
Codex、Claude Code、Gemini CLI 怎么选?新手先按编程任务分级,而不是看排行榜
OpenAI 最近把 Codex 放到“every role, tool, and workflow”的语境里,说明 AI 编程工具正在发生一个明显变化:它们不再只是帮开发者补全几行代码,而是在尝试进入更完整的工作流。OpenAI 官方内容里也提到,Codex 正在通过角色、插件、工具连接和工作流能力,覆盖更多任务场景。这对新手开发者来说,既是机会,也是风险。机会在于:很多重复性开发任务,确实可以
OpenAI 最近把 Codex 放到“every role, tool, and workflow”的语境里,说明 AI 编程工具正在发生一个明显变化:它们不再只是帮开发者补全几行代码,而是在尝试进入更完整的工作流。OpenAI 官方内容里也提到,Codex 正在通过角色、插件、工具连接和工作流能力,覆盖更多任务场景。
这对新手开发者来说,既是机会,也是风险。
机会在于:很多重复性开发任务,确实可以被 AI 加速。
风险在于:AI 编程工具越像 Agent,新手越容易把它当成“自动写完整项目”的按钮。
这篇文章不做排行榜。
不讨论 Codex、Claude Code、Gemini CLI 到底谁第一。
因为对新手来说,更重要的问题不是“哪个最强”,而是:
我的任务到底适合哪类 AI 编程工具?哪些任务可以交给它,哪些必须自己把关?
如果这个问题没想清楚,越强的 AI 工具,越容易帮你制造更隐蔽的技术债。
一、为什么不能只看 AI 编程工具排行榜?
现在 AI 编程工具很多。
Codex、Claude Code、Gemini CLI、Cursor、Copilot、Cline 等,都有不同用户群体。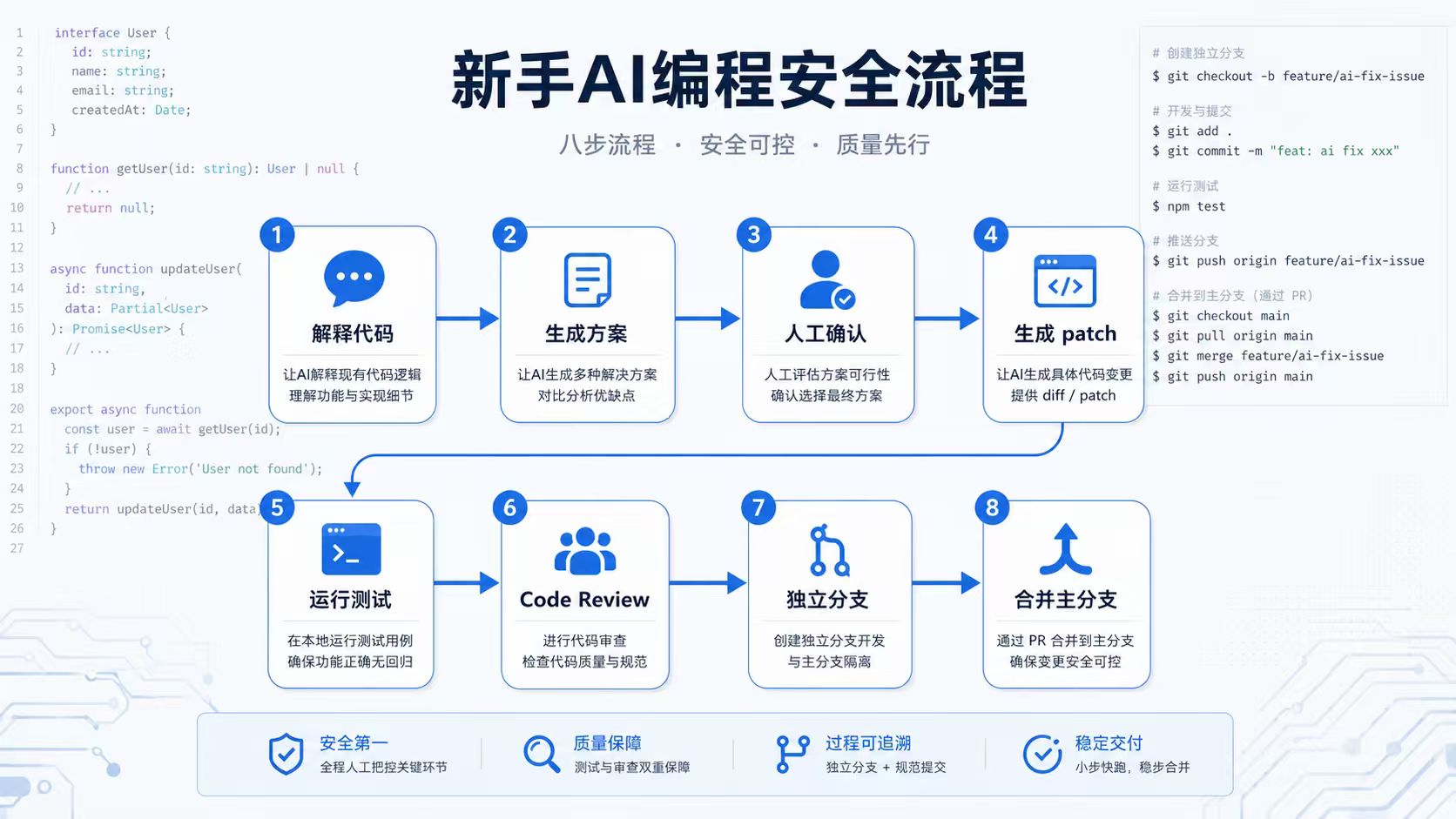
