
【智能体】使用Ollama部署本地大模型+One API调用
一、Ollama部署本地模型
1、在官网下载ollma 官网地址: https://ollama.com/
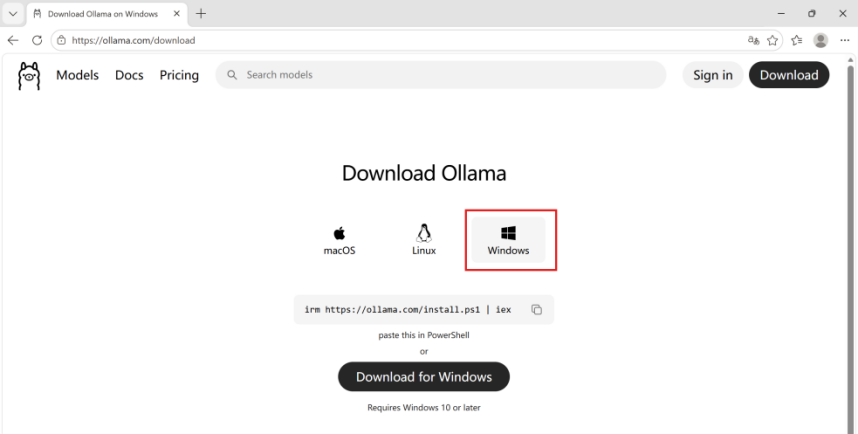
2、选择下载对应的版本,然后一路默认安装(需要在github外网上下载)
3、安装完成后,在控制台输入 ollama -v验证安装是否成功

