
文本分割是决定检索精度的关键一步。LangChain4j 内置了 7 种分割器:
-
DocumentByParagraphSplitter:按段落切 -
DocumentByLineSplitter:按行切 -
DocumentBySentenceSplitter:按句子切 -
DocumentByWordSplitter:按单词切 -
DocumentByCharacterSplitter:按固定字符数切 -
DocumentByRegexSplitter:按正则表达式切 -
DocumentSplitters.recursive(...)(默认):递归分割,优先按段落,再按行、句子、词
最常用的便是递归分割器,它能够智能地避免一个自然段刚好被拦腰截断。你还可以配置两个核心参数:
-
最大字符数:单个文本片段包含的字符上限(默认 300)。
-
重叠字符数:相邻片段之间共享的字符数量,用来保持语义连贯,避免“高考”等关键词因切割而丢失。
先说第一种按照段落分割文本,举个例子,假设我们文本中的内容是一片散文,总共由6个段落组成。

那么DocumentByParagraphSplitter就会把文档分割成6个部分,但是这里大家要注意的是这每一部分并不是将来进行向量化的文本片段,文本片段是根据这6部分的内容组合而成的。通常情况下LangChain4j是允许我们指定文本片段的字符容量的,假设我指定单个文本片段的字符容量为300,那么在组合文本片段的时候,第一部分的自然段和第二部分的自然段的字符总和不到300,可以放到同一个文本片段中,但是加上第三部分的自然段,字符总和超过了300,那么第三部分的自然段就不能再放到这个文本片段中了,而是放到下一个新的文本片段中。
当然除了按照段落分割文本,LangChain4j还提供了按行分割、按句子分割、按单词分割、按固定数量的字符分割等等不同方式的文档分割器,都可以使用。这里我们关注一下最后一种文本分割器,它是通过一个静态方法recursive创建出来的,叫做递归分割器,它组合了段落分割器、行分割器、句子分割器以及词分割器,它会按照优先级进行分割文档,先按照段落分割,再按照行,再按照句子,最后按照词,有什么用呢?
咱们刚才按段落分割,第三个自然段是不是放不下了?此时如果是递归分割器的话它会继续使用行分割器,把第三个自然段进一步分割,尝试把得到的内容放到当前文本片段中,如果还是不行,再按照句子分割,这就是它的作用。
咱们默认使用的也是这种递归分割器,默认使用的单个文本最大字符个数就是300,当然了,我不想使用这个默认的切割器,我觉得300个字符太少了,我想多设置一点儿,行不行呢?也可以,接下来我们看应该如何操作。
3.1构建并配置分割器
DocumentSplitter documentSplitter = DocumentSplitters.recursive(
每个片段最大容纳的字符,
两个片段之间重叠字符的个数
);// 每个片段最多 500 字符,相邻片段重叠 100 字符
DocumentSplitter ds = DocumentSplitters.recursive(500, 100);
然后将它传给 EmbeddingStoreIngestor:
/**
* 加载文档到向量数据库
*/
@RequestMapping("/loadDocuments")
public void loadDocuments() {
//1.加载文档进内存
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content",
new ApachePdfBoxDocumentParser()
);
/*List<Document> documents = FileSystemDocumentLoader.loadDocuments(
"C:\\Users\\Administrator\\ideaProjects\\consultant\\src\\main\\resources\\content",
new ApachePdfBoxDocumentParser()
);*/
//2.构建文档分割器对象 每个片段最多 500 字符,相邻片段重叠 100 字符
DocumentSplitter documentSplitter = DocumentSplitters.recursive(500,100);