很多新手喜欢先看测评:
- 谁生成代码更快;
- 谁能读懂大项目;
- 谁 CLI 体验更好;
- 谁能自动改 Bug;
- 谁能跑测试;
- 谁能处理多文件改动。
这些测评当然有参考价值。
但对新手来说,排行榜只能回答“工具能力上限”,不能回答“你的任务适不适合”。
比如: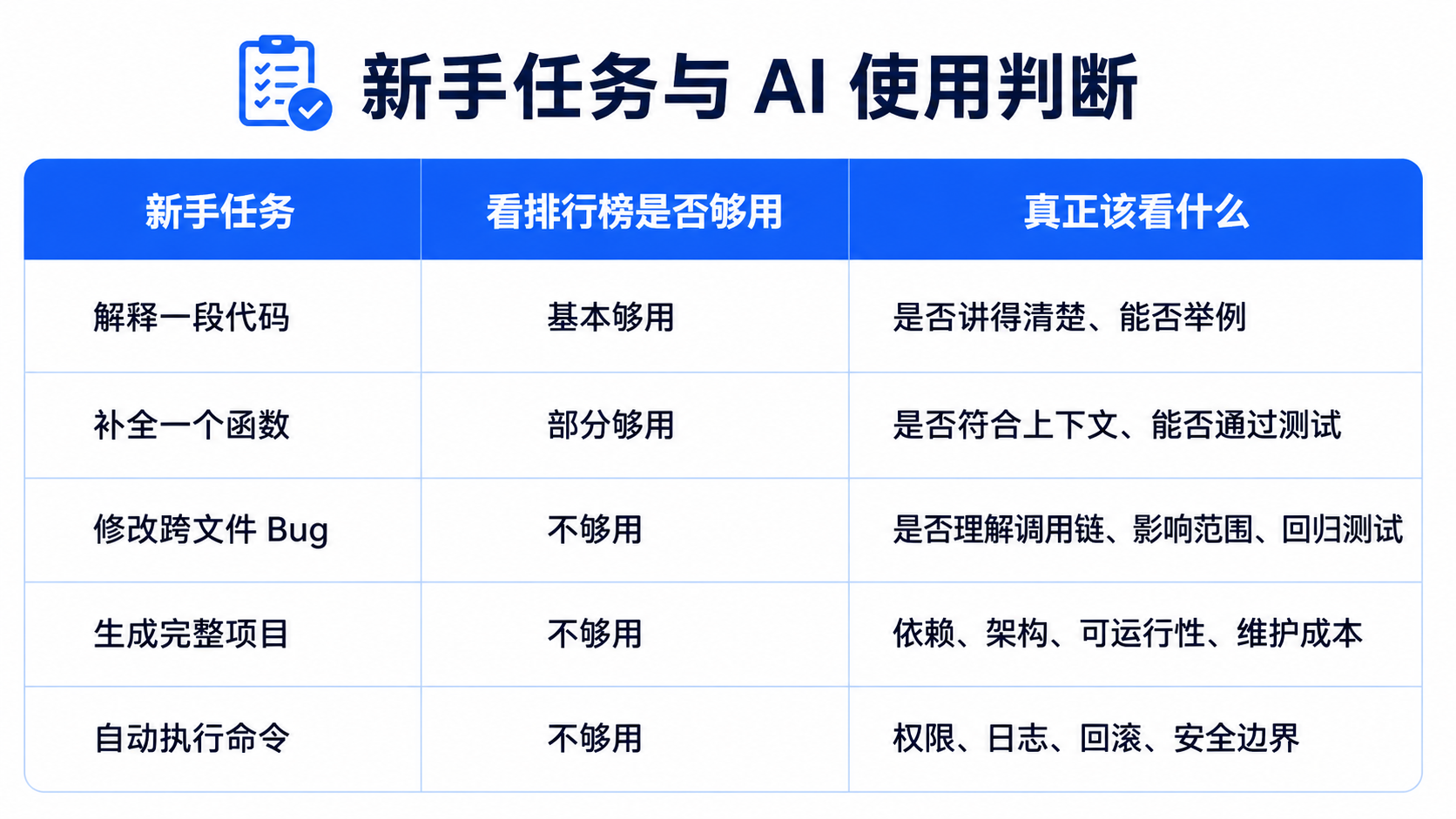
AI 编程工具真正的难点,不在单次回答,而在工程上下文。
这说明 AI 编程工具进入真实开发流程后,问题往往不是“模型不会写代码”,而是:
- 环境不一致;
- 依赖没装全;
- 配置不匹配;
- 命令执行失败;
- 工具调用链出错;
- 生成内容无法在本地复现。
所以新手选工具,不能只看 demo。
必须先看自己的任务风险。
二、先把编程任务分成 4 个等级