4、在控制台运行模型,Ollama会默认吧模型文件放在C:\User\用户名ollama\models\目录下,如果需要放在其他目录下,需指定模型存放的目录

使用临时指定模型目录,再运行模型(Windows CMD 命令):
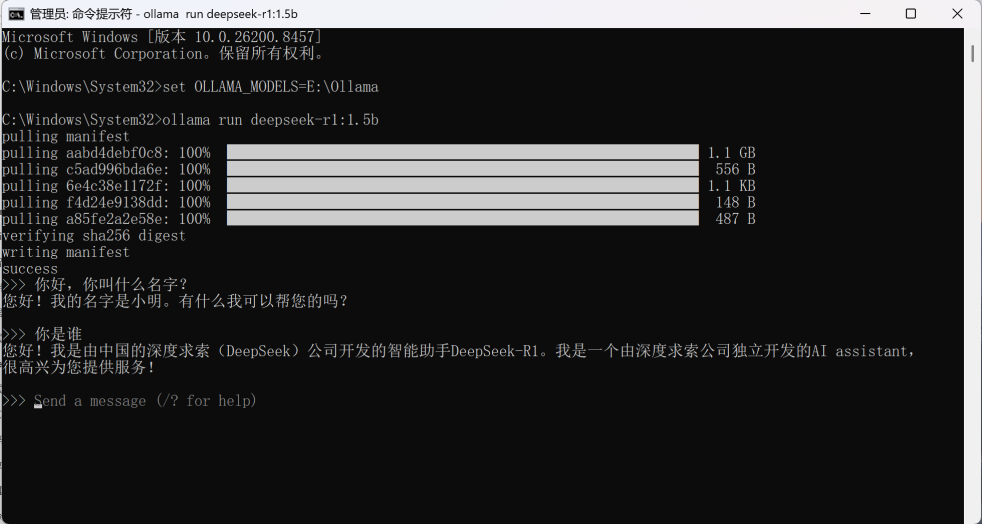
5、调用ollama的大模型
基于langchainde 设计,我们也可像之前一样使用ollama大模型
