
搭建Ollama并运行qwen,简单RAG实现
1、wsl环境中安装ollama
curl -fsSL https://ollama.com/install.sh | sh
2、启动
ollama serve
3、拉取模型
# 拉取模型(此过程会下载约4-5GB的数据) ollama pull qwen2.5:7b # 推荐:中文能力强,综合性能优秀 # 或者 ollama pull llama3.2:7b # 备选:国际主流模型
ollama run qwen2.5:7b
4、安装python
WSL2中安装Python的步骤
# 1. 更新包列表
sudo apt update
# 2. 安装Python3和pip
sudo apt install python3 python3-pip -y
# 3. 验证安装
python3 --version
pip3 --version
# 4. (可选)设置python3为默认python命令
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3 1
如果wsl是ubantu 要用虚拟环境
# 1. 创建虚拟环境(在用户目录下)
python3 -m venv ~/ai_venv
# 2. 激活虚拟环境
source ~/ai_venv/bin/activate
# 激活后,命令行提示符前会出现 (ai_venv)
# 3. 在虚拟环境中安装包(不会影响系统)
pip install --upgrade pip
pip install langchain langchain-community chromadb pypdf
# 4. 运行你的脚本(确保在虚拟环境中)
python /mnt/f/tmp/test_rag.py
# 5. 退出虚拟环境(完成后)
deactivate
安装旧版lanchain
# 1. 安装兼容的旧版本
pip uninstall langchain langchain-community langchain-core langchain-classic langchain-text-splitters -y
pip install "langchain==0.1.0" "langchain-community==0.0.10"
# 2. 验证
python -c "from langchain.chains import RetrievalQA; from langchain_community.llms import Ollama; print('✅ 所有关键模块导入成功!')"
# 3. 现在运行你的测试脚本
python /mnt/f/tmp/test_rag.py编辑脚本
# test_rag.py - 带错误处理的完整版
import sys
print("=== RAG系统测试 ===")
# 1. 导入必要的库
try:
from langchain.chains import RetrievalQA
from langchain_community.llms import Ollama
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import OllamaEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import TextLoader
print("✅ 所有库导入成功")
except ImportError as e:
print(f"❌ 导入失败: {e}")
sys.exit(1)
# 2. 连接本地Ollama(对话模型)
try:
llm = Ollama(base_url="http://localhost:11434", model="qwen2.5:7b")
print("✅ 已连接本地对话模型 (qwen2.5:7b)")
except Exception as e:
print(f"❌ 连接Ollama失败: {e}")
sys.exit(1)
# 3. 尝试不同的嵌入模型
embedding_models = ["all-minilm", "nomic-embed-text", "mxbai-embed-large", "qwen2.5:7b"]
embeddings = None
for model in embedding_models:
try:
print(f"尝试使用嵌入模型: {model}")
embeddings = OllamaEmbeddings(base_url="http://localhost:11434", model=model)
# 简单测试
test_embed = embeddings.embed_query("test")
print(f"✅ 嵌入模型 '{model}' 可用")
break
except Exception as e:
print(f" 模型 '{model}' 不可用: {str(e)[:80]}...")
continue
if embeddings is None:
print("❌ 所有嵌入模型都不可用")
print("请先安装一个嵌入模型:")
print(" ollama pull all-minilm # 推荐,轻量快速")
print(" ollama pull nomic-embed-text")
sys.exit(1)
# 4. 创建测试文档
insurance_text = """
【健康保险条款示例】
第一条 保险责任
在本合同有效期内,被保险人因遭受意外伤害或疾病,在符合本合同约定的医院进行治疗,本公司按下列约定给付保险金:
一、住院医疗保险金:被保险人需支付免赔额人民币5000元,免赔额以上部分按90%比例报销,年度累计给付以20万元为限。
二、重大疾病保险金:一次性给付人民币30万元。
"""
with open("sample_policy.txt", "w", encoding="utf-8") as f:
f.write(insurance_text)
# 5. 加载、分割文档
try:
loader = TextLoader("sample_policy.txt")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)
texts = text_splitter.split_documents(documents)
print(f"✅ 文档处理完成,分割为 {len(texts)} 个片段")
except Exception as e:
print(f"❌ 文档处理失败: {e}")
sys.exit(1)
# 6. 创建向量库
try:
vectorstore = Chroma.from_documents(texts, embeddings, persist_directory="./insurance_db")
print("✅ 向量知识库构建完成")
except Exception as e:
print(f"❌ 创建向量库失败: {e}")
sys.exit(1)
# 7. 创建RAG问答链
try:
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever(search_kwargs={"k": 2}),
chain_type="stuff"
)
print("✅ RAG问答链创建完成")
except Exception as e:
print(f"❌ 创建问答链失败: {e}")
sys.exit(1)
# 8. 测试问答
print("\n" + "="*50)
print("开始问答测试")
print("="*50)
test_questions = [
"我这份合同的免赔额是多少钱?",
"我如果住院的话医疗的报销比例是多少?",
"我一整年的报销上限是多少?",
"重大疾病保险金怎么赔付?陪多少钱?"
