
AI 编程 Agent 进入工作流后,开发者要先设计任务边界,而不是直接让它写代码
一、热点发生了什么:AI 编程工具正在从“补全代码”变成“接管任务”
过去开发者使用 AI 编程工具,最常见的方式是补全一段代码、解释一个报错、生成一个函数、写一段测试用例。
这类用法本质上还是“问答式辅助”:开发者提问题,AI 给片段,开发者自己复制、修改、运行、提交。
但最近几个热点说明,AI 编程工具正在往更深的方向走。
OpenAI 近期强调 Codex 不再只是 coding tool,而是开始进入更多角色、工具和工作流。它可以帮助团队构建内部应用、准备材料、创建 dashboard,把自然语言任务转成更具体的工作产物。与此同时,GitHub Copilot 也在推动 Agent tasks REST API 这类能力,让 AI Agent 不只是 IDE 里的对话窗口,而是可以被任务系统调用、被流程管理、被工程链路接入。
这意味着一个变化:
AI 编程工具不再只是“帮我写一段代码”,而是开始变成“帮我完成一个开发任务”。
对开发者来说,这件事值得兴奋,但也更需要谨慎。
因为代码补全出错,通常只是一个局部问题;而 Agent 接入工作流后,如果任务边界不清、输入不完整、输出不校验,影响的可能是需求实现、分支质量、测试覆盖、线上稳定性,甚至团队协作方式。
所以这篇文章不讨论“AI 写代码有多强”,而讨论一个更工程化的问题:如何把 AI 编程 Agent 接进开发流程,同时保证任务可审计、结果可验证、风险可回滚。
二、为什么开发者要关心:Agent 写代码不是问题,问题是它会改变交付链路
很多开发者第一次接触 Codex、Copilot Agent、Cursor、Claude Code 这类工具时,会先测试它会不会写代码:能不能生成 CRUD,能不能修 Bug,能不能补单元测试,能不能读懂老项目,能不能根据报错改配置。
这些测试当然有用,但还不够。
当 AI 只是写一个函数时,你可以把它当高级代码补全。当 AI 能根据任务描述创建分支、修改多个文件、生成测试、提交 PR 时,它就变成了开发流程的一部分。
这时候要关注的不是“它能不能写”,而是:它是否理解任务边界;是否知道哪些文件不能改;是否能说明修改原因;是否能生成可运行的验证步骤;是否能把风险暴露出来;输出是否方便 Code Review;是否能被 CI、测试、权限、日志系统约束。
Agent 的能力越强,团队越不能只靠信任;必须靠流程约束。
三、最容易被误解的地方:把 Prompt 当需求文档
很多团队在试用 AI 编程工具时,会直接给一句任务:
帮我优化登录模块,顺便把异常处理也完善一下。
这句话看起来像需求,但对 AI Agent 来说边界非常模糊。什么叫优化?是性能优化、代码结构优化、交互体验优化,还是安全策略优化?异常处理要覆盖哪些异常?是否允许改数据库结构?是否允许改接口返回格式?是否需要兼容旧客户端?是否需要补测试?是否有不能动的文件?
如果这些信息没有说清楚,AI 可能会做出“看起来很积极”的修改:改了多个文件,重构了逻辑,顺手调整了接口,甚至把原来依赖的错误码格式改掉。
从表面看,它完成了任务。从工程角度看,它可能引入了新的风险。
