
叫板 Claude Code,DeepSeek TUI 确实能打
写在前面:这篇不是广告,也不是简单的"安装+跑一跑"水文。我会把架构原理、成本模型、踩坑细节全部摊开来讲。如果你只是想知道"好不好用"——结论在最后。
起点:一句蹩脚的中文
2026 年 5 月 1 日,美国独立开发者 Hunter Bown 在 GitHub 发了一张图,配了一行字:
"鲸鱼兄弟们,谢谢你们。"
没有团队,没有融资,没有大厂背书。
到 5 月 7 日,Star 数突破 22,000,冲上 GitHub 全球趋势榜第一。
它是什么?一句话和一张图
DeepSeek-TUI = 专门为 DeepSeek V4 定制的终端 Coding Agent。
类比最近你最熟悉的工具:Claude Code 做了什么,它就做了什么——只不过模型换成了 DeepSeek,成本降到了 1/10。
但这个"1/10"背后的原因,不只是模型便宜。接下来我们从架构开始拆。
一、架构拆解:为什么说它不是套壳
大多数"支持 DeepSeek"的工具是这样做的:
base_url = "https://api.deepseek.com/v1"
# 然后照旧跑,什么都没改DeepSeek-TUI 的思路完全不同。作者用 Rust 从零写了一套针对 DeepSeek V4 经济结构专门设计的执行引擎。整体架构如下:
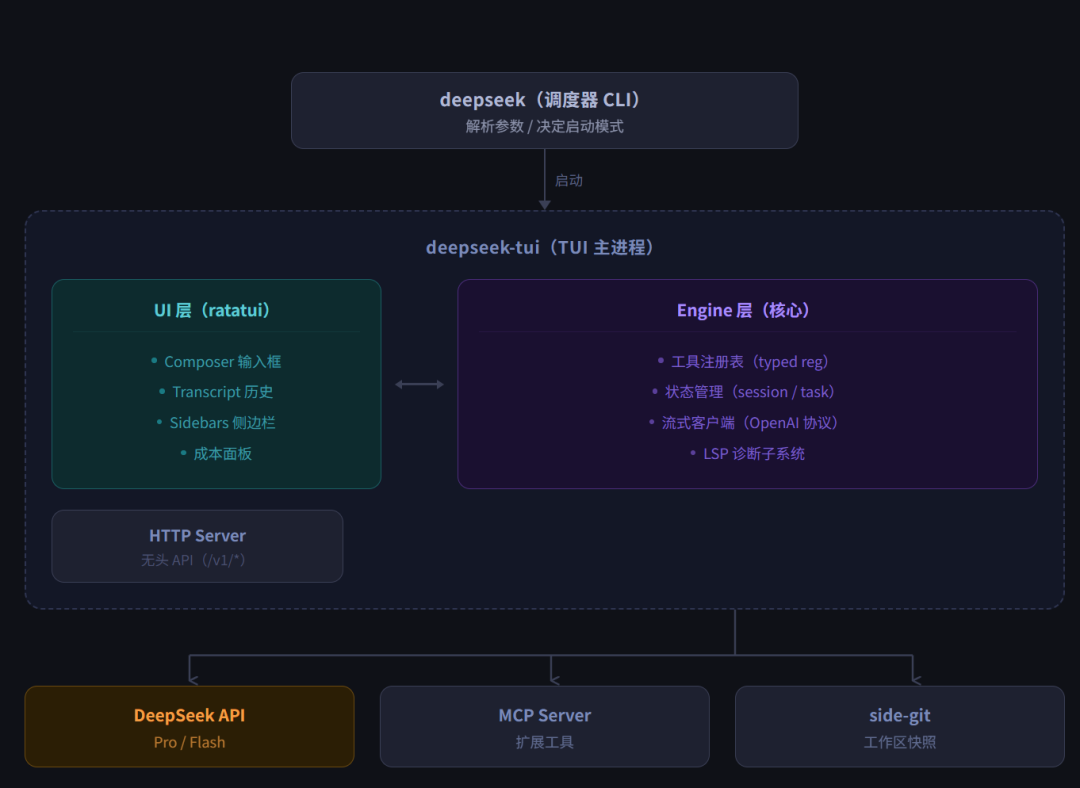
工具注册表里有什么:
|
工具 |
功能 |
|---|---|
read_file
/ |
文件读写,edit 输出内联 unified diff |
shell |
Shell 命令执行(带沙箱) |
git_* |
diff / log / commit / patch / restore |
web_search
/ |
网络搜索 & 页面抓取 |
rlm_query |
并行调度 1-16 个 Flash 子任务 |
agent_spawn
/ |
子 Agent 完整生命周期管理 |
load_skill |
动态加载 Skill 指令包 |
|
MCP 工具集 |
通过 |
LSP 诊断子系统是一个被很多评测忽略的细节:每次编辑后,TUI 会自动调用 rust-analyzer、pyright、typescript-language-server、gopls、clangd 等语言服务器,把诊断结果(错误/警告)直接注入到下一轮模型上下文里——AI 不只是"写完就算",而是写完、看诊断、再修,形成一个自动闭环。
二、成本模型:为什么能做到 1/10
这是这篇文章最核心的部分,也是大多数评测没讲透的地方。
2.1 基础定价对比
|
模型 |
输入(/百万 Token) |
输出(/百万 Token) |
前缀缓存命中 |
|---|---|---|---|
|