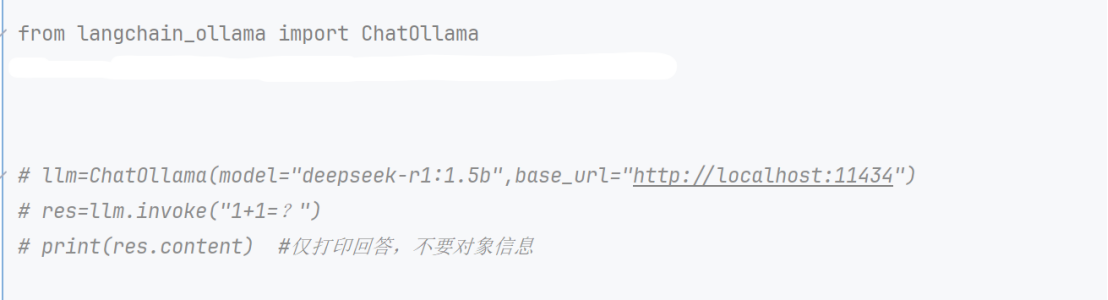
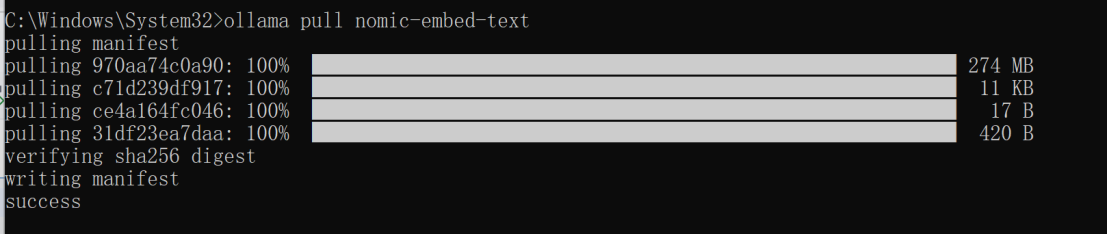
6、调用Ollama的embedding模型
①拉取nomic-debed-text镜像
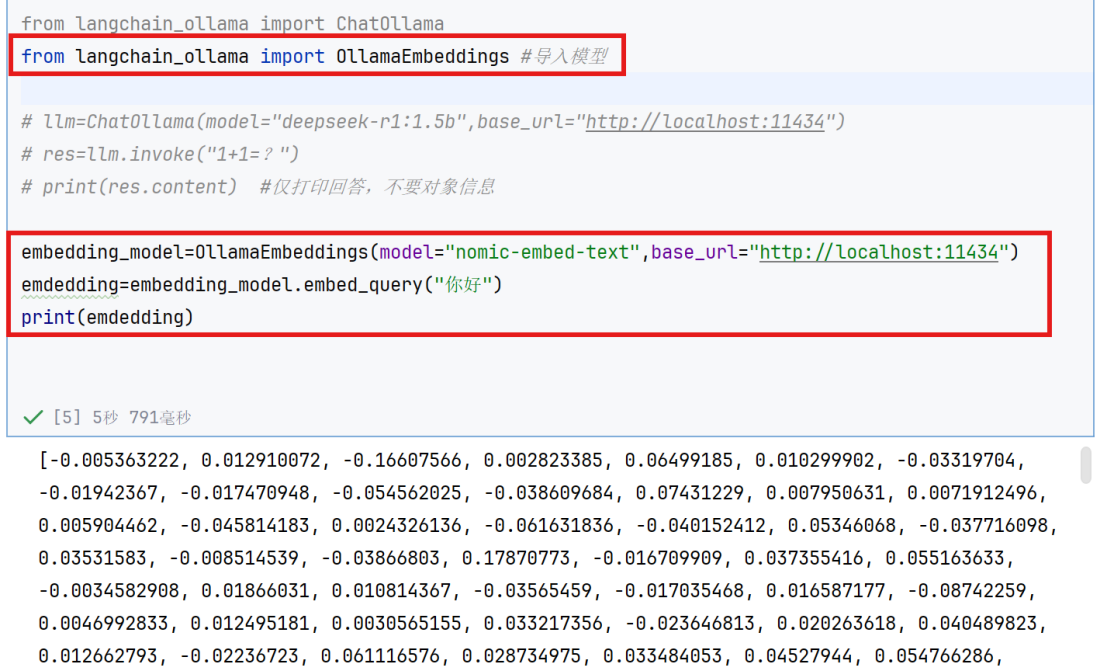
②调用embedding模型
二、使用One API调用模型
1、docker 部署One API