开发者要记住一句话:Prompt 不是一句需求口号,而应该是一份轻量级任务契约。
AI 编程 Agent 的 Prompt,至少要包含目标、范围、输入、限制、输出、验证方式和禁止事项。
四、真实使用场景:让 AI Agent 修复接口分页 Bug
假设你维护一个后端项目,线上反馈“订单列表接口翻到第 3 页后偶尔出现重复数据”。这是一个典型的编程场景常用任务:有明确问题、有代码上下文、有验证方法,也有潜在风险。
如果直接把任务丢给 AI:
修复订单列表分页重复的问题。
AI 可能会尝试修改排序字段、分页参数、SQL 查询,甚至改动缓存逻辑。它未必知道问题到底出在排序稳定性、游标分页、数据库索引,还是前端重复请求。
更合理的做法,是把任务拆成三层:诊断层先让 AI 分析可能原因,不允许修改代码;方案层让 AI 给出 2–3 个修复方案,并说明影响范围;实现层在选定方案后,再允许它修改指定文件并补充测试。
这就是把 AI Agent 从“自由发挥”变成“受控执行”。
五、推荐工作流:AI Agent 三段式接入开发流程
| 阶段 | AI 可以做什么 | 人要做什么 | 产物 | 风险控制 |
|---|---|---|---|---|
| 任务澄清 | 读取需求、列出疑问、识别上下文缺口 | 补充业务规则和限制条件 | 任务说明 | 避免误解需求 |
| 影响分析 | 扫描相关代码、列出可能修改点 | 判断是否允许修改这些模块 | 影响范围清单 | 避免乱改核心逻辑 |
| 方案设计 | 给出多种实现方案和权衡 | 选择方案,确认边界 | 技术方案 | 避免过度重构 |
| 代码实现 | 修改指定文件、生成测试 | Review 代码和测试 | Patch / PR | 避免不可控变更 |
| 验证回归 | 生成验证步骤、补充测试命令 | 运行测试,检查结果 | 验证报告 | 避免假通过 |
| 合并上线 | 生成 PR 描述和风险说明 | 人工审批、合并、发布 | PR / Release Note | 保留责任边界 |
这套流程的核心不是让 AI 少做事,而是让 AI 在正确的位置做事。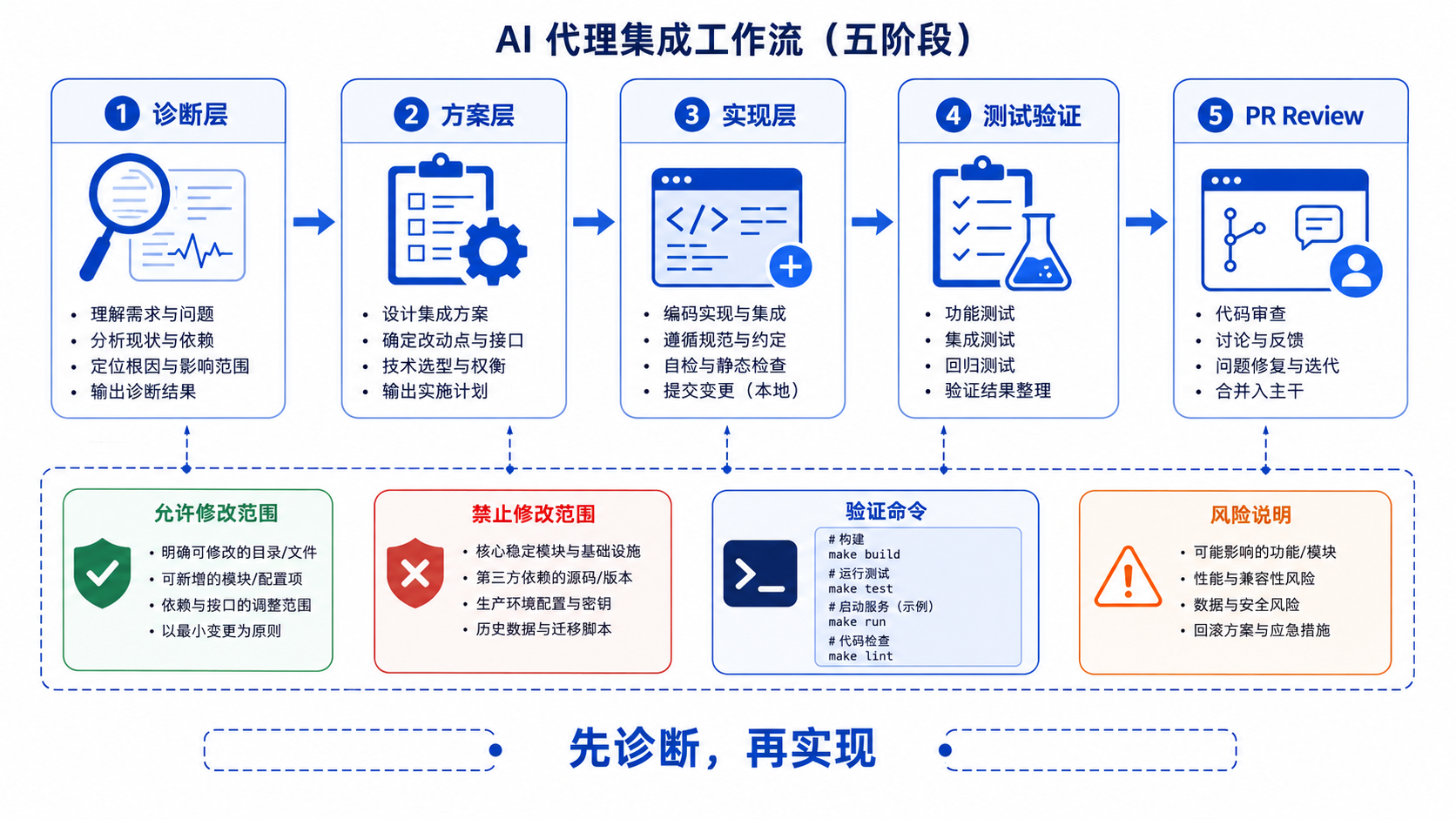
六、Prompt 块 1:诊断阶段,不允许 AI 直接改代码
你现在是一个代码诊断助手,不要直接修改代码。
任务背景:
订单列表接口在翻到第 3 页后,偶尔出现重复订单数据。
项目技术栈:
- 后端:Node.js + Express
- 数据库:PostgreSQL
- ORM:Prisma
- 分页方式:page + pageSize
- 当前排序:createdAt desc
请你完成以下任务:
1. 根据分页、排序、查询条件、缓存和并发请求几个方向,列出可能原因。
2. 指出每个原因对应需要检查的文件或逻辑位置。
3. 不要生成修复代码。
4. 不要假设数据库表结构,缺少信息时请明确提出需要补充的上下文。
5. 最后输出一个“下一步排查清单”。
输出格式:
- 可能原因
- 需要检查的位置
- 需要补充的信息
- 下一步排查清单