DeepSeek V4 Flash |
$0.14 |
$0.28 |
$0.003625 |
|
DeepSeek V4 Pro(折后) |
$2.19 |
$8.75 |
— |
|
Claude Opus 4 |
~$15 |
~$75 |
有,价更高 |
DeepSeek V4 Pro 折扣(75% off)有效期至 2026 年 5 月 31 日 23:59(北京时间),之后回标准价,以官网为准。
Flash 的价格是 Claude Opus 的 约 1/107(输入)到 1/268(输出)。这是定价差,还不是实际任务差。
2.2 前缀缓存:每次请求省 97.5%
这才是 DeepSeek-TUI 成本模型里最重要的机制,没有之一。
原理: 一个 Agent 会话里,以下内容在每次请求时都会重复发给模型:
-
系统 Prompt(工具定义、行为指令)
-
已有的对话历史
-
项目上下文(你
@的文件)
在 Claude Code 里,这些内容每轮都按正常价计费。
在 DeepSeek-TUI 里,这些内容会被主动结构化、前置,命中 DeepSeek 的前缀缓存。**命中缓存的 Token 价格是正常价格的 2.5%**( 0.14)。
一个具体的计算例子:
假设你的系统 Prompt + 工具定义 = 5,000 Token,每次请求都会重复发。跑一个 20 轮对话的任务:
不用缓存:5,000 × 20 轮 × $0.14/MTok = $0.014
命中缓存:5,000 × 20 轮 × $0.003625/MTok = $0.000363单这一项就省了 **97.4%**。
TUI 界面底部会实时显示 Cache Hit / Miss 明细,你能精确看到每轮省了多少钱。
注意事项: 前缀缓存有一个技术限制——缓存的命中需要前缀完全一致。长任务(超过 30 分钟)随着对话历史不断追加,前缀结构会发生变化,命中率会逐渐下降。这时候用 /compact 指令手动压缩上下文,可以恢复一部分命中率。
2.3 Auto 模式:低成本路由,高成本执行
deepseek --model auto "帮我重构这个模块"Auto 模式的工作机制:
用户输入 → Flash 快速预判(极低成本)
↓
判断:简单任务?复杂任务?需要 Thinking?
↓
路由:Flash 直接回答 / Pro + Thinking 深度处理这是一个标准的"廉价路由 + 昂贵执行"架构,在后端工程里很常见(轻量规则过滤 + 重型业务处理)。用在 Agent 的 Token 消耗管理上,效果很显著。
实测体感(三天数据):约 75-80% 的日常编程任务 Flash 够用,只有复杂 debug 和架构设计才会升 Pro。平均成本比固定用 Pro 低 60% 以上。
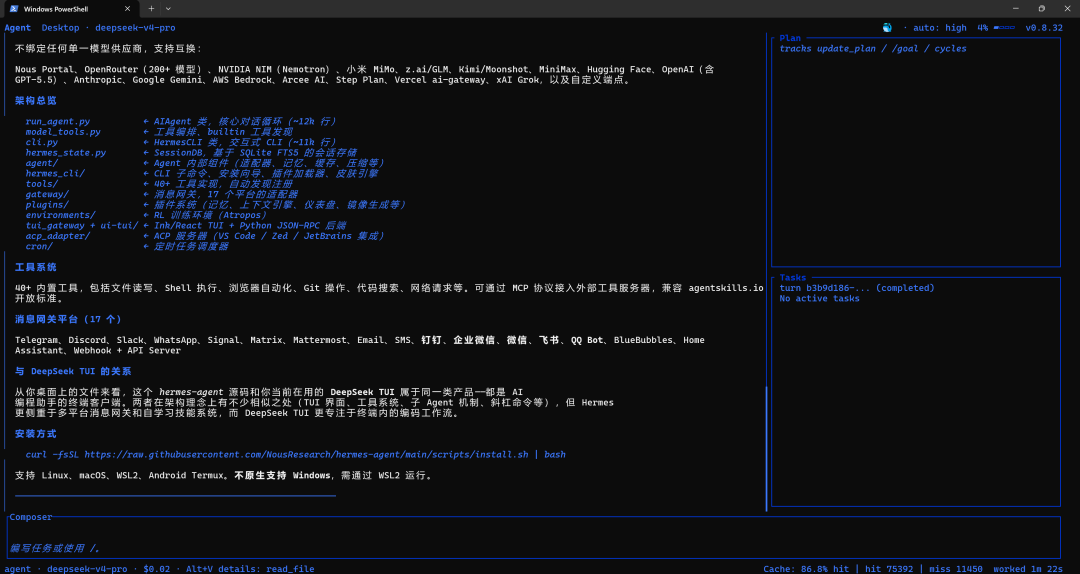
三、RLM 并行子 Agent:技术亮点深度拆解
