
聊聊Deepseek V4,你可能忽略的彩蛋
4月24号,万众期待的DeepSeek,终于发布了V4版本。千呼万唤始出来啊。
依然开源,依然便宜,而且还升级到了万亿参数。
不过如果你关注AI圈,就会发现上周除了DeepSeek-V4,还有另一个万亿参数的开源模型发布,那就是Kimi K2.6。
在最新的Artificial Analysis和Openrouter榜单上,这两家创业公司排排坐,双双挤入前列,追赶GPT、Claude和Gemini,场面非常和谐。
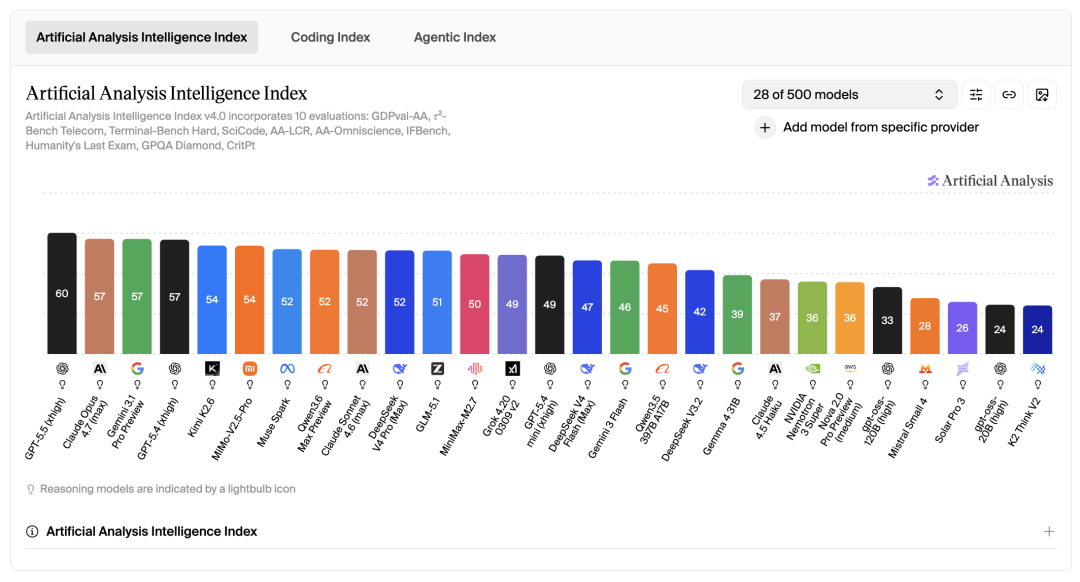
但是,如果你把视线移到太平洋对岸,你就会看到另一幅画面:硅谷AI的竞争,已经快从“智力竞赛”变成“黑手党火并”了。
1、
现在的硅谷,已经不是那个“开放、共享、改变世界”的理想国了,更像大型《甄嬛传》现场,《小时代》加强版。
OpenAI、Anthropic、谷歌这三家,过去半年干的事情只有两件:“造墙”顺便攻击“友商”。
为什么?
