
Claude Code 最反直觉的地方,不是多 Agent,而是它处处在防人的直觉
给看过 Claude Code、但还没真正看懂它设计味道的人写的一篇大白话拆解
最近我重读了一遍小林coding那篇讲 Claude Code 多 Agent 机制的文章,越看越觉得它真正厉害的地方,不是“多 Agent”这三个字本身,而是它在很多关键点上,都故意跟人的第一直觉反着来。
按人的第一反应,我们会觉得:
- 子 Agent 当然应该共享更多上下文,不然不就什么都不知道了吗?
- 父子 Agent 通信,直接函数调用最顺手,为什么还要绕?
- 一个 Agent 干完任务就该结束,为什么还要“叫醒”它?
- 主 Agent 当然应该最强、最会干活,为什么要把它削成一个协调员?
- 成本优化应该是后面的事,先把能力做出来再说。
但 Claude Code 偏不这么干。
它的思路更像是在说:**工业级 Agent 系统,最怕的不是“不够聪明”,而是“太按人的直觉去实现”。**
所以这篇文章,我不想再顺着源码讲一遍流程。我想做三件事:
- 第一,先把原文的结构重新梳理清楚。
- 第二,把文里出现的 Claude / Claude Code 的反直觉设计全部重新归类。
- 第三,站在企业级 Agent 的角度,讲清楚这些设计到底值不值得学。
一句大白话:Claude Code 的设计哲学,不是“让每个 Agent 更强”,而是“让整个系统别失控”。
一、先把原文结构重新捋一遍:它表面在讲多 Agent,底层其实在讲“怎么防失控”
那篇文章表面上是按源码模块在讲,但如果你换个角度看,它其实是一个非常标准的“先立问题,再拆反直觉设计,再提原则”的结构。
我把它重新整理成 6 步:
1. **先回答:为什么一个 Agent 不够。**
这一段不是铺垫,而是整个问题意识的起点。因为只有先讲清楚上下文爆炸、职责混乱、无法并发,后面的多 Agent 才不是炫技。
2. **再讲隔离机制。**
这部分是核心中的核心。Claude Code 不是先讲“怎么派 Agent”,而是先讲“派出去以后怎么别把主线程搞乱”。
