
Claude Fable 5 发布后,企业 Agent Runtime 为什么更需要 MateClaw?

2026 年 6 月 9 日,Anthropic 正式发布 Claude Fable 5。X 上这条发布帖在本机浏览器里显示的时间是 2026 年 6 月 9 日 17:08,同日 Anthropic 也同步发布了官网公告、Claude API 文档、模型说明、迁移指南、prompting 指南、fallback/计费说明和价格页。官方不是只发了一条社媒消息,而是把 Fable 5 当作一个完整平台能力来发布:模型 ID、API 行为、上下文能力、工具调用限制、安全拒答、fallback credit、云平台可用性都一起补齐了。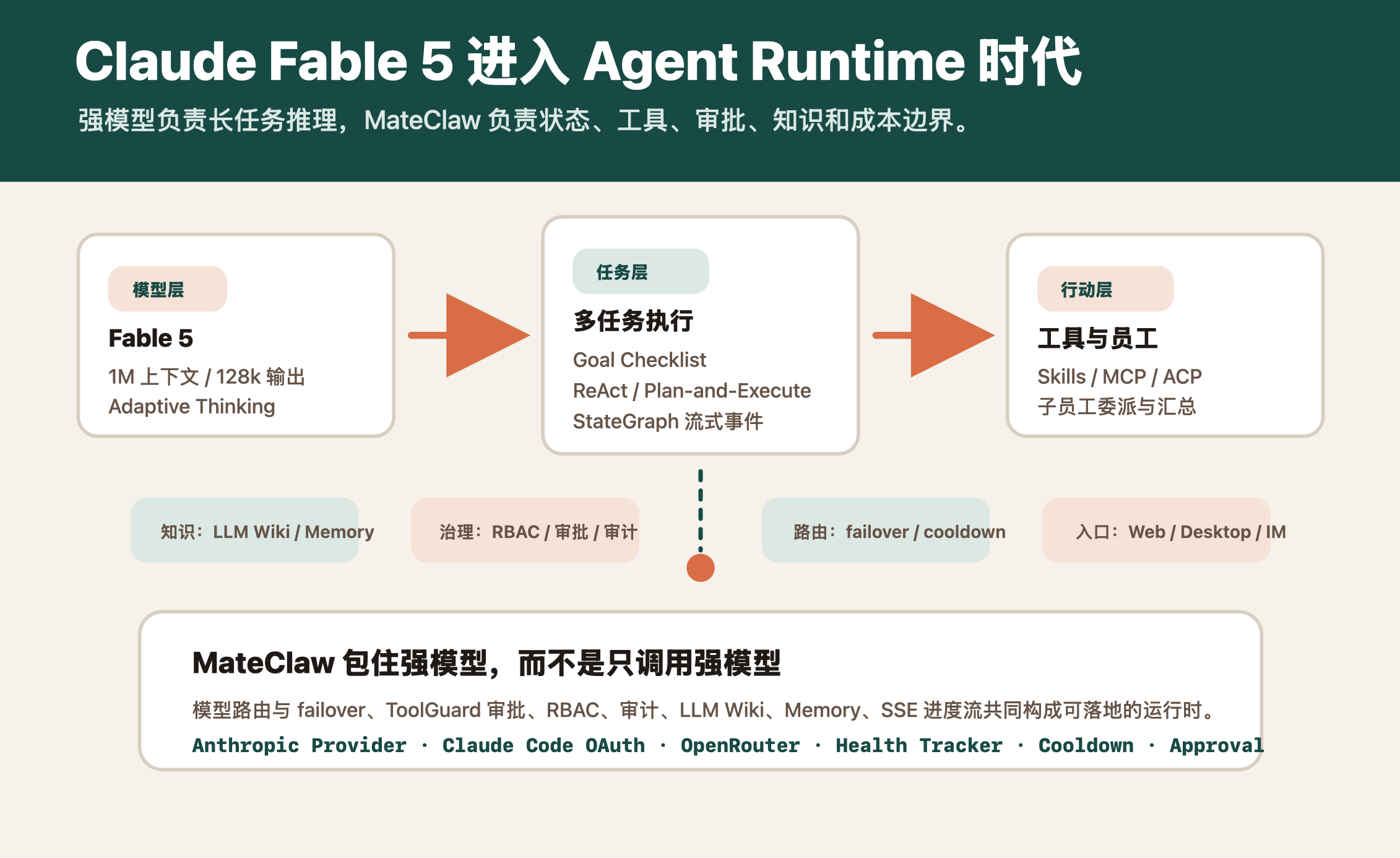
这次发布的核心,是 Anthropic 把 Fable 5 定位为“最强的广泛可用模型”,用于 demanding reasoning 和 long-horizon agentic work。与此同时,Anthropic 还发布了 Claude Mythos 5,但 Mythos 5 只面向 Project Glasswing 等受限用户开放。简单说,Mythos 5 更像内部/受控版本,Fable 5 则是经过安全分类器处理后可公开使用的版本。官方还强调两者支持 1M token 上下文、最高 128k 输出、always-on adaptive thinking,并且不会返回原始 chain of thought。
