
ChatGPT 正在变成工作入口,AI 办公提效别再停留在“临时问一句”
## 1. 热点背后:ChatGPT 正在从聊天框变成工作入口
这两天有一条新闻很适合 CSDN 用户关注:Reuters 今日援引 FT 报道称,OpenAI 正准备把 ChatGPT 改造成更像“superapp”的综合入口,并把 Codex、AI agents、图像生成以及外部服务集成放进更统一的产品体验里。
如果只当新闻看,它可能只是“ChatGPT 又升级了”。
但从技术团队视角看,这件事意味着:AI 工具正在从“临时聊天窗口”变成“任务处理入口”。
OpenAI 近期也发布 Codex 知识工作报告,提到 Codex 不再只是编码工具,也在帮助不同职业处理研究、数据分析、工作流自动化等知识工作。
这对办公场景很关键。
过去很多团队做 AI 办公提效,方式很粗糙:
```text
把一段材料复制到 ChatGPT
让它总结
把结果复制回文档
人工再修改
```
这当然有用,但问题也很明显:
- 每个人输入方式不一样;
- 每次输出格式不一样;
- 结果无法稳定入库;
- 好用的 Prompt 没版本管理;
- 人工审核结果没有记录;
- 下次还要重新来一遍。
所以很多团队用了 AI 后,发现效率并没有稳定提高。
不是 AI 没用,而是流程没设计好。
对 CSDN 用户来说,真正值得做的不是收藏更多 Prompt,而是把 AI 办公任务工程化。
---
## 2. 临时聊天式用法 vs 流程化用法
先看一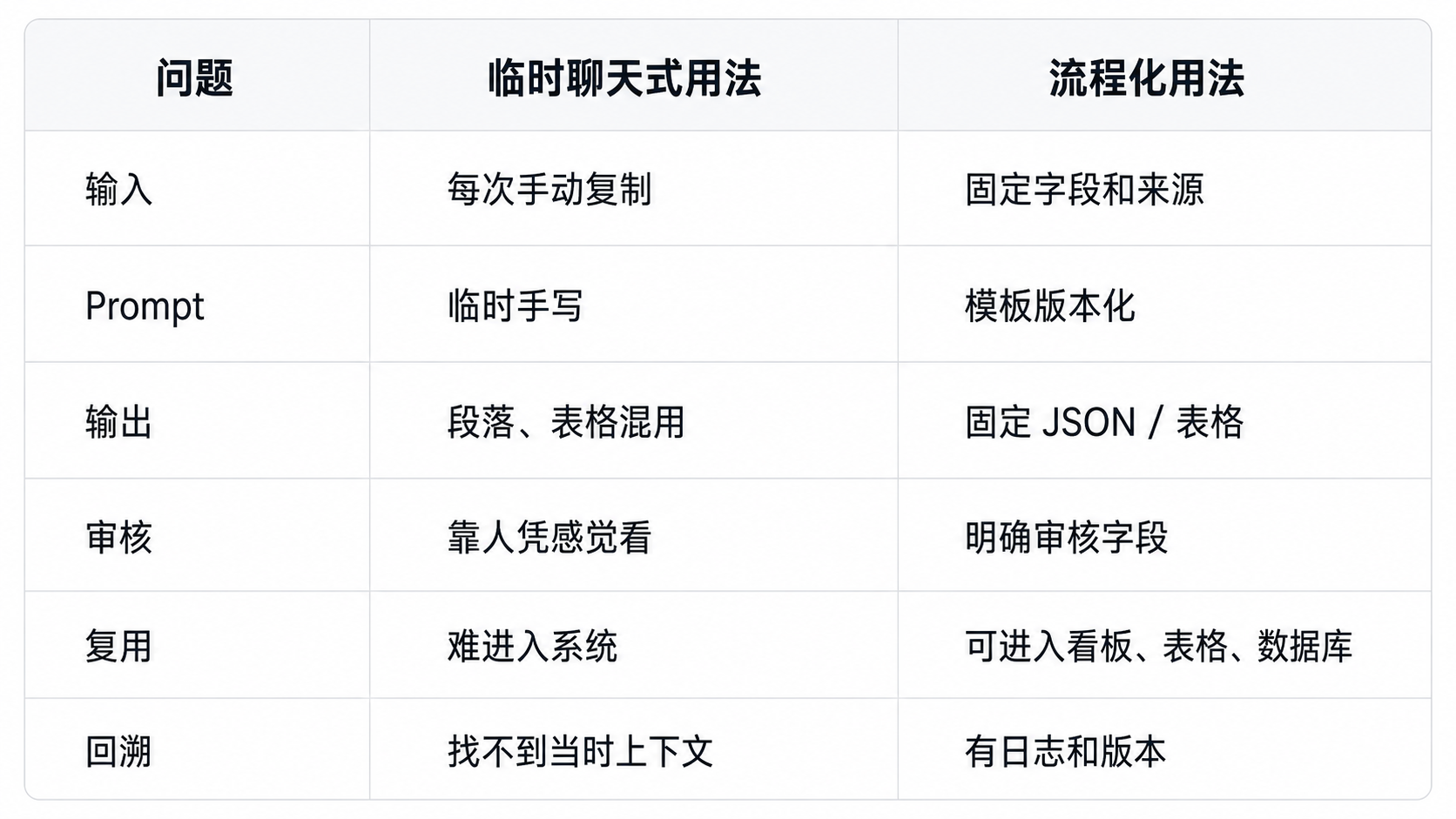 个对比。
个对比。
流程化并不代表复杂。
它的核心只是把 AI 从“随手问一下”,变成任务流里的一个固定节点。
比如一个运营团队每天有 100 条用户反馈。
临时聊天式用法是:
```text
帮我总结一下这些反馈。
```
流程化用法则是:
1. 把反馈按固定字段输入;
2. 用固定 Prompt 归类;