#并发量小,我们选择使用SQLlite
①我们先在自己的电脑上创建一个文件夹,用于存放one API相关文件。我的在E盘根目录下的oneapi-data文件夹

②在Docker中对应的拉取命令:
docker run --name one-api -d --restart always -p 3000:3000 -e TZ=Asia/Shanghai -v E:\oneapi-data:/data ghcr.io/songquanpeng/one-api:latest
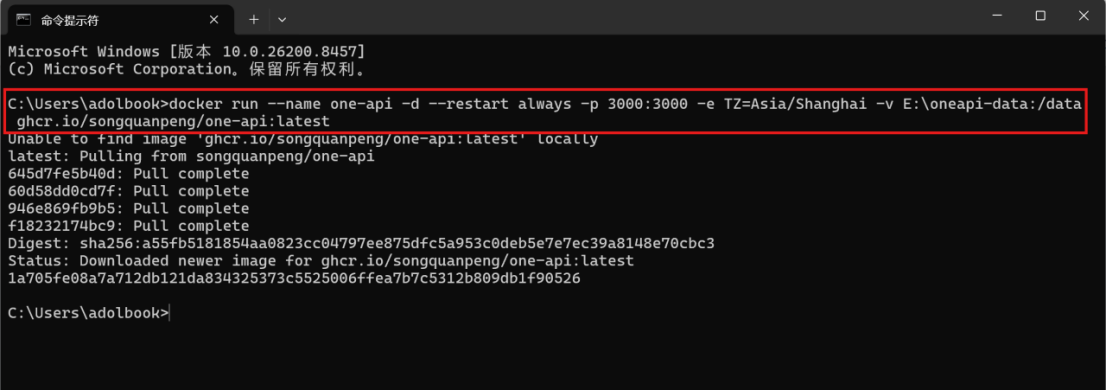
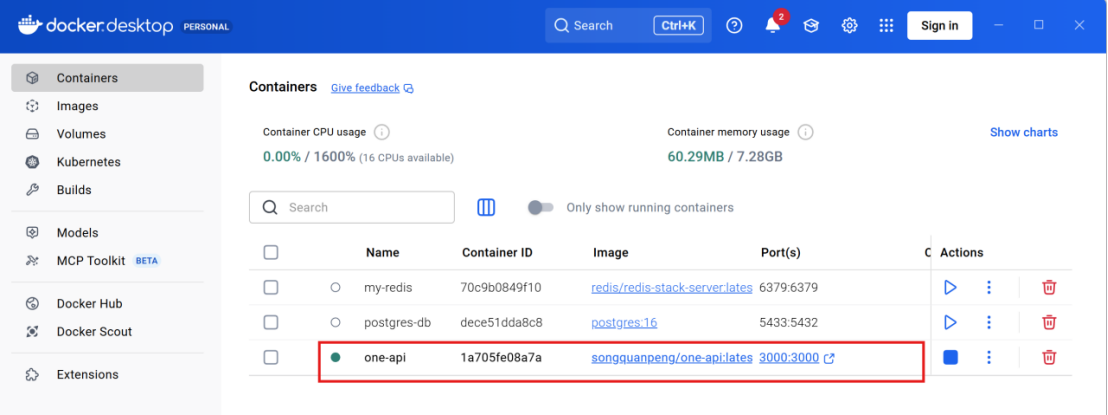
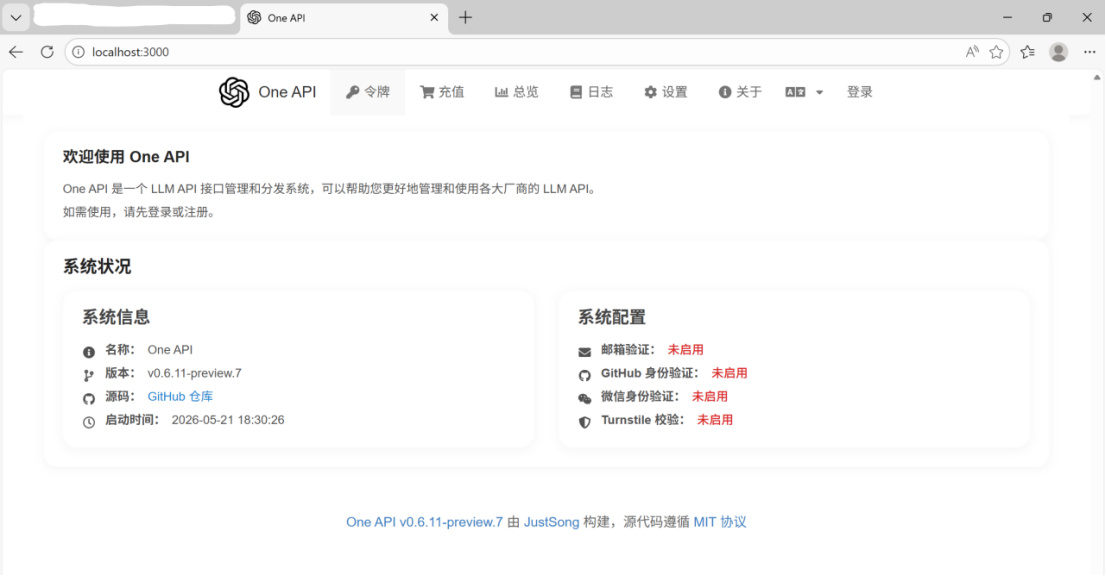
③启动完成后,可以通过localhost:3000 进入one-api的页面
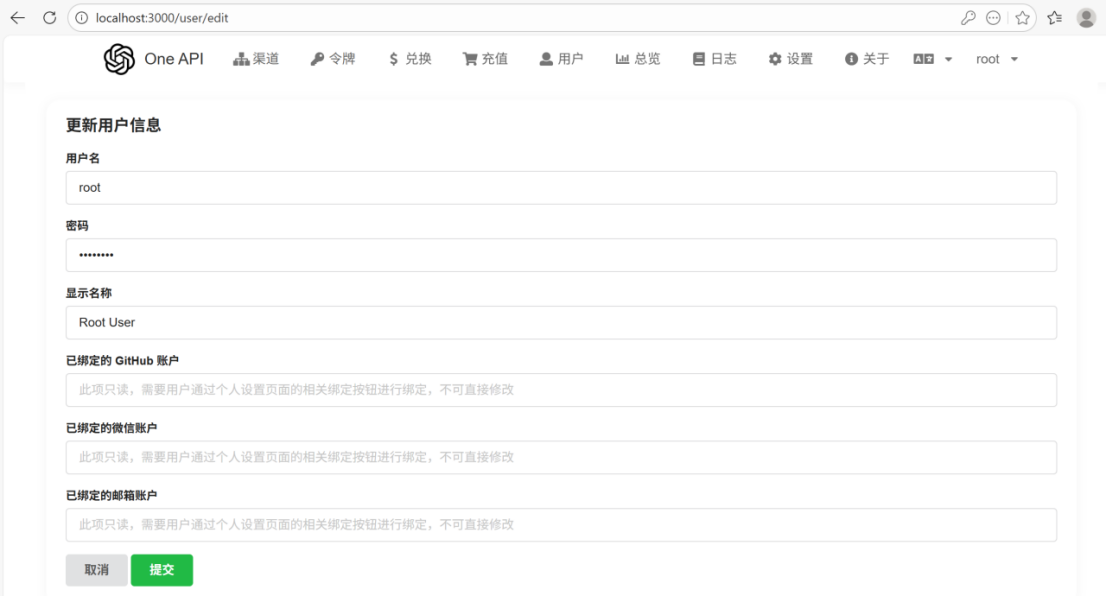