从发布动作看,Anthropic 明显不是在推一个普通聊天模型,而是在为 agent runtime 铺路。Fable 5 的官方叙事集中在软件工程、知识工作、科研、视觉理解和长任务上;发布图里也把它和 Claude Opus 4.8、Mythos Preview、GPT-5.5、Gemini 3.1 Pro 放在同一张 benchmark 表中比较。它强调的不是“回答更快”,而是“任务越长、越复杂,领先越明显”。这非常符合 agent runtime 的需求:模型要能规划、调用工具、读长上下文、持续修改代码、处理失败并自我修复。
公开实测里,编程表现目前是最有说服力的部分。Simon Willison 用 Fable 5 做真实项目改造,包括 CPython WASM 相关迁移,以及给 Datasette/LLM 加入更复杂的 tool call 确认、暂停和恢复能力。他的反馈不是简单“代码写得不错”,而是模型能参与 API 设计、测试、文档和迭代修复,更接近一个可以长时间协作的工程 agent。
Every / Dan Shipper 的测评也给出类似结论:Fable 5 在他们内部 Senior Engineer benchmark 上大幅领先 Opus 4.8 和 GPT-5.5,尤其适合把完整任务交给模型,让它在后台持续推进。第三方榜单里,Fable 5 在 SWE-bench Verified、Terminal-Bench 这类更贴近真实工程环境的测试中也表现靠前,说明它的优势不只是刷静态代码题,而是能在代码库、终端、测试和修改闭环里发挥作用。
