
星图平台镜像免配置优势:Qwen3-VL:30B预置flash-attn/vllm/ollama全栈优化
星图平台镜像免配置优势:Qwen3-VL:30B预置flash-attn/vllm/ollama全栈优化
你有没有想过,自己动手搭建一个能“看懂”图片、还能跟你“聊天”的智能助手?比如,在飞书群里发一张产品设计图,AI就能立刻分析出设计亮点;或者上传一张数据报表,它就能帮你解读关键趋势。
听起来很酷,但一想到要部署一个30B参数的多模态大模型,是不是瞬间头大?环境配置、依赖安装、网络调试……每一步都可能是个坑。
别担心,今天我要带你体验一种“开箱即用”的极致部署。我们利用CSDN星图AI云平台,借助其预置了全栈优化的 Qwen3-VL:30B 社区镜像,零基础、免配置,快速搭建一个私有化的多模态AI助手,并通过 Clawdbot 将其接入飞书。
整个过程,你几乎不用碰任何复杂的底层命令。我们聚焦在“用起来”,而不是“配起来”。下面,就跟我一起看看,星图平台的预置镜像到底能省多少事。
1. 为什么说“免配置”是最大优势?
在深入动手之前,我们先聊聊痛点。传统上,本地部署一个大模型,尤其是像 Qwen3-VL:30B 这样的“巨无霸”,需要跨越三座大山:
- 环境依赖地狱:CUDA版本、PyTorch版本、flash-attention2、vLLM……这些依赖环环相扣,版本不匹配就报错,一报错就是半天。
- 资源门槛高:30B模型需要48GB左右的显存,普通消费级显卡根本跑不动,自己搭建服务器成本高昂。
- 网络与安全配置繁琐:让服务能被公网安全访问,需要配置反向代理、SSL证书、防火墙规则,对新手极不友好。
而星图平台的社区镜像,直接帮我们搬走了这三座山。
- 全栈预优化:镜像里已经预装了匹配的CUDA、PyTorch,并集成了对推理速度至关重要的 flash-attention 和 vLLM 优化库。最省心的是,Ollama 也预装并配置好了,提供了一个即开即用的Web界面和标准化API。
