
三强争霸:Claude Sonnet4.6、Gemini 3.1 Pro、GLM-5深度解析与全面对比
人工智能领域迎来密集爆发期。Anthropic、谷歌、智谱 AI 三大巨头相继推出重磅模型 —— Claude Sonnet4.6、Gemini 3.1 Pro 与 GLM-5,分别从综合能力升级、核心推理突破与开源性价比三个维度重塑行业格局。这三款模型不仅代表了当前 AI 技术的顶尖水平,更折射出全球大模型竞争从参数规模比拼转向实际任务价值兑现的关键趋势。本文将从核心特性、性能表现、定价策略、应
人工智能领域迎来密集爆发期。Anthropic、谷歌、智谱 AI 三大巨头相继推出重磅模型 —— Claude Sonnet4.6、Gemini 3.1 Pro 与 GLM-5,分别从综合能力升级、核心推理突破与开源性价比三个维度重塑行业格局。这三款模型不仅代表了当前 AI 技术的顶尖水平,更折射出全球大模型竞争从参数规模比拼转向实际任务价值兑现的关键趋势。本文将从核心特性、性能表现、定价策略、应用场景等维度进行深度解析与横向对比,为开发者与企业用户提供决策参考。
一、三款模型核心特性与技术突破
(一)Claude Sonnet4.6:均衡全能的 “效率王者”
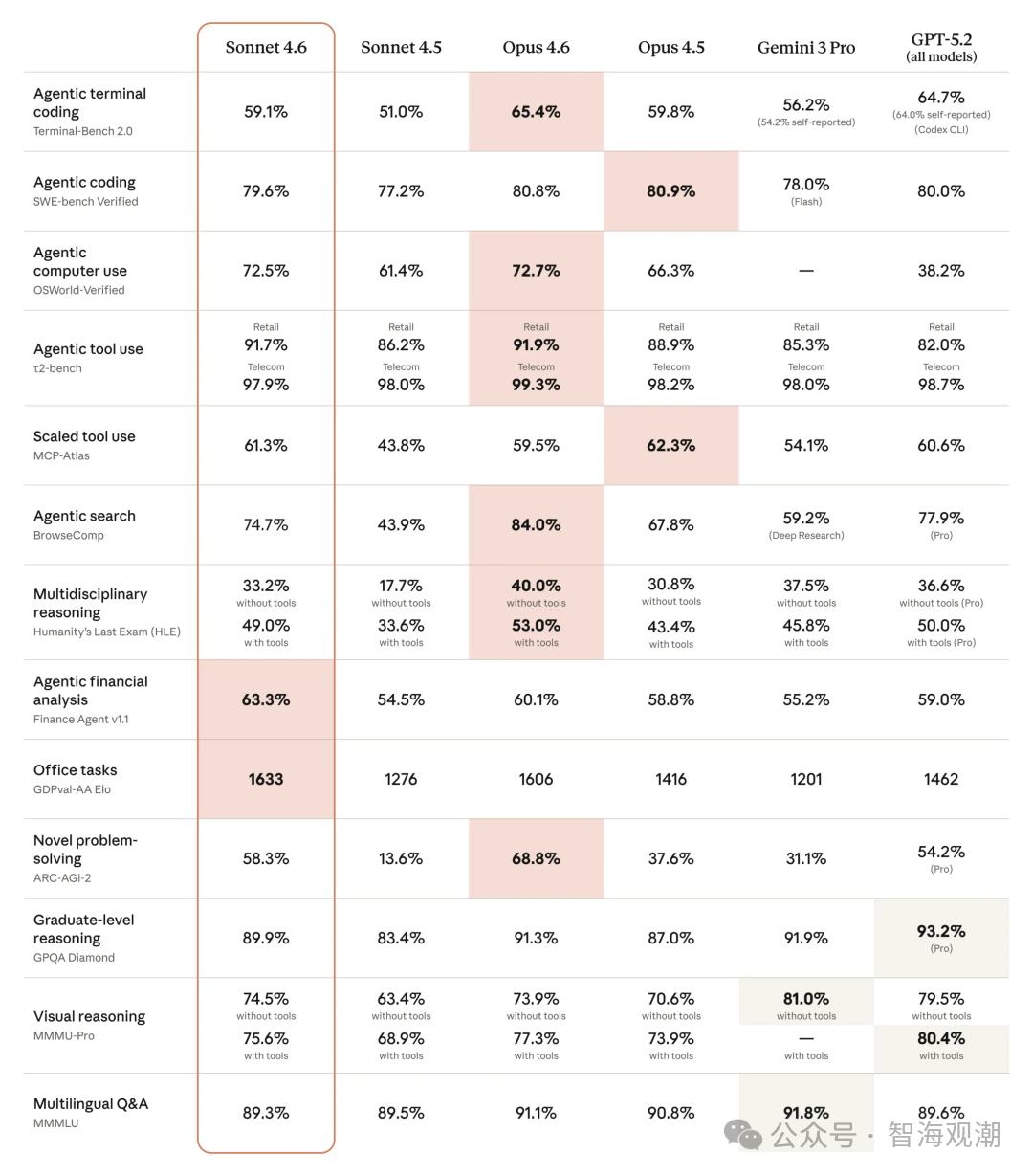
2026 年 2 月 18 日,Anthropic 在大年初二率先发布 Claude Sonnet4.6,定位为 “当前能力最强的 Sonnet 模型”。该模型延续了 Anthropic 一贯的稳健风格,实现了编码、计算机使用、长上下文推理等六大核心能力的全面升级,尤其在实用性与稳定性上表现突出。
其最引人注目的突破是 Beta 版支持 100 万 token 上下文窗口,足以容纳完整代码库、长篇合同或数十篇研究论文,且能在全上下文范围内进行高效推理。在计算机使用场景中,Sonnet4.6 在 OSWorld-Verified 基准测试中取得 72.5% 的高分,较前代提升显著,能够完成浏览复杂电子表格、多步骤网页表单填写等人类级任务,在多浏览器标签页信息整合方面表现亮眼。
安全性方面,该模型大幅提升了对提示注入攻击的抵抗能力,表现与更高端的 Opus 4.6 相近,为企业级应用提供了更可靠的安全保障。用户反馈显示,Sonnet4.6 在指令遵循、减少幻觉、多步骤任务执行一致性等方面均有明显改进,70% 的用户更倾向于选择该模型而非前代 Sonnet4.5,甚至 59% 的用户在部分场景中认为其表现优于 Opus 4.5。