3. 输出固定 JSON;
4. 程序校验字段;
5. 人工确认高风险结果;
6. 写入表格或看板;
7. 每周复盘分类准确率。
这才是可持续的 AI 办公提效。
---
## 3. 适合先流程化的 4 类办公任务
不是所有办公任务都适合一开始接 AI。
建议从高频、重复、可核对、低风险的任务开始。
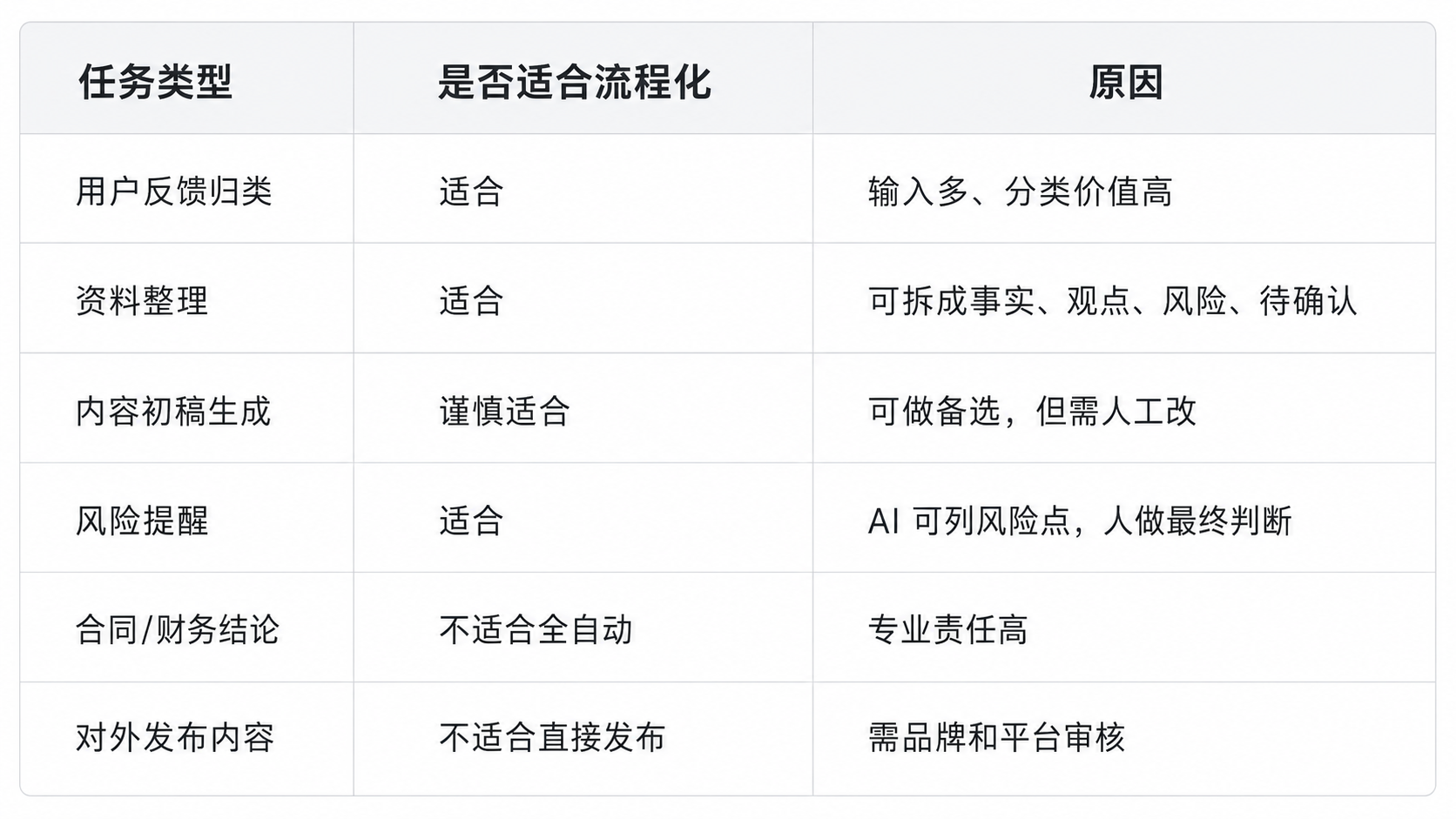
本篇用“运营反馈池”做主案例。
这个场景足够常见,也适合用来演示轻量流程。
---
## 4. 设计输入:不要只丢一段原文
一个可复用的 AI 办公流程,第一步是输入结构化。
假设你要处理用户反馈,不建议只传:
```text
用户说找不到优惠入口,这个商品尺码偏大,物流多久到?
```
更好的输入是:
```json
{
"task_id": "feedback_20260607_001",
"source": "product_page",
"business_line": "ecommerce",
"raw_text": "找不到优惠入口,这个商品尺码偏大,物流多久到?",
"expected_output": "classification_table",
"review_required": true
}
```
字段不一定多,但要稳定。
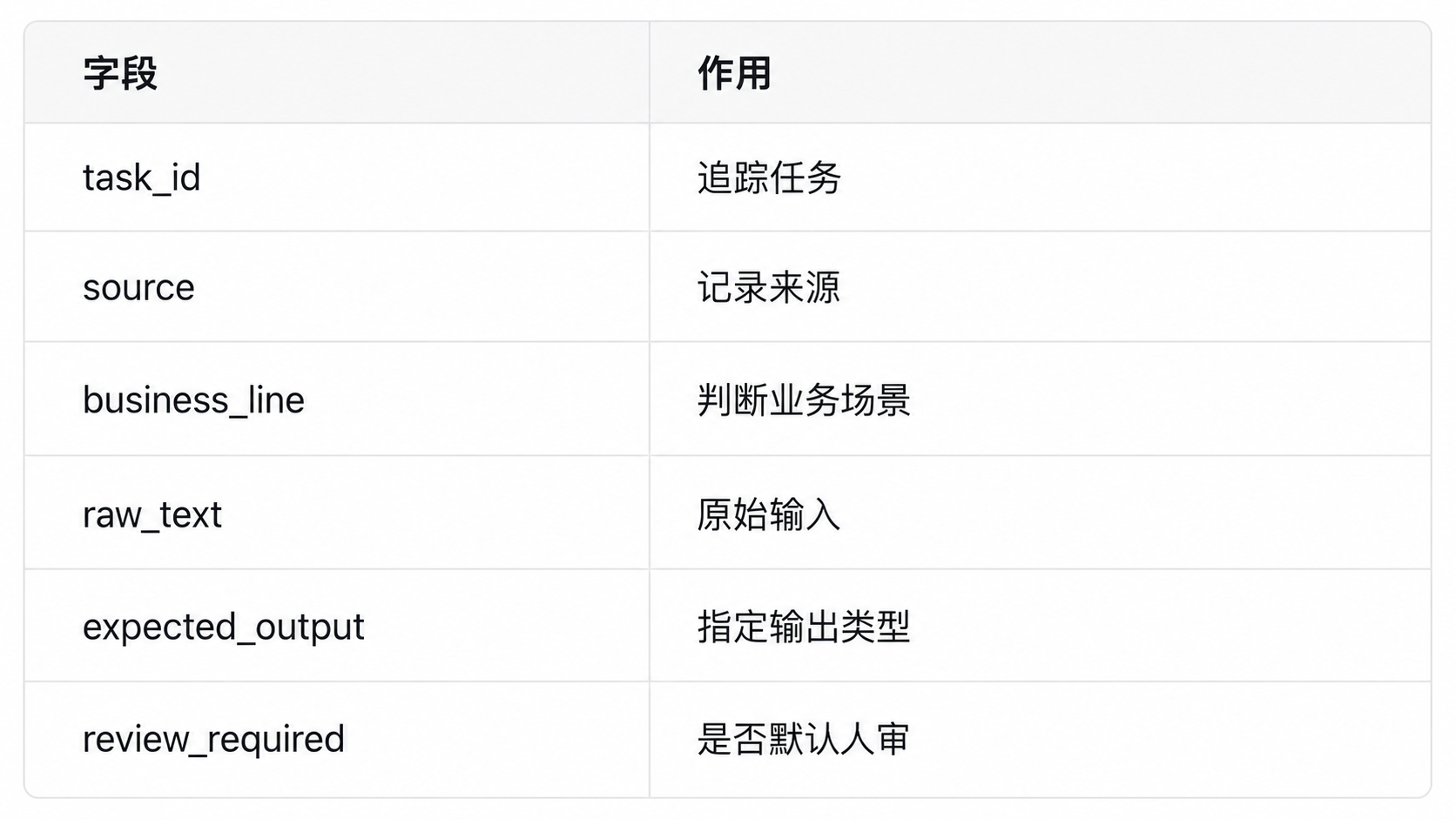
输入结构化后,后面才能做校验、入库和复盘。
---
## 5. Prompt 模板:重点不是写长,而是写边界
一个常见错误是:Prompt 写得很长,但没有边界。
比如:
```text
帮我分析一下这些反馈,整理成对业务有帮助的内容。
```
这句话太宽。
AI 可能给你一段很漂亮的总结,但不一定能进入系统。
更适合流程化的 Prompt 是这样:
```text
你是一个运营反馈初筛助手。
请处理输入 raw_text 中的用户反馈,并输出 JSON 数组。