- 按需使用算力:我们不需要购买昂贵的显卡,只需在星图平台按需租用符合要求的GPU实例(如48G显存),用完了可以关机,成本可控。
- 内网穿透与安全访问:平台自动为每个实例分配了唯一的、支持HTTPS的公网访问域名,无需自己折腾内网穿透或域名解析。
简单说,你拿到的是一个“拧上发条就能跑”的完整AI服务器。我们的任务,从“从零搭建环境”变成了“在现成环境上安装应用”。接下来,我们就开始这个“组装”过程。
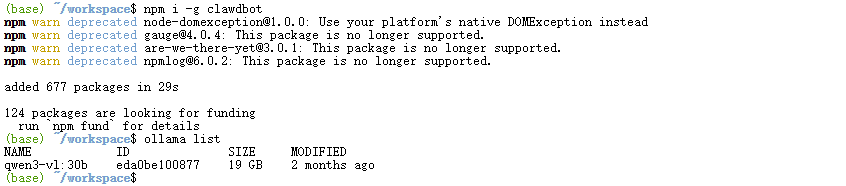
2. 三分钟启动你的Qwen3-VL:30B服务器
2.1 镜像选择与启动
登录星图AI云平台,进入控制台。在创建实例时,关键一步是选择镜像。
-
搜索镜像:在社区镜像列表中,直接搜索
Qwen3-vl:30b。你会发现官方已经提供了多个版本,我们选择那个标识清晰的镜像。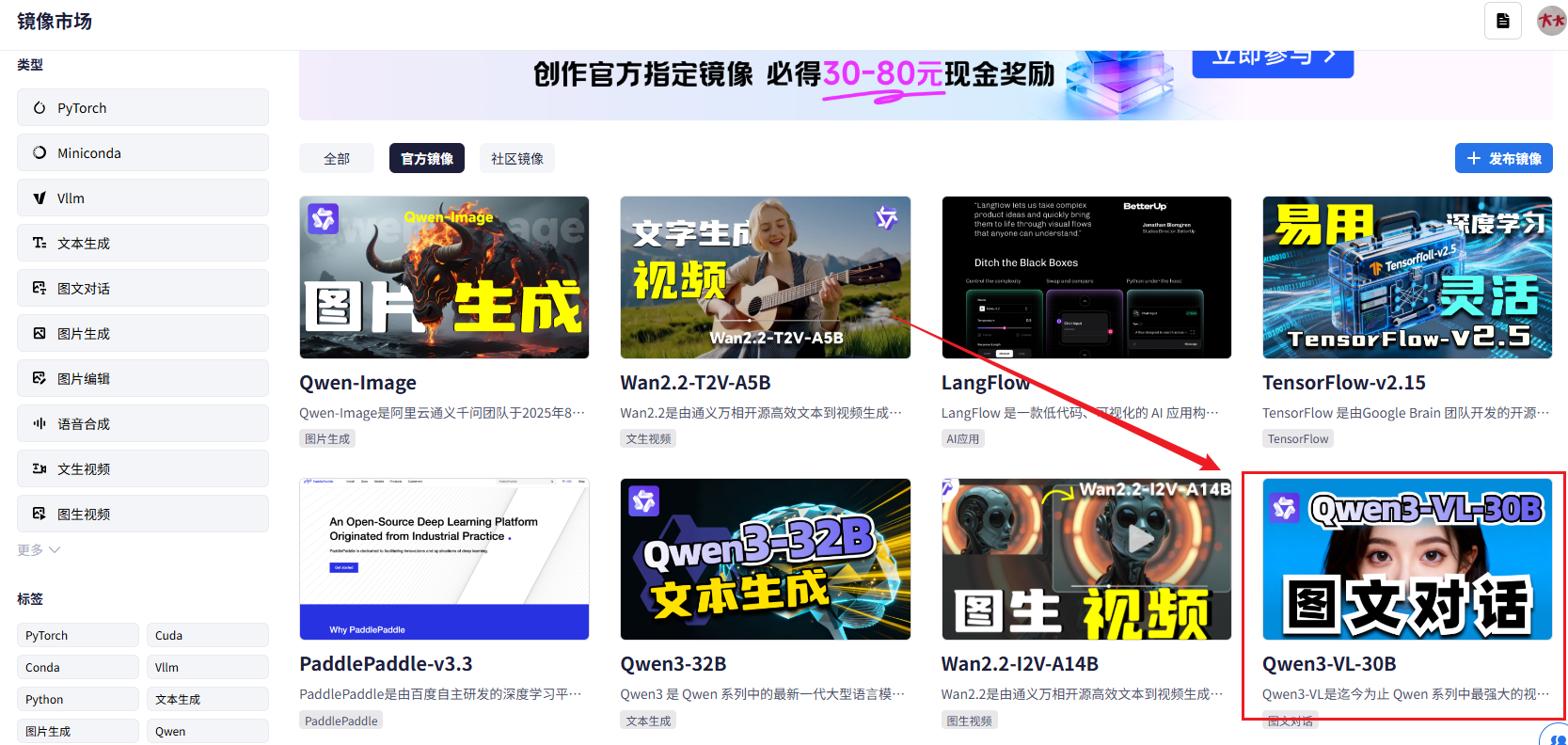
-
一键配置:由于该镜像明确要求48G显存,星图平台非常智能地默认预选了匹配的硬件配置。你基本上不需要调整任何参数,直接点击“创建”或“启动”即可。这避免了新手因配置不当导致模型无法运行的尴尬。
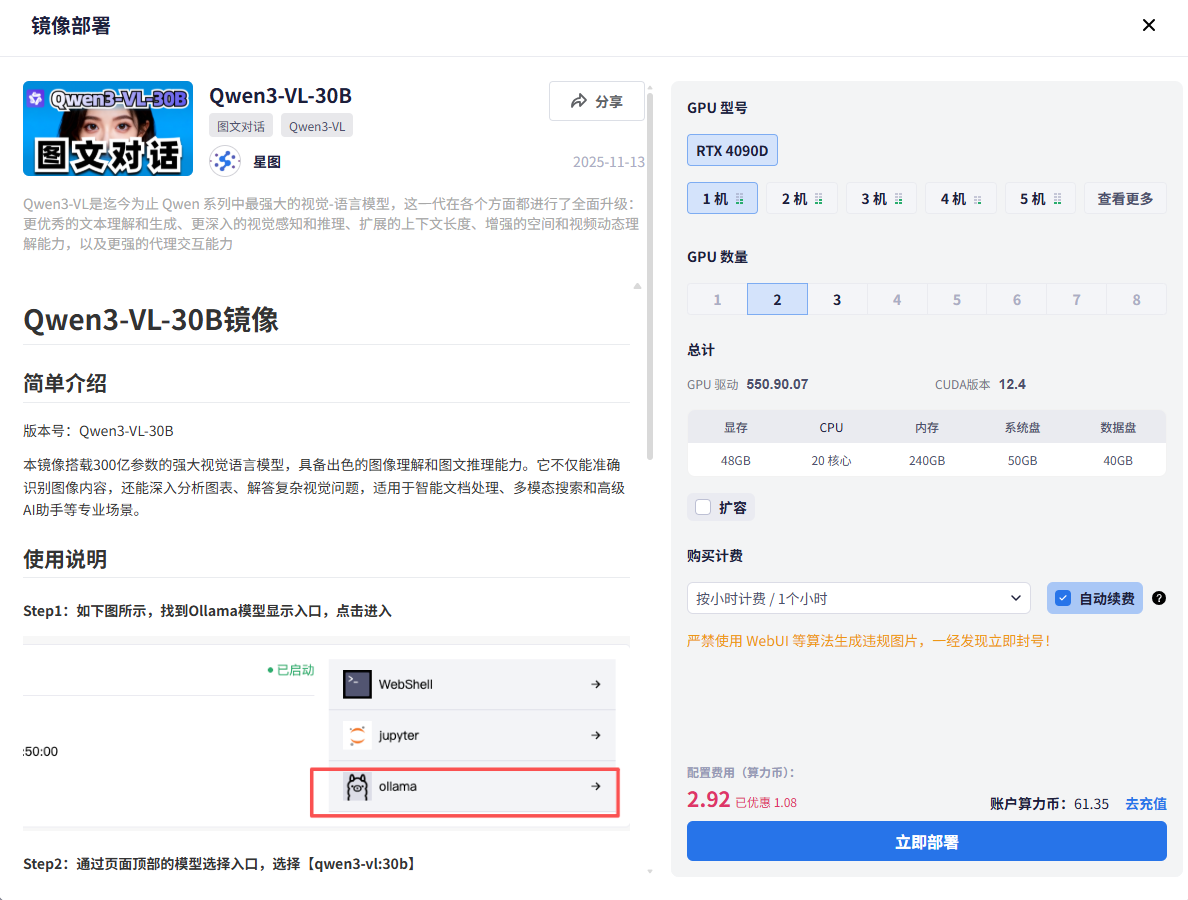
等待几分钟,实例启动成功。至此,一个搭载了全栈优化Qwen3-VL:30B模型的服务器就已经在云端运行起来了。你不需要执行任何 pip install 或 ollama pull 命令。
2.2 快速验证:模型真的能用了
实例启动后,如何验证一切正常?星图平台提供了最直接的入口。
-
Web界面直连:在实例控制台,找到一个名为 “Ollama 控制台” 的快捷方式。点击它,会直接在新标签页打开Ollama预装的Web UI界面。
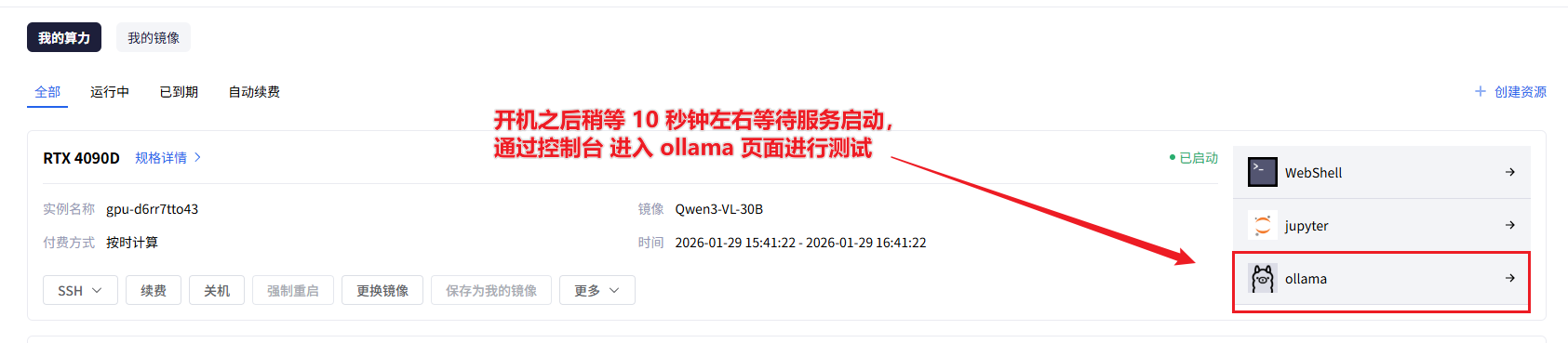
-
直观对话测试:在Web UI里,选择