(二)Gemini 3.1 Pro:推理跃升的 “全能冠军”
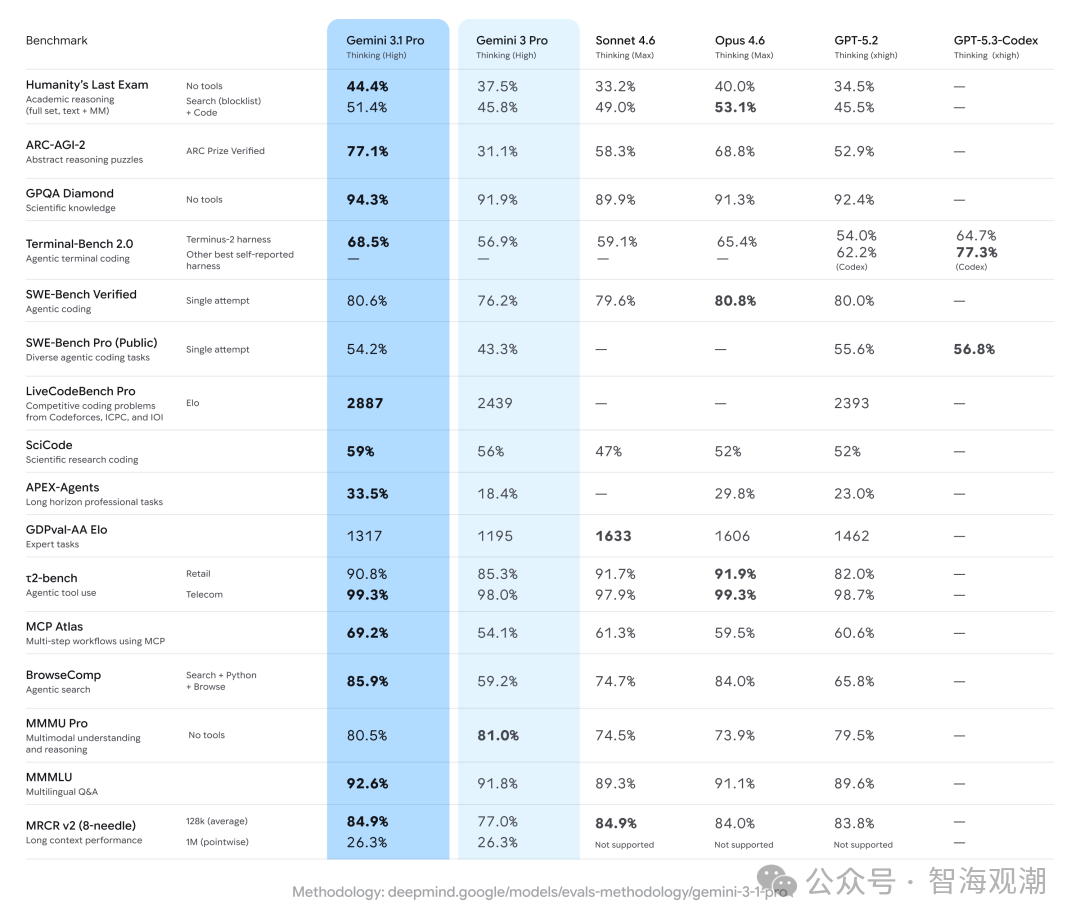
紧随 Anthropic 之后,谷歌于 2026 年 2 月 20 日推出 Gemini 3.1 Pro,作为 Gemini 3 系列的核心升级版本,该模型以 “解决更棘手问题” 为目标,实现了核心推理能力的跨越式提升。采用混合专家架构的 Transformer 模型,支持最高 100 万 token 输入和 6.4 万 token 输出,可处理文本、视频等多模态文件。
其最震撼的突破体现在抽象推理领域:在评估全新逻辑模式求解能力的 ARC-AGI-2 基准测试中,Gemini 3.1 Pro 取得 77.1% 的验证成绩,不仅是前代 Gemini 3 Pro 的两倍以上,更超越了 Claude Sonnet4.6(58.3%)和 Opus 4.6(68.8%),甚至超过人类平均正确率(约 60%)。在科学知识测试 GPQA Diamond 中,其 94.3% 的得分位居三款模型之首,展现出强大的专业知识储备。
编码能力方面,Gemini 3.1 Pro 在 LiveCodeBench Pro 上的 Elo 得分达到 2887,SWE-Bench Verified 测试中取得 80.6% 的成绩,尤其在科学编程任务 SciCode 上以 59% 的得分领先于 Claude 系列。此外,该模型在多模态应用中表现突出,能够生成高清 SVG 动画、构建实时航空仪表盘、开发 3D 交互式模拟等,将复杂推理能力转化为实用工具。
(三)GLM-5:开源普惠的 “性价比黑马”
GitHub:https://github.com/zai-org/GLM-5
Hugging Face:https://huggingface.co/zai-org/GLM-5
OpenRouter:http://openrouter.ai/z-ai/glm-5
2026 年 2 月 12 日,智谱 AI 发布首款 IPO 后重磅模型 GLM-5,以 “Agentic Engineering” 为核心理念,标志着 AI 自动化编程进入规模化应用阶段。作为开源模型中的佼佼者,GLM-5 在参数规模(7440 亿)、训练数据量(28.5 万亿 tokens)上实现翻倍增长,同时采用 DeepSeek 稀疏注意力机制,在保证性能的前提下降低部署成本。