3. **然后讲通信机制。**
这里真正反直觉的点是:它不用直接函数返回,而是用消息驱动、异步通知。
4. **再讲 Fork Subagent。**
这部分看起来像优化细节,实际上是在讲一个非常关键的生产级问题:成本和延迟,不是后优化,而是架构的一部分。
5. **再讲 Coordinator 模式。**
这里才真正进入“多 Agent 并行协作”的主战场,而且它不是简单多派几个 worker,而是把主 Agent 的角色彻底改掉。
6. **最后收束成一组设计原则。**
也就是说,这篇文章最后真正想交付给读者的,不只是 Claude Code 的源码知识,而是一套能拿去面试、拿去做系统设计的判断框架。
所以如果让我一句话总结原文结构,我会这么说:
**它不是在教你“Claude Code 里有几个 Agent 模式”,而是在教你“工业级 Agent 为什么要故意违背你的实现直觉”。**
二、我把文中所有 Claude / Claude Code 的反直觉设计,重新归成 10 条
下面这 10 条,是我把原文里那些零散设计点重新归并后的版本。你会发现,单看每一条都不复杂,但合在一起,就是一整套很成熟的工程哲学。
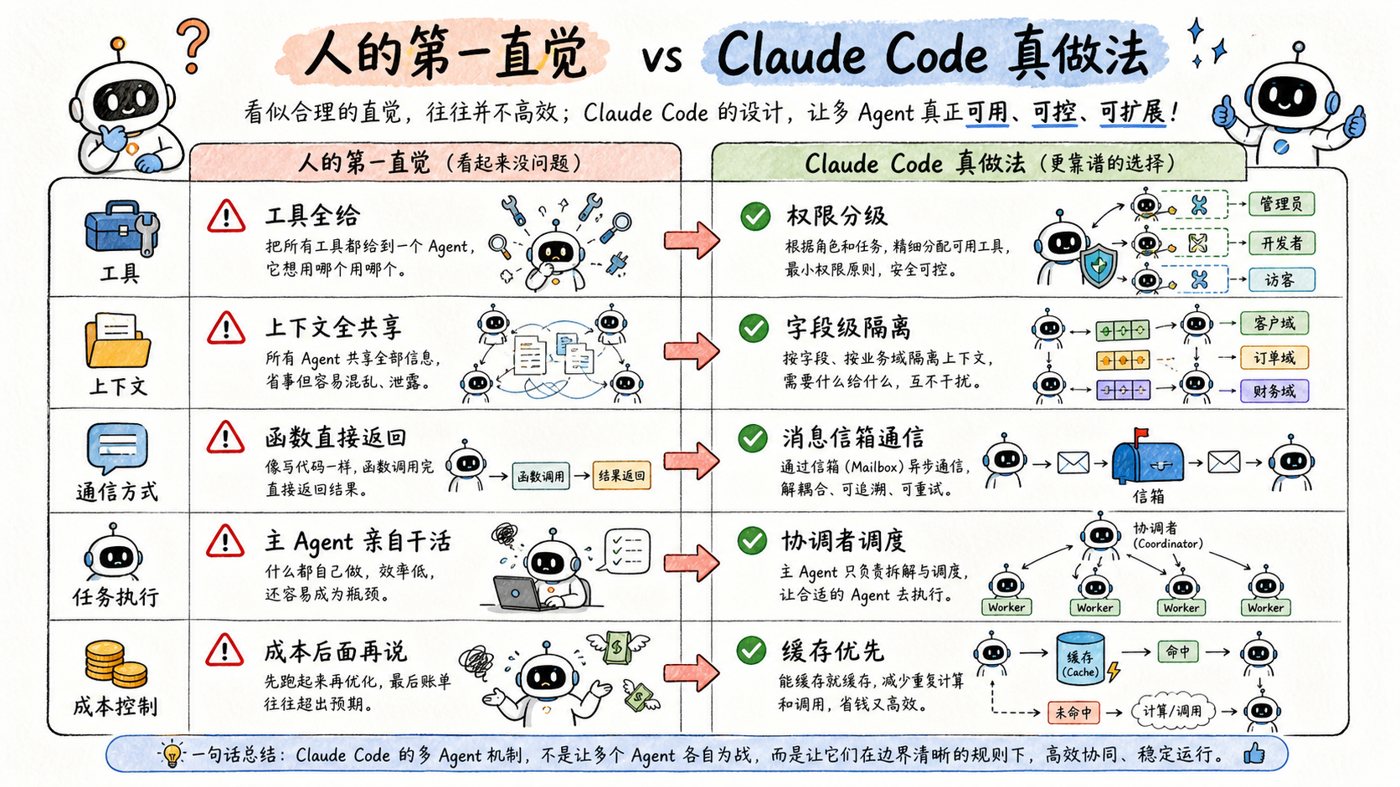
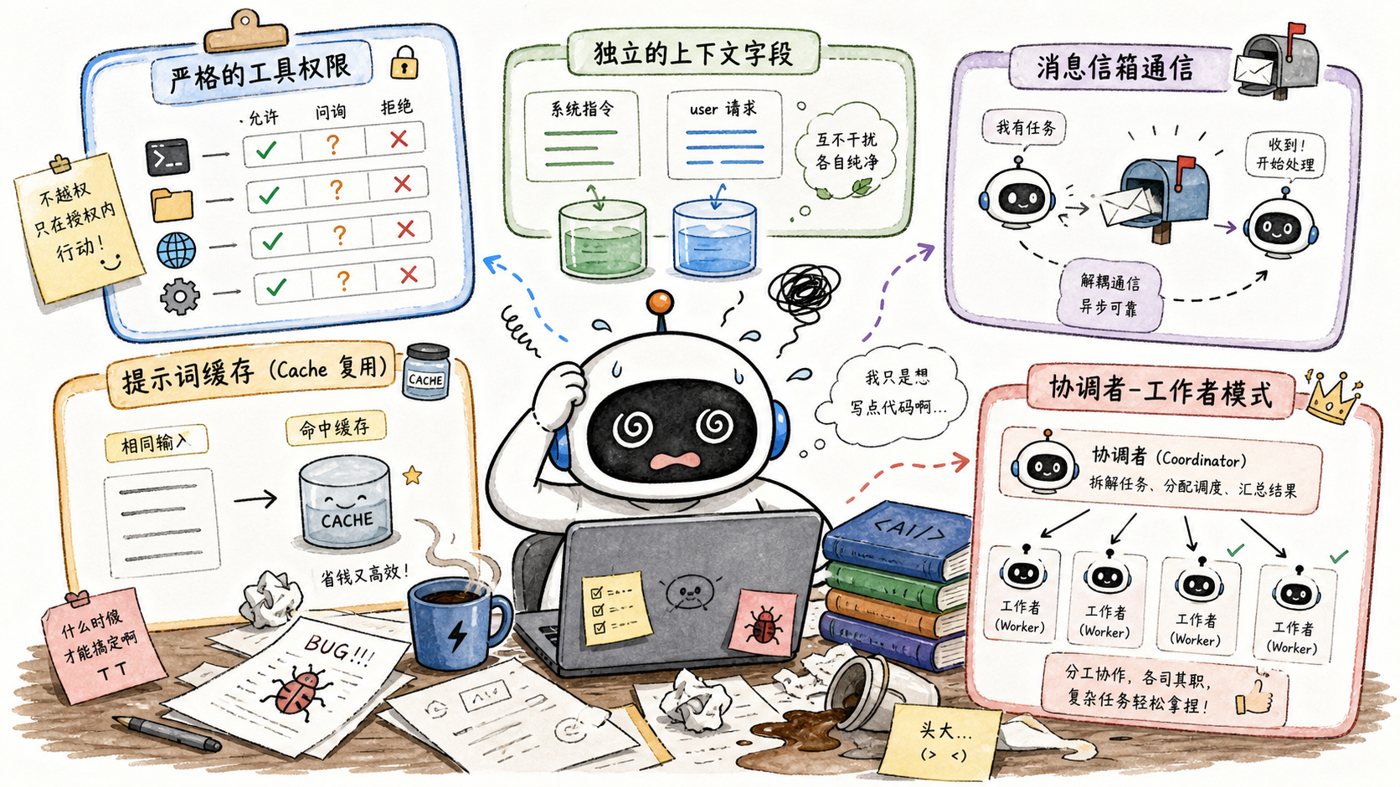
1. 不是所有 Agent 都该拥有全部工具,而是越往下走,权限越小
普通人的直觉是:既然子 Agent 也是 Agent,那工具给全一点,它不是更能干活吗?
Claude Code 的思路正相反。它先把一批工具列进全局黑名单,再对自定义 Agent 额外加限制,异步后台 Agent 甚至直接走白名单。
这背后的意思很狠:**能力不是越多越好,能力只要超过边界,就会开始制造系统复杂度。**
子 Agent 如果也能继续派 Agent、也能乱问用户、也能改任务管理状态,那它不是更强,而是在给系统制造递归失控的机会。
2. 不是“全共享”或“全新建”,而是按字段粒度做上下文隔离
这是我觉得最值得抄走的一条。