qwen3-vl:30b模型,直接输入问题,比如上传一张图片并提问。如果它能正确理解和回答,说明模型服务运行完美。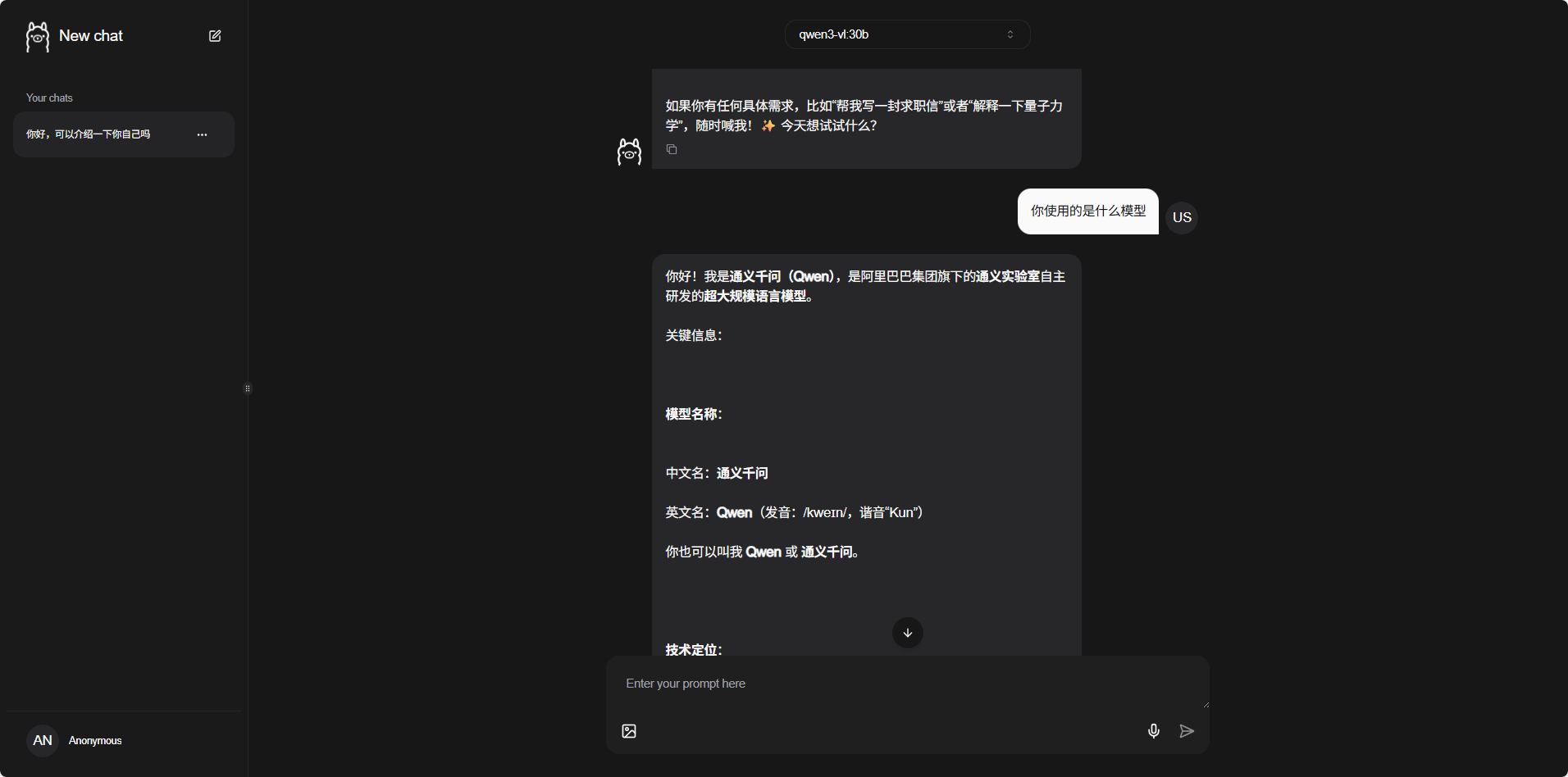
-
API接口测试:对于开发者,更关心API是否可用。星图平台为每个实例提供了固定的公网域名。你可以在本地用Python脚本快速测试一下连通性。
from openai import OpenAI
# 注意:base_url 需要替换成你的实例实际域名
client = OpenAI(
base_url="https://你的实例专属域名.web.gpu.csdn.net/v1", # 替换这里!
api_key="ollama" # Ollama 默认的API Key
)
try:
response = client.chat.completions.create(
model="qwen3-vl:30b",
messages=[{"role": "user", "content": "你好,请介绍一下你自己。"}]
)
print("API调用成功!回复内容:")
print(response.choices[0].message.content)
except Exception as e:
print(f"连接失败,错误信息: {e}")
看到成功的回复,是不是感觉有点不可思议? 一个30B的多模态大模型,从选择到可用,只花了你选择镜像和等待启动的时间。这就是预置优化镜像带来的“免配置”魔力。
3. 安装与配置Clawdbot:连接AI与飞书的桥梁
模型服务好了,但它还是个“孤岛”。我们需要一个机器人框架来管理它、连接它到飞书这样的协作平台。这里我们选择 Clawdbot,它功能强大且配置相对直观。
3.1 一键安装Clawdbot
得益于星图镜像预装了Node.js和npm,安装Clawdbot只需要一行命令:
npm i -g clawdbot
3.2 初始化配置向导