对新手开发者来说,可以先把任务分成 4 个等级。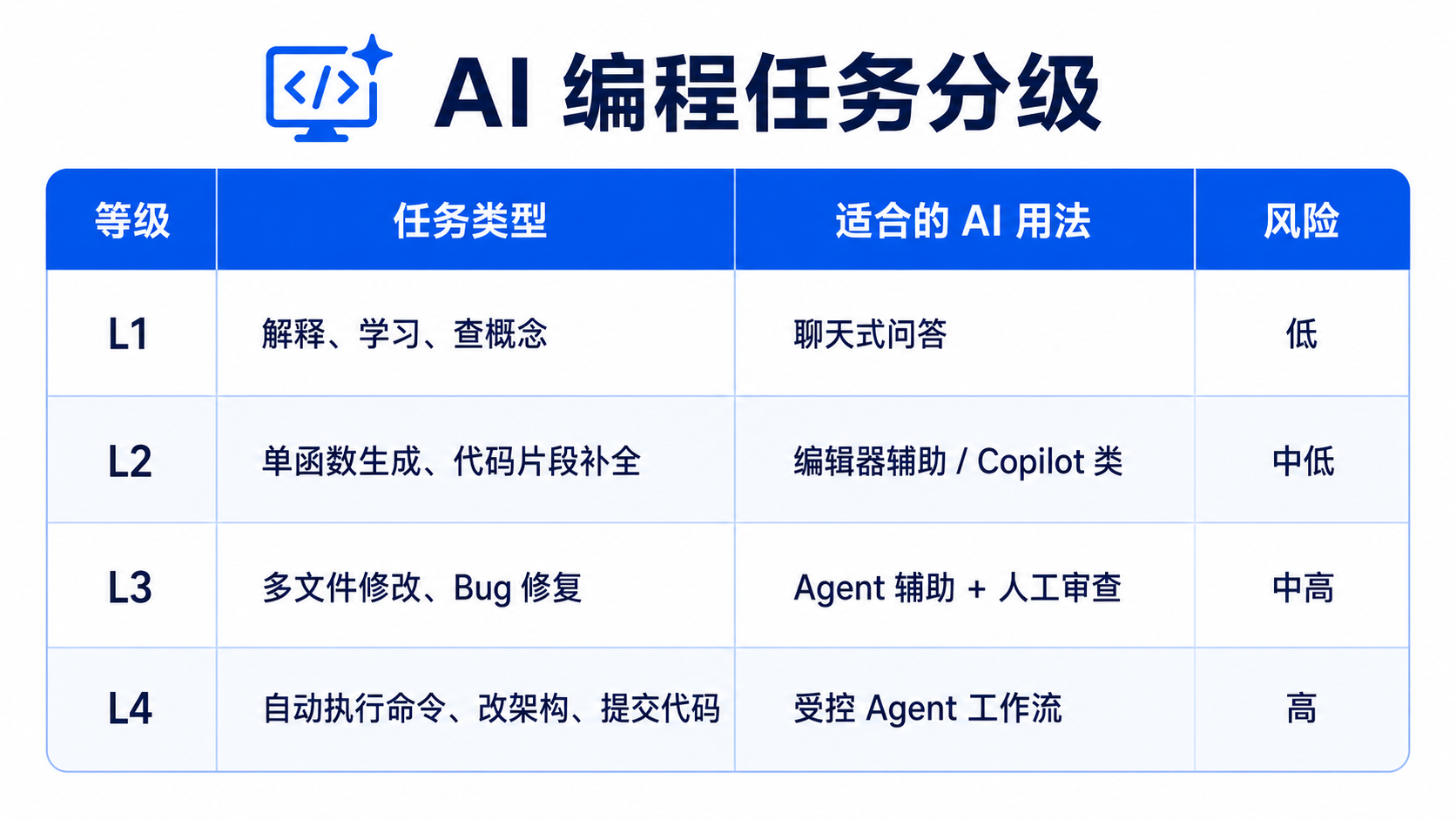
这张表比工具排行榜更重要。
因为不同等级对应的工具选择完全不同。
L1 不需要复杂工具。
你只是想理解闭包、Promise、递归、SQL Join,用普通聊天式 AI 就够了。
L2 可以用编辑器补全。
比如写一个格式转换函数、生成一个接口类型、补充测试样例,这类任务适合 AI 做局部辅助。
L3 才开始需要 Codex、Claude Code、Gemini CLI 这类 Agent。
因为它可能要读多个文件、理解上下文、修改调用链、运行测试。
L4 最危险。
涉及自动执行命令、批量改文件、改依赖、改架构、提交代码、部署脚本,这时不能让 AI 自由发挥,必须加权限、日志和回滚。
三、输入示例:新手如何描述一个适合 AI 辅助的 Bug?
