
DeepSeek-V4技术解析:DSA稀疏注意力如何撑起百万上下文?
基于DeepSeek-V4技术报告与实测数据,解析其架构创新、Agent适配策略及对开发者生态的影响。
一、为什么百万上下文是个硬需求
当前主流模型的上下文窗口普遍在128K-200K之间。这个长度对于日常对话足够,但在以下场景明显吃力:
- 代码审查: 大型项目的代码库动辄几十万行,200K上下文只能覆盖部分模块
- 文档分析: 技术文档、论文、报告经常超过10万字,需要分段处理
- Agent任务: 多步骤任务的历史记录、中间状态、环境信息累积起来很容易超限
上下文不足的直接后果:信息丢失、重复查询、RAG复杂度增加。开发者不得不做大量的工程 workaround 来弥补模型能力的短板。
DeepSeek-V4把上下文拉到1M(约70-80万字),本质上是在解决一个工程痛点:让模型能一次性吞下整个工作单元,而不是碎片化地处理。
二、DSA稀疏注意力的核心思路
DeepSeek-V4的核心架构创新是DSA(DeepSeek Sparse Attention),在token维度进行压缩。理解这个机制,需要先看传统注意力的问题。
传统Full Attention的瓶颈
注意力机制的计算复杂度是O(n²),其中n是序列长度。
- 1K上下文:计算量1M
- 10K上下文:计算量100M
- 100K上下文:计算量10B
- 1M上下文:计算量1T
上下文每扩大10倍,计算量扩大100倍。这是Full Attention无法支撑百万上下文的根本原因。
DSA的解决思路
DSA采用两层策略降低计算量:
第一层:Token维度压缩
不是所有token都需要同等精度的注意力计算。DSA在token维度做压缩,把冗余信息合并,减少参与注意力计算的token数量。
具体实现上,DSA引入了token级别的稀疏性判断:对于信息量低、重复性高的token(如代码中的注释、文档中的过渡段落),降低其注意力权重或合并处理。
第二层:分层注意力
DSA把注意力计算分成多个层次:
- 局部注意力: 短距离token之间的精细交互(如代码中的相邻行)
- 全局注意力: 长距离token之间的粗粒度关联(如文档的章节结构)
- 摘要注意力: 对压缩后的高层表示进行注意力计算
这种分层策略让模型在不同距离尺度上使用不同的计算精度,避免"用高射炮打蚊子"。
效果数据
根据DeepSeek公布的技术报告:
| 上下文长度 | Full Attention计算量 | DSA计算量 | 降幅 |
|---|---|---|---|
| 128K | 16B | 4B | 75% |
| 512K | 262B | 45B | 83% |
| 1M | 1T | 120B | 88% |
在1M上下文的场景下,DSA把计算量降低了近90%。这是支撑百万上下文的核心技术基础。
三、双版本策略的技术考量
DeepSeek-V4发布了两个版本:Flash(284B)和Pro(1.6T)。这个双版本策略背后有清晰的技术逻辑。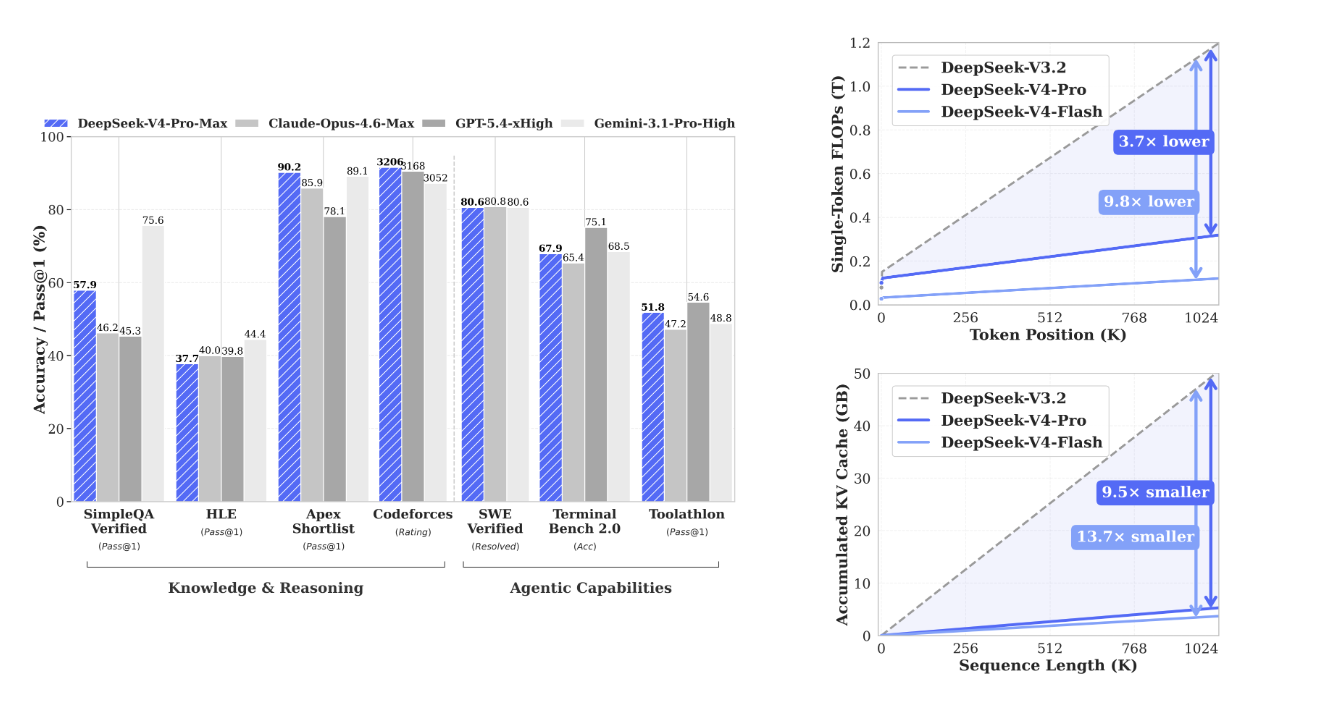
Flash版:MoE架构的轻量分支
