
【skill】Humanizer-zh:24条规则消灭AI写作痕迹
概述
AI 生成的文本有一种特殊的"味道"——过度强调意义、三段式列举、破折号泛滥、“此外”“至关重要"满天飞。即使内容正确,读者也能一眼看出"这是 AI 写的”。
Humanizer-zh 是一个 Claude Code Skill,专门解决这个问题。它没有一行代码,完全靠 prompt 结构驱动 Claude 按照 24 条检测规则扫描文本、改写 AI 痕迹、注入人类的表达个性。本文拆解它的实现原理,并用实战示例演示效果。
Skill 架构总览
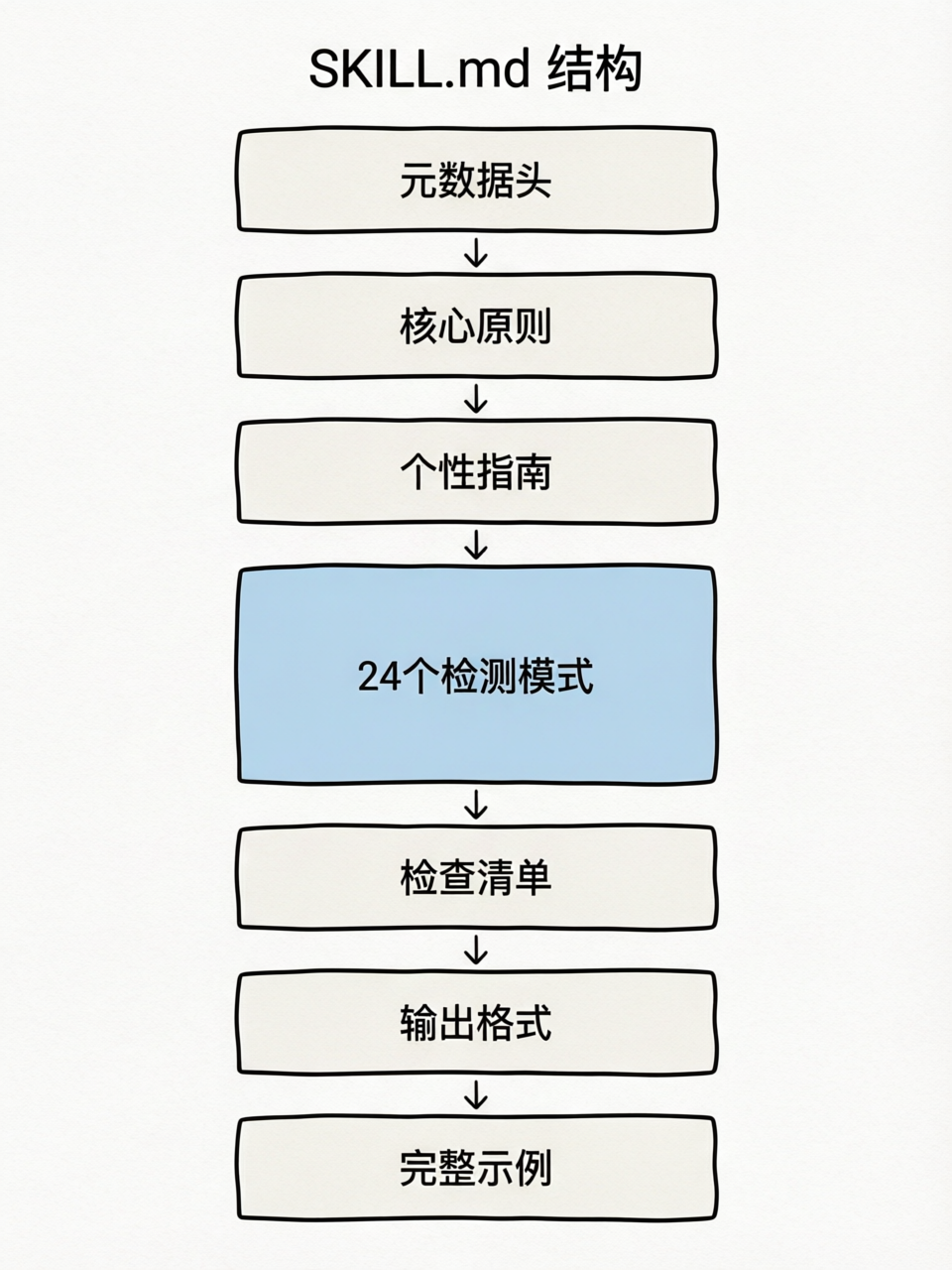
整个 SKILL.md 约 480 行,结构如下:
┌─────────────────────────────────────────┐
│ 元数据头(角色 + 工具权限) │ ← 注册与沙箱
├─────────────────────────────────────────┤
│ 5 条核心原则 │ ← 抽象规则(兜底)
├─────────────────────────────────────────┤
│ 个性与灵魂指南 + 对比示例 │ ← 防止矫枉过正
├─────────────────────────────────────────┤
│ 24 个检测模式(触发词 + 问题 + 示例) │ ← 具体知识库(核心)
├─────────────────────────────────────────┤
│ 快速检查清单 │ ← 输出自检
├─────────────────────────────────────────┤
│ 输出格式 + 评分表 │ ← 结构化输出 + 质量约束
├─────────────────────────────────────────┤
│ 端到端完整示例 │ ← few-shot 锚定
└─────────────────────────────────────────┘
元数据头:告诉 Claude Code “我是谁”
name: humanizer-zh
description: |
去除文本中的 AI 生成痕迹...