但 Fable 5 也带来了 agent runtime 必须处理的新问题:它贵、慢、token 消耗大,而且在安全敏感场景下可能拒答或 fallback 到 Opus 4.8。因此它不适合所有请求都默认调用,更适合放在 runtime 的高价值路径里:复杂代码库改造、长周期 agent、关键架构判断、大规模 review、科研推理和多步骤工具任务。真正的产品能力不只是接入 Fable 5,而是围绕它设计预算控制、任务拆分、状态保存、权限边界、fallback 策略和结果验证。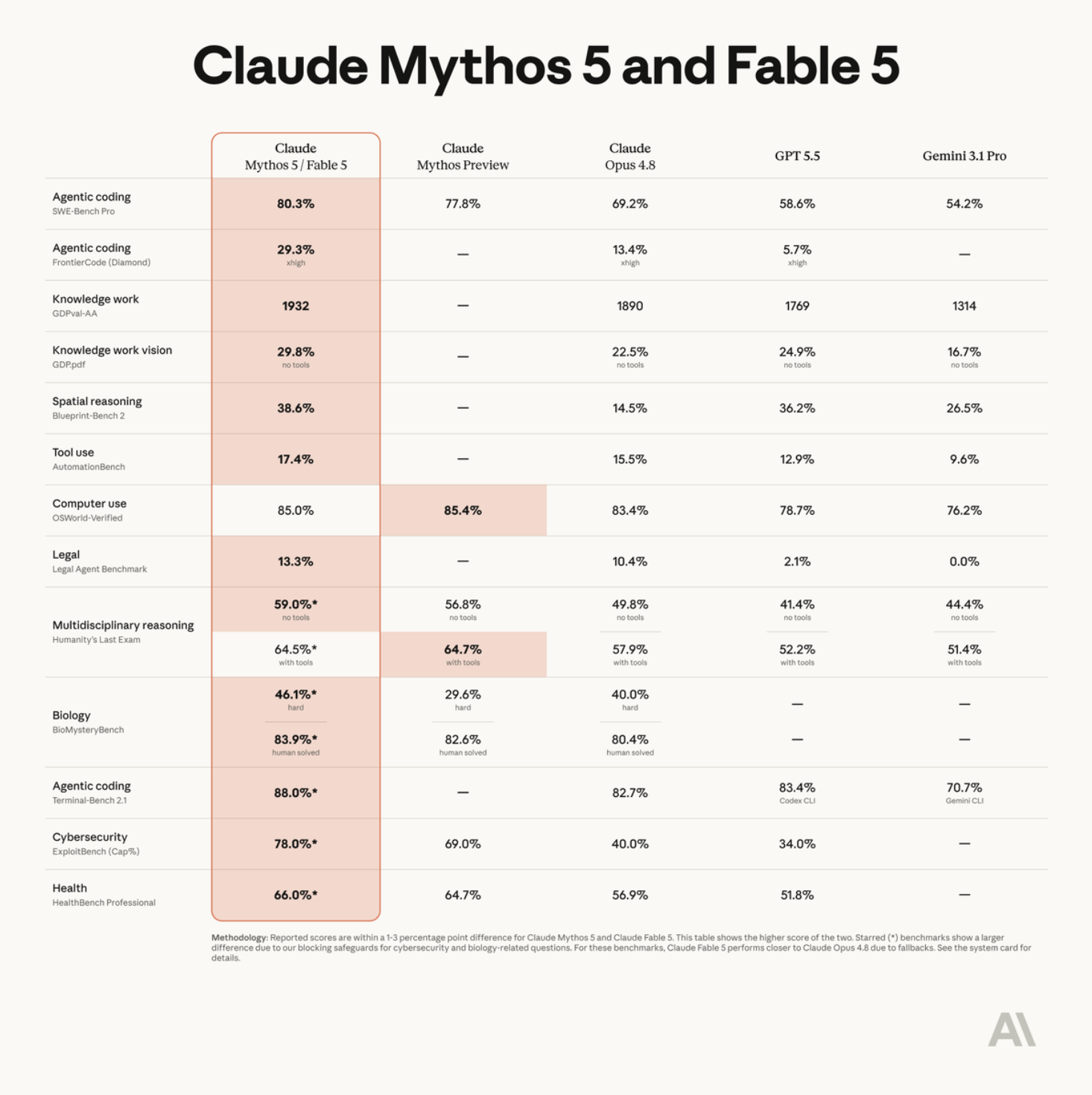
为什么这件事和 MateClaw 有关?
很多团队接入新模型的第一反应,是把 model name 加到配置里,然后把默认模型切过去。这个动作当然必要,但它只解决“能不能调用”的问题,没解决“能不能在企业里长期跑”的问题。
Fable 5 这种模型越强,越会把 Agent 从“回答问题”推向“执行任务”。一旦 Agent 可以读代码、调工具、改文件、查知识库、调用内部 API、委派子任务,系统就必须回答几个工程问题:
- 任务拆到哪一步?
- 哪些工具可以自动执行,哪些必须审批?
- 长任务中断以后,状态如何恢复?
- 贵模型什么时候用,普通模型什么时候用?
- 模型 fallback 后,用户是否还能拿到一致结果?
- 执行过的工具、审批、引用来源,后面怎么审计?