很多新手用 AI 修 Bug 时,Prompt 写得太随意。
错误示例:
这个接口报错了,帮我修一下。
这类输入缺少上下文,AI 只能猜。
更适合的输入应该包括:
项目背景:
这是一个 Node.js + Express 的接口服务。
问题现象:
GET /api/orders/:id 在部分订单不存在时返回 500。
期望行为:
当订单不存在时,返回 404,并输出 JSON:
{
"error": "ORDER_NOT_FOUND"
}
相关代码:
- routes/order.ts
- services/orderService.ts
限制:
1. 不要改数据库结构。
2. 不要改其他接口返回格式。
3. 只给出修改建议和补丁,不要直接假设全部项目结构。
4. 需要补充一个最小测试用例。
这个输入比“帮我修一下”强很多,因为它说明了:
- 技术栈;
- 问题现象;
- 期望输出;
- 相关文件;
- 修改限制;
- 测试要求。
AI 编程工具不是不能帮你修 Bug,而是你要给它足够明确的边界。
四、输出示例:不要只要代码,要让 AI 说明影响范围
如果你让 AI 只输出代码,风险很大。
更好的方式是要求它输出结构化结果。
比如:
{
"diagnosis": "订单不存在时 service 抛出异常,路由层未区分业务错误和系统错误",
"files_to_change": [
"services/orderService.ts",
"routes/order.ts",
"tests/order.test.ts"
],
"patch_summary": [
"在 orderService 中返回 null 或抛出业务错误",
"在 route handler 中将 ORDER_NOT_FOUND 映射为 404",
"增加订单不存在场景的测试"
],
"risk_level": "medium",
"needs_human_review": true
}
这里的重点是:
你不是只让 AI 写代码,而是让它先说明判断过程、修改文件和风险等级。
这一步对新手尤其重要。
因为新手最容易只看“代码能不能跑”,忽略“改动影响了哪里”。
五、一个适合新手的 Prompt 模板
下面是一个新手可以直接改的 AI 编程辅助 Prompt:
你是一个谨慎的代码审查和修复助手。
任务:
基于我提供的问题描述和代码片段,分析可能原因,并给出最小修改方案。
要求:
1. 不要假设我没有提供的项目结构。
2. 不要大范围重构。
3. 优先给出最小可验证修改。
4. 必须说明影响范围。
5. 必须列出需要人工确认的点。
6. 如果信息不足,请先提出需要补充的上下文。
7. 不要直接建议自动提交或自动部署。
输出格式:
{
"problem_summary": "问题概述",
"likely_cause": "可能原因",
"minimal_fix": [
"修改点 1",
"修改点 2"
],
"files_affected": [
"文件路径"
],
"test_suggestion": [
"测试建议"
],
"risk_level": "low | medium | high",
"human_checklist": [
"人工确认项"
]
}
这个模板适合 L2 到 L3 之间的任务。
如果任务已经进入 L4,比如自动改依赖、批量执行命令、修改数据库迁移脚本,就不能只靠 Prompt,还要加权限控制。
六、用配置文件约束 Agent 行为
当你开始使用 Codex、Claude Code、Gemini CLI 这类工具时,一个重要变化是:你不只是和模型聊天,而是在配置一个“会执行任务的助手”。
新手可以先从一个简单的 AGENTS.md 开始。
AGENTS.md 示例
# Project AI Agent Rules
## Project
This is a TypeScript + Express API service.
## Allowed tasks
- Explain code
- Generate tests
- Suggest minimal patches
- Refactor small functions with human approval
## Not allowed
- Do not change database migration files without explicit approval
- Do not modify package.json dependencies without asking
- Do not run destructive shell commands
- Do not commit code automatically
- Do not deploy
## Output format
Before editing, always provide:
1. Problem summary
2. Files likely affected
3. Risk level
4. Test plan
5. Human approval question
## Review policy
All changes must be reviewed by a human before merge.