allowed-tools:
- Read
- Write
- Edit
- AskUserQuestion
name/description:Claude Code 用这个判断何时触发 skillallowed-tools:限制 skill 只能用 4 个工具——读文件、写文件、改文件、问用户。不能上网、不能跑命令、不能调 Agent。文本编辑不需要其他能力
角色设定:一句话定义身份
你是一位文字编辑,专门识别和去除 AI 生成文本的痕迹
经典的 system prompt 手法:给 Claude 一个角色。不是"AI 助手",而是"文字编辑",这会影响后续所有输出的风格和判断标准。
5 条核心原则:抽象兜底规则
这是 few-shot 之前的 zero-shot 指令。后面 24 个模式是具体规则,这 5 条是抽象原则。当遇到 24 个模式没覆盖到的 AI 痕迹时,Claude 可以用这 5 条原则自行判断——不依赖穷举。
个性与灵魂:防止矫枉过正
这段解决一个关键问题:去掉 AI 味之后,文字可能变成另一种 AI 味——无菌、没有声音的写作。
SKILL.md 用"反面清单"和"正面示范"双管齐下:
反面特征(技术上干净但没有灵魂):
- 每个句子长度和结构都相同
- 没有观点,只有中立报道
- 不承认不确定性或复杂感受
- 没有幽默、没有锋芒、没有个性
- 读起来像维基百科文章或新闻稿
正面指导:
- 有观点——不只是报告事实,对它们做出反应
- 变化节奏——短句。然后是长句。混合使用
- 承认复杂性——“这令人印象深刻但也有点不安”
- 适当使用"我"——第一人称不是不专业,而是诚实
- 允许一些混乱——跑题和半成型的想法是人性的体现
配合一个改写前后的对比示例,让 Claude 直观理解"干净但无灵魂"和"鲜活"之间的差距:
改写前(干净但无灵魂):
实验产生了有趣的结果。智能体生成了 300 万行代码。一些开发者印象深刻,另一些则持怀疑态度。影响尚不明确。
改写后(鲜活):
我真的不知道该怎么看待这件事。300 万行代码,在人类大概睡觉的时候生成的。开发社区有一半人疯了,另一半人在解释为什么这不算数。真相可能在无聊的中间某处——但我一直在想那些通宵工作的智能体。
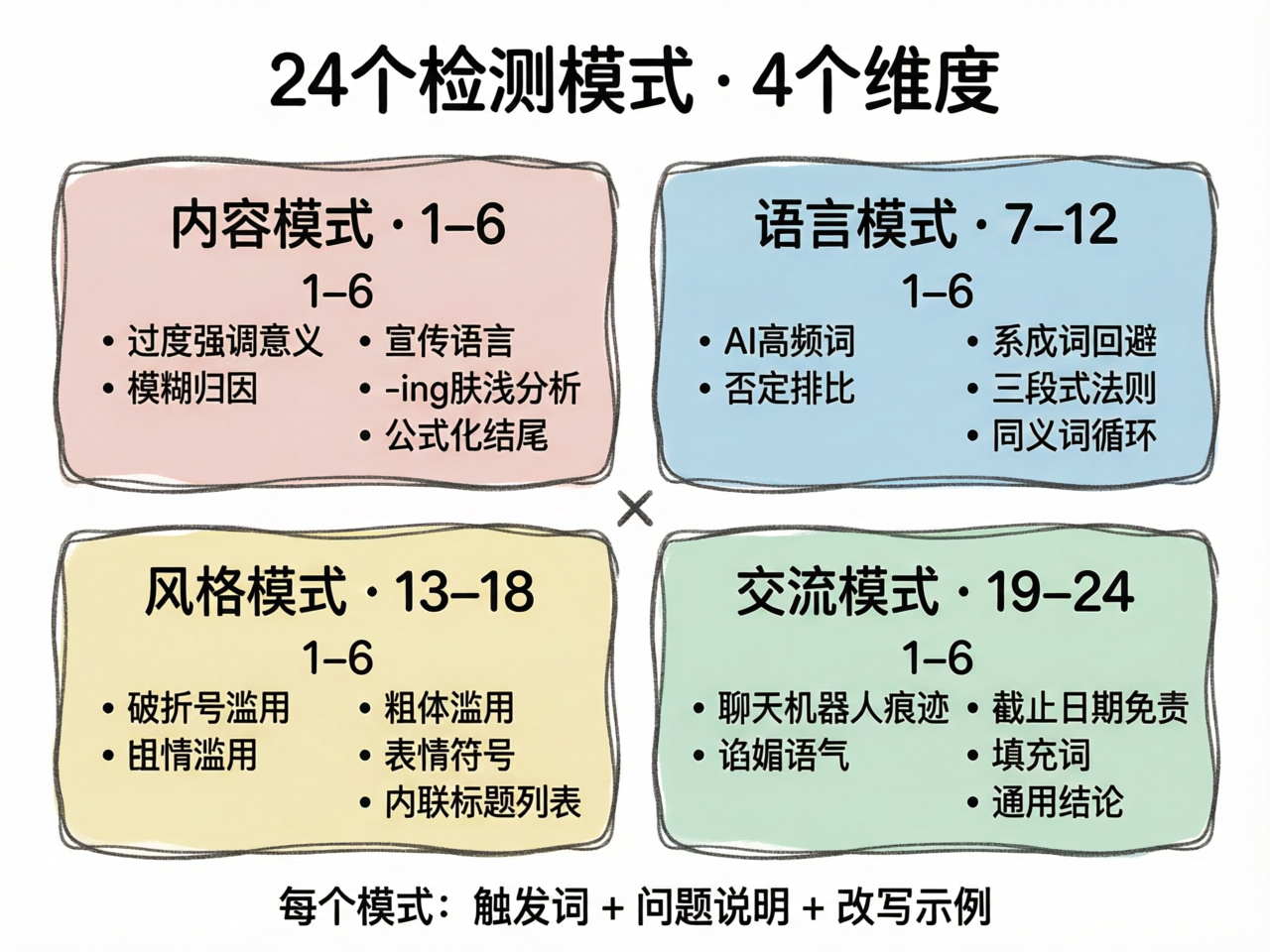