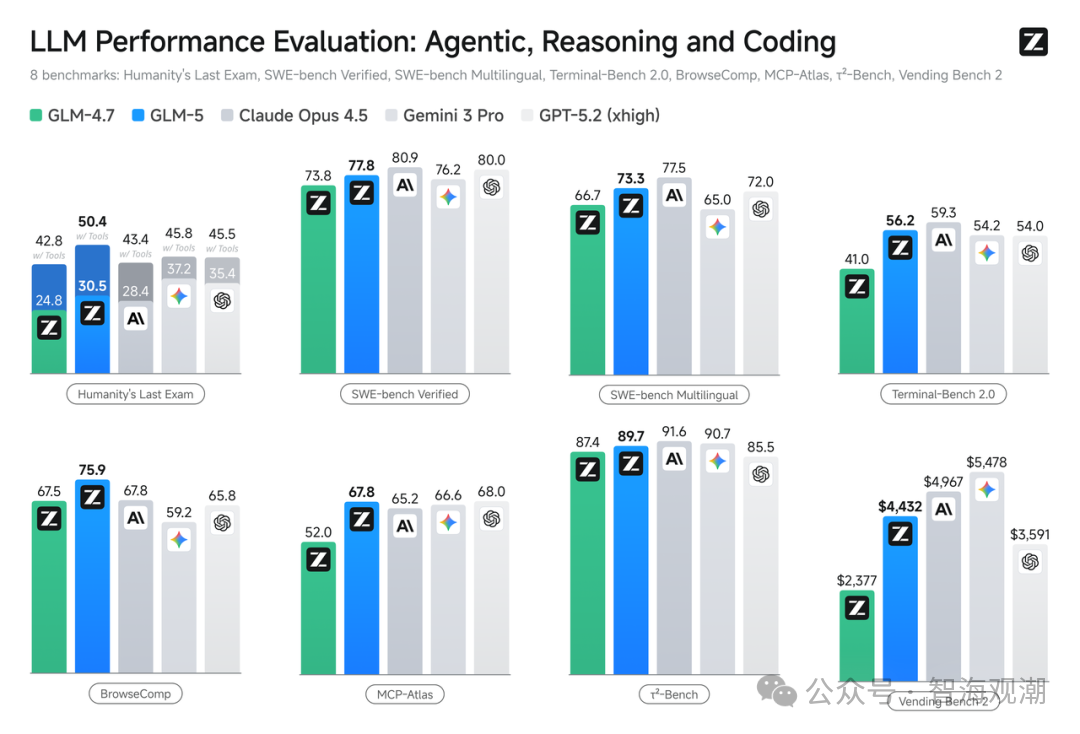
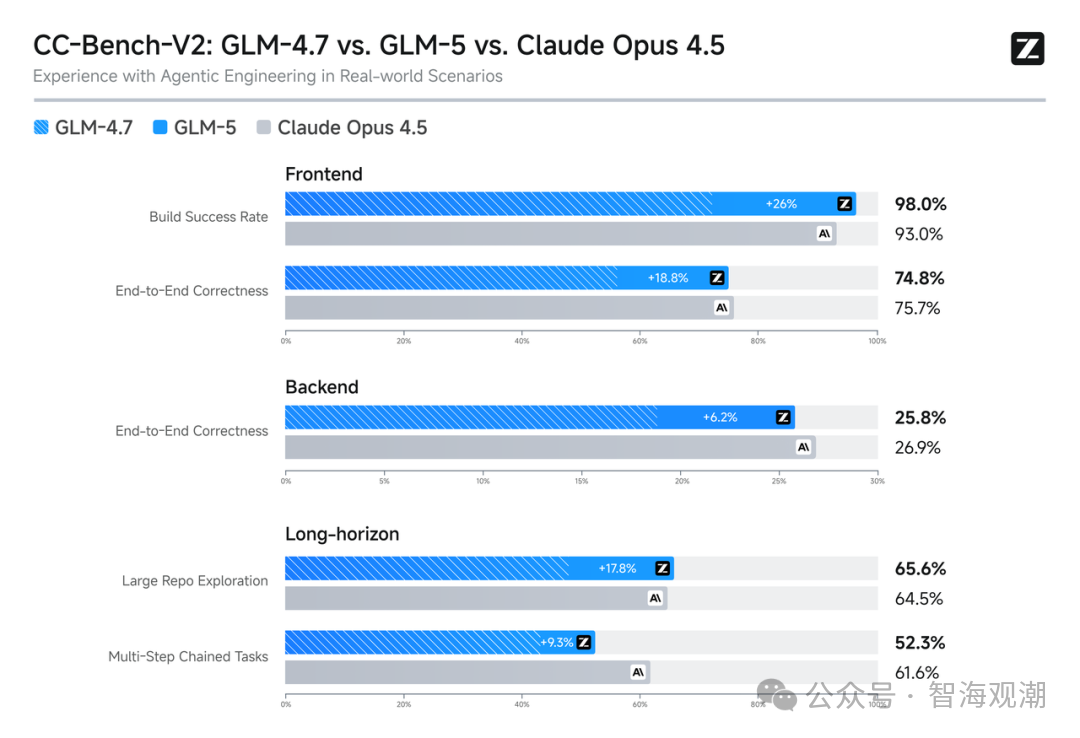
其核心优势集中在编码与智能体能力上:在 SWE-bench-Verified(77.8%)和 Terminal Bench 2.0(56.2%)测试中取得开源模型最高分数,性能超越 Gemini 3 Pro。在前端开发中,GLM-5 的构建成功率达到 98.0%,端到端正确性接近 Claude Opus 4.5;后端开发与长程任务处理中,较前代 GLM-4.7 提升超过 20%,能够自主完成系统重构、深度调试等复杂工程任务。
作为开源模型,GLM-5 已在 GitHub、Hugging Face 等平台开放,遵循 MIT License,支持基于华为、寒武纪等国产芯片部署,为国内开发者提供了无壁垒的技术接入路径。其定价策略极具颠覆性,成为开源领域性价比的代名词。
二、核心性能横向对比
(一)基准测试成绩综合排名
测试项目
Claude Sonnet4.6
Gemini 3.1 Pro
GLM-5
领先模型
ARC-AGI-2(抽象推理)
58.3%
77.1%
Gemini 3.1 Pro
GPQA Diamond(科学知识)
89.9%
94.3%
Gemini 3.1 Pro
SWE-Bench Verified(编码)
79.6%
80.6%
77.8%
Gemini 3.1 Pro
Terminal-Bench 2.0(终端编码)
59.1%
68.5%
56.2%
Gemini 3.1 Pro
OSWorld-Verified(计算机使用)
72.5%
Claude Sonnet4.6
GDPval-AA Elo(办公任务)
1633
1317
Claude Sonnet4.6
BrowseComp(智能搜索)
74.7%
85.9%
87.4%
GLM-5
τ²-Bench(工具使用)
97.9%(电信)
99.3%(电信)
89.7%
Gemini 3.1 Pro