这份文件的价值在于:
它让 AI 工具有一个项目级边界,而不是每次都从零解释。
对于新手来说,先写规则,比直接让 Agent 进仓库更安全。
七、一个简单的任务选择函数
如果你想把这个判断写成工具,可以先做一个简单的任务分级函数。
def classify_ai_coding_task(task):
risk_score = 0
if task.get("multi_file_change"):
risk_score += 2
if task.get("runs_shell_commands"):
risk_score += 3
if task.get("changes_dependencies"):
risk_score += 3
if task.get("touches_database"):
risk_score += 4
if task.get("requires_business_decision"):
risk_score += 2
if task.get("has_tests"):
risk_score -= 1
if risk_score <= 1:
return "L1: 适合聊天式辅助"
elif risk_score <= 3:
return "L2: 适合编辑器辅助或局部生成"
elif risk_score <= 6:
return "L3: 适合 Agent 辅助,但必须人工审查"
else:
return "L4: 高风险任务,不建议直接交给 Agent"
task = {
"multi_file_change": True,
"runs_shell_commands": False,
"changes_dependencies": False,
"touches_database": False,
"requires_business_decision": False,
"has_tests": True
}
print(classify_ai_coding_task(task))
输出示例:
L2: 适合编辑器辅助或局部生成
这个函数很粗糙,但它表达了一个核心思想:
先判断任务风险,再选择 AI 工具。
八、不同工具更适合什么场景?
这部分不做绝对排名,只按编程场景常用方式来分。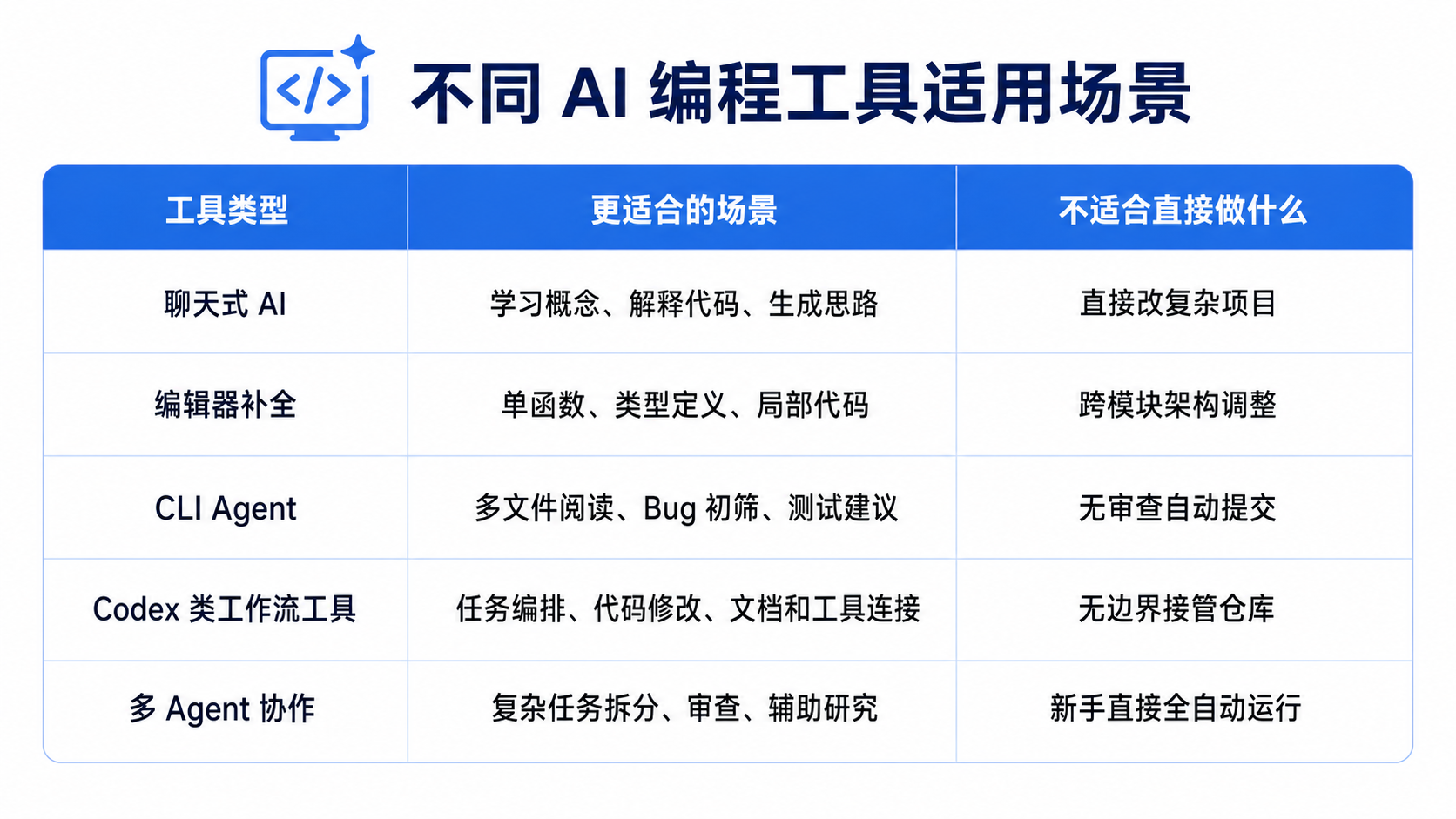
新手最稳的路线通常是:
聊天式理解 → 编辑器局部辅助 → 小范围 Agent 测试 → 受控工作流
不要一上来就让 Agent 读完整仓库、自动改文件、自动跑命令、自动提交。
九、哪些任务适合新手先用 AI 编程工具?
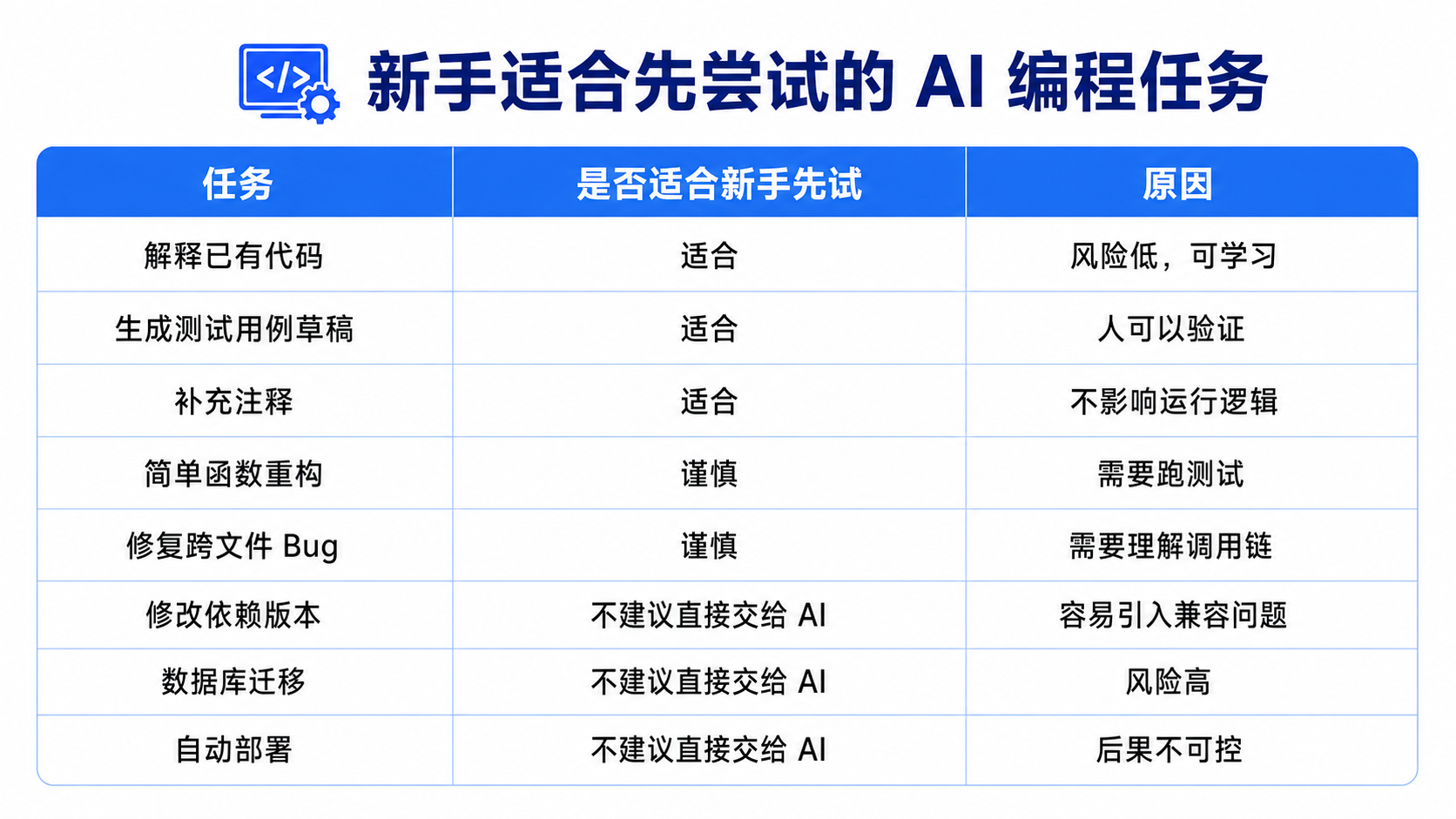
如果你是新手,最推荐先从“解释代码 + 生成测试 + 小范围修改建议”开始。
十、工程边界:AI 编程工具不能替你承担这些责任
AI 可以帮你写代码,但不能替你负责:
- 业务逻辑是否正确;
- 边界条件是否覆盖;
- 安全风险是否排查;
- 依赖是否稳定;
- 数据库迁移是否安全;
- 性能是否满足要求;
- 代码是否符合团队规范;
- 是否能通过 CI/CD;
- 上线后是否可回滚。
所以,不要只问 AI:
代码写好了吗?
而要问:
测试怎么跑?
依赖是什么?
失败时怎么回滚?
哪些地方需要人工审查?
十一、一个新手使用 AI 编程工具的安全流程
推荐新手按这个流程走:
Step 1:先让 AI 解释代码,不让它修改
Step 2:让 AI 生成修改方案,不直接应用
Step 3:人工确认影响范围
Step 4:小范围生成 patch
Step 5:运行测试
Step 6:人工 code review