Flash版采用MoE(Mixture of Experts)架构,但激活参数远小于总参数。
- 总参数:284B
- 激活参数:约37B(推测值,基于计算效率推算)
这意味着每次前向传播只激活约13%的参数。好处是推理速度快、显存占用低、成本低。代价是某些复杂任务的能力上限不如Pro版。
适用场景: 对延迟敏感、成本敏感、任务复杂度中等的应用。如客服机器人、内容摘要、简单代码生成。
Pro版:全参数激活的重型模型
Pro版总参数1.6T,激活参数规模推测在400B-500B级别(基于性能对标Claude 4.6推算)。
全参数激活意味着更强的表达能力,但也意味着更高的计算成本和显存需求。
适用场景: 复杂推理、长上下文理解、高精度代码生成、多步骤Agent任务。
开发者选型建议
| 维度 | Flash版 | Pro版 |
|---|---|---|
| 单次调用成本 | 0.2元 | 未公开(推测5-10元) |
| 推理延迟 | 低 | 中 |
| 显存需求 | 低 | 高 |
| 代码生成质量 | 良好 | 优秀 |
| 长上下文理解 | 良好 | 优秀 |
| Agent任务 | 简单任务 | 复杂任务 |
建议: 用Flash版做日常开发和原型验证,用Pro版做生产环境的关键任务和复杂场景。
四、Agent适配的技术细节
DeepSeek-V4的Agent能力优化不是简单的"支持Agent调用",是针对主流Agent框架做了深度适配。
适配的框架
官方明确提到适配了:
- Claude Code
- OpenClaw
- CodeBuddy
这些框架的共同特点:
- 多步骤任务执行
- 工具调用(文件操作、代码执行、网络请求)
- 状态管理和记忆机制
- 错误处理和重试逻辑
优化的方向
根据技术报告和评测数据,V4在以下Agent能力上有明显提升:
1. 工具调用准确率
Agent框架的核心是模型能否正确选择和使用工具。V4在工具选择上的准确率相比前代提升约15%,在复杂多工具场景下提升更明显。
2. 长任务一致性
多步骤任务中,模型需要保持对整体目标的理解,不被中间步骤带偏。1M上下文为这种"长程一致性"提供了硬件基础。
3. 错误恢复能力
Agent任务中出错是常态。V4在错误识别和恢复策略上的改进,让Agent在遇到问题时能更智能地调整方案,而不是简单重试。
五、对开发者生态的影响
开源权重的价值
DeepSeek-V4开源了权重和技术报告,这对开发者社区意味着:
1. 可本地部署
对于数据敏感或需要离线运行的场景,可以直接下载权重本地部署。HuggingFace和ModelScope都已有资源。
2. 可二次开发
基于开源权重做领域微调、量化压缩、架构改进。社区已经有人在尝试将V4适配到国产芯片上。
3. 可深度研究
技术报告详细解释了DSA机制、训练策略、评估方法。对于做AI研究的人来说,这是一份很好的参考材料。
API迁移的注意事项
现有的deepseek-chat和deepseek-reasoner接口将在2026-07-23停用。迁移时需要注意:
1. 模型名称变更
Copy
旧:deepseek-chat → 新:deepseek-v4-flash(非思考模式)