这个功能是 DeepSeek-TUI 与所有竞品真正拉开差距的地方。
3.1 原理
普通 Agent 串行执行:
任务
└─ 分析
└─ 步骤1(读文件A)→ 步骤2(读文件B)→ ... → 步骤N → 汇总
总时间:T1 + T2 + ... + TNRLM(Recursive Language Model)并行执行:
任务
└─ Pro 协调器(分析 + 任务拆解,短暂调用)
├─ Flash 子Agent-1(处理文件A)─┐
├─ Flash 子Agent-2(处理文件B)─┤
├─ Flash 子Agent-3(处理文件C)─┤ 并行
│ ...(最多16路) ├─ Pro 汇总
└─ Flash 子Agent-N(处理文件N)─┘
总时间:max(T子任务) + T汇总RLM 在内部启动一个 Python 沙箱,把子任务喂给 Flash 进行批量化处理,子任务结果不会污染父 Agent 的主上下文,最终只把结论返回给 Pro 协调器。
3.2 成本分析
以一个具体例子说明:给一个有 200 个文件的 monorepo,让每个文件打"是否涉及鉴权逻辑"的标签。Claude Code 通常会顺序读、顺序判断;DeepSeek-TUI 用 RLM 一次发 16 个 Flash 实例并行打标,每个实例独立成本约等于 $0.14/MTok 输入价里那一份——并行带来的速度收益和成本收益是叠加的。
并行成本不叠加是关键点:16 个 Flash 并行,总成本 = Flash 价格 × 总 Token 消耗,不会因为并行而乘以 16。
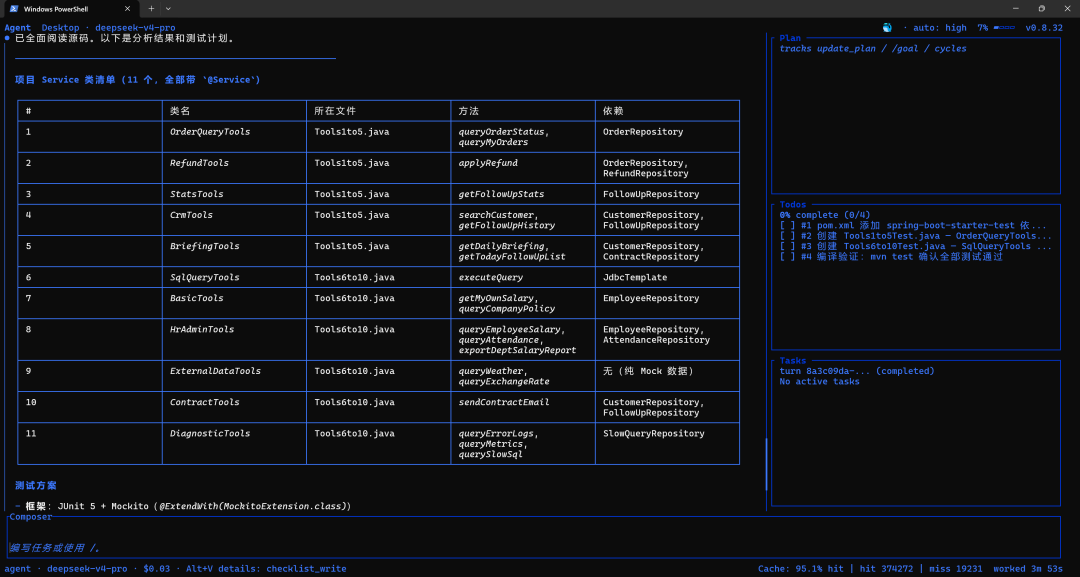
实测数据(给 11 个 Service 类批量生成单元测试):
|
指标 |
DeepSeek-TUI + RLM |
Claude Code(估算) |
|---|---|---|
|
执行时间 |
4 分钟 |
12-15 分钟 |
|
费用 |
¥1.2 |
¥6-8 |
|
并行度 |
11 个子任务同时跑 |
串行逐个处理 |
3.3 适合 RLM 的场景 vs 不适合的场景
适合:
-
给 N 个独立模块批量生成文档 / 注释
-
给 N 个独立类批量生成单元测试
-
对大型 monorepo 批量做代码审查
-
把一份大文件拆成独立章节分别处理
不适合(强调:不要用 RLM):
-
子任务之间有数据依赖(A 的结果要作为 B 的输入)
-
需要维护全局状态的重构任务
-
有顺序要求的数据库迁移脚本
TUI 目前没有依赖感知机制,有依赖的任务并行执行会产生不一致,回滚也麻烦。
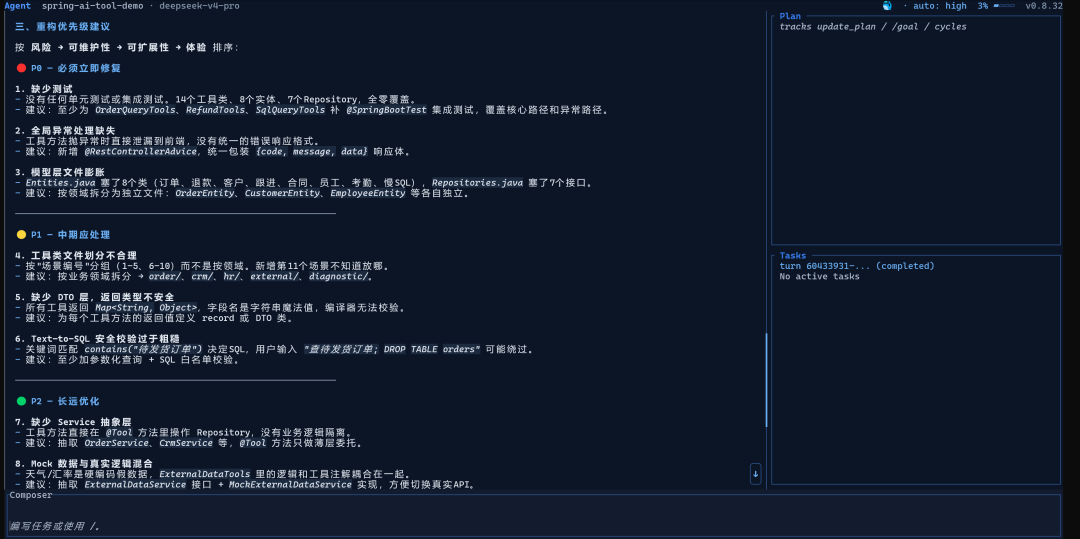
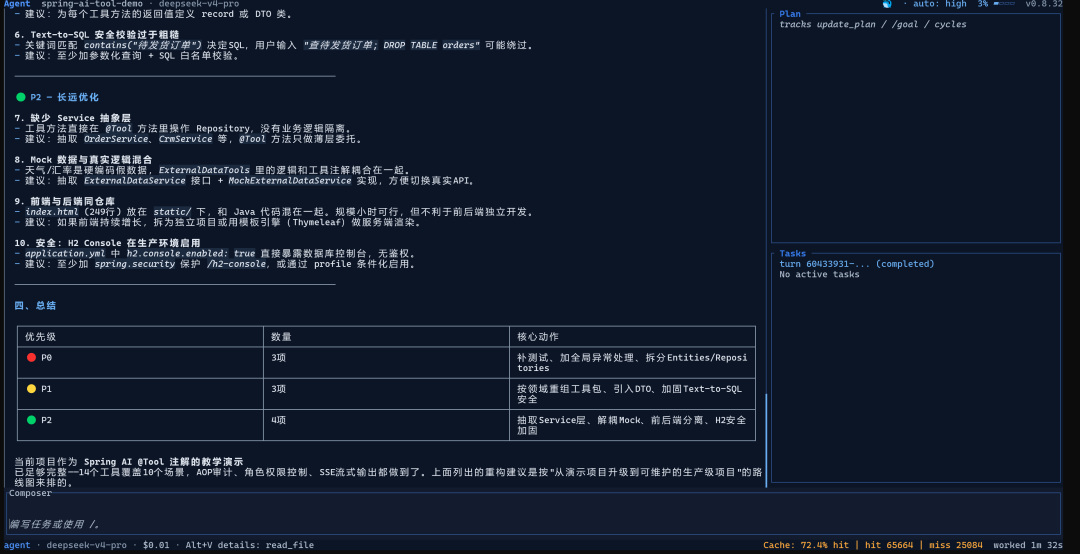
四、三种模式的深度对比
Plan 模式