Step 7:提交到独立分支
Step 8:再合并主分支
对应 Git 流程可以这样:
git checkout -b ai-fix/order-not-found
# 让 AI 给出最小 patch
npm test
git diff
git add .
git commit -m "fix: handle order not found"
# 提交 PR,由人 review
这里最重要的是:
不要让 AI 直接在主分支上操作。
不要跳过测试。
不要跳过 code review。
AI 编程工具越强,越要保持工程习惯。
十二、结论:新手选 AI 编程工具,先选场景,再选工具
Codex、Claude Code、Gemini CLI 这类工具会继续发展。
它们会越来越像能参与工作流的 Agent,也会越来越多地进入开发、办公和知识工作场景。
但对新手来说,最稳的判断不是“哪个工具最强”,而是:
我的任务属于 L1、L2、L3 还是 L4?
我能不能验证输出?
我有没有测试?
它会不会改依赖、改数据库、跑命令?
出错后能不能回滚?

如果你只是学习概念,用聊天式 AI 就够了。
如果你只是写局部代码,用编辑器辅助更合适。
如果你要跨文件修 Bug,可以让 Agent 辅助,但必须人工审查。
如果任务涉及依赖、数据库、部署、权限,就不要直接交给 AI 自动执行。
AI 编程工具不是越强越适合新手。
真正适合新手的,是任务边界清楚、输出可验证、改动可回滚的用法。
如果你正在判断 Codex 是否适合自己的编程场景常用需求,可以把 gpt328.com 当作开通前的选择参考。先分清任务等级、风险边界和使用频率,再决定要不要长期投入,这比看排行榜更靠谱。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)