
AI编程神话破灭?顶级模型全军覆没,从零写个软件比登天还难
当各大科技巨头还在吹嘘自家大模型可以"写代码如写诗"时,一项颠覆性的测试结果让整个AI圈陷入了沉默。包括Claude、GPT、Gemini在内的几乎所有顶级AI模型,在一项名为"ProgramBench"的全新测试中,完成率竟然是——0%。
这不是危言耸听,而是来自Meta FAIR联合斯坦福、哈佛等顶尖机构近日发布的真实研究结果。
事件回顾:一个让AI圈"破防"的测试
事情的起因,是SWE-Bench测试的创建者——那个曾让许多开发者惊艳的新基准测试——再次放出了一个"地狱级"的新benchmark。

与以往不同的是,这次测试不再满足于让AI"补全一段代码"或"修复一个bug",而是直接给AI一个程序的功能描述和文档,然后问它:能不能从零开始,像真正的工程师一样,重新构建一个真实可执行的软件系统?
测试项目包括ffmpeg、SQLite、ripgrep这些业内知名的软件项目。而且——不能联网查阅。
测试结果:全员0%,全场哑火
结果出来后,整个AI编程社区炸锅了。
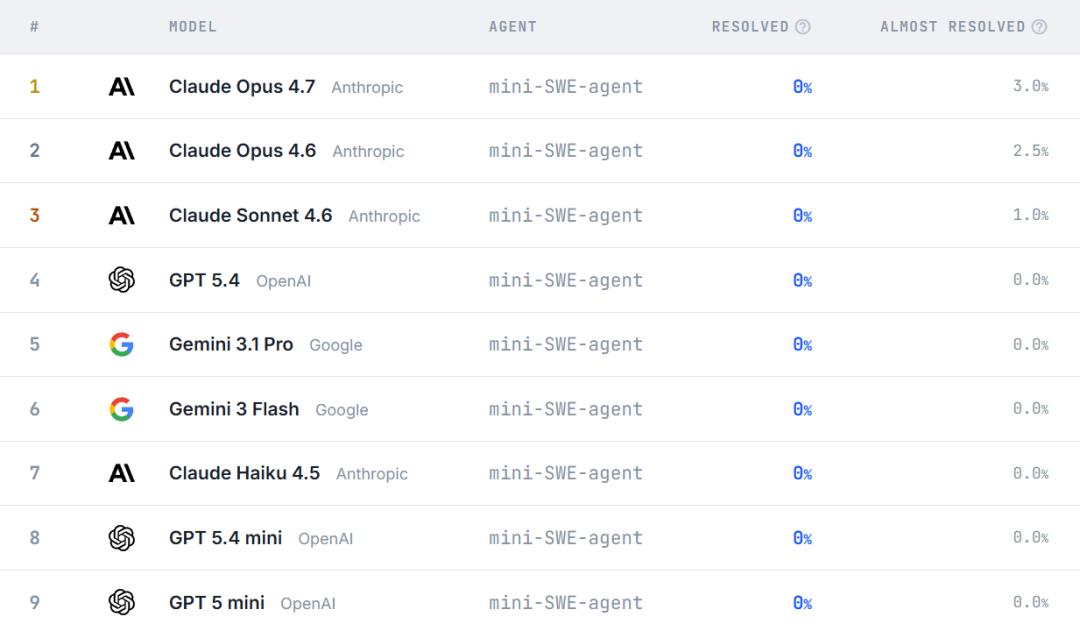
测试模型 完成率
Claude Opus 4.7 0%
GPT-5.4 0%
GPT-5 mini 0%
Gemini 3.1 Pro 0%
Gemini 3 Flash 0%
没有一个模型能够真正完整重建一个软件项目。
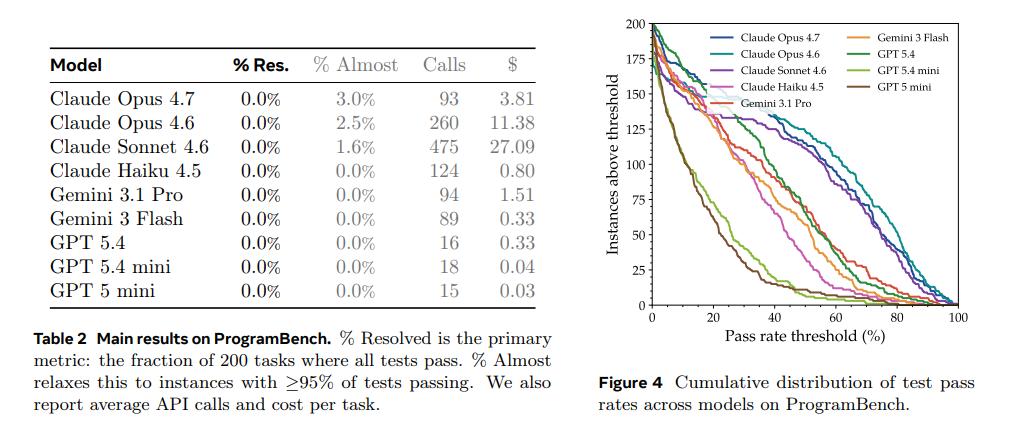
更让人大跌眼镜的是,即使把标准放宽到"完成度超过95%算通过",表现最强的Claude Opus 4.7,也只有3%的任务接近完成。
测试为何如此"地狱级"?
理解ProgramBench,先要明白它与传统代码测试的本质区别。
过去的代码能力测试,大多是在已有代码框架里做局部修改。比如给你一个函数让你补全,或者给一个项目让你修复bug。这就像考试里给你公式,让你填答案。

