
LangChain RAG + FastAPI 接口化 + Docker 容器化(个人知识库问答系统)
✅ FastAPI 集成 LangChain。✅ Swagger API 文档。✅ 文件上传 + PDF 处理。✅ Docker 容器化。✅ RAG 系统接口化。,可以直接在线测试!
·
- 把 RAG 系统封装成 RESTful API(可被前端 / 小程序 / App 调用)
- 给 API 加 文档、异常处理、日志、配置化
- 把整套服务 Docker 容器化,一键部署、到处运行
- 接口支持:上传 PDF、构建知识库、提问、清空知识库
先讲核心新知识(必须掌握)
1. FastAPI 是什么?
高性能 Python Web 框架,用来把你的 AI 服务变成 API 接口:
- 自动生成 API 文档(
/docs) - 支持异步、高并发
- 类型提示、自动校验参数
- 适合做 AI 后端服务
2. Docker 是什么?
容器化工具,把你的代码 + 环境 + 依赖打包成一个镜像:
- 解决「在我电脑能跑,你那不能跑」问题
- 一键部署到服务器 / 云平台
- 隔离环境,稳定不冲突
3. 我们要做的架构
用户/前端 → FastAPI接口 → RAG系统 → Chroma向量库 → 返回回答🚀 第一步:项目结构(标准工程化)
rag_api_project/
├── .env # 配置文件
├── main.py # FastAPI 主程序
├── requirements.txt # 依赖
├── Dockerfile # 构建镜像
├── .dockerignore # Docker 忽略文件
└── uploads/ # 上传PDF目录
└── chroma_db/ # 向量库(自动生成)📦 第二步:完整代码(功能极强、稳定、可直接部署)
1. requirements.txt
fastapi==0.136.1
langchain-community==0.3.20
langchain-openai==0.3.20
uvicorn[standard]>=0.46.0
python-multipart
pymupdf
chromadb2. .env
DOUBAO_API_KEY=你的豆包key
CHROMA_DB_DIR=./chroma_db
UPLOAD_DIR=./uploads
HOST=0.0.0.0
PORT=8000
3. main.py(核心:FastAPI + RAG)
import os
import sys
# 强制所有 IO 操作使用 UTF-8 编码(必须在所有 import 之前)
if sys.platform == "win32":
sys.stdin.reconfigure(encoding='utf-8')
sys.stdout.reconfigure(encoding='utf-8')
sys.stderr.reconfigure(encoding='utf-8')
os.environ["PYTHONUTF8"] = "1"
os.environ["PYTHONLEGACYWINDOWSSTDIO"] = "0"
import logging
import shutil
import urllib.parse
from fastapi import FastAPI, UploadFile, File, HTTPException
from dotenv import load_dotenv
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from pyexpat.errors import messages
from starlette.responses import HTMLResponse, JSONResponse
# 日志配置
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 加载环境变量
load_dotenv()
UPLOAD_DIR = "./uploads"
CHROMA_DB_DIR = "./chroma_db"
app = FastAPI(title="RAG 文档回答 API", version="2.0")
print(os.getenv("UPLOAD_DIR"))
# 创建目录
os.makedirs(os.getenv("UPLOAD_DIR"), exist_ok=True)
# 初始化大模型
llm = ChatOpenAI(
api_key=os.getenv("ZHIPU_API_KEY"),
base_url="https://open.bigmodel.cn/api/paas/v4",
model="glm-4.6",
temperature=0.0,
)
# 嵌入
embedding = OpenAIEmbeddings(
openai_api_key=os.getenv("ZHIPU_API_KEY"), # 智谱API Key
openai_api_base="https://open.bigmodel.cn/api/paas/v4",
model="embedding-3"
)
# 全局变量
vector_db = None
rag_chain = None
# rag 工具函数
def load_pdf_build_rag(pdf_path):
global vector_db, rag_chain
# 加载
logger.info(f"Loading PDF: {pdf_path}")
loder = PyMuPDFLoader(pdf_path)
docs = loder.load()
logger.info(f"Loaded 完成 {len(docs)} documents")
# 分割
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\n\n", "\n", "。", "!", "?", " "]
)
split_chunks = splitter.split_documents(docs)
chunks = []
for chunk in split_chunks:
if chunk.page_content.strip():
# 强制UTF-8编码
chunk.page_content = chunk.page_content.encode("utf-8", errors="ignore").decode("utf-8")
chunks.append(chunk)
logger.info(f"开始构建向量库")
# 构建向量库
vector_db = Chroma.from_documents(
documents=chunks,
embedding=embedding,
