
手把手教你:Windows+Docker 部署 Ollama + Qwen2:7B 纯 CPU 实战
一、准备工作
已经安装 Docker或Docker Desktop。
二、部署Ollama
(一)拉取Ollama镜像
拉取LTS 稳定版,打开Power Shell或CMD窗口,执行以下命令:
docker pull ollama/ollama:latest查看是否拉取Ollama镜像成功:
docker images列表里出现 ollama/ollama:latest 就是拉取成功。
(二)启动容器测试(CPU 模式)
打开Power Shell或CMD窗口,执行以下命令:
docker run -d --name my-ollama -p 11434:11434 -v D:\Docker\docker_volumes\ollama_data:/root/.ollama ollama/ollama参数说明:
-d:后台运行;
--name:给容器名字;
-p:端口映射(默认 11434);
-v:数据卷持久化(模型 / 配置不会随容器删除丢失)。
(三)查看容器状态
打开Power Shell或CMD窗口,执行以下命令:
docker ps能看到 my-ollama running 就就代表镜像完全可用。
三、访问测试
访问 API 端口,打开Power Shell或CMD窗口,执行以下命令:
curl http://localhost:11434返回 Ollama is running 即成功。现在你的电脑就有了一个本地大模型服务。
也可以在浏览器访问http://localhost:11434

页面返回Ollama is running即表示成功。
四、容器内部署模型
(一)进入ollama容器内部
打开Power Shell或CMD窗口,执行以下命令:
docker exec -it my-ollama bash(二)拉取模型
执行以下命令(qwen2:7b轻量适合本地运行):
ollama pull qwen2:7b模型下载时间跟网速有关。
(三)运行模型
执行以下命令,运行模型:
ollama run qwen2:7b出现 >>> 输入提示符,代表CPU 运行大模型成功!可以直接输入问题对话,例如:
你好,你是怎么出生的?现在你已经有可以调用的模型了。
五、外部调用 Ollama API
Ollama 启动后默认提供 REST API,你的应用可以直接调用。
(一)测试 API 连通性
打开PowerShell或CMD窗口, 执行命令:
curl http://localhost:11434返回 Ollama is running 就代表Ollama启动成功。
验证模型是否启动,执行命令:
curl http://localhost:11434/api/generate -X POST -H "Content-Type: application/json" -d "{\"model\":\"qwen2:7b\",\"prompt\":\"你好\",\"stream\":false}"要返回下边这段话,就代表部署成功、模型运行正常:
{
"model": "qwen2:7b",
"response": "", // 有这行就稳了!
"done": true
}(二)Python 调用 Ollama API
import requests
# 本地 Docker Ollama 服务地址(固定不变)
OLLAMA_API = "http://localhost:11434/api/generate"
# 你要使用的模型(必须和 docker 里运行的一致)
MODEL_NAME = "qwen2:7b"
def ask_ollama(prompt):
data = {
"model": MODEL_NAME, # 你启动的模型名
"prompt": prompt, # 你的问题
"stream": False # 一次性返回结果
}
try:
# 发送请求
response = requests.post(OLLAMA_API, json=data)
return response.json()["response"].strip()
except Exception as e:
return f"调用失败:{e}"
if __name__ == "__main__":
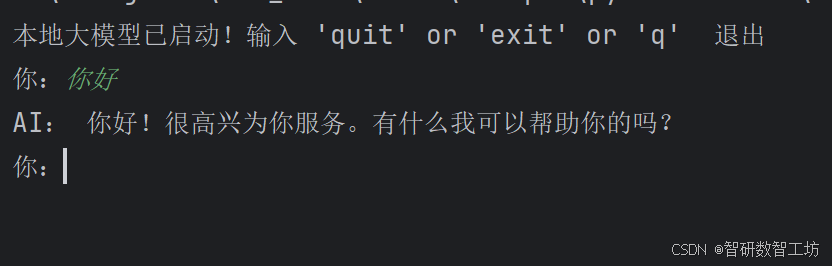
print("本地大模型已启动!输入 'quit' or 'exit' or 'q' 退出")
while True:
user_input = input("你:")
if user_input.lower() in ["quit", "exit", "q"]:
break
answer = ask_ollama(user_input)
print("AI:", answer)
执行以上代码,控制台输出:

输出“你好”,返回内容,代表接口连接成功。
六、Ollama常用接口
# 多轮对话接口(带上下文记忆)
curl http://localhost:11434/api/chat
# 单次文本补全接口(无内置上下文)
curl http://localhost:11434/api/generate应用场景:
用 /api/chat:聊天机器人、智能客服、多轮问答、带记忆的助手。
用 /api/generate:写代码、写文案、摘要、翻译、一次性文本生成。
七、常用管理命令
# 停止 Ollama
docker stop my-ollama
# 启动 Ollama
docker start my-ollama
# 重启 Ollama
docker restart my-ollama
# 查看已安装模型
docker exec -it my-ollama ollama list
# 安装模型
docker exec -it my-ollama ollama pull qwen2:7b
# 启动已安装模型(会自动下载 → 加载 → 进入聊天界面)
docker exec -it my-ollama ollama run qwen2:7b
# 停止正在运行模型
docker exec -it my-ollama ollama stop qwen2:7b
# 查看正则运行模型
docker exec -it my-ollama ollama ps
# 启动已安装模型(只启动模型,不进入聊天界面)
docker exec -it my-ollama ollama stop qwen2:7b
# 删除模型
docker exec -it my-ollama ollama rm qwen2:7b
汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)