因为他们是闭源的捍卫者,在这条路线下,提高估值和收入的前提是我的模型比别人好。
所以,必须维持技术领先,封锁核心技术。
于是,我们可以看到这样的画面:
你今天发布新模型,我两小时后就上线新功能,主打一个“截胡”。
OpenAI敢说全球领先,Gemini就说,家族能覆盖全生态全路径。
Anthropic刚说自己年入300亿,OpenAI首席营收官就立马发内部信,说他收入注水严重,吹了最少80亿。

来而不往非礼也,在“超级碗”这个美国春晚的舞台上,Anthropic也是不惜重金,买个广告位,广告词是,“广告正在进入AI领域,但不会进入Claude”。
简直是公开内涵刚刚测试广告业务的OpenAI。
这哪是科技竞争?分明是大型修罗场。
大家就在内耗的泥潭里,一边烧着投资人的钱,一边互相揣几脚。
2、
但是当视野回到国内,我看到了一个非常反常的画面。
如果你仔细看DeepSeek-V4的技术报告,会发现他们这次采用了一个叫Muon的优化器来训练模型。
Muon这东西,最早是一个叫Keller Jordan的独立研究者提出来的。但是,把这个理论上的“实验室产品”真正拿到万亿参数规模上跑通,并且做出关键改进(MuonClip)的,是Kimi。
他们验证了这玩意儿在超大规模预训练中能做到“全程零Loss Spike”——翻译一下,就是训练过程稳如老狗,不会突然崩盘。
DeepSeek一看,哥们儿,你这优化器挺稳啊,行,我也整一个。
Kimi这边也是一样。
在Kimi K2的技术报告里,直接表示采用了DeepSeek的MLA架构。
这玩意儿相当于汽车界的涡轮增压。它最牛逼的地方在于,能把KV Cache的压缩率做到93%以上。
听不懂没关系,你只需要知道,随着AI对话越来越长,内存开销会呈指数级爆炸。
Kimi 一看,这玩意儿真香,直接用在了自己的万亿模型里。
你用我的架构省显存,我用你的优化器搞训练。
没有授权谈判,没有专利官司,没有律师函警告。
我都怀疑这俩公司私底下是不是串通好了。
他们不在乎谁是“第一发明人”,在乎的是“谁能把这玩意儿落地”。
可能也正是这种协同进化,让中国AI在极短的时间内,完成了一次又一次的迭代。
3、
说到底,中美两边的不同景象,主要是开源和闭源路线,以及资源差异带来的。
美国那边呢,OpenAI和Anthropic都是闭源,并且可以说拿着全球最顶级的资源在训练模型。
他们更关注的就是市场占有率和行业的定义权。
但是中国这边,客观来讲距离头部AI还有差距,这很大程度上是由芯片被卡、算力和资金不足带来的。
所以,Deepseek 和 Kimi 现在都在走开源路线,这是为了从性价比的路线包抄闭源模型,不卷用户量、先做大生态,让更多开发者、企业能够先应用起来。
而且如果你仔细看这两家公司这一路的发展,就会发现,中国AI并不是在跟随美国的策略,其实已经进入到“平行探索”的阶段。
比如,DeepSeek引领了“思维链”(CoT),让AI学会了像人一样思考、打草稿。Kimi则在“智能体”(Agent)上走得更远。
这就是良性竞争。
我不是抄你的,但我会参考你的。你走这条路,我走那条路,最后大家在山顶汇合,顺便把路上的坑都给填平了。
此外,这两家公司也有不同的坚持。
DeepSeek走的是“单点极致”路线:聚焦基础模型的核心能力,模型能力要强,价格要低,规模化要快,用极致的性价比横扫市场。
而Kimi走的是“落地为王”路线:解决Agentic模型进入真实工作场景的痛点,提高AI的自主工作能力和时长。
这种差异化,让中国的开源AI生态变得丰富起来。
4、
这场AI大仗,拼到最后其实就两样东西:算力和效率。
在算力封锁的大背景下,中国AI公司和中国芯片公司,正在完成一次隐秘的会师。
DeepSeek-V4已经公开表示,他们用了华为芯片做推理。
Kimi的新论文《Prefill-as-a-Service》也在证明国产芯片可以和国外芯片一起用于推理。
以前,模型公司觉得国产芯片不好用,芯片公司觉得模型公司不给反馈。
现在,DeepSeek和Kimi成了中间的那个连接点。

他们在最极端的条件下,倒逼国产芯片去适配最先进的算法。
这种“软硬结合”的阵痛期一旦过去,中国AI的底层底座,将会变得前所未有的稳固。
2025年,DeepSeek R1让我们拿到了牌桌的入场券。
2026年,这群中国卷王正在用开源和协同,努力定义牌桌的规则。
也许有人依然认为国产模型是落后的,这点即便是Deepseek,也不能否认。
但就像原子弹一样,最重要的是,我们先拥有。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)