这个 Prompt 的重点是“不允许直接修改代码”。很多团队用 AI 出问题,不是因为 AI 不会写代码,而是因为还没诊断清楚,就让 AI 进入实现阶段。诊断和实现应该分开。
七、输入示例:给 AI 的最小上下文
// src/routes/orders.js
router.get('/orders', async (req, res) => {
const page = Number(req.query.page || 1);
const pageSize = Number(req.query.pageSize || 20);
const orders = await prisma.order.findMany({
where: {
status: 'PAID'
},
orderBy: {
createdAt: 'desc'
},
skip: (page - 1) * pageSize,
take: pageSize
});
res.json({
page,
pageSize,
data: orders
});
});
给 AI 的输入不应该只是一句“有重复数据”,而应该补充可验证现象:
补充上下文:
1. 订单表中 createdAt 可能存在相同时间戳。
2. 用户反馈主要发生在 page=3 或 page=4。
3. 相同请求参数重复调用时,偶尔顺序不同。
4. 当前没有二级排序字段。
5. 不希望改接口返回结构。
6. 可以修改查询排序逻辑,可以新增单元测试。
这类信息可以明显降低 AI 误判概率。
八、输出示例:AI 理想输出应该长什么样
可能原因:
当前分页使用 skip/take,并且只按 createdAt desc 排序。
如果多条订单的 createdAt 完全相同,数据库在相同排序值之间的返回顺序可能不稳定。
当第 2 页和第 3 页边界处存在多个 createdAt 相同的订单时,就可能出现重复或遗漏。
建议方案:
在 createdAt desc 后增加稳定的二级排序字段,例如 id desc。
这样可以保证排序结果稳定。
影响范围:
只影响订单列表接口的排序稳定性,不改变接口返回结构。
建议修改:
orderBy 从单字段排序改为多字段排序。
验证方式:
1. 构造多条 createdAt 相同的订单。
2. 连续请求 page=1、page=2、page=3。
3. 检查不同页之间是否存在重复 id。
然后再给代码修改建议:
const orders = await prisma.order.findMany({
where: {
status: 'PAID'
},
orderBy: [
{ createdAt: 'desc' },
{ id: 'desc' }
],
skip: (page - 1) * pageSize,
take: pageSize
});
这个修改看起来很小,但符合工程要求:没有改接口结构,没有改业务状态,没有引入复杂重构,有明确原因,有验证方法。
九、Prompt 块 2:实现阶段,限定文件和输出格式
你现在进入代码实现阶段。
任务:
修复订单列表接口分页时可能出现重复数据的问题。
已确认原因:
当前只按 createdAt desc 排序。当多条订单 createdAt 相同时,数据库返回顺序可能不稳定,导致分页边界出现重复或遗漏。