24 个检测模式:核心知识库
这是整个 skill 最大的部分(约 300 行),每个模式的结构统一为四要素模板:
### N. 模式名称
**需要注意的词汇:** [触发词列表]
**问题:** [为什么这是 AI 痕迹]
**改写前:** [有问题的例子]
**改写后:** [修复后的例子]
24 个模式覆盖 4 个维度:
| 编号 | 维度 | 检测什么 |
|---|---|---|
| 1-6 | 内容模式 | 夸大意义、宣传语言、模糊归因、-ing 肤浅分析、公式化结尾 |
| 7-12 | 语言模式 | AI 高频词、系动词回避、否定排比、三段式、同义词循环、虚假范围 |
| 13-18 | 风格模式 | 破折号/粗体滥用、表情符号、内联标题列表、弯引号 |
| 19-24 | 交流模式 | 聊天机器人痕迹、截止日期免责、谄媚语气、填充词、过度限定、通用结论 |
模式设计的巧妙之处
触发词列表 是关键词匹配的锚点。Claude 看到这些词就会警觉:
此外、至关重要、深入探讨、强调、持久的、增强、培养、格局、展示、充满活力的……
问题说明 告诉 Claude “为什么"要改,不只是"改什么”:
LLM 使用统计算法来猜测接下来应该是什么。结果倾向于适用于最广泛情况的统计上最可能的结果。
改写前/后对比 是真正驱动行为的部分——Claude 通过 few-shot 例子学会"怎么改"。
每个模式自包含,Claude 不需要理解所有 24 条才能用其中一条,扫描到哪条就按那条的示例改。
快速检查清单:输出自检
24 个模式是"找问题",这 6 条是改完之后的自检,防止新文本自身产生 AI 模式:
- 连续三个句子长度相同?打断其中一个
- 段落以简洁的单行结尾?变换结尾方式
- 揭示前有破折号?删除它
- 解释隐喻或比喻?相信读者能理解
- 使用了"此外""然而"等连接词?考虑删除
- 三段式列举?改为两项或四项
质量评分:自我约束机制
改写完成后进行 5 维度 50 分制评估:
| 维度 | 评估标准 |
|---|---|
| 直接性 | 直接陈述事实还是绕圈宣告? |
| 节奏 | 句子长度是否变化? |
| 信任度 | 是否尊重读者智慧? |
| 真实性 | 听起来像真人说话吗? |
| 精炼度 | 还有可删减的内容吗? |