我们很容易在两个极端里选:
- 要么父子共享同一份上下文;
- 要么给子 Agent 一份全新的上下文。
Claude Code 说:两个都不对。
它的做法是按字段拆:
- 读文件缓存要克隆,避免污染父 Agent 的阅读视图;
- 全局 UI 状态不让子 Agent 写;
- 任务注册通路要保留;
- 嵌套深度和身份追踪要单独维护。
也就是说,它的答案不是“共享还是不共享”,而是:**这项状态到底该复制、该屏蔽、该共享,还是该新建?**
这就是成熟系统和演示系统的差别。
3. 不是让子 Agent 也能改全局状态,而是干脆把写权限关掉
这点特别反人性。
人的直觉是:既然子 Agent 也在干活,它当然应该能改状态。
Claude Code 直接说,不给。
原因也很简单:只要异步子 Agent 能写主线程的全局状态,就一定会出现竞态条件。两个地方同时写同一份东西,界面、任务、状态就会开始互相抢。
所以它不是去“优化并发写状态的冲突”,而是更直接:**从权限上彻底不让你写。**
很多系统最稳定的设计,不是把冲突处理得更优雅,而是从架构上别让冲突发生。
4. 不是一刀切全禁写,而是专门给“后台任务登记”留后门
这条就更妙了。
如果把子 Agent 的全局写权限全禁掉,会不会有副作用?有。
比如它自己启动的后台命令、后台 bash 进程,总得有个地方登记,不然主系统根本不知道这东西还活着,最后就会变成孤儿任务。
所以 Claude Code 的做法不是简单粗暴的“全部禁止”,而是:
- 大部分写状态通路全关;
- 但“注册/结束后台任务”这条路必须保留。
这说明它在设计时想的不是“我要不要隔离”,而是“我隔离之后,系统最基本的回收和治理能力还能不能工作”。
5. 不是父子之间直接函数调用,而是像发短信一样走消息队列
这是原文里我最喜欢的一类反直觉设计。
正常工程师一上来会想:父 Agent 派个子任务,不就调个函数等返回吗?
Claude Code 说,不这么做。
它采用的是:
- 父 Agent 往子 Agent 的消息信箱里塞一条消息;
- 子 Agent 在自己的下一轮循环里自己读这条消息;