/plan 分析这个 Spring Boot 项目的架构,给出重构优先级建议它做什么: 只读项目结构和文件内容,给你一个带优先级的任务清单,不修改任何文件。
什么时候必须用: 第一次接手陌生代码库、任务描述有歧义、上次跑 Agent 跑偏了需要重新对齐。
我的真实经历: 有两次直接跳进 Agent,跑了一段发现 AI 理解方向不对,改动已经写进去了,回滚 + 重新解释 + 重跑,浪费了将近半小时。Plan 那 5 分钟是值得花的保险。
原理细节: Plan 模式只调用只读工具(read_file、list_directory),不调用 write_file、shell、git_* 等写操作工具。你在 Plan 模式里的所有上下文会被保留,切到 Agent 模式后可以直接接着跑。
Agent 模式(默认)
核心设计是每次关键操作前暂停确认,并展示具体内容:
═══════════════ 待执行操作 ═══════════════
操作类型:write_file
目标文件:src/test/java/UserServiceTest.java
内容预览(前15行):
─────────────────────────────────────
@ExtendWith(MockitoExtension.class)
class UserServiceTest {
@Mock
private UserRepository userRepository;
@InjectMocks
private UserService userService;
@Test
void testFindById_Success() {
// given
User mockUser = new User(1L, "张三", "zhangsan@test.com");
when(userRepository.findById(1L)).thenReturn(Optional.of(mockUser));
─────────────────────────────────────
确认执行? [y] 是 [n] 否 [s] 跳过这步 [e] 编辑后执行
══════════════════════════════════════注意这个确认框有 [e] 编辑后执行 选项——你可以在执行前直接修改 AI 打算写的内容,比 Claude Code 的"要么接受要么拒绝"给了更多控制权。
工作区回滚(side-git): Agent 模式下,每次执行前后 TUI 都会通过 side-git 打一个快照,存储在 ~/.deepseek/workspaces/<项目名>/ 下,不会碰你项目自己的 .git。跑偏了随时 /restore 回去。
/restore # 查看可回滚的快照列表
revert_turn 3 # 回到第 3 轮执行之前的状态YOLO 模式
deepseek --yolo