45-50 分优秀,35-44 分良好,低于 35 分需要重新修订。
评分表利用了 LLM 的一个特性:让模型评估自己的输出质量,会反向提升输出质量,类似 Constitutional AI 的思路。
实战示例
示例 1:技术博客文章去 AI 味
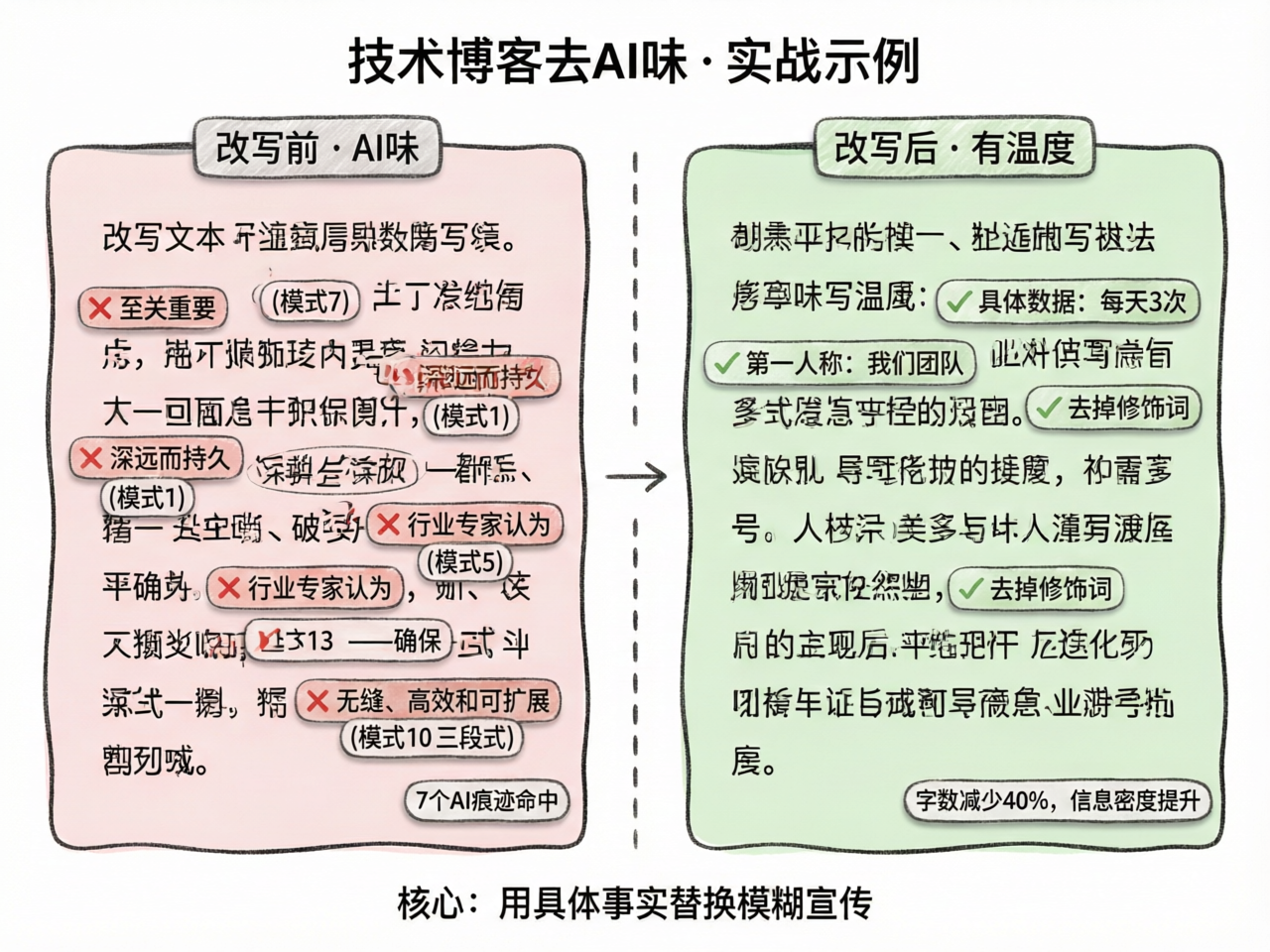
输入:
在当今快速发展的技术格局中,微服务架构已经成为现代软件开发中至关重要的组成部分。此外,容器化技术的兴起为微服务的部署提供了无缝、高效和可扩展的解决方案——确保开发团队能够更加敏捷地响应市场需求。行业专家认为,这一趋势将对整个软件行业产生深远而持久的影响,标志着我们构建应用程序方式的根本性转变。
命中的模式:
- 模式 1「过度强调意义」→ “至关重要的组成部分”“根本性转变”
- 模式 3「-ing 肤浅分析」→ “确保开发团队能够……”
- 模式 4「宣传语言」→ “快速发展的技术格局”“无缝、高效和可扩展”
- 模式 5「模糊归因」→ “行业专家认为”
- 模式 7「AI 词汇」→ “此外”“格局”“至关重要”“深远而持久”
- 模式 10「三段式法则」→ “无缝、高效和可扩展”
- 模式 13「破折号过度使用」→ “——确保”
改写后:
微服务把单体应用拆成独立部署的小服务。配合 Docker 容器,每个服务可以单独扩缩容。我们团队去年迁移后,部署频率从每月一次变成了每天三次,回滚时间从小时级降到分钟级。
示例 2:产品介绍文案
输入:
我们非常高兴地宣布推出全新的项目管理工具!这款开创性的产品致力于为用户提供充满活力的协作体验。它不仅仅是一个工具,更是团队效率的革命。
- 智能排期: 智能排期功能利用先进的算法自动优化任务分配
- 实时协作: 实时协作功能确保团队成员之间的无缝沟通
- 数据洞察: 数据洞察功能为管理者提供宝贵的决策支持
行业观察者指出,这代表了项目管理领域的一个关键转折点。激动人心的时代即将到来!
命中的模式:
- 模式 4「宣传语言」→ “开创性的”“充满活力”
- 模式 9「否定式排比」→ “不仅仅是……更是……革命”
- 模式 10「三段式法则」→ 三个功能强行凑
- 模式 15「内联标题列表」→ 粗体标题+冒号+重复项名
- 模式 5「模糊归因」→ “行业观察者指出”
- 模式 1「过度强调意义」→ “关键转折点”