每个对象包含:
- original_text:原始反馈
- category:页面问题 / 物流问题 / 商品信息 / 售后问题 / 其他
- importance:高 / 中 / 低
- suggested_action:建议动作
- need_human_review:true / false
- reason:分类理由
规则:
1. 不要编造输入中没有的信息。
2. 如果无法判断,category 填“其他”,need_human_review 填 true。
3. 涉及价格、权益、承诺、投诉时,need_human_review 必须为 true。
4. 输出只允许 JSON,不要输出解释文字。
```
这个 Prompt 做了 4 件事:
1. 定义 AI 角色;
2. 限定输出 Schema;
3. 规定无法判断时怎么处理;
4. 明确人工审核条件。
这比临时问答更稳定。
---
## 6. 输出 Schema:让 AI 结果可以进入下一步
理想输出应该长这样:
```json
[
{
"original_text": "找不到优惠入口",
"category": "页面问题",
"importance": "中",
"suggested_action": "优化入口提示",
"need_human_review": true,
"reason": "涉及页面转化路径,需要人工确认入口设计"
},
{
"original_text": "这个商品尺码偏大吗",
"category": "商品信息",
"importance": "中",
"suggested_action": "增加尺码说明",
"need_human_review": true,
"reason": "涉及商品描述准确性,需要人工确认"
},
{
"original_text": "物流多久到",
"category": "物流问题",
"importance": "低",