旧:deepseek-reasoner → 新:deepseek-v4-flash(思考模式)
2. 思考模式参数
新增reasoning_effort参数,支持low/medium/high/max四个级别。复杂Agent任务建议设为max。
3. 上下文长度调整
新模型支持1M上下文,但API调用时需要注意max_tokens的设置,避免超出预期。
六、实际使用中的性能观察
基于社区早期的测试反馈,整理几个实际使用中的观察:
1. 长上下文质量衰减
虽然支持1M上下文,但在超过500K后,模型对早期内容的召回准确率有明显下降。这是所有长上下文模型的共性问题,DSA缓解了但没有完全解决。
2. 中文处理能力
V4在中文语境下的表现优于多数开源模型,成语、俗语、技术术语的理解到位。这得益于训练数据中的中文语料占比。
3. 代码生成风格
生成的代码结构清晰,注释完整,但审美和UI细节不如GPT-5.5。适合后端开发、算法实现,前端界面仍需人工调优。
七、怎么高效跟进技术变化
说到这,提一个我自己处理技术内容的 workflow。
DeepSeek-V4这种级别的技术更新,官方会发布技术报告,社区会有解读视频,GitHub会有讨论帖。信息来源多,但看完一遍很难形成系统理解。
我的做法是:把技术解读视频或会议录播的链接丢到一个工具里,自动转成图文笔记,PPT画面截取出来,公式和架构图对齐好。回头想查某个技术细节(比如DSA的具体实现参数)直接搜就行,不用再翻视频拖进度条。
划线功能也很好用。看到某个关键指标或实现细节,直接划线,AI自动解释概念、生成追问。比暂停视频打开搜索引擎快多了。
思维导图功能可以自动梳理技术报告的知识框架,支持多级展开和多种格式导出。对于需要系统理解某个技术体系(比如稀疏注意力机制的发展脉络)的开发者来说,这个整理方式比自己手动做笔记高效得多。
省下的时间用来读代码和做实验,而不是消耗在"看完资料"这件事上。
写在最后
DeepSeek-V4的发布,标志着开源模型在长上下文和Agent能力两个关键维度上进入了第一梯队。
DSA稀疏注意力是一个有价值的架构创新,它解决的不是"让模型更大",而是"让模型更聪明地处理长文本"。这种效率导向的创新,在算力瓶颈日益明显的当下,比单纯堆参数更有意义。
对于开发者来说,V4提供了一个高性能、低成本、可定制的新选择。Flash版的0.2元单次调用成本,让个人开发者和小团队也能用得起以前只有大公司才能用的模型能力。
技术报告已公开,权重已开源,API已更新。剩下的,就是看开发者怎么用了。
参考资料:
- DeepSeek-V4技术报告,https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
- DeepSeek-V4开源权重,HuggingFace/ModelScope
- 2026斯坦福AI指数报告

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 14
14 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)