
刚刚!Cursor 发布最强自研模型 Composer 2.5,性能追平 Opus 4.7,马斯克亲自下场试用

刚刚!Cursor 在官博上放出了 Composer 2.5,自研 Composer 系列里它自己口径"迄今最强"的一版。
新模型出来不到几小时,Elon Musk 直接转发了 Cursor 的官推,配文很短:"试用一下!(部分训练于 Colossus 2)"。一条转推把这次发布顶到了 X 平台首页热门,原推阅读量当天就冲过了 1000 万。
Cursor 给 Composer 2.5 的官方定调是一句话:比同级模型聪明,效率最高 10 倍。这话听起来像营销文案,但把它放进基准测试和价格表对比 Claude Opus 4.7、GPT-5.5,差不多能看出含义:性能挤进了第一梯队,成本压到了完全不同的量级。
先看数据:Composer 2.5 到底有多强
Cursor 这次给出了三个基准上的横向对比,对手全部是当下最热的几款。
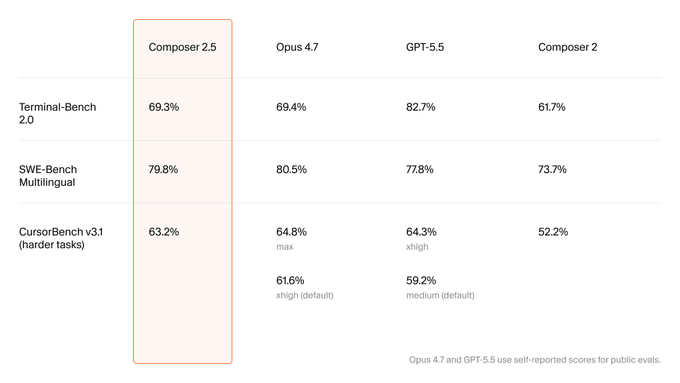
几个关键读数:
-
Terminal-Bench 2.0:Composer 2.5 拿到 69.3%,几乎和 Opus 4.7 打平(69.4%),但落后 GPT-5.5(82.7%)一截。终端任务这块,GPT-5.5 暂时还是最强。
-
SWE-Bench Multilingual:Composer 2.5 拿到 79.8%,和 Opus 4.7(80.5%)只差不到 1 个百分点,比 GPT-5.5 还高 2 个百分点。多语言代码任务上,它基本可以和 Opus 4.7 同台。
-
CursorBench v3.1:Cursor 自己的硬核任务集。Composer 2.5 拿到 63.2%,比 Opus 4.7 默认档(61.6%)高,和 GPT-5.5 默认档(59.2%)拉开 4 个百分点。
对比上一代 Composer 2,三个基准全部大幅前进,CursorBench 上从 52.2% 直接拉到 63.2%,提了 11 个百分点。这是 Cursor 自研路线一个比较像样的迭代。
但更值得说的不是这几个数字本身,而是数字背后的"性价比曲线"。
10 倍效率从哪来:同级表现,价格砍到七分之一
Cursor 这次专门画了一张 CursorBench 3.1 的得分和成本对比图,横轴是单任务平均成本,纵轴是得分。
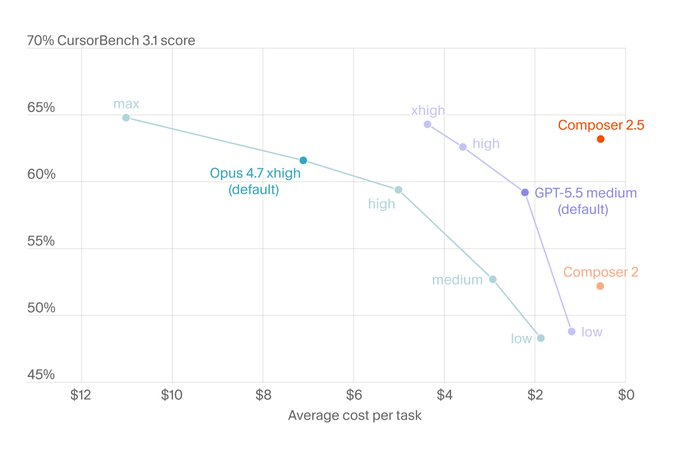
这张图传递的信息很直接:
-
Opus 4.7 默认档(xhigh):约 7 美元/任务,得 61% 左右;想再提分到 64%,需要切到 max 档,成本飙到 11 美元/任务。
-
GPT-5.5 默认档(medium):约 2 美元/任务,得 59% 左右。
-
Composer 2.5:约 1 美元/任务,得 63% 左右。
Composer 2.5 落在图右上角孤独的位置,得分接近 Opus 4.7 默认档,但单任务成本只有它的七分之一。和 GPT-5.5 默认档比,得分高一档,成本还便宜一半。Cursor 那句"最高 10 倍效率"的口径,大致就是从这张图来的。
这事对开发者意味着什么?很现实:
-
如果你在 Cursor 里写代码,一天跑十几次长链路的 Agent 任务,过去用 Opus 默认档可能账单要几十美元,换成 Composer 2.5 可以把成本压到几美元。
-
如果你团队在做 AI 自动化重构、批量代码迁移这类高频任务,便宜七倍意味着你能并行跑更多任务,或者用更长的上下文。
-
Cursor 还宣布 未来一周内 Composer 2.5 的免费额度翻倍,相当于直接发了一波抢用户的活动。
具体 API 定价上,Composer 2.5 标准版输入 0.5 美元 / 百万 token,输出 2.5 美元 / 百万 token;快速版输入 3 美元,输出 15 美元。
技术底子:Kimi K2.5 开源底座 + 85% 自研训练
3 月份 Composer 2 上线的时候,Cursor 没有主动承认底座来自 Kimi K2,引发过一场不大不小的争论。这次 Composer 2.5,Cursor 选择直接把这层关系摆到台面上。