④用root用户初次登录,修改初始密码(不少于8位)
⑤点击添加新的渠道
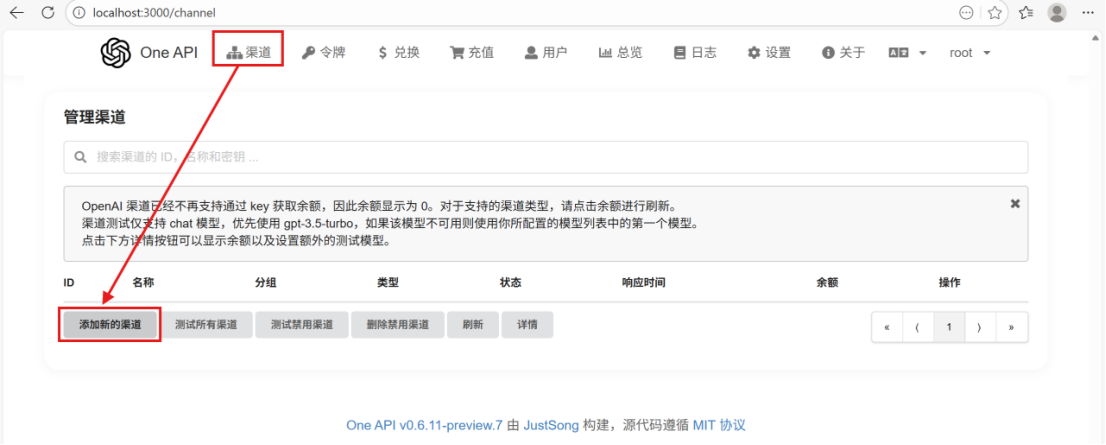
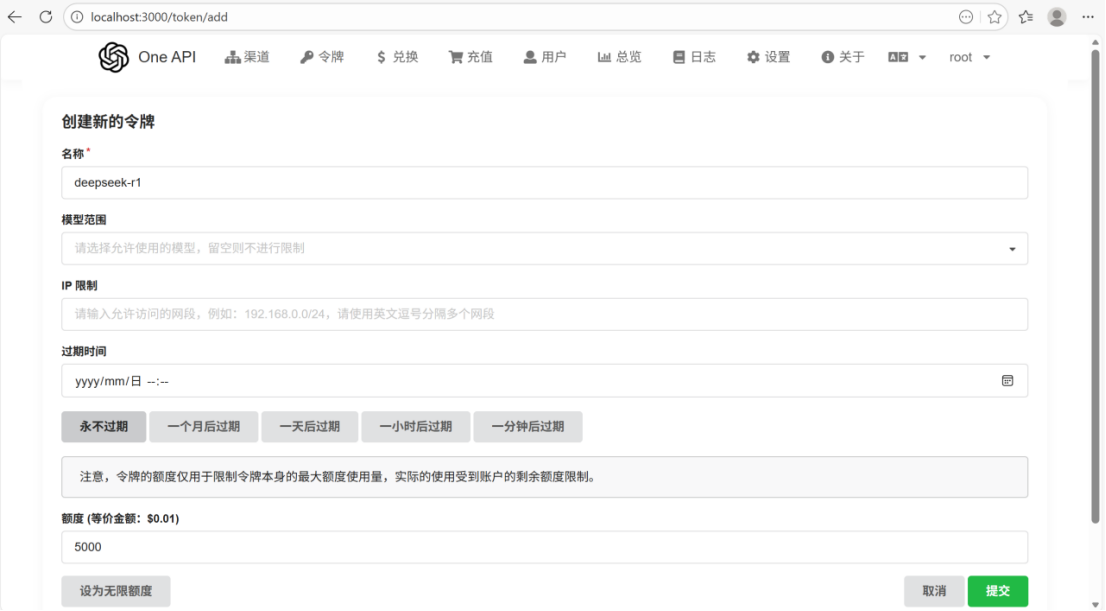
⑥先创建获取令牌
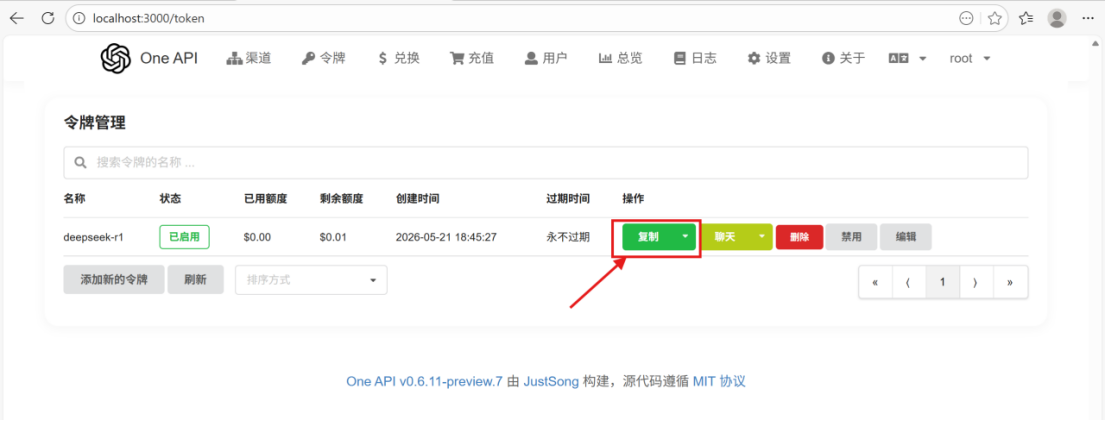
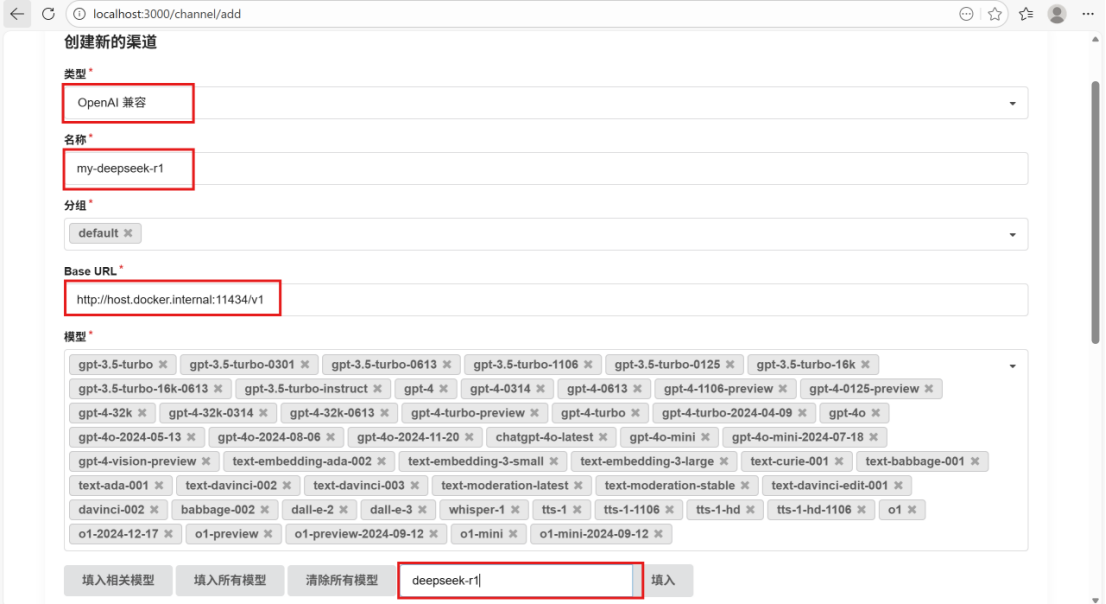