从基准测试结果可见,Gemini 3.1 Pro 呈现 “碾压式” 优势,在抽象推理、科学知识、编码等核心维度均位列第一,尤其在高难度逻辑推理任务中与其他模型拉开明显差距;Claude Sonnet4.6 则在办公任务、计算机使用场景中保持领先,展现出更强的场景适配性;GLM-5 作为开源模型,在智能搜索、工具调用等领域表现亮眼,核心性能逼近闭源模型水平。
(二)关键能力细分对比
长上下文处理:Claude Sonnet4.6 以 100 万 token 上下文窗口领先,且能有效进行全上下文推理,在 Vending-Bench Arena 模拟业务运营测试中,通过 “早期产能投资 + 后期盈利聚焦” 的策略实现收益碾压;Gemini 3.1 Pro 支持 100 万 token 输入,但 1M 规模下的逐点性能仅 26.3%;GLM-5 上下文窗口为 200K,虽规模较小,但在长文本处理效率上表现突出。
编码能力:Gemini 3.1 Pro 在竞争性编程、科学编程中优势明显,LiveCodeBench Pro 的 Elo 得分远超同类模型;Claude Sonnet4.6 在代码理解与逻辑整合上表现出色,用户反馈其修改代码前能更精准把握上下文;GLM-5 则在开源场景中性价比突出,前端开发成功率接近 Claude Opus 4.5,适合中小型团队技术落地。
多模态能力:Gemini 3.1 Pro 全面领先,支持文本、视频等多模态输入,能生成高质量 SVG 动画、3D 交互场景;Claude Sonnet4.6 在视觉推理 MMMU-Pro 测试中,工具辅助下得分 75.6%,表现稳健;GLM-5 目前侧重文本与编码任务,多模态能力相对薄弱。
安全性与可靠性:Claude Sonnet4.6 在抵抗提示注入攻击方面表现最优,与 Opus 4.6 处于同一水平;Gemini 3.1 Pro 通过降低幻觉率提升可靠性,企业用户反馈其数据推理准确性显著提升;GLM-5 作为开源模型,安全性需用户自行配置,但智谱 AI 提供了基础的安全防护框架。
三、定价策略与开放权限对比
(一)定价结构差异
Claude Sonnet4.6:定价策略简洁透明,与前代保持一致,每百万输入 token 3 美元,每百万输出 token 15 美元。免费用户与专业版用户均可默认使用,无需额外付费升级,API 调用与云平台部署价格统一,适合个人开发者与中小企业长期使用。