- 子 Agent 完成之后,再异步通知父 Agent。
为什么要绕?
因为直接函数调用虽然顺手,但会把父 Agent 阻塞死,也很难优雅支持并行。消息驱动虽然看着麻烦,但天然适合长任务、并发任务、可恢复任务。
**这里反直觉的本质是:为了并发和可恢复性,它放弃了最自然的“同步返回”。**
6. 不是任务完成就彻底结束,而是可以从 transcript 里“叫醒”继续干
这也是很多人第一次看到会愣一下的设计。
大多数人会觉得:一个子 Agent 任务结束了,生命周期就结束了。
Claude Code 的做法更像“休眠”,不是“死亡”。
如果父 Agent 后面还有新需求,它可以把已经完成的子 Agent 从保存下来的 transcript 里恢复出来,拼上新消息,再继续跑。
这个设计好在哪?
- 不用重建上下文;
- 不用重新解释一遍前情;
- 更省钱;
- 更适合长链路任务的续命。
也就是说,Claude Code 不是把 Agent 当一次性函数,而是把它当一个**可暂停、可恢复、可续命的工作单元**。
7. 不是“差不多一样”就能复用缓存,而是要求字节级完全一致
这条特别适合拿去打醒那些只盯能力不盯成本的人。
Claude / Anthropic 的 prompt cache 很强,但命中条件非常苛刻:不是语义相近,不是大致相同,而是**字节级别完全一致**。
一个空格不同、一个工具顺序不同、一个动态字段变了,缓存就直接没了。
这意味着什么?
意味着 Claude Code 在设计 Fork Subagent 的时候,不能只想着“我复用一下父 Agent 的上下文”,而是必须把 system prompt、工具顺序、上下文拼接方式、消息前缀,统统锁到极致。
这条反直觉点在于:**缓存命中不是运营层的优化,而是架构层的约束。**
8. 不是重新给 Fork Agent 生成一份 prompt,而是直接复用父 Agent 已渲染好的字节
这条很细,但特别高级。
很多人会觉得:Fork 一个子 Agent,不就再生成一次 system prompt 吗?