//3.构建一个EmbeddingStoreIngestor对象,完成文本数据切割,向量化, 存储
EmbeddingStoreIngestor embeddingStoreIngestor = EmbeddingStoreIngestor.builder()
.embeddingStore(embeddingStore)
.documentSplitter(documentSplitter)
.build();
embeddingStoreIngestor.ingest(documents);
}四、向量模型:从“能用”到“精准”
向量模型的作用是把分割后的文本片段向量化或者把用户消息向量化。
public interface EmbeddingModel {
default Response<Embedding> embed(String text) {
return this.embed(TextSegment.from(text));
}
default Response<Embedding> embed(TextSegment textSegment) {
}
Response<List<Embedding>> embedAll(List<TextSegment> texts);
default int dimension() {
return ((Embedding)this.embed("test").content()).dimension();
}
}LangChain4j中提供了EmbeddingModel接口用于定义有关向量模型的方法,例如有embed、embedall等等方法用于把文本片段向量化。LangChain4j提供了一个内存版本的向量模型实现方案,而咱们快速入门中使用的就是这个向量模型,只是咱们当时并没有指定这个向量模型,因为它被封装到EmbeddingStoreIngestor中了,所以我们并没有看到。
但是这种内置的向量模型内有时候功能没有那么强大,说白了就是支持的向量维度太少,检索的时候没有那么精准,所以有些情况下我们需要替换它,使用一些功能更强大的向量模型。阿里云百炼平台也提供了专门用于向量化的向量模型text-embedding-v3,接下来我们看应该如何把我们程序中内存版本的向量模型替换成阿里云百炼提供的向量模型。
4.1 在配置文件中添加向量模型信息
langchain4j:
open-ai:
embedding-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: ${API-KEY}
model-name: text-embedding-v3
log-requests: true
log-responses: true4.2 注入并使用 EmbeddingModel
当我们配置完毕后,LangChain4j会自动的根据我们的配置信息往IOC容器中注入一个EmbeddingModel对象供我们使用,所以接下来我们只需要把这个EmbeddingModel对象交给EmbeddingStoreIngestor和EmbeddingStoreContentRetriever即可,一个是存储的时候使用,一个是检索的时候使用。
package com.langchan4jSpringBoot.config;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.store.embedding.EmbeddingStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 向量检索配置类
* 负责配置 LangChain4j RAG 架构中的内容检索组件
*/
@Configuration
public class EmbeddingConfig {
@Autowired
private EmbeddingModel embeddingModel;
/**
* 创建内容检索器 Bean
* 用于从向量数据库中检索与查询最相关的内容片段,支持 RAG(检索增强生成)场景
*
* @param embeddingStore 向量存储接口,由 Spring 自动注入,负责实际的向量数据存储和查询
* @return ContentRetriever 内容检索器实例