允许修改:
- src/routes/orders.js
- tests/orders.pagination.test.js
禁止修改:
- 数据库 schema
- 接口返回结构
- 订单状态逻辑
- 鉴权逻辑
- 与订单无关的模块
实现要求:
1. 将订单查询排序改为稳定排序。
2. 保持 createdAt desc 为主排序。
3. 增加 id desc 作为二级排序。
4. 补充一个测试用例,覆盖 createdAt 相同情况下分页不重复。
5. 输出修改说明、测试说明和潜在风险。
输出格式:
- 修改文件列表
- 代码修改片段
- 测试用例
- 验证命令
- 风险说明
这个 Prompt 的关键点是“允许修改”和“禁止修改”。AI Agent 在项目中最危险的行为之一,是为了完成目标而过度扩大修改范围。
十、错误示例:不要让 AI 这样改
router.get('/orders', async (req, res) => {
const allOrders = await prisma.order.findMany({
where: {
status: 'PAID'
}
});
const sortedOrders = allOrders.sort((a, b) => {
return new Date(b.createdAt) - new Date(a.createdAt);
});
const page = Number(req.query.page || 1);
const pageSize = Number(req.query.pageSize || 20);
const data = sortedOrders.slice((page - 1) * pageSize, page * pageSize);
res.json({
page,
pageSize,
data
});
});
这段代码看起来也解决了排序问题,但工程上很危险:把数据库分页变成了内存分页;数据量大时性能会明显下降;没有稳定的二级排序;查询成本不可控;可能引发线上接口超时;修改方向偏离原始问题。
十一、技术边界:AI Agent 适合做什么,不适合做什么
| 任务类型 | 是否适合交给 AI | 原因 |
|---|---|---|
| 生成单元测试 | 适合 | 输入输出明确,结果可运行验证 |
| 修复局部 Bug | 适合,但要限定范围 | 有明确现象和验证方式 |
| 重构小函数 | 适合 | 影响范围较小 |
| 生成接口文档 | 适合 | 可根据代码结构提取 |
| 扫描潜在异常分支 | 适合 | AI 擅长列遗漏 |
| 修改核心交易逻辑 | 谨慎 | 影响大,需要强 Review |
| 改数据库 schema | 谨慎 | 涉及迁移和兼容 |
| 处理支付、权限、安全逻辑 | 不建议完全交给 AI | 风险和责任较高 |
| 大规模架构重构 | 不建议直接交给 AI | 上下文复杂,影响不可控 |
越局部、越可验证、越低风险,越适合 AI;越核心、越高风险、越涉及责任,越需要人主导。