Claude Code 不这样做。它的 Fork 机制里,有个很有意思的细节:那条子 Agent 的 prompt 生成函数直接返回空字符串。
不是因为它没 prompt,而是因为它根本不打算重新生成。
它直接拿父 Agent 那份已经渲染好的 prompt 字节复用,最大化保证缓存命中。
这说明它考虑问题的角度已经不是“功能上能不能工作”,而是“只要我重新生成一次,就有可能差一个字节,那我干脆别生成”。
这个思路非常工业级。
9. 不是让主 Agent 继续做最强执行者,而是把它削成纯协调者
Coordinator 模式最反直觉的地方,其实不在“多派 worker”,而在于它重新定义了主 Agent 的工作。
常规直觉是:主 Agent 最懂全局,也最强,所以应该一边思考、一边执行、一边调度。
Claude Code 的做法是:**主 Agent 不干具体活了,只干三件事:派活、收结果、做合成。**
这背后是一个很重要的组织设计原则:
协调和执行最好分开。
你要么是干活的人,要么是分派和判断的人。两种角色混在一起,最后往往两边都做不好。
所以 Coordinator 模式不是“更强的主 Agent”,而是“更克制的主 Agent”。
10. 不是层层递归越多越强,而是尽量限制成扁平两层
多 Agent 系统最容易让人上头的地方,就是不停往下套娃:
- 主 Agent 派子 Agent;
- 子 Agent 再派孙 Agent;
- 孙 Agent 再派重孙 Agent……
从“看起来很高级”的角度,这很诱人。
但 Claude Code 的思路很清楚:能避免递归,就避免递归。
所以在 Coordinator 模式里,它尽量维持成:
- 一个协调者;
- 一层 worker。
worker 负责执行,协调者负责调度,worker 再去协调别人这件事,被工具权限设计直接限制掉。