persist_directory=CHROMA_DB_DIR,
)
logger.info(f"构建完成 向量库")
# 被遗弃了
# vector_db.persist()
# 构建rag
retriever = vector_db.as_retriever(k=3)
prompt = ChatPromptTemplate.from_template("""
你是严格的文档问答助手,只根据下面的文档内容回答。
不知道就说:文档中没有相关内容。
文档:
{context}
问题:
{question}
""")
logger.info("开始拼接链")
rag_chain = (
{"context":retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
logger.info("拼接链完成")
return len(chunks)
def clear_kownledge_base():
global vector_db, rag_chain
db_path = CHROMA_DB_DIR
if os.path.exists(db_path):
shutil.rmtree(db_path)
vector_db = None
rag_chain = None
# api接口
@app.get("/", summary="健康检查")
def health_check():
return {"status": "running", "messages":"RAG API服务正常"}
@app.post("/upload-pdf", summary="上传PDF并构建知识库")
def upload_pdf(file:UploadFile = File(...)):
try:
if not file.filename.endswith(".pdf"):
raise HTTPException(status_code=400, detail="只支持PDF文件")
# 2. ✅ 关键:处理中文文件名编码(解决 ascii 报错)
filename = file.filename
save_path = os.path.join(os.getenv("UPLOAD_DIR"), filename)
with open(save_path, "wb") as f:
f.write(file.file.read())
logger.info("加载PDF前")
chunk_num = load_pdf_build_rag(save_path)
logger.info("持久化数据完成")
return JSONResponse({
"status": "success",
"filename": filename,
"chunk_count": chunk_num,
"message": "PDF上传并构建知识库成功"
})
except Exception as e:
logger.error(f'上传失败:{str(e)}')
return HTTPException(status_code=500, detail=f'处理失败:{str(e)}')
@app.post("/ask", summary="向RAG提问")
def ask(question:str):
try:
if not vector_db or not rag_chain:
raise HTTPException(status_code=400, detail="请先上传PDF构建知识库")
answer = rag_chain.invoke(question)
return JSONResponse({
"status": "success",
"question":question,
"answer": answer
})
except Exception as e:
logger.error(f"提问失败:{str(e)}")
raise HTTPException(status_code=500, detail=f"处理失败:{str(e)}")
@app.post("/clear", summary="知识库清空")
def clear_db():
clear_kownledge_base()
return {"status": "success", "message": "向量库已清空"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(
"main:app",
host=os.getenv("HOST"),
port=os.getenv("PORT"),
reload=True
)
4. Dockerfile(容器化打包)
dockerfile
# 1. 基础镜像(Python 3.11 轻量级)
FROM python:3.12-slim
# 2. 设置工作目录
WORKDIR /app
# 换清华源加速,避免下载超时
RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 安装依赖
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
# 5. 复制全部代码
COPY . .
# 6. 暴露端口(Flask 默认 5000)
EXPOSE 8000
# 7. 启动命令
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]5. .dockerignore
__pycache__
.env
uploads/
chroma_db/
*.pyc
*.pyo
*.pyd📖 第三步:详细功能说明(超级重要)
1. 提供 4 个生产级 API
GET /→ 健康检查POST /upload-pdf→ 上传 PDF,自动构建向量库POST /ask?question=xxx→ 提问,返回 RAG 回答POST /clear→ 清空知识库
2. 自动生成 API 文档(可视化!)
启动后访问:
http://localhost:8000/docs
你会看到 Swagger UI 自动接口文档,可以直接在线测试!
3. 工程化特性
- 全局异常捕获
- 日志系统
- 类型校验
- 文件上传安全校验
- 环境变量配置
- 向量库持久化
- 状态管理(是否已上传 PDF)
🚀 第四步:运行方式(2 种)
方式 1:直接运行(本地测试)
python main.py
方式 2:Docker 容器运行(生产部署)
清理旧缓存:
docker system prune -f
docker rmi -f rag_api_project
# 构建镜像
docker build -t rag-api .