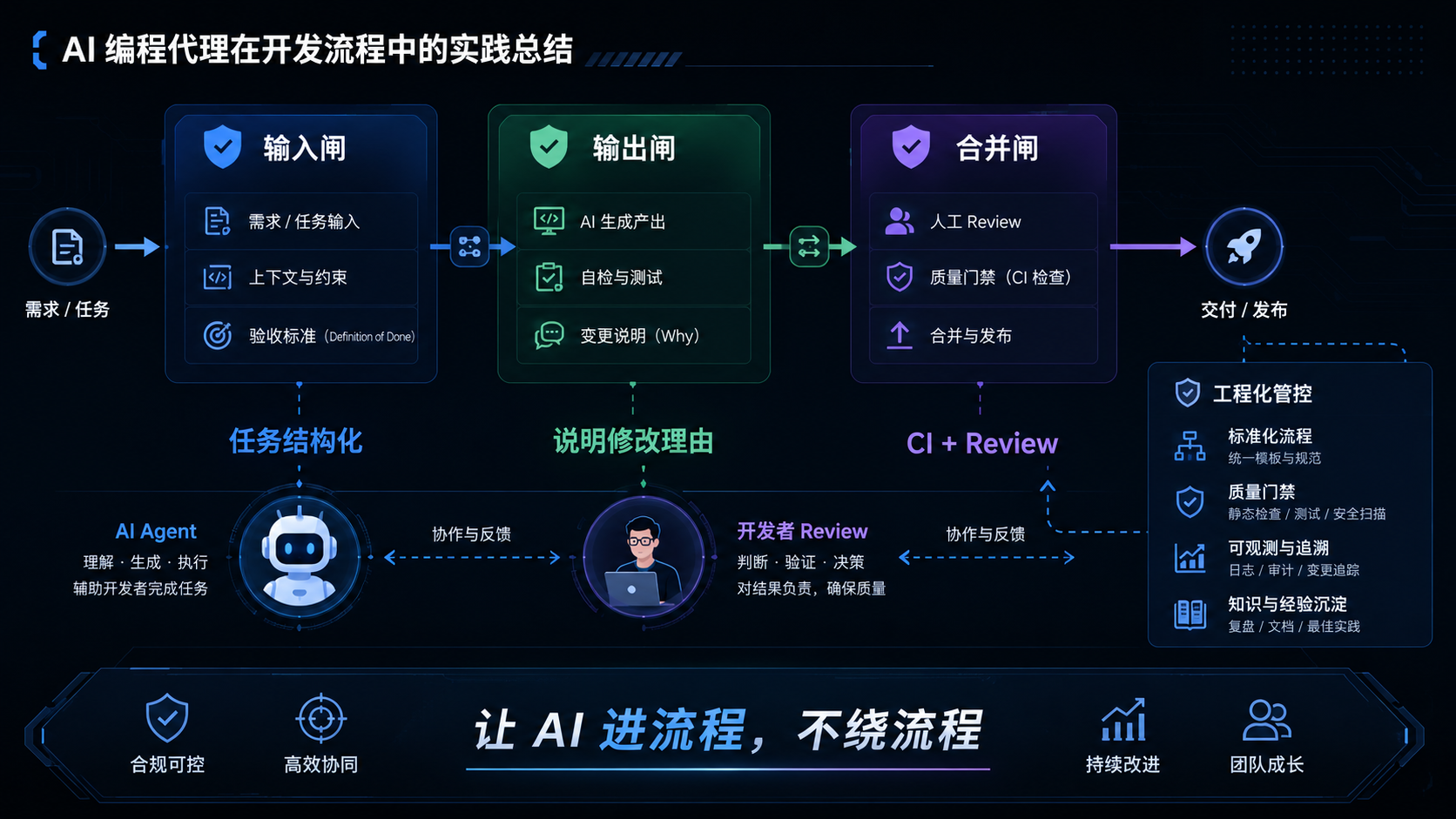
十二、团队落地建议:给 AI Agent 加三道闸
1. 输入闸:任务必须结构化
不要让团队成员随便写一句自然语言就让 AI 改代码。至少要求任务包含背景、现象、期望结果、可修改范围、禁止修改范围、验证方式、风险说明。
## 背景
描述问题发生的业务场景。
## 当前现象
描述可复现现象、日志、截图或报错。
## 期望结果
说明修复后应该达到什么状态。
## 允许修改范围
列出允许 AI 修改的目录或文件。
## 禁止修改范围
列出不能改的模块、接口、数据库结构或业务规则。
## 验证方式
说明需要运行哪些测试或手动验证步骤。
## 风险说明
说明可能影响的调用方、用户路径或历史兼容逻辑。
2. 输出闸:AI 必须说明修改理由
AI 不应该只交代码,还要交解释。每次 Agent 输出都应该包含修改文件、修改原因、未改范围、验证方式、可能影响,以及需要人工重点 Review 的位置。
3. 合并闸:AI 代码必须过 CI 和人工 Review
不管 AI 看起来多靠谱,都不建议直接合并。最低要求应该是单元测试通过、Lint 通过、类型检查通过、关键路径人工 Review、高风险模块负责人确认、PR 描述保留 AI 修改说明。
十三、不建议怎么做
第一,不建议直接让 AI 修改整个项目。项目越大,上下文越复杂,AI 越容易误判依赖关系。
第二,不建议把生产密钥、数据库连接、用户数据直接贴给 AI。即使工具本身提供安全机制,团队也应该养成最小化输入习惯。
第三,不建议用 AI 输出替代 Code Review。AI 可以帮你找问题,但不能替团队承担质量责任。
第四,不建议让 AI 一次完成“需求分析 + 架构设计 + 代码实现 + 上线说明”。链路太长,任何一个环节错了,后面都会继续放大错误。
第五,不建议只看生成速度。开发效率不是代码生成速度,而是从需求到稳定上线的总时间。AI 写得快,如果 Review、修复、回滚成本更高,反而不划算。
十四、明确结论:AI Agent 要接进流程,而不是绕开流程
Codex、Copilot Agent、Gemini Managed Agents 这类工具变强后,开发者最该升级的不是“会不会写 Prompt”,而是“会不会设计 AI 可参与的工程流程”。
如果只是让 AI 写一个函数,它是助手。如果让 AI 修改项目,它就是流程参与者。如果让 AI 自动创建任务、修改文件、生成 PR,它就必须被纳入权限、测试、日志、Review 和回滚机制。
真正可靠的 AI 编程实践,不是把开发者从流程里拿掉,而是让 AI 承担重复、局部、可验证的工作,让开发者把精力放在任务定义、方案选择、风险判断和最终质量上。
如果你只是偶尔问代码问题,免费工具也许已经够用;如果你已经把 Codex 用在日常开发,并且处在编程场景常用的 Bug 修复、测试生成、接口文档、代码解释等任务里,可以把 gpt985com 当成开通前的信息核对参考,重点看清周期、使用边界和异常说明,不要只因为工具能写代码就忽略工程验证。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)