"suggested_action": "补充发货说明",
"need_human_review": false,
"reason": "常规物流问题,可按规则处理"
}
]
```
有了这种输出,后续可以:
- 写入表格;
- 进入看板;
- 按重要程度排序;
- 将 `need_human_review=true` 的项推给人工;
- 统计一周内最多的问题类型;
- 复盘 AI 分类是否准确。
AI 办公提效不是生成更多文字,而是生成可以进入流程的数据。
---
## 7. 用 Python 做一个轻量校验
下面用 Pydantic 做基础结构校验。
```python
from typing import Literal
from pydantic import BaseModel, ValidationError
class FeedbackResult(BaseModel):
original_text: str
category: Literal["页面问题", "物流问题", "商品信息", "售后问题", "其他"]
importance: Literal["高", "中", "低"]
suggested_action: str
need_human_review: bool
reason: str
def validate_feedback_results(data: list[dict]) -> tuple[list[FeedbackResult], list[str]]:
valid_results = []
errors = []
for index, item in enumerate(data):
try:
valid_results.append(FeedbackResult(**item))
except ValidationError as exc:
errors.append(f"第 {index + 1} 条结构校验失败:{exc}")
return valid_results, errors
sample_output = [
{
"original_text": "找不到优惠入口",
"category": "页面问题",
"importance": "中",
"suggested_action": "优化入口提示",
"need_human_review": True,
"reason": "涉及页面转化路径,需要人工确认入口设计"
}
]
valid, errors = validate_feedback_results(sample_output)
if errors:
print("结构校验失败,需要重新生成或转人工")
print(errors)
else:
print("结构校验通过,可以进入审核队列")
```
这段代码不复杂,但很关键。
它把 AI 输出从“看起来像 JSON”,变成“真的符合系统要求”。
---
## 8. 再加一层业务规则校验
结构校验通过,不代表业务一定安全。
比如“涉及价格、权益、承诺”的内容,即使 JSON 格式正确,也必须人工确认。
可以再加一层业务规则:
```python
RISK_KEYWORDS = ["价格", "优惠", "承诺", "赔偿", "投诉", "合同", "隐私", "账号"]
def apply_business_rules(result: FeedbackResult) -> FeedbackResult:
text = result.original_text + result.suggested_action + result.reason
if any(keyword in text for keyword in RISK_KEYWORDS):
result.need_human_review = True
if result.importance == "高":
result.need_human_review = True