# 或者启动后输入
/yolo所有操作不等确认,直接执行。
适用场景:
-
全新建立的测试项目(没有历史包袱)
-
搭脚手架 / 初始化骨架
-
CI 环境里的自动化批处理
不适用场景:
-
存量代码库的任何改动
-
你对这个工具还没建立足够的信任积累
关于"信任积累"这件事: 我在 Claude Code 上用了半年,才敢偶尔开它的 YOLO 等价模式(--dangerously-skip-permissions)。DeepSeek-TUI 用了三天,信任还没建起来。这不是工具的问题,是使用时间的问题。YOLO 的前提是你对工具的判断风格足够熟悉,知道它在哪些情况下会保守、哪些情况下会冒进。
五、被忽视的隐藏功能
5.1 Skills 系统:可迁移的指令包
这个功能和 Claude Code 的 CLAUDE.md 类似,但做了一个很聪明的设计:
发现路径(first-wins 顺序):
.agents/skills/ ← 项目级别
./skills/
.opencode/skills/ ← 兼容 OpenCode
.claude/skills/ ← 兼容 Claude Code ✅
~/.deepseek/skills/ ← 用户全局这意味着你已经积累的 Claude Code skills 或 OpenCode skills 可以零迁移在 DeepSeek-TUI 下使用。
管理命令:
/skills # 列出所有可用 Skills
/skill my-spring-skill # 激活指定 Skill
/skill new # 创建新 Skill
/skill install github:owner/repo # 从 GitHub 安装社区 Skill
/skill update # 更新
/skill uninstall # 卸载创建一个自己的 Skill(例子):
mkdir -p ~/.deepseek/skills/java-test-style
cat > ~/.deepseek/skills/java-test-style/SKILL.md << 'EOF'
---
name: java-test-style
description: 生成 JUnit 5 单元测试时使用,规范测试风格和命名
---
# Java 测试风格规范
生成单元测试时,严格遵守以下约定:
1. 测试方法命名:`测试方法名_场景_预期结果`,如 `findById_existingId_returnsUser`
2. 必须使用 @ExtendWith(MockitoExtension.class),禁止 @RunWith
3. Mock 注入统一用 @InjectMocks,不手动 new
4. Given-When-Then 三段式注释,禁止省略
5. 异常测试用 assertThrows,不用 @Test(expected=...)