**它宁可少一点“理论上的灵活性”,也要多一点“现实里的可控性”。**
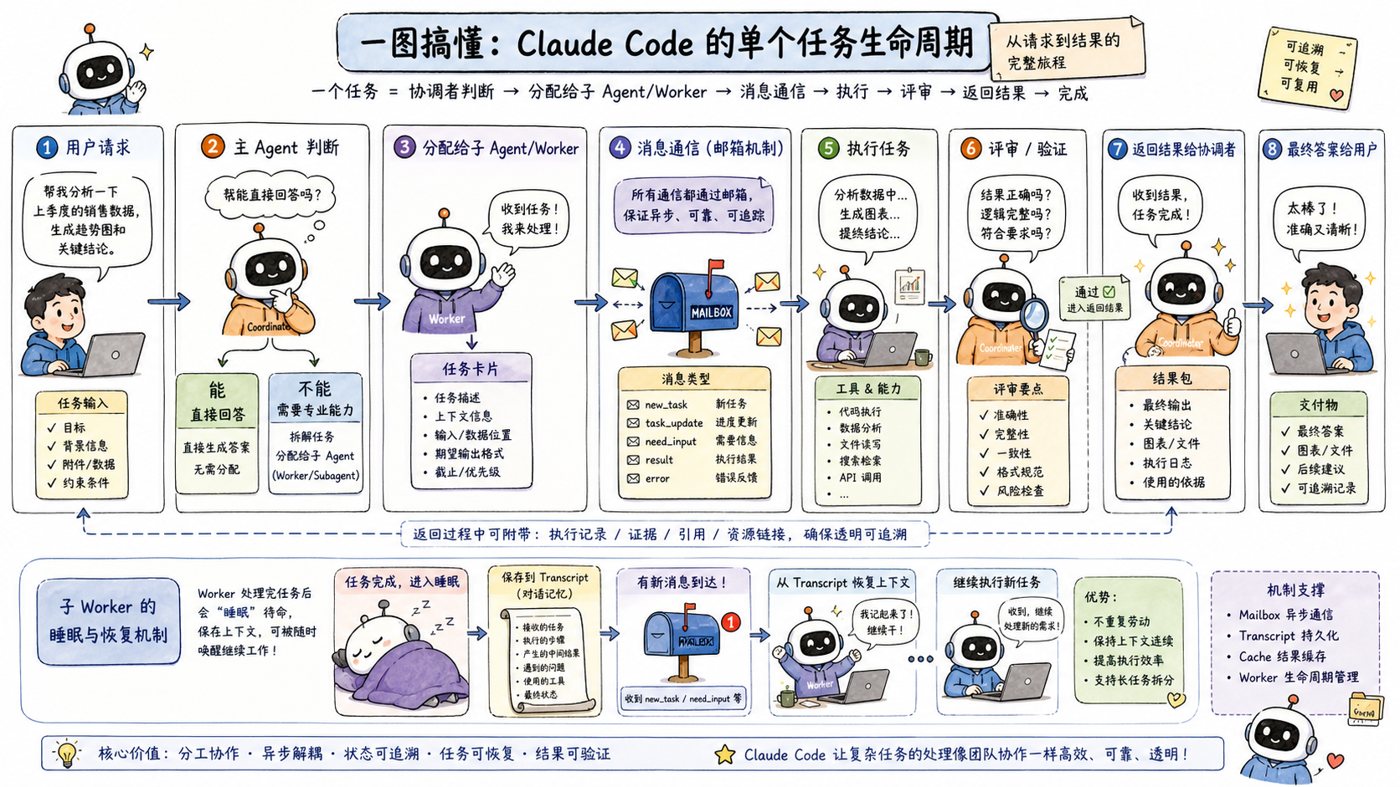
三、如果把上面 10 条缩成一句话:Claude Code 在防 5 件事
把这些反直觉设计再往下压一层,你会发现它们其实都在防同一类东西。
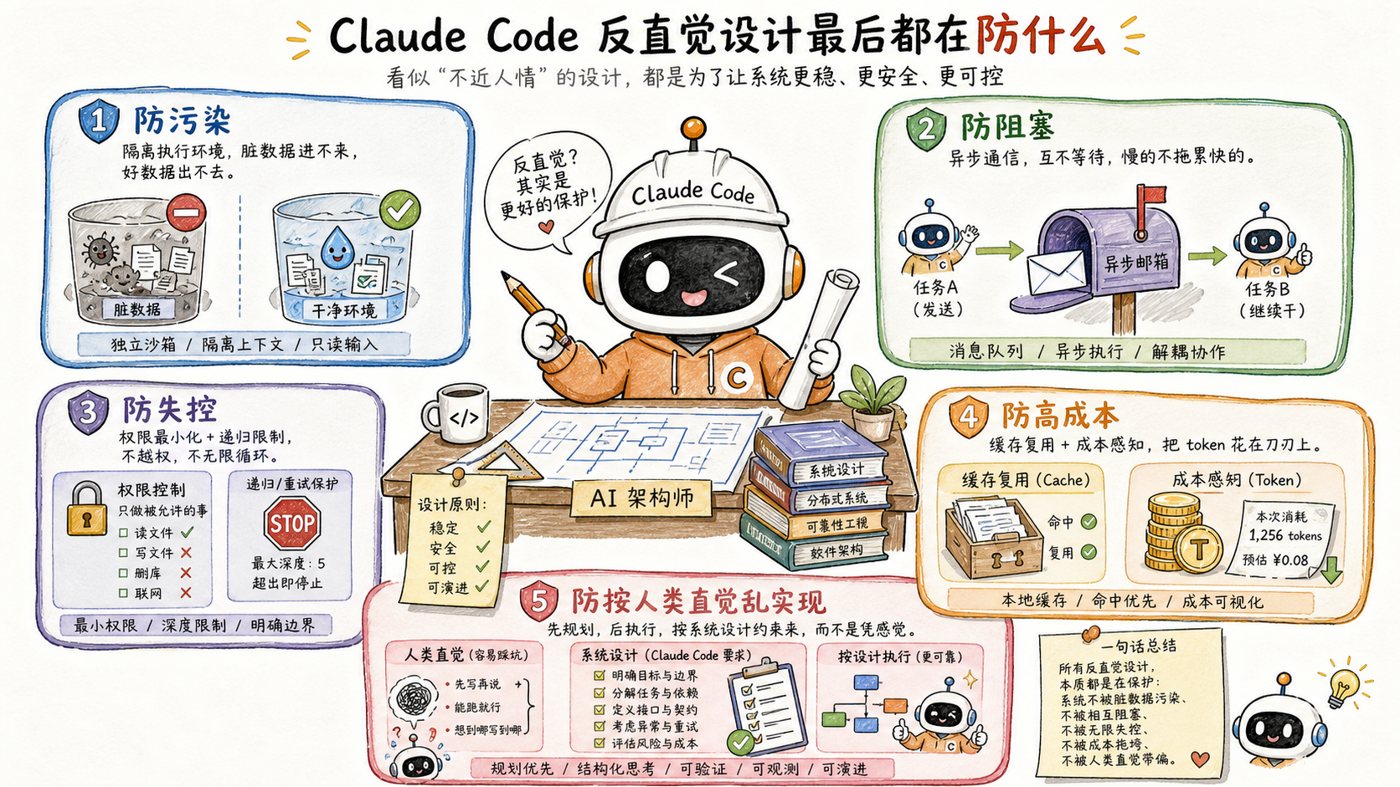
1. 防污染
上下文隔离、缓存克隆、禁写全局状态,本质上都在防一个子 Agent 影响另一个 Agent,或者影响父 Agent。
2. 防阻塞
消息队列通信、异步 worker、并行调度,本质上都在防主循环被长任务卡死。
3. 防失控
工具权限分级、深度追踪、扁平两层结构,本质上都在防递归嵌套和权限越界。
4. 防高成本
Fork Subagent、prompt cache 复用、续命而不重建,本质上都在防 token 成本和延迟线性爆炸。
5. 防“人觉得这样顺手,所以就这样实现”
这是最深的一层。
很多系统的问题,不是技术做不到,而是设计者太相信自己的第一直觉。Claude Code 这套东西最厉害的地方,就是它几乎在每个关键节点上都问了一句:
**“如果按最顺手的方式实现,系统以后会不会出事?”**
四、如果你自己要做企业级 Agent,这 5 条最值得抄
看完这些设计,别急着记名字。真正值得拿走的,是下面这 5 条。
1. 先分角色,再分模型
别一上来就纠结“哪个模型最强”。先问清楚:
- 谁负责调研?
- 谁负责实现?
- 谁负责验证?
- 谁负责最后拍板?
角色没分清,后面全会乱。
2. 工具权限一定要按身份分级
主 Agent 能做的事,子 Agent 不一定能做。
同步 Agent 能做的事,后台异步 Agent 不一定能做。
别让所有 Agent 都拿一整套工具箱,那是给系统埋雷。
3. 通信优先消息化,不要迷信同步函数调用
