
LangChain实战:新手手撸RAG全记录(四)
上一章我们把各种文档洗干净切好了,存成了一个标准的 JSON 文件,但 JSON 文件还是文本,计算机看不懂没法直接拿来回答问题,这一章的任务就是:把文本变成向量,存进数据库,然后提供检索功能,我将这些功能写进了vector_store.py里
简单说,这个文件负责三件事:
读取上一章生成的json文件processing_results.json
把里面的文本切分成小段,用BGE模型转成向量,存到Chroma里
通过search_documents、search_with_score这些函数增强检索,让后面的问答模块能根据问题找到最相关的文档片段
4.1 加载预处理数据
第一步当然是读数据,通过load_processed_json函数检查文件是否存在,然后加载 JSON
def load_processed_json() -> List[Dict[str, Any]]:
if not PROCESSED_JSON_PATH.exists():
raise FileNotFoundError(f"处理后的数据文件未找到:{PROCESSED_JSON_PATH},请先运行data_preprocess.py")
with open(PROCESSED_JSON_PATH, 'r', encoding='utf-8') as f:
data = json.load(f)
print(f"已加载{len(data)}个文档的JSON数据")
return data4.2 文档对象转换
LangChain有一套自己的文档类Document,后面很多操作都要用它,所以我把JSON里的每个文档转成Document对象
def json_to_documents(json_data: List[Dict[str, Any]]) -> List[Document]:
documents = []
for item in json_data:
file_name = item['file_name']
data = item['data']
raw_text = data['raw_text']
metadata = data.get('metadata', {})
# 生成文档ID
text_hash = hashlib.md5(raw_text.encode()).hexdigest()[:8]
doc_id = f"{file_name}_{text_hash}"
doc = Document(
page_content=raw_text,
metadata={
'source': file_name,
'doc_id': doc_id,
'file_type': metadata.get('type', 'unknown'),
'file_size': metadata.get('file_size', 0),
**metadata
}
)
documents.append(doc)
# 如果原文档里有表格,把每个表格也单独作为一个文档
if data.get('tables'):
for table_idx, table in enumerate(data['tables']):
table_text = json.dumps(table, ensure_ascii=False, indent=2)
table_doc = Document(
page_content=f"表格数据:\n{table_text}",
metadata={
'source': file_name,
'doc_id': f"{doc_id}_table_{table_idx}",
'file_type': metadata.get('type', 'unknown'),
'content_type': 'table',
'table_index': table_idx,
**metadata
}
)
documents.append(table_doc)
return documents如果没给文档生成ID,重复运行程序时,向量库里会有大量重复文档,所以加了doc_id,基于文件名和内容哈希生成,保证同样的内容只会存一次(不过这里只是生成 ID,并没有做去重,实际上去重可以在存储时利用 ID 实现,但 Chroma 的 from_documents 会直接添加,不会去重。如果想真正去重,需要额外逻辑,这里先不管)。
另外,我把表格单独抽出来作为一个文档,因为很多时候用户想查的是表格里的数据,如果只存正文可能查不到,单独存一份检索效果更好。
4.3 文档拆分
原始文档可能很长,直接整个存成向量,检索时容易把不相关的内容也带进来,而且大模型的上下文窗口有限,太长也塞不下,所以需要把文档切成小段
def split_documents(documents: List[Document]) -> List[Document]:
text_splitter=RecursiveCharacterTextSplitter(
chunk_size=500, # 每个块500字符
chunk_overlap=50, # 块间重叠50字符
separators=["\n\n", "\n", "。", ";", ",", " ", ""],
length_function=len,
)
splits=text_splitter.split_documents(documents)
print(f"文档已拆分为{len(splits)}个片段")
return splitsRecursiveCharacterTextSplitter是LangChain提供的一个智能分块器,它会优先按段落 (\n\n) 切,不行再按句子 (\n、。) 切,最后按词切,这样能最大程度保证语义完整。
重叠 50 字符是为了防止正好把一句话从中间切断了,丢失上下文,比如前一段末尾是张三的月薪是,后一段开头是15000元,如果不重叠这两部分就分开了,检索时可能找不到完整的答案。
4.4 向量存储管理
这是整个文件的核心函数:get_vector_store,它负责获取一个Chroma向量库实例,并且有缓存、有加载、有重建的逻辑
_vector_store: Optional[Chroma] = None
def get_vector_store(force_recreate: bool = False) -> Chroma:
global _vector_store
if _vector_store is not None and not force_recreate:
return _vector_store
print("初始化向量存储...")