EOF激活后,每次生成测试代码,AI 会自动遵守这套规范。
5.2 User Memory:跨会话偏好保持
# 在配置文件里启用
enable_user_memory = true
# 或者在 TUI 里
/memory add "我的项目都用 Java 17,依赖管理用 Maven,不用 Gradle"
/memory add "测试框架统一用 JUnit 5 + Mockito,禁止用 PowerMock"Memory 内容会被注入到每次对话的系统 Prompt 里,不用每次重复交代背景信息。
5.3 Thinking 强度可实时调节
用 Shift+Tab 在 TUI 里实时切换推理强度:
off → high → max → off(循环切换)-
off:不开 Thinking,速度最快,成本最低,适合简单任务 -
high:中等推理深度,日常 debug 够用 -
max:最强推理,复杂架构问题、看不懂的 bug,上这个
切换后右侧状态栏会实时显示当前档位,Token 消耗随之变化。
5.4 HTTP/SSE 无头 API:嵌入其他工具
deepseek serve --http启动后,TUI 暴露一个 /v1/* REST API,可以把 DeepSeek-TUI 嵌入 IDE 插件、Web UI、CI 脚本:
# 示例:通过 API 触发一个 Agent 任务
curl -X POST http://localhost:8765/v1/sessions \
-H "Content-Type: application/json" \
-d '{"prompt": "给 src/service 所有文件生成文档注释", "mode": "agent"}'这对需要把 AI 任务集成到 CI/CD 流水线的场景非常有用。
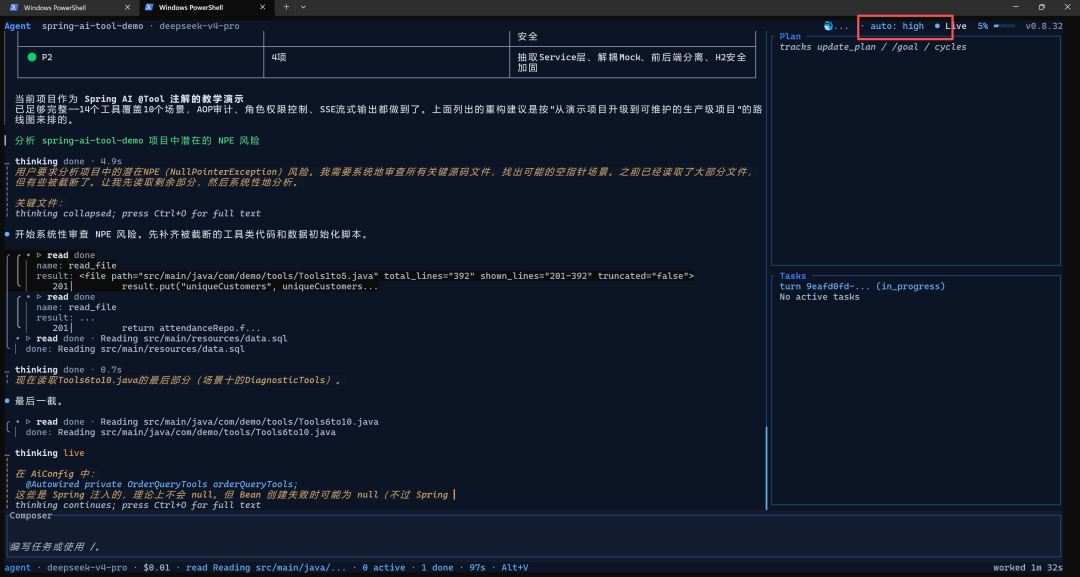
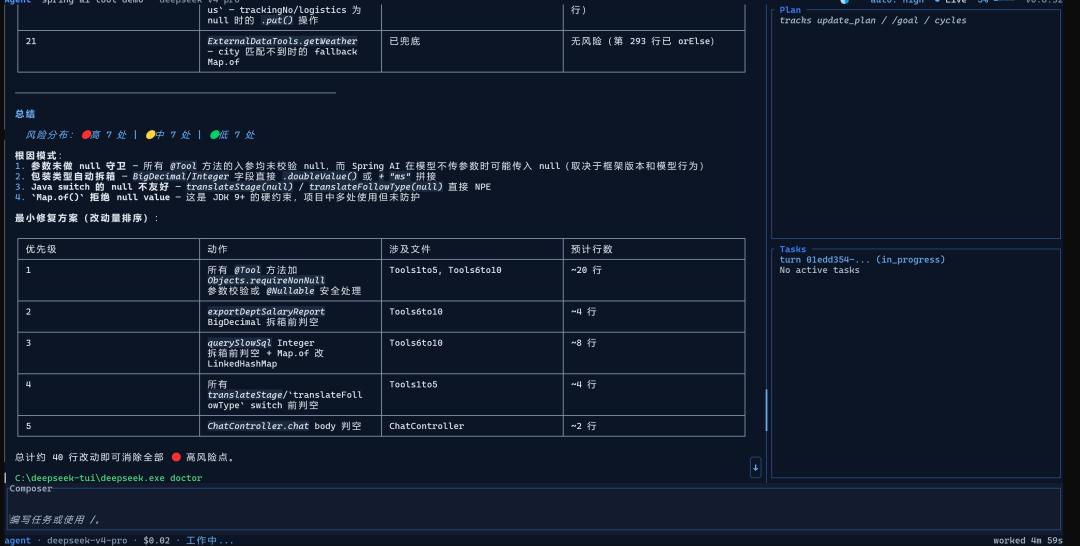
六、安装全流程(含所有真实踩坑)
方式一:npm(推荐,最省事)
npm install -g deepseek-tui
deepseek --version注意: npm 包本身只是个下载器,会自动从 GitHub Releases 拉取对应平台的预编译 Rust 二进制。Node.js 装好就能用,deepseek 本身运行时不依赖 Node。
方式二:Homebrew(macOS)
brew install deepseek-tui踩坑 1: 如果报 Your Command Line Tools are too outdated,先去苹果官网下载最新版 Xcode Command Line Tools,更新后重跑 brew 命令。
踩坑 2: Homebrew 的 manifest 可能比 GitHub/npm 版本滞后,如果需要最新版,用 npm 或直接下二进制。
方式三:Cargo(Rust 开发者)
cargo install deepseek-tui-cli --locked # 安装 deepseek 调度器
cargo install deepseek-tui --locked # 安装 deepseek-tui 运行时国内网络可以配置镜像:
# ~/.cargo/config.toml
[source.crates-io]
replace-with = "rsproxy"
[source.rsproxy]
registry = "https://rsproxy.cn/crates.io-index"方式四:直接下二进制
去 github.com/Hmbown/DeepSeek-TUI/releases:
|
平台 |
需要下载的文件(两个都要!) |
|---|---|
|
macOS Apple Silicon |
deepseek-aarch64-apple-darwin
+ |
|
macOS Intel |
deepseek-x86_64-apple-darwin
+ |
|
Linux x86_64 |
deepseek-x86_64-unknown-linux-gnu
+ |
|
Windows x64 |
deepseek-windows-x64.exe
+ |
⚠️ 最大的坑:两个二进制都必须在 PATH 里!