只要任务可能变长、可能并发、可能恢复,消息化通信几乎一定比同步直返更稳。
它看起来绕一点,但系统复杂度会低很多。
4. 成本优化不是上线之后再说,而是能力边界的一部分
Claude Code 这个案例最值得学的一点是:
它不是先做出一套“看起来很强”的多 Agent,再慢慢优化成本;
它是从设计 Fork 的那一刻起,就把缓存命中和成本控制算进架构里。
这对企业尤其重要。因为很多 Agent 不是死在功能上,而是死在账单上。
5. 真正成熟的主 Agent,往往没那么“全能”
这一点最容易被忽略。
很多人会觉得,一个系统越强,主 Agent 就应该越像“全能大脑”。
但成熟系统反而经常反过来:
- 执行的事情,分给 worker;
- 具体的调研,分给 subagent;
- 主 Agent 自己只保留判断、调度、合成。
这不是削弱,而是降噪。
五、最后给一句我自己的总结
如果只看表面,Claude Code 这套多 Agent 机制像是在回答:
“一个大任务怎么拆给多个 Agent 去做?”
但如果往深一层看,它真正回答的是:
**“当你真的想把 Agent 做成生产系统时,哪些最自然的实现方式反而最危险?”**
所以我现在觉得,Claude Code 最值得学的,不只是 Multi-Agent,而是一种更冷静的系统设计态度:
- 共享,不一定是好事;
- 递归,不一定代表强大;
- 同步,不一定更简单;
- 主 Agent,不一定该最能干;
- 成本,不一定能放到最后再考虑。
说得再直白一点:
**Agent 系统真正的水平,不在于它能不能“多派几个 Agent”,而在于它能不能在多 Agent 的情况下,依然不乱、不贵、不堵、不失控。**
这才是 Claude Code 这类系统,真正反直觉、也真正值钱的地方。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)