CHROMA_PERSIST_DIR.mkdir(parents=True, exist_ok=True)
embedding_model = get_embeddings()
should_recreate = force_recreate
# 尝试加载现有的向量库
if not should_recreate and CHROMA_PERSIST_DIR.exists() and any(CHROMA_PERSIST_DIR.iterdir()):
try:
_vector_store = Chroma(
persist_directory=str(CHROMA_PERSIST_DIR),
embedding_function=embedding_model,
collection_name=CHROMA_COLLECTION_NAME,
)
if _vector_store._collection.count() > 0:
print(f"从持久化目录加载向量存储)
return _vector_store
else:
print("加载的向量存储为空,将重新创建")
should_recreate = True
except Exception as e:
print(f"加载失败:{e},将重新创建")
should_recreate = True
# 创建新的向量库
print("正在创建新的向量存储...")
json_data = load_processed_json()
documents = json_to_documents(json_data)
splits = split_documents(documents)
_vector_store = Chroma.from_documents(
documents=splits,
embedding=embedding_model,
persist_directory=str(CHROMA_PERSIST_DIR),
collection_name=CHROMA_COLLECTION_NAME,
)
return _vector_store全局变量 _vector_store:单例模式,避免重复初始化。第一次调用后会缓存,后面直接返回
持久化目录:CHROMA_PERSIST_DIR是向量库存盘的地方。第一次运行时会创建,后面直接从磁盘加载,省去重新计算向量的时间
优先加载现有库:如果目录里有数据,就尝试加载。加载后检查是否为空,防止坏数据
强制重建:force_recreate=True可以强制重新生成向量库,比如文档更新了,需要重建
4.5 检索功能
有了向量库,接下来就是检索,我设计了两个检索函数:
search_documents:只返回文档列表,不带分数
def search_documents(query: str, top_k: int = 5, filter_dict: Optional[Dict] = None) -> List[Document]:
vector_store = get_vector_store()
if filter_dict:
docs = vector_store.similarity_search(query, k=top_k, filter=filter_dict)
else:
docs = vector_store.similarity_search(query, k=top_k)
print(f"检索到{len(docs)}条相关文档")
return docssearch_with_score:返回含文档和相似度分数的列表,分数是L2距离,越小越相似,有时候需要知道相关程度,比如排序或阈值过滤
def search_with_score(query: str, top_k: int = 5, filter_dict: Optional[Dict] = None) -> List[tuple]:
vector_store = get_vector_store()
if filter_dict:
docs_with_scores = vector_store.similarity_search_with_score(query, k=top_k, filter=filter_dict)
else:
docs_with_scores = vector_store.similarity_search_with_score(query, k=top_k)
return docs_with_scores两个函数都支持filter_dict过滤,比如只查PDF文件:{"file_type": "pdf"},比如我只想查法律条文,可以指定file_type 为txt文件
4.6 格式化与统计
format_docs:把检索到的文档格式化成易读的字符串,带上来源信息,方便后面展示给用户
def format_docs(docs: List[Document], include_metadata: bool = True) -> str:
formatted = []
for i, doc in enumerate(docs):
content = doc.page_content.strip()
if include_metadata:
source = doc.metadata.get('source','未知来源')
file_type = doc.metadata.get('file_type','未知类型')
header = f"[{i+1}]来源: {source} ({file_type})"
formatted.append(f"{header}\n{content}")
else:
formatted.append(f"{i+1}.{content}")
return "\n\n"+"\n\n".join(formatted) +"\n"get_collection_stats:获取向量库的统计信息,比如总文档数、各类型文件分布,可以用来监控或调试
def get_collection_stats() -> Dict[str, Any]:
try:
vector_store = get_vector_store()
count = vector_store._collection.count()
# 收集文件类型分布
file_types = {}
all_docs = vector_store._collection.get(include=['metadatas'])
if all_docs and all_docs['metadatas']:
for meta in all_docs['metadatas']:
if meta and 'file_type' in meta:
ft = meta['file_type']
file_types[ft] = file_types.get(ft, 0) + 1
return {
'total_documents':count,
'collection_name':CHROMA_COLLECTION_NAME,
'persist_directory':str(CHROMA_PERSIST_DIR),
'file_types':file_types
}
except Exception as e:
print(f"获取统计信息失败:{e}")
return {'error':str(e)}4.7 重建向量库
当数据更新后,需要重建向量库,rebuild_vector_store 函数强制重新创建,并且输出统计信息
def rebuild_vector_store():
try:
print("开始强制重建向量数据库...")