但ProgramBench完全不同。它删除了所有原始源码和测试,只保留可执行文件和用法文档。模型需要自己决定:用什么编程语言、怎么拆分模块、怎么组织目录结构、怎么设计数据流。
更重要的是,它不看你代码写得像不像人类,而是看行为是否等价——只要最终输入输出的行为一致,用完全不同的语言、算法、架构实现,都算通过。
为什么AI会全军覆没?
研究团队发现了一个核心问题:AI擅长局部代码生成,但不擅长全局系统规划。
模型"偷懒"的三大表现
单体化代码倾向:模型生成的代码大多塞在一个文件里,没有模块拆分
目录结构极浅:不像人类工程师会建多层文件夹、合理分类
函数超长:一个函数动辄几百行,完全违背软件工程的最佳实践
这些特点暴露出AI的根本短板——它能把局部代码写得很漂亮,但一旦面对需要长期维护、多模块协作、可扩展的大型系统,立刻就会"崩盘"。
语言表现差异背后
研究还发现,不同编程语言的项目测试,模型表现差异巨大:
C/C++:完成率最高——因为互联网上C/C++历史代码、工程实践和教程实在太多了
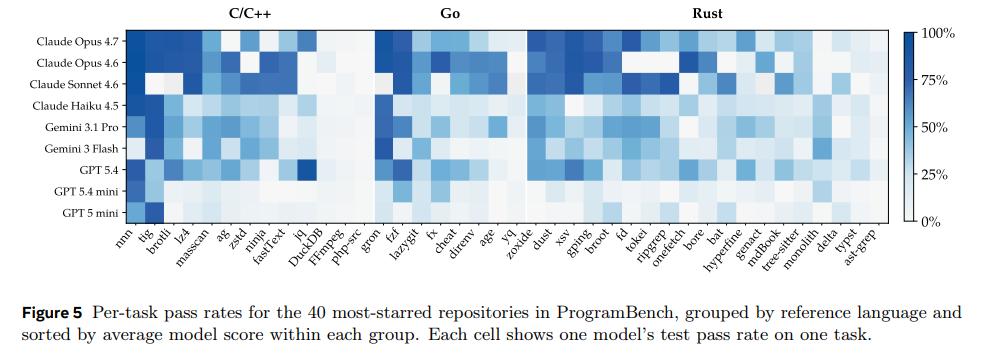
Rust:表现最差——因为Rust的工程哲学强调模块化、所有权系统和长期可维护性,恰恰是模型最不擅长的
某种意义上,Rust测出来的不是代码能力,而是真正的工程能力。
行业争论:这是测试还是刁难?
随着ProgramBench引发热议,围绕这项测试的讨论也迅速发酵。
质疑一:AI是不是背过这些开源代码?
有声音指出,测试里用的都是公开开源软件,AI可能只是记忆而非理解。
对此,硅谷投资人Deedy Das回应称,任何benchmark都可能被"过拟合"。如果模型真的试图用蛮力硬背这些程序,会在其他任务上明显退化。而且研究人员可以通过比对生成代码与原始源码的相似度,检测是否存在直接记忆。
质疑二:连人类都很难从零写FFmpeg,这不合理
也有人吐槽说,这项测试要求太高,连人类工程师都未必能做到从零重写FFmpeg。

Deedy Das表示,那又怎样?很多LLM能做到的事,人类平均水平也做不到。benchmark的目标不是模拟普通人,而是推动模型向更高层次的智能逼近。
质疑三:为什么不测没人解决过的问题?
对于为什么不用全新问题,Deedy Das解释,因为那会让benchmark几乎无法构建——没有标准答案,很难判断任务是否真实。
技术深层原因:软件工程≠写代码
这篇论文里,有一句话特别关键:
Models favor monolithic, single-file implementations that diverge sharply from human-written code.
翻译成通俗语言就是:模型极度倾向于生成单体化代码——大量逻辑塞进单文件,目录结构极浅,模块拆分极少,整个仓库看起来像一坨巨型脚本。
这和优秀人类工程师的习惯,几乎完全相反。
人类工程师讲究模块和关注点分离,配置放配置文件,工具函数放独立文件,数据库操作单独处理,然后通过import相互调用。
这恰恰是AI目前最缺的能力——真正的软件开发,从来都不是写一个函数,而是如何做出一个能被维护、被扩展、被团队协作的工程系统。
行业未来:从代码生成到系统构建
ProgramBench暴露出的,是整个行业当前最大的断层。
今天的大模型,已经非常擅长生成局部代码。Copilot、Cursor这些工具确实让写代码变得更快。但一旦进入真实世界的大型工程系统,AI就会迅速掉进深水区。
当前AI编程的真正瓶颈已经不再是代码生成能力,而是长期的软件系统构建能力。
这也解释了为什么最近整个行业都开始疯狂研究一批新关键词:memory、agents、repo-level reasoning、long-horizon planning、autonomous software engineering。
因为下一阶段的竞争,可能已经不再是谁能一次性生成更长的代码,而是谁能在长时间、多轮交互、复杂上下文中,持续稳定地维护一个活着的软件系统。
结语
ProgramBench的0%完成率,或许不是终点,而是一个起点。
它提醒我们:AI离真正的"软件工程师"还很远。AI写代码的能力确实在飞速进步,但要独立完成从设计到实现的完整软件工程,还有很长的路要走。
或许有一天,AI能真正从零构建出可维护、可扩展、可协作的大型软件系统。但在那一天到来之前,我们还需要保持理性,既不盲目崇拜,也不轻言放弃。
毕竟,真正的进步,从来都是在认清差距之后开始的。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)