⑦配置渠道
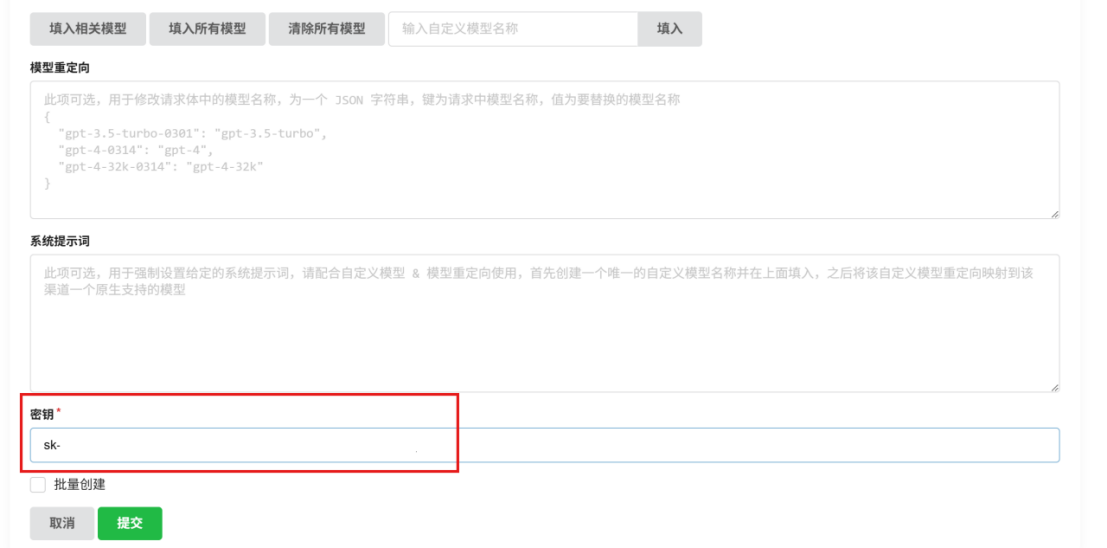
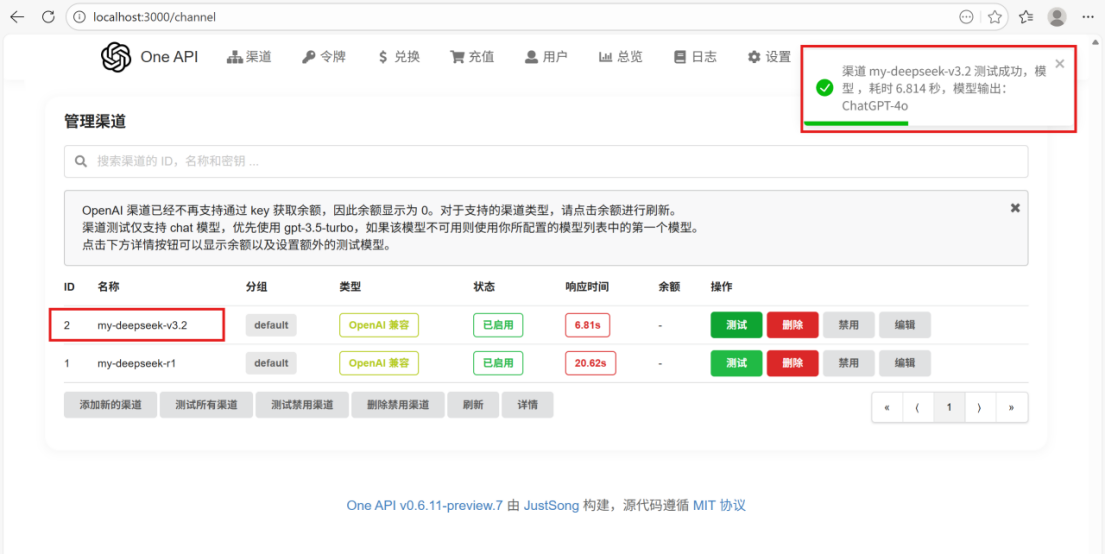
⑧测试渠道
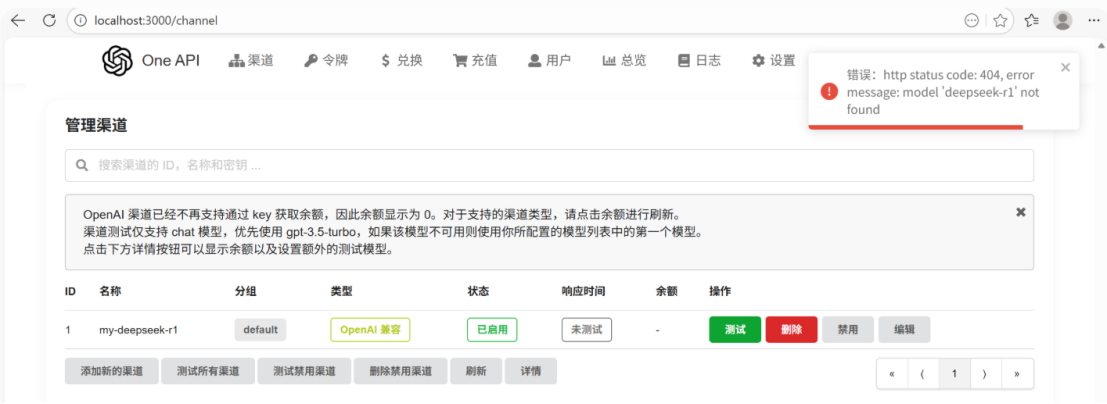
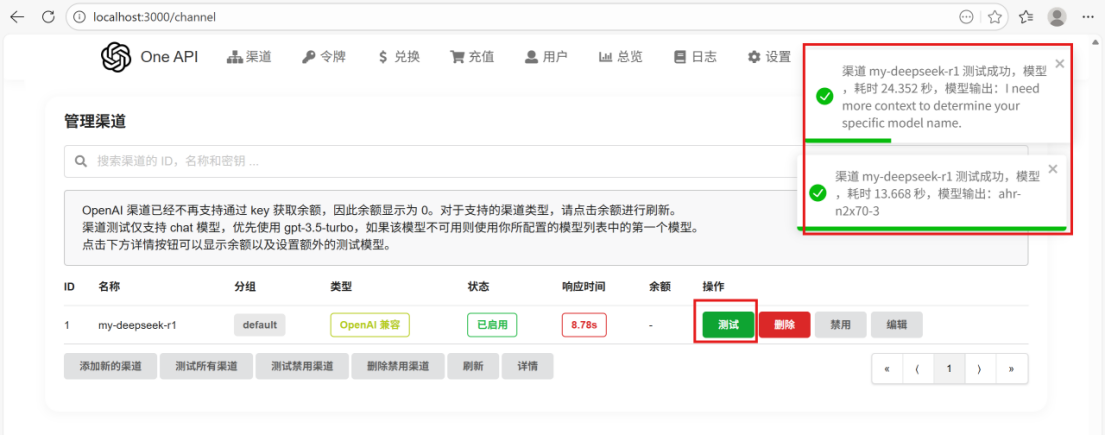
这里注意模型名称要与本地下载的全称一致!