Gemini 3.1 Pro:定价较为复杂,采用阶梯式收费:输入 token 不超过 20 万时,每百万收费 2 美元,超过则为 4 美元;输出 token 不超过 20 万时,每百万收费 12 美元,超过则为 18 美元。额外收取上下文缓存费(0.2-0.4 美元 / 百万 token)与存储费(4.5 美元 / 百万 token / 小时),联网搜索前 5000 次免费,后续每 1000 次收费 14 美元。整体成本低于 Claude Opus 4.6,但高于 Sonnet4.6 与 GLM-5。
GLM-5:定价极具颠覆性,每百万输入 token 仅 0.8 美元,每百万输出 token 2.56 美元,分别为 Claude Opus 4.6 的 1/6 和 1/10,GPT 5.3 Codex 的 46% 和 18%。开源版本可免费部署,但智谱 AI 调整了套餐策略,取消首购优惠,套餐价格整体涨幅 30%,已订阅用户保持原价。
(二)开放权限与部署方式
模型
开放对象
部署方式
特殊限制
Claude Sonnet4.6
所有 Claude 套餐用户、API 用户
Claude 官网、Cowork、API、主流云平台
无明显限制,免费套餐默认升级
Gemini 3.1 Pro
开发者、企业用户、消费者
Google AI Studio、Vertex AI、Gemini App、NotebookLM
预览版阶段,Pro/Ultra 套餐用户额度更高
GLM-5
代码订阅用户、开源社区
智谱官网、GitHub、Hugging Face、OpenRouter
算力有限,逐步开放;国际市场应用受限
从开放程度来看,Claude Sonnet4.6 最为便捷,用户无需额外操作即可使用升级版模型;Gemini 3.1 Pro 覆盖全场景用户,但预览版存在额度限制;GLM-5 适合有技术部署能力的团队,开源特性使其可定制化程度最高,但受算力限制,开放节奏较慢。

四、应用场景适配建议
(一)Claude Sonnet4.6:适合注重稳定性与场景适配的用户
核心适配场景
企业办公自动化(复杂表格处理、多步骤表单填写)、法律合同分析、长篇文档摘要、代码审计与优化。
目标用户
中小企业、法律从业者、内容创作者、个人开发者。
优势体现
100 万 token 长上下文适合处理长篇文档,稳定的性能表现与简洁定价降低使用门槛,强大的安全防护适合处理敏感信息。
(二)Gemini 3.1 Pro:适合追求极致推理与多模态应用的用户
核心适配场景