安装完成后,运行初始化命令,它会以交互式向导引导你完成基本设置:
clawdbot onboard
在向导中,对于大多数设置,我们可以先按回车选择默认值或“跳过”。我们的核心配置(比如模型连接)将留到后面通过修改配置文件来完成,这样更灵活。向导完成后,Clawdbot的基础框架就搭好了。
3.3 启动网关并解决访问问题
启动Clawdbot的网关服务,它将在18789端口提供Web控制面板。
clawdbot gateway
启动后,你需要通过星图实例的公网域名访问这个控制面板。将你之前测试API用的域名中的端口号(如11434)替换为 18789。
但是,你可能会遇到第一个小挑战:页面打开是空白的。这是因为Clawdbot默认出于安全考虑,只允许本地(127.0.0.1)访问。我们需要修改配置,让它允许公网访问。
解决方法:修改Clawdbot配置文件
-
打开配置文件:
vim ~/.clawdbot/clawdbot.json -
找到
gateway部分,进行以下关键修改:"bind": "loopback"改为"bind": "lan"(允许局域网/公网访问)。- 在
"auth"部分设置一个自定义的Token,例如"token": "csdn"(用于控制面板登录)。 - 添加
"trustedProxies": ["0.0.0.0/0"],信任所有代理转发(因为请求经过星图平台网关)。
修改后的片段如下:
"gateway": { "mode": "local", "bind": "lan", "port": 18789, "auth": { "mode": "token", "token": "csdn" }, "trustedProxies": ["0.0.0.0/0"], "controlUi": { "enabled": true, "allowInsecureAuth": true } } -
保存退出,并重启Clawdbot网关服务(先按