*/
@Bean
public ContentRetriever contentRetriever(EmbeddingStore embeddingStore) {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore) // 设置向量数据库操作对象
.minScore(0.5) // 设置相似度阈值,低于此分数的结果将被过滤
.maxResults(3) // 设置最大返回片段数量,控制上下文窗口大小
.embeddingModel(embeddingModel)
.build();
}
}
@Autowired
private EmbeddingModel embeddingModel;
/**
* 加载文档到向量数据库
*/
@RequestMapping("/loadDocuments")
public void loadDocuments() {
//1.加载文档进内存
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content",
new ApachePdfBoxDocumentParser()
);
/*List<Document> documents = FileSystemDocumentLoader.loadDocuments(
"C:\\Users\\Administrator\\ideaProjects\\consultant\\src\\main\\resources\\content",
new ApachePdfBoxDocumentParser()
);*/
//2.构建文档分割器对象 每个片段最多 500 字符,相邻片段重叠 100 字符
DocumentSplitter documentSplitter = DocumentSplitters.recursive(500,100);
//3.构建一个EmbeddingStoreIngestor对象,完成文本数据切割,向量化, 存储
EmbeddingStoreIngestor embeddingStoreIngestor = EmbeddingStoreIngestor.builder()
.embeddingStore(embeddingStore)
.documentSplitter(documentSplitter)
.embeddingModel(embeddingModel)
.build();
embeddingStoreIngestor.ingest(documents);
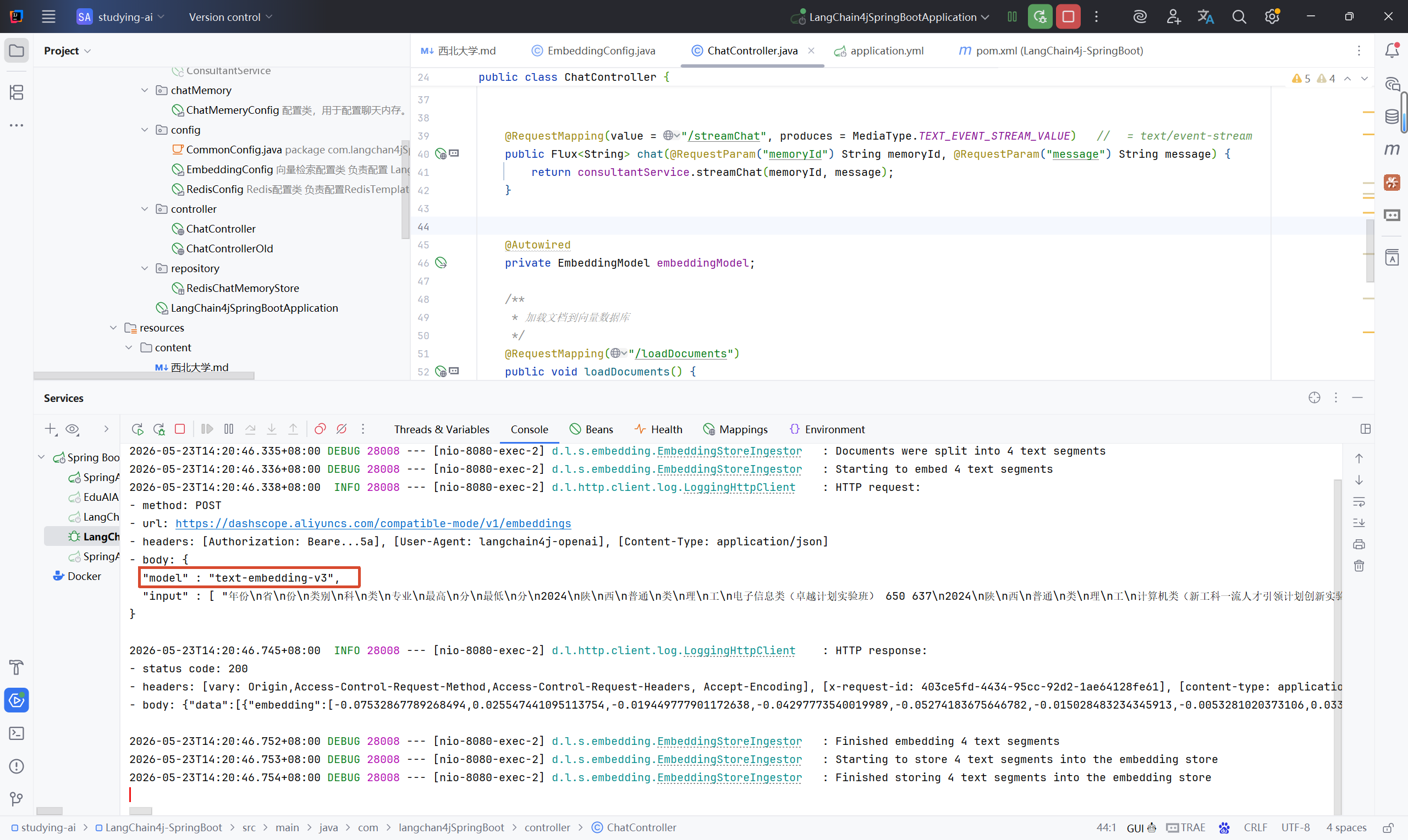
}测试的时候大家可以查看IDEA控制台的日志,确保替换完成。
五、向量数据库操作对象:挥别内存,拥抱 Redis
EmbeddingStore是用来操作向量数据库的API,将来不管是存储还是检索都需要借助于它来完成。LangChain4j提供的EmbeddingStore接口中提供了两组方法,分别是add用于存储数据,search用于检索数据。
public interface EmbeddingStore<Embedded> {
String add(Embedding embedding);
void add(String text, Embedding embedding);
String add(Embedding embedding, Embedded embedded);
List<String> addAll(List<Embedding> embeddings);
EmbeddingSearchResult<Embedded> search(EmbeddingSearchRequest request);
}同时LangChain4j还提供了一个实现方案InMemoryEmbeddingStore,也就是咱们之前一直使用的方案,但是这它操作的是内存向量数据库,有些情况下不能满足实际开发中的需求。大家可以想一下,如果我们使用内存向量数据库,一旦服务器重启数据就丢失了,又得重新加载文档、重新向量化,这样每次启动都会比较耗时,还有就是每次启动都会使用百炼平台提供的向量模型完成向量化,它是收费的,每次都这么干那是跟钱过不去,没必要对吧。