return result
review_queue = [apply_business_rules(item) for item in valid]
for item in review_queue:
print(item.model_dump())
```
这一步解决的是:
AI 可能没有把某些风险标出来,但系统可以通过规则补一刀。
真实业务里,还可以增加:
- 敏感词规则;
- 平台规则;
- 客户隐私规则;
- 高价值用户规则;
- 品牌语气规则。
AI 负责初筛,规则负责兜底,人负责最终判断。
---
## 9. 结果入库:让 AI 输出能沉淀
如果 AI 输出只停留在聊天窗口,就很难复用。
可以设计一个简单表结构:
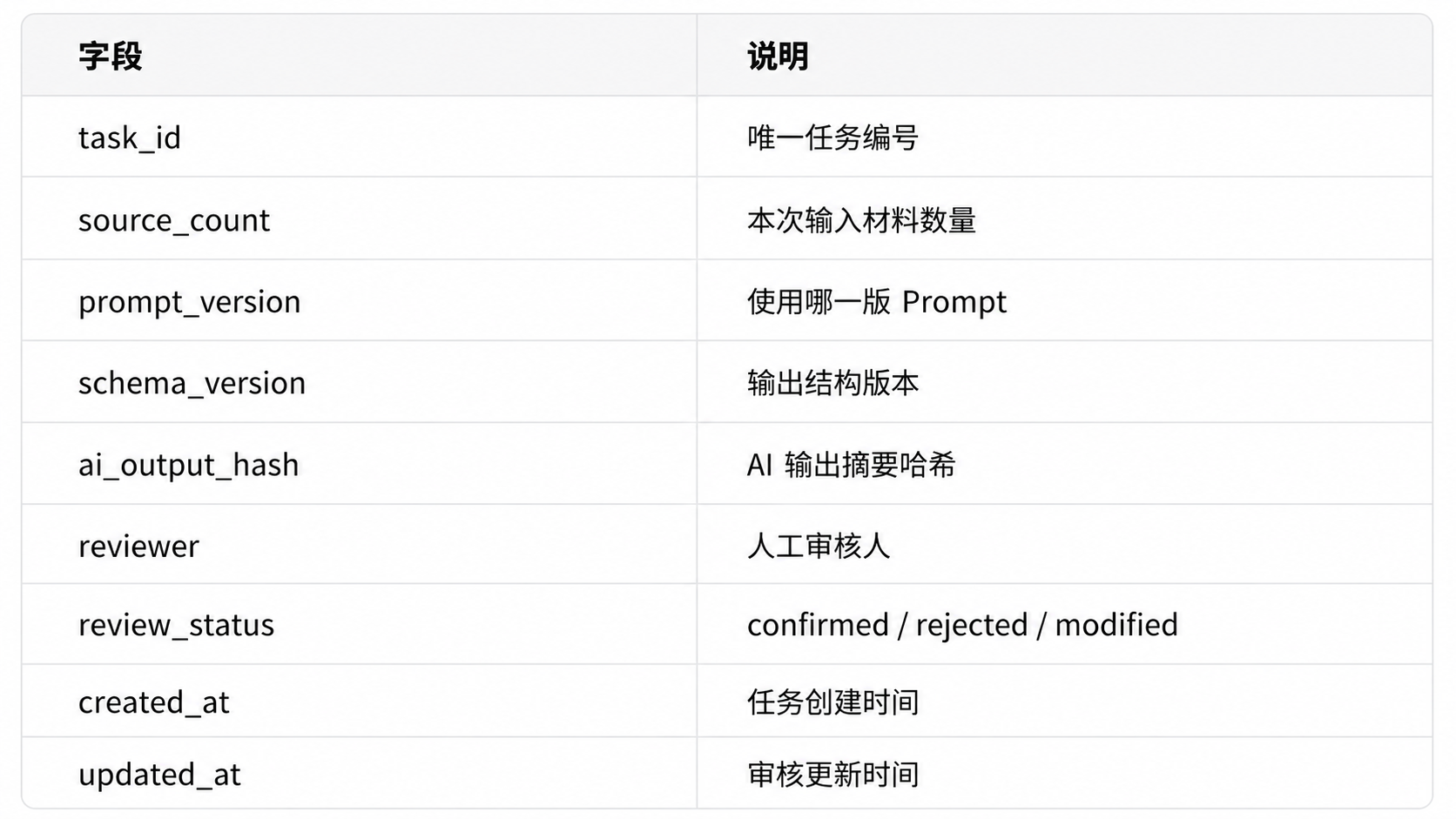
这张表的目的不是复杂化,而是为了回答几个问题:
- 哪版 Prompt 效果更好?
- 哪类反馈最常见?
- 哪些输出经常被人工改?
- AI 是否真的节省时间?
- 哪些场景不适合继续自动化?
如果没有记录,就只能靠感觉判断。
有了记录,才可能持续优化。
---
## 10. 输入示例与输出示例
### 输入示例
```json
{
"task_id": "feedback_20260607_002",
"source": "comment_area",
"business_line": "content_platform",
"raw_text": "标题有点夸张,案例感觉不真实,结尾像广告",
"expected_output": "content_risk_review",
"review_required": true
}
```
### Prompt 示例
```text
你是一个内容风险初筛助手。
请根据 raw_text 判断用户反馈中提到的内容问题。
输出 JSON 数组,每个对象包含:
- issue:问题描述