官博和 X 推文都明说了:Composer 2.5 基于和 Composer 2 相同的开源基础,即 Moonshot 的 Kimi K2.5。
但同时给出了一张算力分布图:
-
Kimi K2 原始训练:7.5%
-
Kimi K2.5 原始训练:7.5%
-
Cursor 在 K2.5 之上的额外训练和 RL:85%
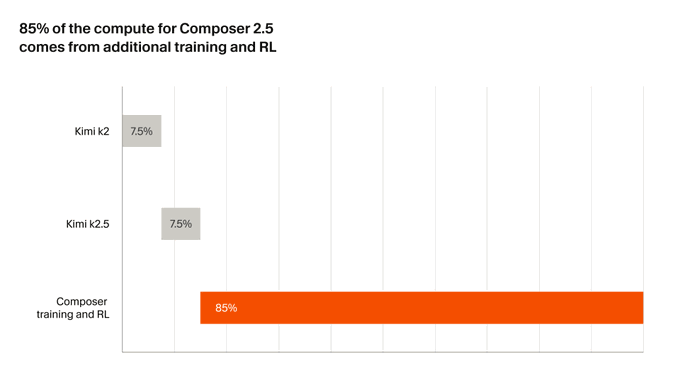
换句话说,开源底座只贡献了一小段路,剩下八成五的训练算力是 Cursor 自己投进去的。这个比例的真实性外人没法核验,但摆出来本身就是一个表态:**这次别再说我"只是套壳了"**。
Cursor 这次披露的几个技术细节也算干货:
-
基于文本反馈的定向强化学习:在 Agent 轨迹里识别出"模型本可以做得更好"的位置,直接插入文本反馈来改写教师模型的概率分布,再用 on-policy 蒸馏把这部分知识灌给学生模型。简单理解就是不再一刀切地给整段轨迹打分,而是定位到具体哪一步出错、为什么出错。
-
合成任务规模提升 25 倍:Composer 2.5 使用的合成训练任务数量是 Composer 2 的 25 倍,并且用"功能删除"这类方法基于真实代码库自动生成。
-
分片 Muon 优化器 + 双网格 HSDP:在万亿参数规模上,优化器每一步只要 0.2 秒。这对训练吞吐影响非常直接。
对一个还在做产品的公司来说,这种披露密度算比较真诚。同期的几家头部模型厂商,已经很少再披露这一层的训练工程细节了。
与 xAI 合作:下一代模型即将登场,10 倍算力起步
如果 Composer 2.5 只是这次发布的开胃菜,主菜其实在另一条推文里。
Cursor 官推同步公布了一条更重磅的消息:正在和 SpaceXAI 一起从零训练一个显著更大的新模型,总算力是 Composer 2.5 的 10 倍,使用 Colossus 2 的百万 H100 等效算力。
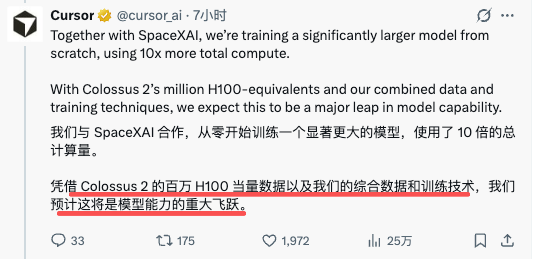
这条消息得放到 4 月份的背景里看。4 月 22 日,SpaceX 官方账号发推宣布和 Cursor 深度合作,并且给出了一个选项:今年晚些时候 SpaceX 可以选择以 600 亿美元收购 Cursor,或者支付 100 亿美元作为合作对价。当时这条推文炸了一整天,Cursor 创始人 Michael Truell 也明确转发表态。
过去这一个多月,外界一直不清楚这笔合作的实际进展。Composer 2.5 这次的公告,相当于第一次给出了具体节点:
-
Composer 2.5 本身 已经有"部分训练于 Colossus 2"(这点 Musk 自己在转推里点明了)。
-
下一代更大模型 正在用 10 倍算力从零训练,按 Cursor 的说法这是"模型能力上的重大跃升"。
Colossus 2 是 xAI 在田纳西州孟菲斯部署的超级计算集群,按公开口径百万 H100 等效。把这个量级的算力对接到一家 AI 编程公司,过去一年里几乎没有先例。换个角度看,Cursor 等于在算力侧拿到了一张和 Anthropic、OpenAI 一个量级的入场券。
回头看 Cursor 从 2 月到现在的节奏:Composer 2 用 Kimi 底座被质疑,Composer 2.5 直接把这层公开摆上台面,并且在三个基准上拿出了能打的成绩。中间还嵌套着和 xAI 的 600 亿美元收购选项、Colossus 2 算力对接。
这是一家在"应用公司"和"模型公司"两条路上同时押注的 Cursor。前者,它已经是 AI 编程赛道当下最赚钱的产品。后者,它今天刚刚把自己摆上了模型基准表的横轴。
下一步要看的是两件事:一是 Composer 2.5 在真实开发者手里跑一周后口碑会不会反转,二是和 xAI 合训的下一代模型什么时候露面。后者按 Cursor 给出的措辞,可能比这次的 Composer 2.5 还要重磅。
值得期待。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 13
13 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)