科学研究与工程计算、复杂系统开发、多模态内容创作(SVG 动画、3D 交互设计)、智能体开发、创意编程。
目标用户
科技企业、科研机构、专业开发者、设计师。
优势体现
顶尖的抽象推理能力适合解决未知逻辑问题,多模态支持拓展应用边界,高效的 token 利用率降低大规模任务成本。
(三)GLM-5:适合预算有限与需要定制化部署的用户
核心适配场景
开源项目开发、中小企业技术落地、前端 / 后端开发、内部工具构建、国产芯片部署场景。
目标用户
初创公司、开发团队、国产化需求企业、学生开发者。
优势体现
极低的使用成本与开源特性适合二次开发,支持华为等国产芯片部署,满足国产化合规要求,编码能力接近闭源旗舰模型。
五、行业影响与未来趋势展望
三款模型的密集发布,标志着 AI 行业进入 “能力深耕” 的新阶段。Gemini 3.1 Pro 的推理突破证明,核心能力升级比参数规模扩张更能创造价值;Claude Sonnet4.6 的均衡表现则体现了用户对 “稳定实用” 的核心需求;GLM-5 的开源普惠策略,进一步降低了前沿技术的应用门槛,推动 AI 民主化进程。
从竞争格局来看,谷歌凭借 Gemini 3.1 Pro 重新夺回性能榜首,Anthropic 则以 Sonnet4.6 巩固中端市场优势,智谱 AI 通过 GLM-5 在开源领域实现弯道超车,形成 “闭源双雄 + 开源黑马” 的三足鼎立格局。未来,大模型竞争将聚焦三个方向:一是核心推理能力的持续突破,尤其是抽象逻辑与复杂问题求解;二是行业场景的深度适配,从通用能力转向垂直领域解决方案;三是成本与效率的平衡,在保证性能的同时降低部署与使用成本。
对于用户而言,选择模型需摒弃 “唯性能论”,结合实际需求综合判断:追求极致体验与多模态应用,优先选择 Gemini 3.1 Pro;注重稳定性与长文本处理,Claude Sonnet4.6 是性价比之选;预算有限或需要定制化部署,GLM-5 则是开源领域的最优解。随着技术的快速迭代,三款模型均会持续升级,用户可根据自身业务发展动态调整选择。
总体而言,2026 年初的这场 “三强争霸”,不仅为用户提供了更多优质选择,更推动了 AI 技术从实验室走向实际生产场景,加速了智能化转型的全面落地。未来,随着更多创新模型的涌现,人工智能行业将迎来更激烈的竞争与更广阔的发展空间。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)