- issue_type:标题问题 / 案例问题 / 广告感 / 结构问题 / 其他
- severity:高 / 中 / 低
- suggested_fix:修改建议
- need_human_review:true / false
规则:
1. 不要替用户扩写没有表达过的问题。
2. 如果涉及广告感、夸张承诺、虚假案例,need_human_review=true。
3. 只输出 JSON。
```
### 输出示例
```json
[
{
"issue": "标题有点夸张",
"issue_type": "标题问题",
"severity": "中",
"suggested_fix": "降低标题夸张程度,改成判断型表达",
"need_human_review": true
},
{
"issue": "案例感觉不真实",
"issue_type": "案例问题",
"severity": "高",
"suggested_fix": "补充具体场景或替换为真实可验证案例",
"need_human_review": true
},
{
"issue": "结尾像广告",
"issue_type": "广告感",
"severity": "高",
"suggested_fix": "弱化引导语,改成信息参考或经验补充",
"need_human_review": true
}
]
```
这个例子可以用于内容团队、自媒体团队、运营团队。
它不让 AI 直接决定内容能不能发布,而是让 AI 提前列出风险点。
---
## 11. 技术边界:AI 办公流程不适合全自动
即使流程做得再好,也不建议把所有办公任务全自动化。
尤其是这些任务:
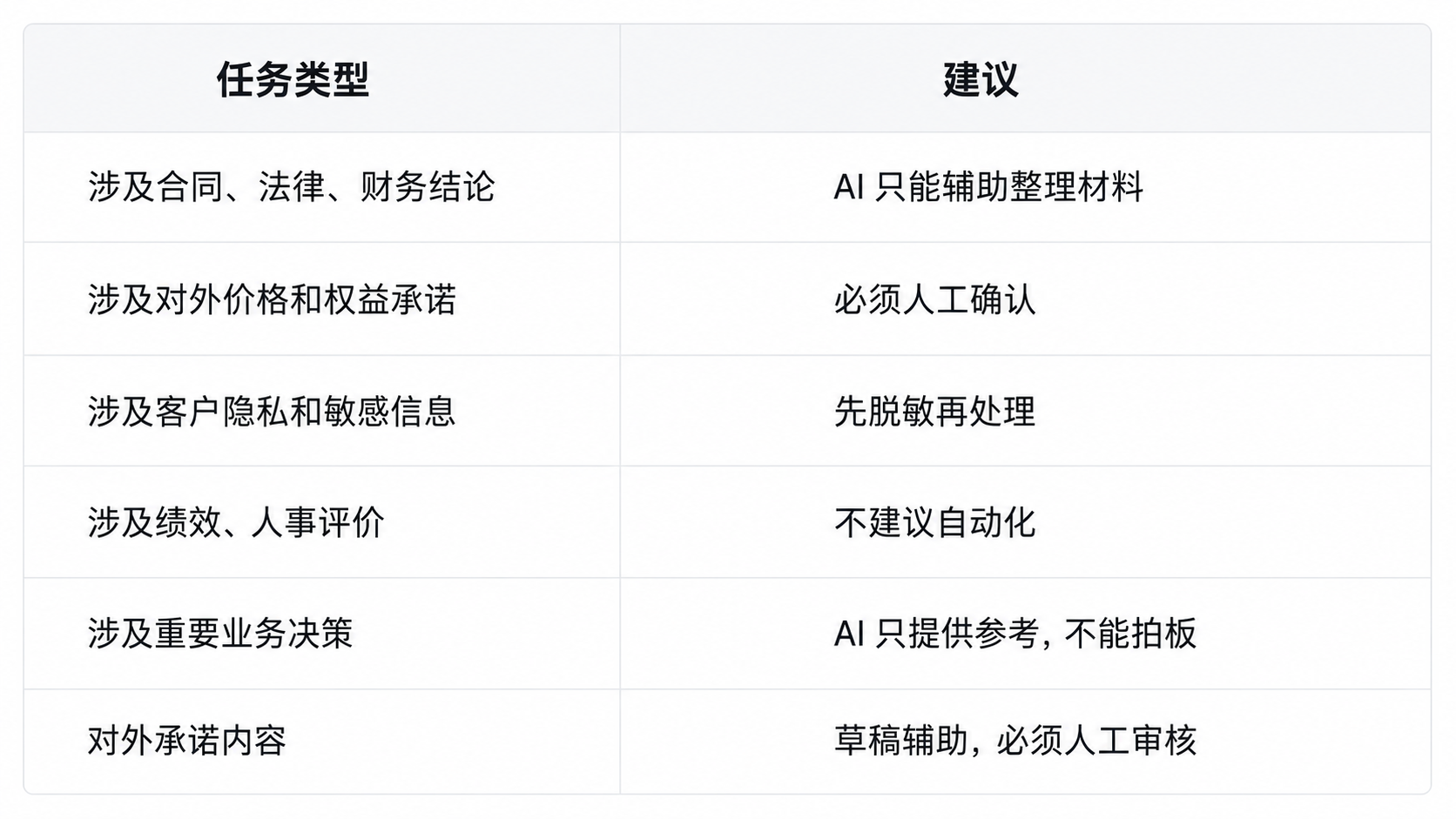
原因很简单:
AI 可以提高处理速度,但责任链不能消失。
---
## 12. 评估效果:不要只看生成速度
一个 AI 办公流程是否有效,可以用 5 个指标评估:
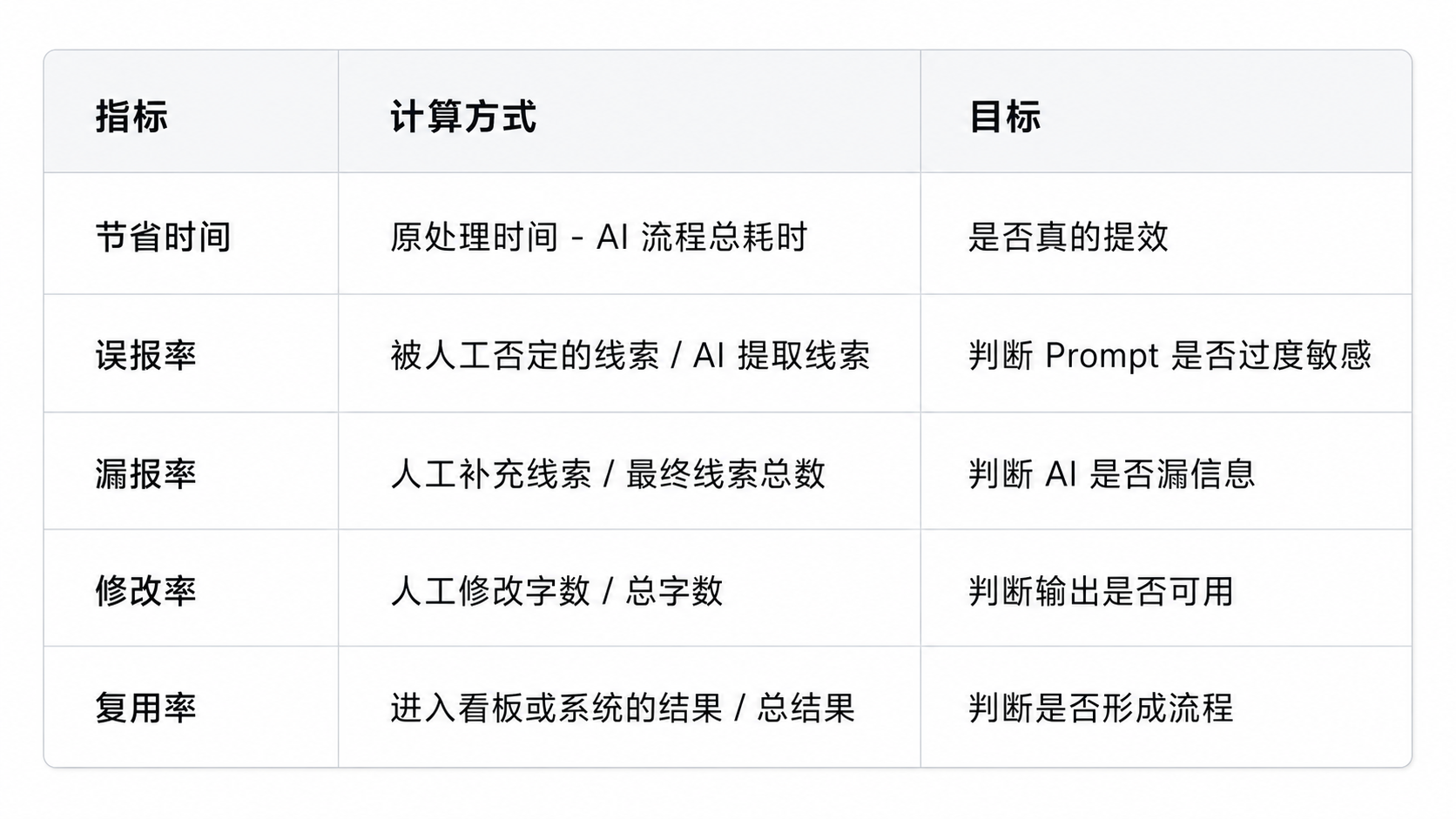
这比“AI 写得快不快”更可靠。
很多团队用 AI 后没有提效,问题就出在这里:
只统计生成速度,不统计返工和复用。
---
## 13. CSDN 用户可以这样落地
如果你是开发者、技术负责人、运营工具开发者,可以从最小版本开始:
```text
第 1 周:
选一个高频低风险任务,如反馈归类或内容风险初筛。
第 2 周:
固定输入字段和 Prompt 模板。
第 3 周:
输出固定 JSON,并用代码做结构校验。
第 4 周:
增加人工审核记录和结果入库。
第 5 周:
看节省时间、修改率、复用率,再决定是否扩展。
```
不要一上来做大而全的 AI 系统。
先跑通一个小流程,比堆十个工具更重要。
---
## 结尾:AI 办公提效,关键是把结果接进流程
ChatGPT 正在变成综合入口,Codex 也在进入更多知识工作场景。Business Insider 今日提到,OpenAI 和 Anthropic 的竞争正在转向更强的工作流黏性;OpenAI Codex app 文档也显示,Codex app 支持并行 threads、worktree、automations 和 Git 功能。
这说明 AI 工具会越来越容易进入工作流。
但越是这样,越不能把 AI 办公停留在“临时问一句”。
更稳的路径是:
1. 选高频、低风险、可核对任务;
2. 固定输入;
3. 固定 Prompt;
4. 固定输出 Schema;
5. 做结构校验;
6. 加业务规则;
7. 人工审核;
8. 结果入库;
9. 用指标评估是否真的提效。
如果你正在做 GPT办公提效,或者想把 AI 用在资料整理、内容初筛、。重点不是追“全自动”,而是先把一个小流程跑通、记录下来、复用起来。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)