# 运行容器
docker run -d -p 8000:8000 rag_api_project:latest
🎯 第五步:API 调用示例(任何语言都能调用)
用 curl 调用
# 上传PDF
curl -X POST "http://localhost:8000/upload-pdf" -F "file=@test.pdf"
# 提问
curl -X POST "http://localhost:8000/ask?question=文档主要讲什么"
Python 调用
import requests
requests.post("http://localhost:8000/ask", params={"question":"什么是RAG"})
Postman调用
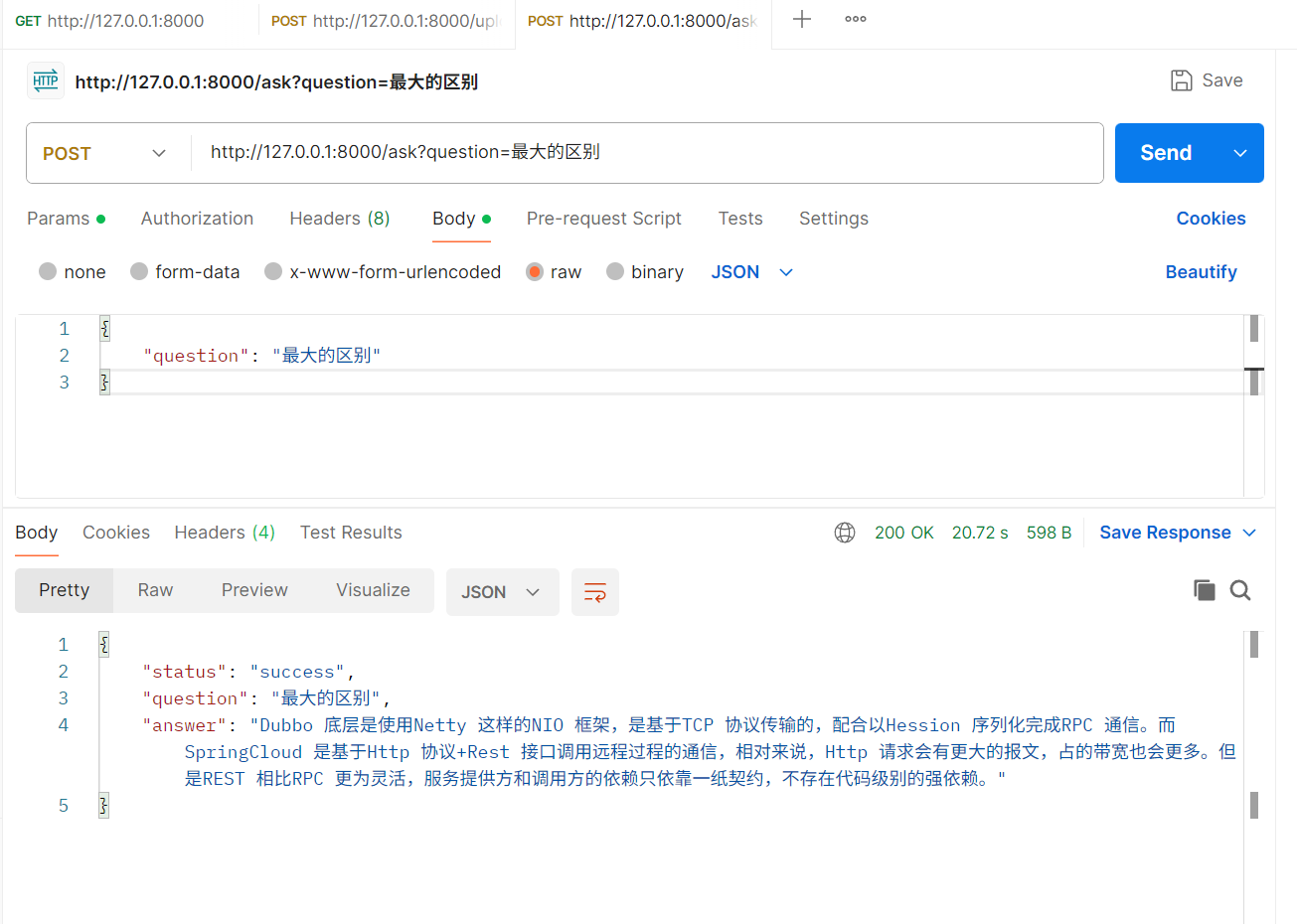
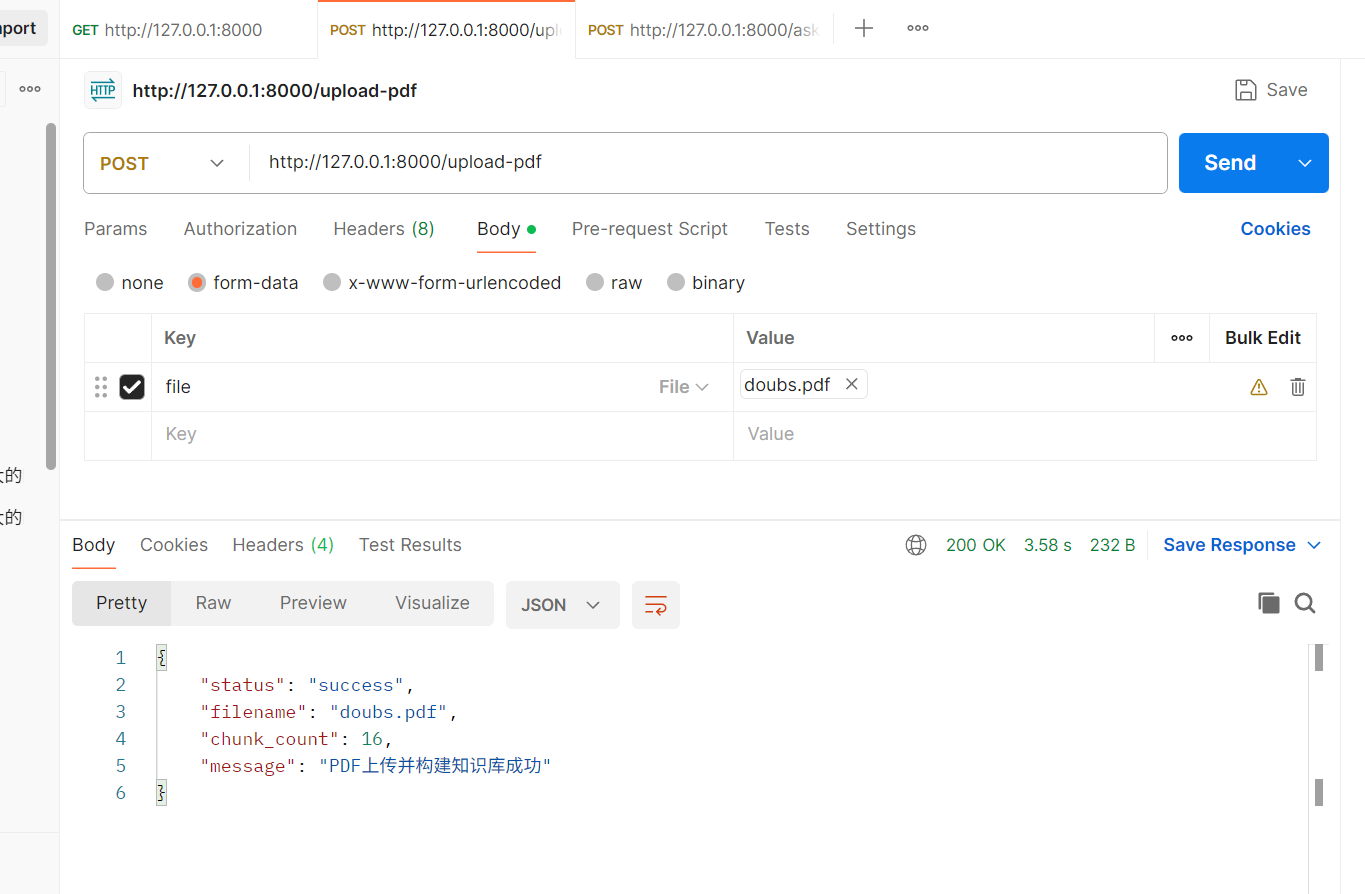
前端 / 小程序 / APP 都能调用!
🎯 第六步:你今天学到的硬核新知识
✅ FastAPI 集成 LangChain
✅ 文件上传 + PDF 处理
✅ RAG 系统接口化
✅ 全局异常处理
✅ 日志系统
✅ 环境变量配置
✅ Docker 容器化
✅ 生产级项目结构
✅ Swagger API 文档
🎯 第七步:遇到了ascii 编码报错
# ==========================================
# 【必须放在第一行】强制 Python 全局 UTF-8 编码
# ==========================================
import sys
import os
# 强制所有 IO 操作使用 UTF-8 编码(必须在所有 import 之前)
if sys.platform == "win32":
sys.stdin.reconfigure(encoding='utf-8')
sys.stdout.reconfigure(encoding='utf-8')
sys.stderr.reconfigure(encoding='utf-8')
os.environ["PYTHONUTF8"] = "1"
os.environ["PYTHONLEGACYWINDOWSSTDIO"] = "0"
汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 5
5 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)