所以咱们得考虑把向量化后的数据存储到外部的向量数据库中。之前给大家介绍过常见的向量数据库有Milvus、Chroma、Pinecone、RediSearch以及pgvector, 用哪一种都行,LangChain4j对这些向量数据库都做了支持。本文将采用redisearch存储向量数据。接下来我们看看具体的操作。
5.1 用 Docker 启动 RedisSearch
先把之前部署的标准 Redis 容器停止并删除(如果有),然后运行支持向量搜索的新镜像:
docker stop redis
docker rm redis
docker run --name redis-vector -d -p 6379:6379 redislabs/redisearch5.2 引入 Redis 起步依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-redis-spring-boot-starter</artifactId>
<version>合适版本</version>
</dependency>5.3 配置连接
langchain4j:
community:
redis:
host: localhost
port: 6379启动时框架会自动创建 RedisEmbeddingStore 实例。
5.4 用 RedisEmbeddingStore 替换内存 store
@Autowired
private RedisEmbeddingStore redisEmbeddingStore;
@Bean
public EmbeddingStore store() {
List<Document> documents = ClassPathDocumentLoader.loadDocuments(
"content", new ApachePdfBoxDocumentParser()
);
DocumentSplitter ds = DocumentSplitters.recursive(500, 100);
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(redisEmbeddingStore) // 存入 Redis
.documentSplitter(ds)
.embeddingModel(embeddingModel)
.build();
ingestor.ingest(documents);
return redisEmbeddingStore;
}
@Bean
public ContentRetriever contentRetriever() {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(redisEmbeddingStore) // 从 Redis 检索
.minScore(0.5)
.maxResults(3)
.embeddingModel(embeddingModel)
.build();
}现在,你的向量数据就稳稳地躺在 Redis 里了,服务重启也不怕。
六、总结
本文沿着 RAG 的存储管线,逐一解析了 LangChain4j 的五大核心 API,并完成了从“入门玩具”到“生产可用”的关键升级:
| 组件 | 入门方案 | 升级方案 |
|---|---|---|
| 文档加载器 | ClassPathDocumentLoader | 按需选用 FileSystem / Url 加载器 |
| 文档解析器 | ApacheTika(默认) | ApachePdfBoxDocumentParser(PDF专精) |
| 文档分割器 | 默认递归分割(300字符) | 自定义递归分割(500字符,100重叠) |
| 向量模型 | 内存版低维模型 | 阿里云 text-embedding-v3 |
| 向量数据库 | InMemoryEmbeddingStore | RedisSearch(数据持久化) |
掌握这些 API 的配置和替换方法后,你就可以根据实际业务需求,灵活地组装出高精准、低成本、可持续运行的企业级 RAG 知识库。快动手试试,让你的 AI 助手真正成为“最新数据张口就来”的专家吧!

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)