]
for i, question in enumerate(test_questions, 1):
print(f"\n{i}. ❓ 问题:{question}")
try:
answer = qa_chain.run(question)
print(f" 💡 回答:{answer}")
except Exception as e:
print(f" ❌ 回答失败: {e}")
print("\n" + "="*50)
print("🎉 RAG系统测试完成!")
print("="*50)测试脚本
# 1. 确保你在虚拟环境中(有 (ai_venv) 前缀)
# 如果不在:source ~/ai_venv/bin/activate
# 2. 确保Ollama服务在运行(在另一个终端窗口)
# ollama serve
# 3. 运行你的RAG测试脚本
python /mnt/f/tmp/test_rag.py
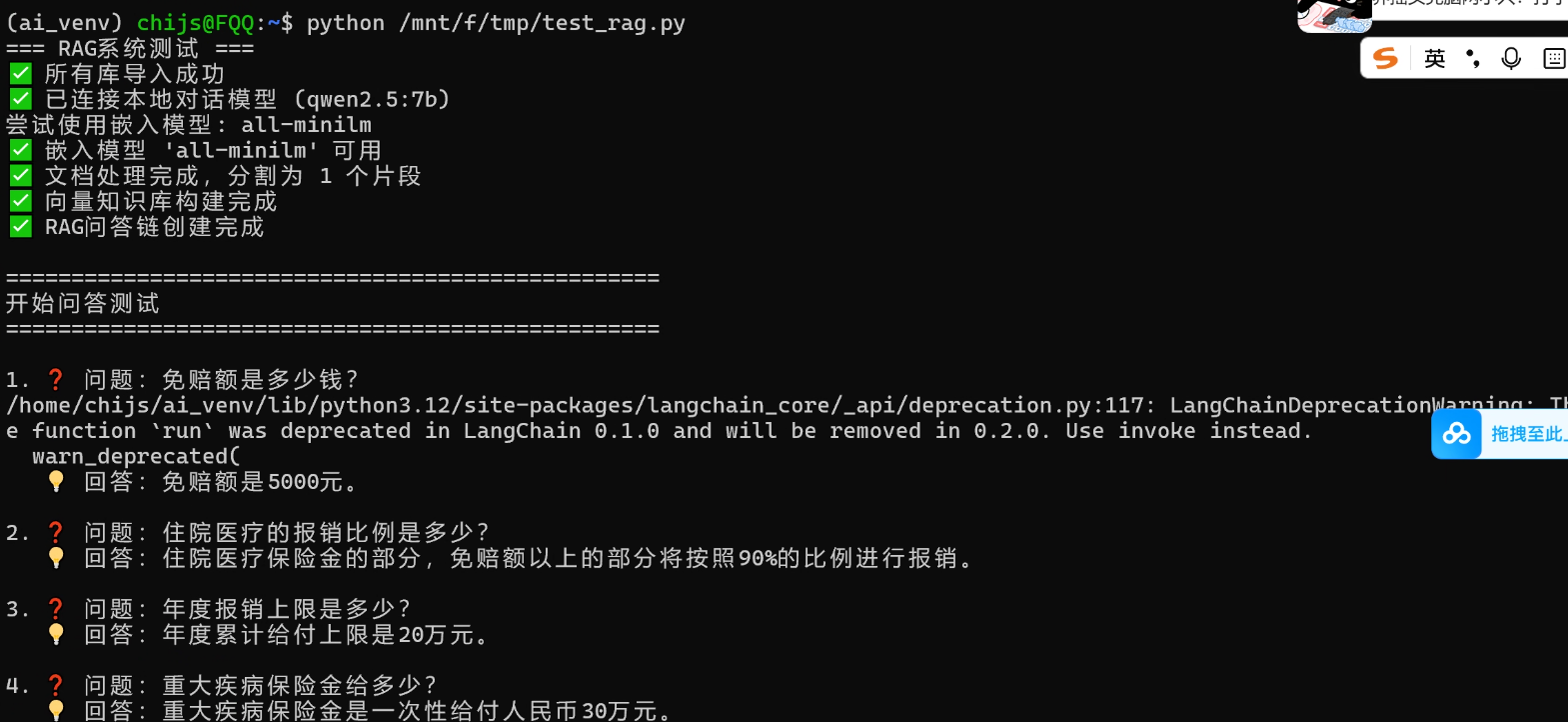
运行脚本后的效果

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)