deepseek(调度器)负责解析命令和决策,deepseek-tui(运行时)负责渲染 TUI 和执行 Agent 逻辑。少一个就报错,但报错信息不直观,很多人卡在这里半天没反应过来。
# macOS / Linux
sudo mv deepseek deepseek-tui /usr/local/bin/
chmod +x /usr/local/bin/deepseek /usr/local/bin/deepseek-tui
deepseek --version # 验证,应该输出版本号配置 API Key
# 推荐方式:存到配置文件,对 IDE、脚本、cron 全场景生效
deepseek auth set --provider deepseek
# 按提示输入 key 即可
# 验证读取是否正常
deepseek doctor踩坑(zsh 用户):
# ❌ 错误:写在 ~/.zshrc 里,只对交互式 shell 生效
export DEEPSEEK_API_KEY="sk-xxx"
# ✅ 正确:写在 ~/.zshenv,对所有场景(IDE 终端、脚本、cron)生效
echo 'export DEEPSEEK_API_KEY="sk-xxx"' >> ~/.zshenv去哪里拿 API Key:platform.deepseek.com 注册,新用户有免费额度,够跑十几轮任务。
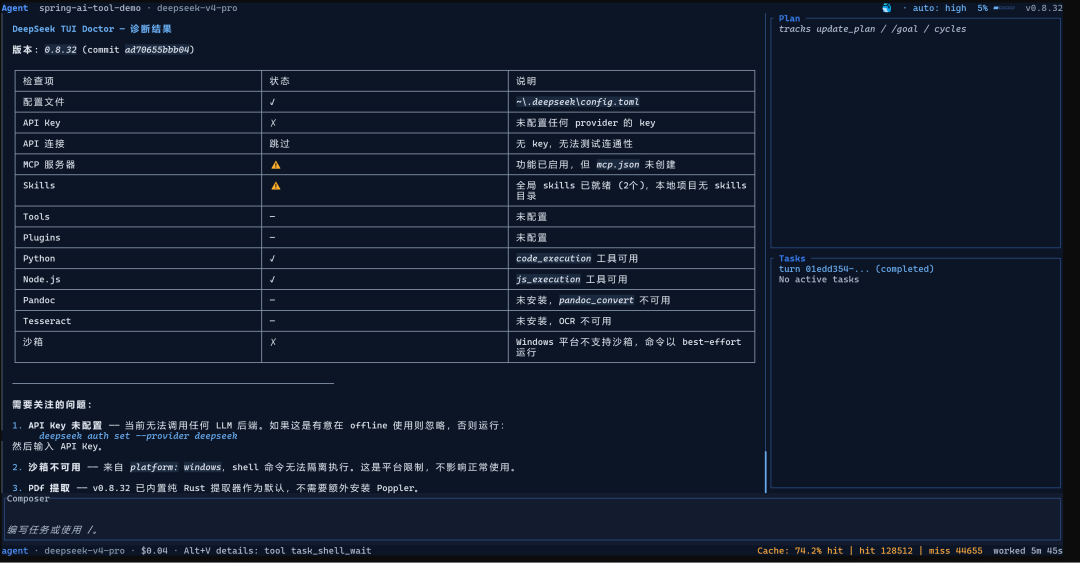
七、全部踩坑清单
|
# |
坑 |
具体现象 |
解决 |
|---|---|---|---|
|
1 |
只放了一个二进制 |
deepseek: command not found
或启动后立刻崩 |
deepseek
和 |
|
2 |
macOS CLT 太旧 |
brew install
失败,提示 Command Line Tools outdated |
苹果官网更新 CLT,再重跑 brew |
|
3 |
zsh API Key 写错位置 |
IDE 终端里报 |
写 |
|
4 |
长任务缓存命中率下降 |
实际费用比 TUI 初始估算高 20-40% |
超过 30 分钟的任务跑 |
|
5 |
RLM 用在有依赖任务上 |
结果不一致,文件互相覆盖 |
有依赖的任务用普通 Agent 模式,不用 RLM |
|
6 |
YOLO 模式用在存量代码库 |
改了很多文件,有的改错了 |
存量库永远用 Agent 模式,YOLO 只用于全新项目 |
|
7 |
文档落后于代码 |
按 README 操作遇到奇怪行为 |
先去 GitHub Issues 搜,比搜教程有用 |
|
8 |
Windows PowerShell 斜杠菜单抖动 |
输入 |
升级到最新版,v0.8.8+ 已修复 |
八、核心配置文件(直接复制)
# ~/.deepseek/config.toml
# ===== 核心模型 =====
# 日常首选 flash(便宜快),复杂任务 Shift+Tab 切 Thinking 强度
model = "deepseek-v4-flash"
context_window = 1000000
api_base = "https://api.deepseek.com"
# ===== 推理参数 =====
thinking_mode = "normal" # off / normal / high / max
temperature = 0.1 # 编程场景最优,输出稳定
top_p = 0.95
max_tokens = 8192
# ===== 执行与安全 =====
max_parallel_agents = 4 # CPU 核数决定,8 核推荐 8,最高 16