Ctrl+C停止,再重新运行clawdbot gateway)。
现在,刷新浏览器,应该能看到Clawdbot的登录界面了。输入你刚才设置的Token(csdn),就能进入控制面板。
4. 核心步骤:让Clawdbot调用你的私有Qwen3-VL模型
现在我们有并行的两个服务:运行在11434端口的Ollama(提供Qwen3-VL模型),和运行在18789端口的Clawdbot网关。最后一步,也是最重要的一步,就是告诉Clawdbot:“别用你自带的或者网上的模型了,去调用我本地11434端口的那个大家伙。”
4.1 配置模型供应商
再次编辑 ~/.clawdbot/clawdbot.json 文件,这次我们要修改 models 和 agents 部分。
-
添加自定义Ollama供应商:在
models.providers对象里,新增一个配置块(例如叫my-ollama),指向本地Ollama服务的API地址。 -
设置默认模型:在
agents.defaults中,将主模型设置为刚定义的my-ollama/qwen3-vl:30b。
关键配置如下:
"models": {
"providers": {
"my-ollama": {
"baseUrl": "http://127.0.0.1:11434/v1", // 本地Ollama服务
"apiKey": "ollama", // Ollama默认API Key
"api": "openai-completions", // 使用OpenAI兼容的API格式
"models": [
{
"id": "qwen3-vl:30b", // 模型ID,必须和Ollama中的名称一致
"name": "Local Qwen3 30B", // 在Clawdbot中显示的名称
"contextWindow": 32000 // 模型的上下文长度
}
]
}
// ... 其他可能的供应商配置
}
},
"agents": {
"defaults": {