vector_store = get_vector_store(force_recreate=True)
stats = get_collection_stats()
print(f"向量数据库重建完成: {stats}")
return True
except Exception as e:
print(f"重建失败: {e}")
return False这样,每次数据预处理跑完后,可以调用这个函数重建,保证向量库最新
4.8 自测代码
if __name__ == "__main__":
print("=" * 60)
print("向量数据库模块测试")
print("=" * 60)
# 测试初始化
start = time.time()
vector_store = get_vector_store()
stats = get_collection_stats()
print(f"初始化成功,耗时: {time.time()-start:.2f}秒")
print(f"统计信息: {stats}")
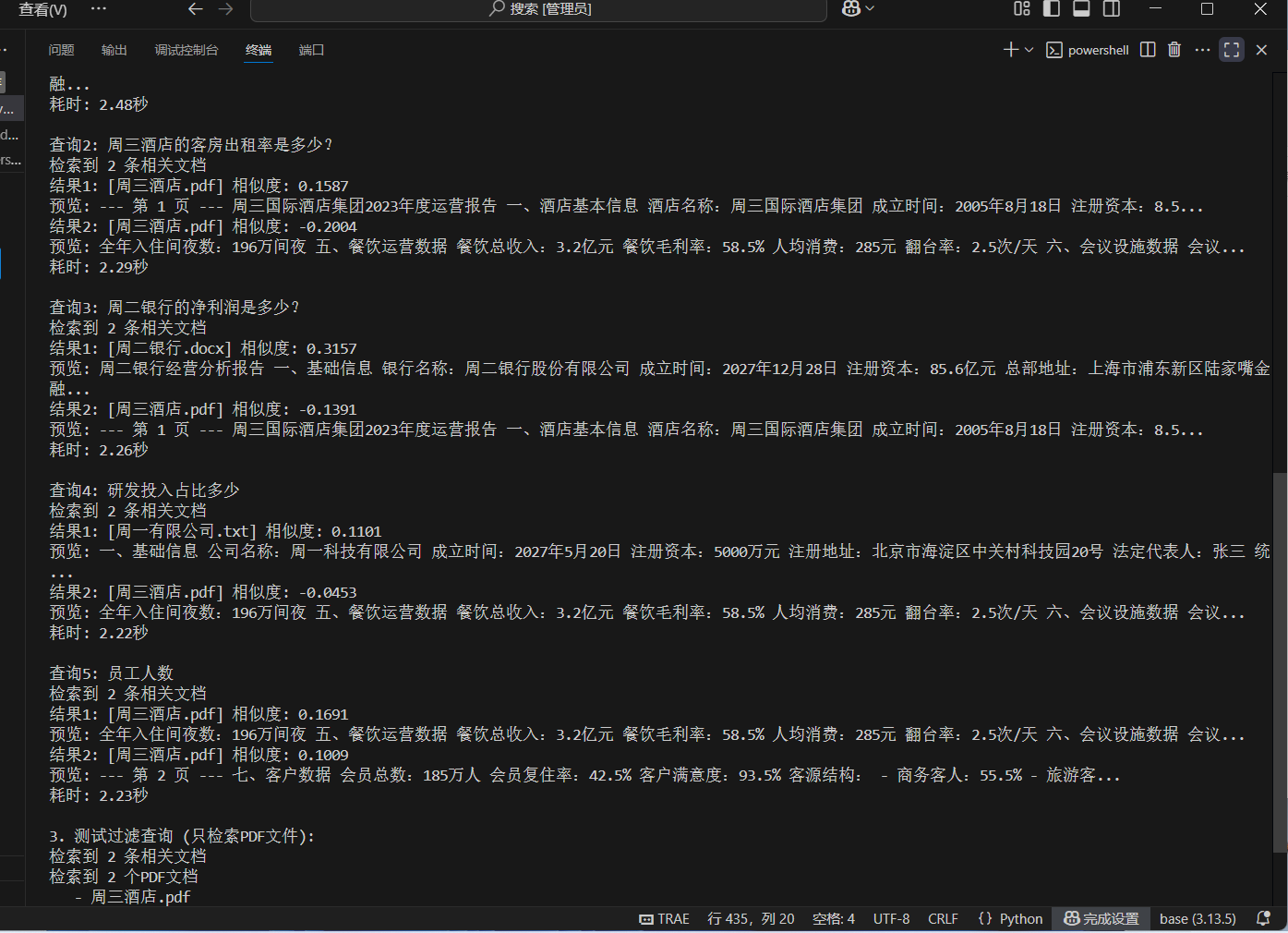
# 测试几个查询
test_queries = ["周一科技公司的注册资本是多少?", "周三酒店的客房出租率是多少?"]
for query in test_queries:
docs_with_scores = search_with_score(query, top_k=2)
if docs_with_scores:
for doc, score in docs_with_scores:
source = doc.metadata.get('source', '未知')
print(f"[{source}] 相似度: {1-score:.4f}")
else:
print("未找到")
# 测试过滤查询
docs = search_documents("酒店数据", filter_dict={"file_type": "pdf"})
print(f"过滤查询到{len(docs)}个PDF文档")运行结果:

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)