auto_approve = false # 存量代码库永远 false
enable_git = true # 强烈建议开,支持 /restore 回滚
# ===== 功能开关 =====
enable_mcp = true
enable_web_search = true
enable_user_memory = true
enable_auto_compress = true # 长会话自动压缩,减少 Token 浪费
# ===== 费用显示 =====
cost_currency = "CNY" # 显示人民币,更直观九、我的工具分工(用了一周后的判断)
|
场景 |
工具 |
理由 |
|---|---|---|
|
批量文档 / 注释生成 |
DeepSeek-TUI + RLM |
并行快,Flash 便宜,质量够用 |
|
批量单元测试 |
DeepSeek-TUI + RLM |
独立模块最适合并行 |
|
陌生代码库摸底 |
DeepSeek-TUI |
几毛钱,先看看再说 |
|
想看 AI 推理链 |
DeepSeek-TUI |
Thinking 可视化,Claude Code 没有 |
|
大型 monorepo 打标 / 审查 |
DeepSeek-TUI + RLM |
200 个文件并行打标,成本优势极大 |
|
CI 容器批量任务 |
DeepSeek-TUI |
12MB 内存 vs Node.js 几百 MB |
|
核心业务逻辑重构 |
Claude Code |
质量上限更高,长任务稳定性更好 |
|
生产环境 bug debug |
Claude Code |
信任校准还没建立,不赌 |
|
需要 GitHub / Slack 等 MCP |
看具体配置 |
两个都支持 MCP,看哪个 MCP 服务更成熟 |
最后:让我真正停下来想的两件事
第一件:我对 Claude Code 的"信任",有多少是能力信任,有多少是习惯依赖。
用了大半年 Claude Code,我以为我信任它的能力。但仔细拆开来看,信任的来源很大一部分是:我熟悉它的行为模式、知道它什么时候保守、什么时候冒进,我对"它的判断风格"有了直觉。
这不是纯粹的能力信任——这是经验校准,是靠使用时间积累的,换工具就要重建。
DeepSeek-TUI 在批量任务场景下质量完全够用,但我对它的经验校准还没建立起来,所以暂时不会把核心业务的判断押给它。这是真实的切换成本,值得说清楚。
第二件:终端 Agent 的护城河,不只是模型能力,更是工程积累的时间。
Claude Code 做了一年多,长任务稳定性、错误恢复机制、边界条件处理——这些都是一个个线上 bug 修出来的。DeepSeek-TUI 现在还在 v0.8,这个差距是真实的。
但 v0.8 在一周内就积累了 22,000 Star、迭代了十几个版本——这个速度也是真实的。
一个人,用 Rust,没有大厂背书,成本 1/10,一周打进 GitHub 全球榜一。
这件事本身就说明:终端 Agent 这件事,没有想象中那么难做,也没有想象中那么容易做好。
值得装上去跑几个任务。Flash 模式,按量计费,花不了几毛钱,你会有自己的判断。
项目地址:github.com/Hmbown/DeepSeek-TUI
中文 README:github.com/Hmbown/DeepSeek-TUI/blob/main/README.zh-CN.md
DeepSeek API 注册:platform.deepseek.com

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)