"model": {
"primary": "my-ollama/qwen3-vl:30b" // 指定默认使用我们的私有模型
}
}
}
4.2 最终验证:对话与资源监控
保存配置文件后,需要重启Clawdbot网关服务以使配置生效。
重启后,打开Clawdbot控制面板的 Chat 页面。发送一条消息,比如“请写一首关于星空的短诗”。
同时,打开一个新的终端窗口,运行 watch nvidia-smi 命令,实时监控GPU的状态。
当你看到以下两点,就证明大功告成了:
-
Clawdbot Chat页面:收到了来自AI的流畅回复。
-
GPU监控窗口:
nvidia-smi显示GPU显存占用显著上升(例如从几GB增加到40GB以上),并且有一个Python进程(通常是vLLM或Ollama的backend)在占用显存。这直观地证明了Clawdbot的请求确实触发了我们私有Qwen3-VL:30B模型的推理计算。
5. 总结与展望
回顾整个流程,我们真正亲手敲的命令并不多,核心是安装Clawdbot和修改它的两个配置文件。最复杂、最耗时的模型环境部署、依赖安装、性能优化(flash-attn, vLLM)和网络暴露,全部由 CSDN星图AI平台的预置镜像 代劳了。
这种“免配置”优势带来的直接好处是:
- 门槛极低:AI新手也能快速拥有一个私有化顶级大模型。
- 聚焦创新:你可以把时间和精力从“环境调试”转移到“应用开发”上,比如设计更酷的机器人技能。
- 稳定可靠:官方镜像经过测试和优化,避免了自建环境的各种玄学问题。
至此,我们已经成功搭建了后端核心:私有化Qwen3-VL:30B模型 + Clawdbot智能网关。它已经是一个可以通过Web界面对话的智能助手了。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 4
4 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)