MateClaw 的价值点就在这里:它不是把强模型包装成一个聊天框,而是把模型放进一个可治理的 Java Agent Runtime 里。
MateClaw 对 Fable 5 的支持方式
MateClaw 已经具备 Anthropic Messages、Claude Code OAuth、OpenRouter 透传等模型接入路径。Fable 5 的官方模型 ID 是 claude-fable-5,在 MateClaw 当前模型管理体系里,可以通过 Anthropic Provider 添加/启用这个模型;如果走 OpenRouter,则可以按 OpenRouter 的模型命名方式透传。
这里要强调一个细节:MateClaw 的支持重点不是把一个新字符串写死,而是它的模型运行时已经具备这些能力:
mate_model_provider管供应商、Key、Base URL、认证方式;mate_model_config管模型 ID、max tokens、thinking 档位、启用状态;- Anthropic ChatModel Builder 会按模型名构造 Anthropic 请求,并处理 prompt cache、thinking、超时;
- 多供应商 failover 会在供应商失败后切换到下一个健康模型;
- Provider health tracker 会把连续失败的供应商放进 cooldown,避免每轮都卡在坏节点上。
所以 Fable 5 接入 MateClaw 后,更合理的用法不是“全站默认替换”,而是把它放进高价值路径:复杂目标、长任务、工程改造、深度 review、科研推理和多步骤工具执行。
多任务执行:MateClaw 怎么让强模型跑起来
MateClaw 里有一个很重要的概念:Digital Employee。每个员工不是一个裸模型,而是带有 Role、Goal、Backstory、工具权限、知识库范围和运行策略的 Agent。