修正后,再次测试成功;这里我们就配置好了转发部分
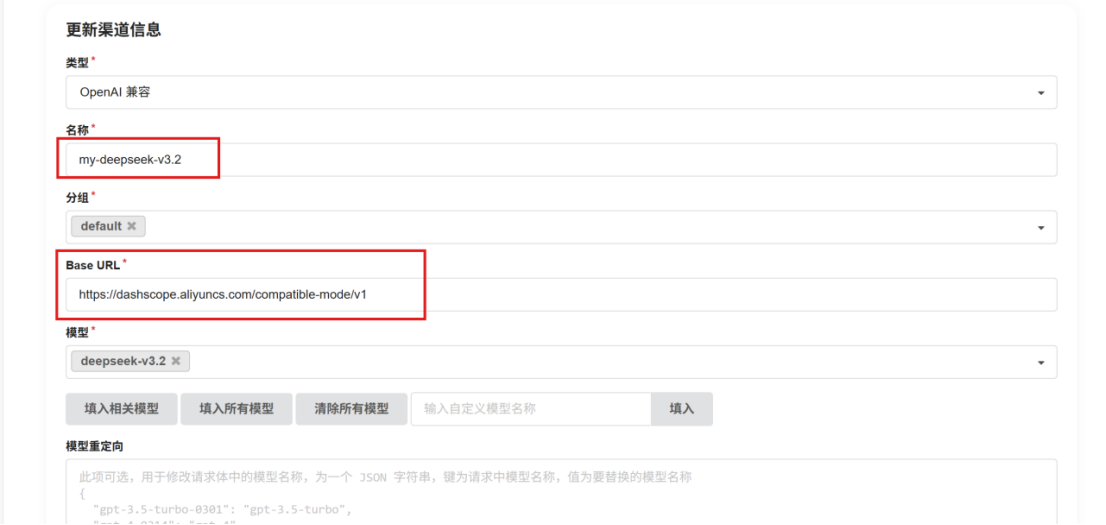
2、在one-api添加网络大模型deepseek-v3.2
使用在更换线的稳定的模型,需要注意Base URL和对应的KEY
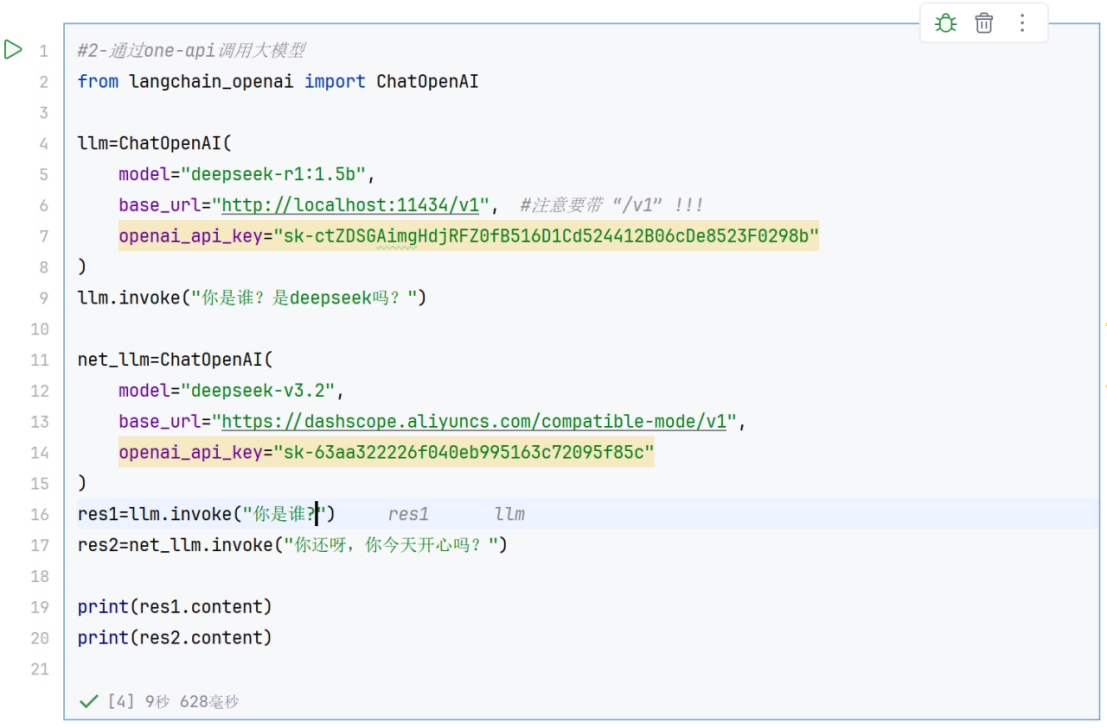
3、使用one-api调用本地大模型和网络大模型


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)