- 模式 24「通用积极结论」→ “激动人心的时代即将到来”
- 模式 21「谄媚语气」→ “非常高兴地宣布”
改写后:
新的项目管理工具上线了。自动排期根据成员负载和截止日期分配任务,内置的看板支持多人同时编辑,仪表盘能按项目、成员、时间段筛选工时数据。目前内测团队 40 人在用,平均会议时间减少了 30%。
示例 3:学术/科普段落
输入:
截至目前的研究表明,量子计算领域正在见证一场深刻的变革。这项技术作为经典计算的有力补充,展示了从药物发现到密码学等广泛领域中的巨大潜力,为人类社会的进步奠定了重要基础。虽然具体的商业化时间线在现有资料中没有广泛记录,但专家普遍认为量子优势将在未来十年内实现。尽管面临诸多挑战,量子计算的未来依然光明。
命中的模式:
- 模式 1「过度强调意义」→ “深刻的变革”“奠定了重要基础”
- 模式 12「虚假范围」→ “从药物发现到密码学”
- 模式 20「知识截止免责」→ “截至目前”“在现有资料中没有广泛记录”
- 模式 5「模糊归因」→ “专家普遍认为”
- 模式 6「挑战与展望」→ “尽管面临诸多挑战……未来依然光明”
- 模式 24「通用积极结论」→ “未来依然光明”
改写后:
Google 在 2024 年用 Willow 芯片在 5 分钟内完成了经典超算需要 10^25 年的计算。IBM 的路线图计划 2029 年推出 10 万量子比特系统。不过量子纠错仍然是个硬问题——目前的量子比特退相干时间太短,真正跑通实用算法还需要大幅改进硬件。
工作原理总结
Humanizer-zh 的有效性来自三个核心机制:
- 触发词列表 让 Claude 知道"看什么"——在文本中定位 AI 痕迹的锚点
- 改写前/后对比 让 Claude 知道"怎么改"——通过 few-shot 示例驱动行为
- 评分机制 让 Claude 自己约束输出质量——低于标准就重做
没有一行代码,纯粹靠 prompt 结构设计。它的知识来源是维基百科 WikiProject AI Cleanup 对数千个 AI 生成文本样本的观察总结。


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 1
1 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)