在多任务执行上,MateClaw 主要靠三层机制:
第一层是 ReAct。适合“边想边查边做”的任务,例如查知识库、调用工具、根据观察结果继续下一步。
第二层是 Plan-and-Execute。适合复杂任务,先把目标拆成步骤,再逐步执行、记录结果、最后汇总。MateClaw 这里用 StateGraph 承载执行过程,不是简单 for-loop。每个 phase、tool call、plan、step 都可以通过 SSE 变成结构化事件,前端能看到进度,后端能持久化执行痕迹。
第三层是 Goal Checklist。它让长任务不只是“聊到哪里算哪里”,而是有目标、有预算、有评价、有完成状态。Goal 可以记录 turns_used、LLM call budget、completion score、criteria checklist 和 evaluation event。对 Fable 5 这类长任务模型来说,这层尤其重要,因为越是长任务,越需要明确的停止条件和验收标准。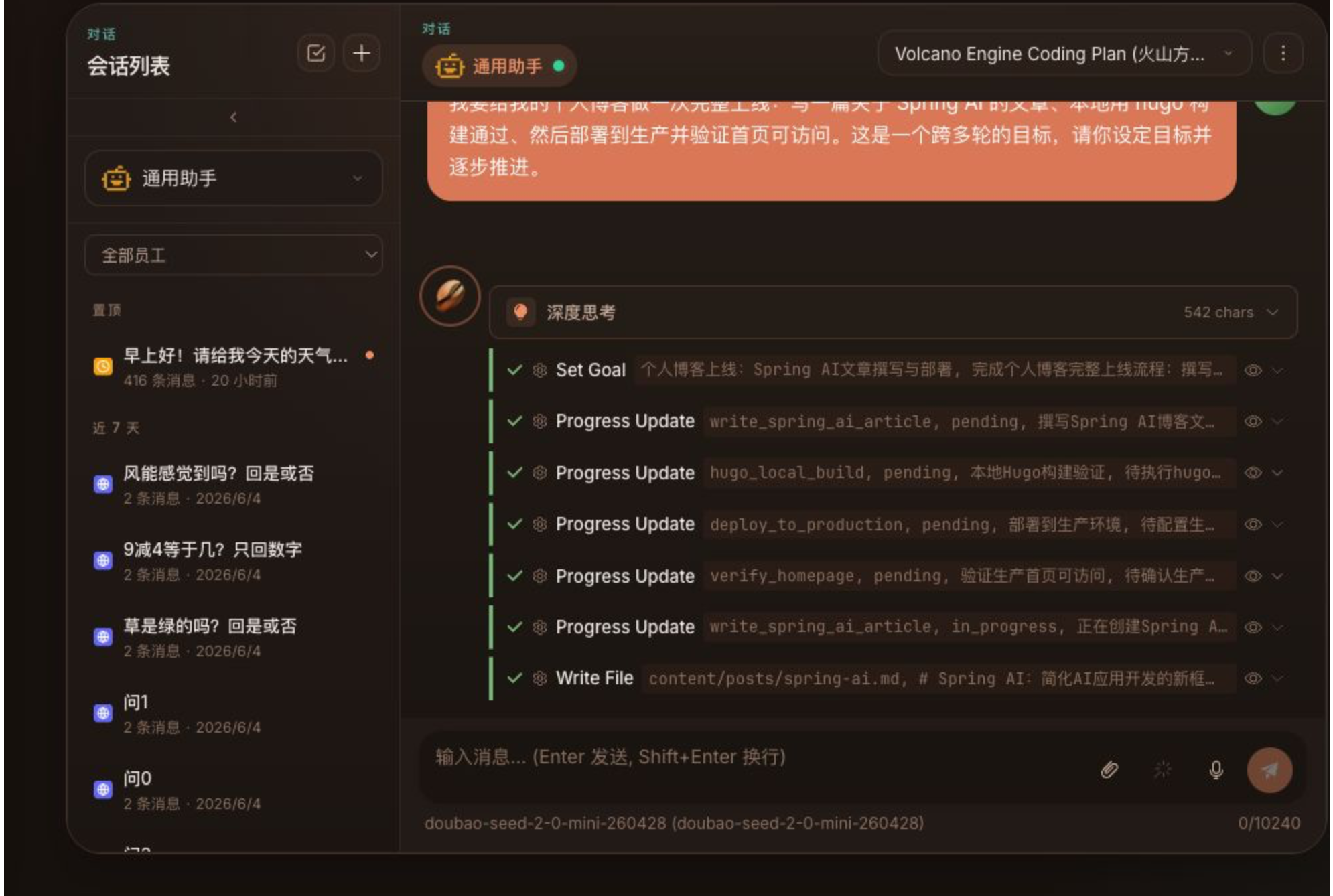
工具调用不能只靠模型自觉
Fable 5 这类模型的强项,是能更稳定地规划、读上下文和调用工具。但企业场景不能只相信模型“会自己判断”。工具一旦能写文件、发消息、调 API、跑 shell、访问知识库,runtime 必须把权限边界放在模型之外。
MateClaw 在这块的实现路径比较工程化:
- Skills:用
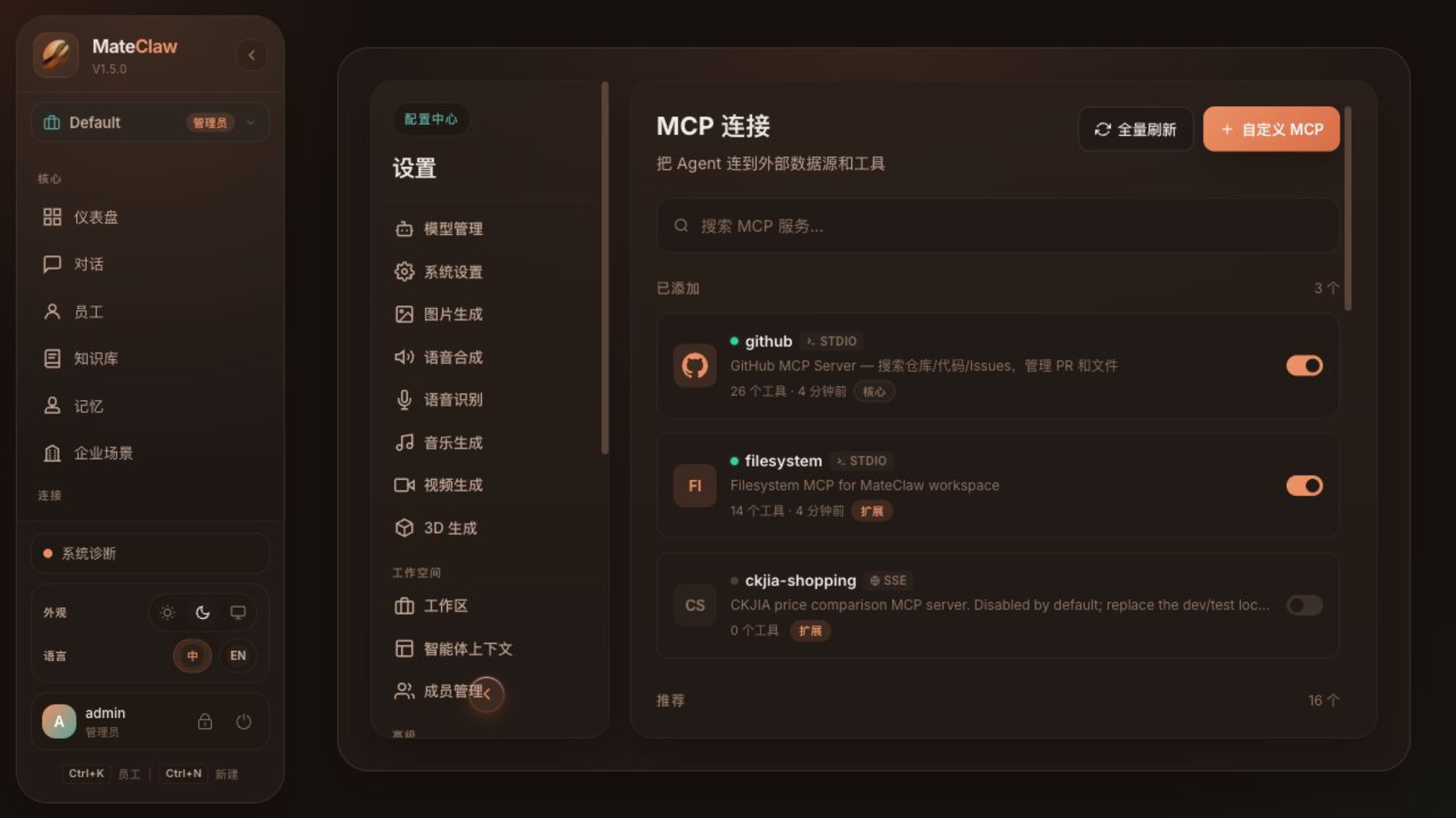
SKILL.md把能力、提示词、工具集合和经验沉淀成包; - MCP:把外部工具服务接进统一工具注册表;
- ACP:把 Claude Code、Codex 这类外部 coding agent 当成可委派员工;
- ToolGuard:对敏感工具做 RBAC、审批、路径保护和审计;
- Approval:工具执行遇到风险时暂停,等人审批后再恢复。
这也是 Fable 5 进入生产环境后最容易被低估的部分。模型越会干活,就越需要审批、日志、权限和回放。否则“长任务能力”会变成“长时间不可控”。
LLM Wiki 和 Memory:给长任务一个可持续上下文
Fable 5 的 1M 上下文很强,但上下文窗口不是企业知识管理的全部。窗口再大,也不等于信息可信、来源可追踪、长期可复用。
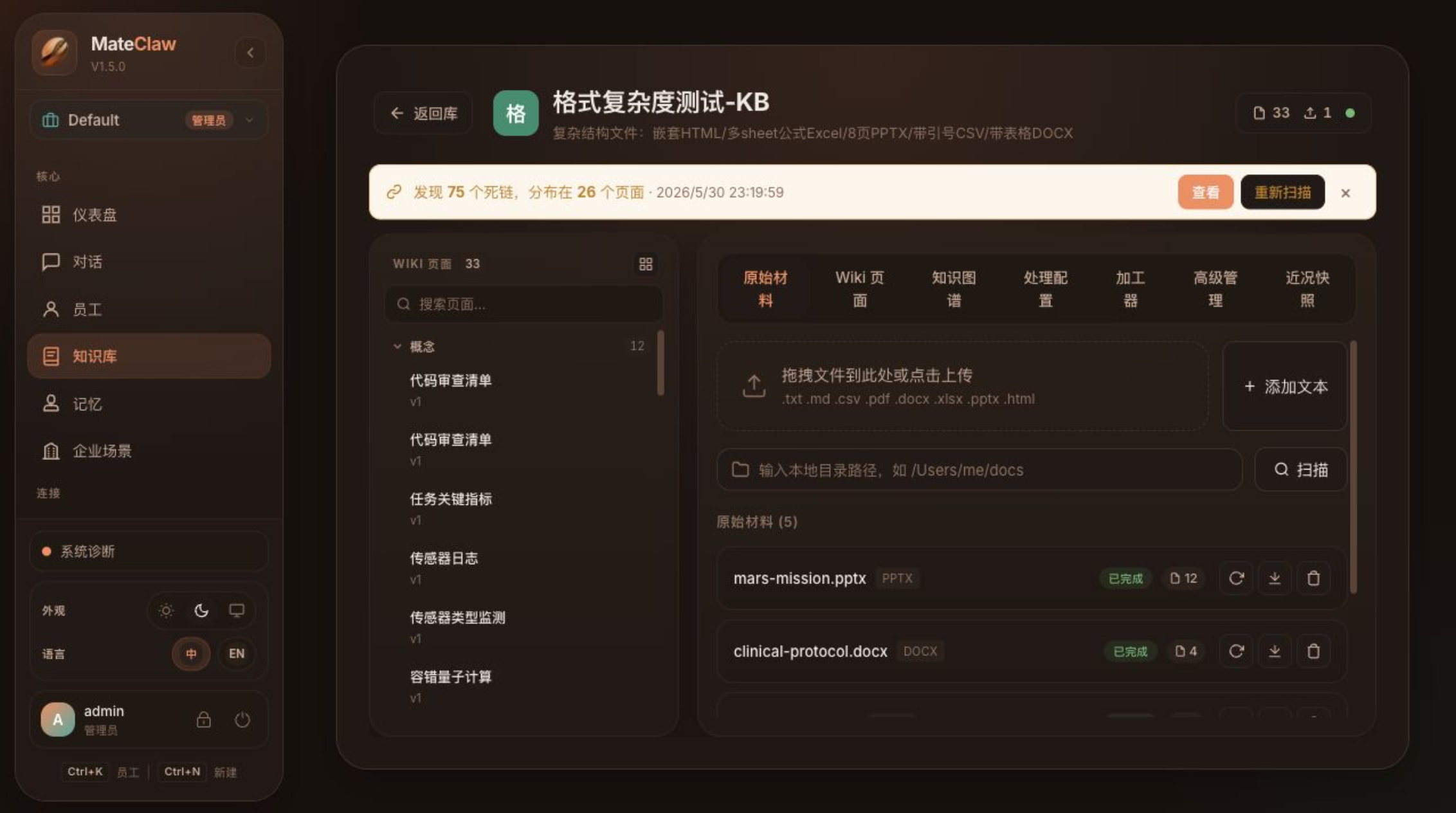
MateClaw 的 LLM Wiki 更像“给 Agent 用的活知识库”:
- 原始资料进入后会被切块、归档、结构化成页面;
- 页面可以保留 citation,回答时能追溯来源;
- hot cache 可以把高频知识注入员工系统提示词;
- 页面类型、分层、失效、权限和流水线可以后台管理;
- Memory 和 Dreaming 负责对会话后的经验做抽取、整理和长期沉淀。
这和 Fable 5 的关系很直接:强模型负责复杂推理,MateClaw 负责把企业知识变成可检索、可引用、可更新、可权限控制的上下文。
更强模型会持续出现,关键是 Runtime 能不能跟上
Fable 5 不会是最后一个“更适合长任务 Agent”的模型。之后还会有更长上下文、更强 coding、更强 tool use、更高并发、更低成本的模型出现。
如果系统架构只围绕某一个模型写死,就会反复追着模型升级改代码。MateClaw 的思路更偏平台化:
- 模型层可替换:Anthropic、OpenAI、DashScope、Gemini、DeepSeek、Kimi、Ollama、LM Studio 等都可以进入统一配置;
- 任务层可编排:ReAct、Plan-and-Execute、StateGraph、Workflow DSL 可以处理不同复杂度;
- 工具层可扩展:Skills、MCP、ACP 三层扩展,不把能力绑死在一个供应商;
- 治理层可审计:RBAC、审批、审计、JWT、PAT、Webhook 签名适合企业自部署;
- 入口层可复用:Web Console、Desktop、Widget、飞书/企业微信/钉钉等 IM Channel 可以共享同一套员工和任务状态。
换句话说,Fable 5 让“长任务 Agent”更可行,而 MateClaw 要解决的是“长任务 Agent 怎么在团队里可控地跑起来”。
一个更现实的使用建议
如果团队已经在使用 MateClaw,可以这样安排 Fable 5:
- 不要一上来设成所有员工的默认模型,先作为高价值模型加入模型池。
- 给架构师、代码审查、知识库整理、科研分析这类员工单独绑定。
- 打开 Goal Checklist,用 criteria 和预算约束长任务。
- 对 shell、文件写入、外部消息、内部 API 调用配置 ToolGuard 审批。
- 保留一个更便宜、更快的模型作为 fallback,用 health tracker 和 cooldown 避免坏供应商拖慢链路。
- 对 Wiki、Memory、工具调用日志做事后 review,确认结果不是只“看起来完成”。
这样用,Fable 5 的价值会更清楚:它不是普通问答模型的升级,而是企业 Agent Runtime 里负责高难度任务的一块“强执行核心”。
总结
Claude Fable 5 的发布,说明头部模型厂商正在把重点从聊天能力推向长任务、工具调用和软件工程闭环。模型会越来越强,但企业真正需要的不是“一个更聪明的聊天框”,而是一个能承载强模型的运行时:任务拆解、状态保存、工具审批、知识引用、成本控制、fallback 和审计。
MateClaw 适合放在这个位置。Fable 5 负责更强的推理和长任务能力,MateClaw 负责把它放进企业可控的 Agent Runtime 中。模型继续变强,平台的价值反而会更明显。
项目与体验:

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)