
18.本地化部署:Ollama 与 LM Studio 的轻量级方案
本地化部署:Ollama 与 LM Studio 的轻量级方案
《大模型知识与部署》系列 · No.18 / 35
适合人群:AI 工程师、个人开发者、IDE 用户
阅读时间:约 25 分钟
写在前面
前两篇我们聊的都是「企业级部署」——vLLM、SGLang、TensorRT-LLM,动辄需要 H100 集群。
这一篇我们换个视角,聊本地化部署——也就是在自己笔记本、台式机、小型服务器上跑大模型。
为什么这件事在 2026 年仍然重要?
✓ 数据隐私:金融、医疗、法律团队不允许数据出域
✓ 离线可用:飞机上、地铁里、内网环境也要能用
✓ 零成本试错:开发期不想花 API 费用
✓ 端侧应用:手机、PC 本地集成 AI
✓ IDE 编程助手:Cursor/Copilot 替代的隐私版
下面这些问题你一定碰过:
- 想在 4090 上跑个本地模型试试,但 vLLM 装起来太重?
- Mac M3 能跑大模型吗?性能怎么样?
- 想给团队搭个内网 ChatGPT,怎么搞?
- 怎么让 VS Code 用本地模型当 Copilot?
- llama.cpp、Ollama、LM Studio 到底是什么关系?
读完本文你将能:
- 区分 4 大本地化方案的差异和适用场景
- 用 Ollama / LM Studio / llama.cpp 跑起本地模型
- 配置 VS Code / Cursor 用本地模型当 Copilot
- 在 Mac M 系列上充分利用 MLX 跑大模型
- 给小团队搭一个内网 LLM 服务
我们开始。
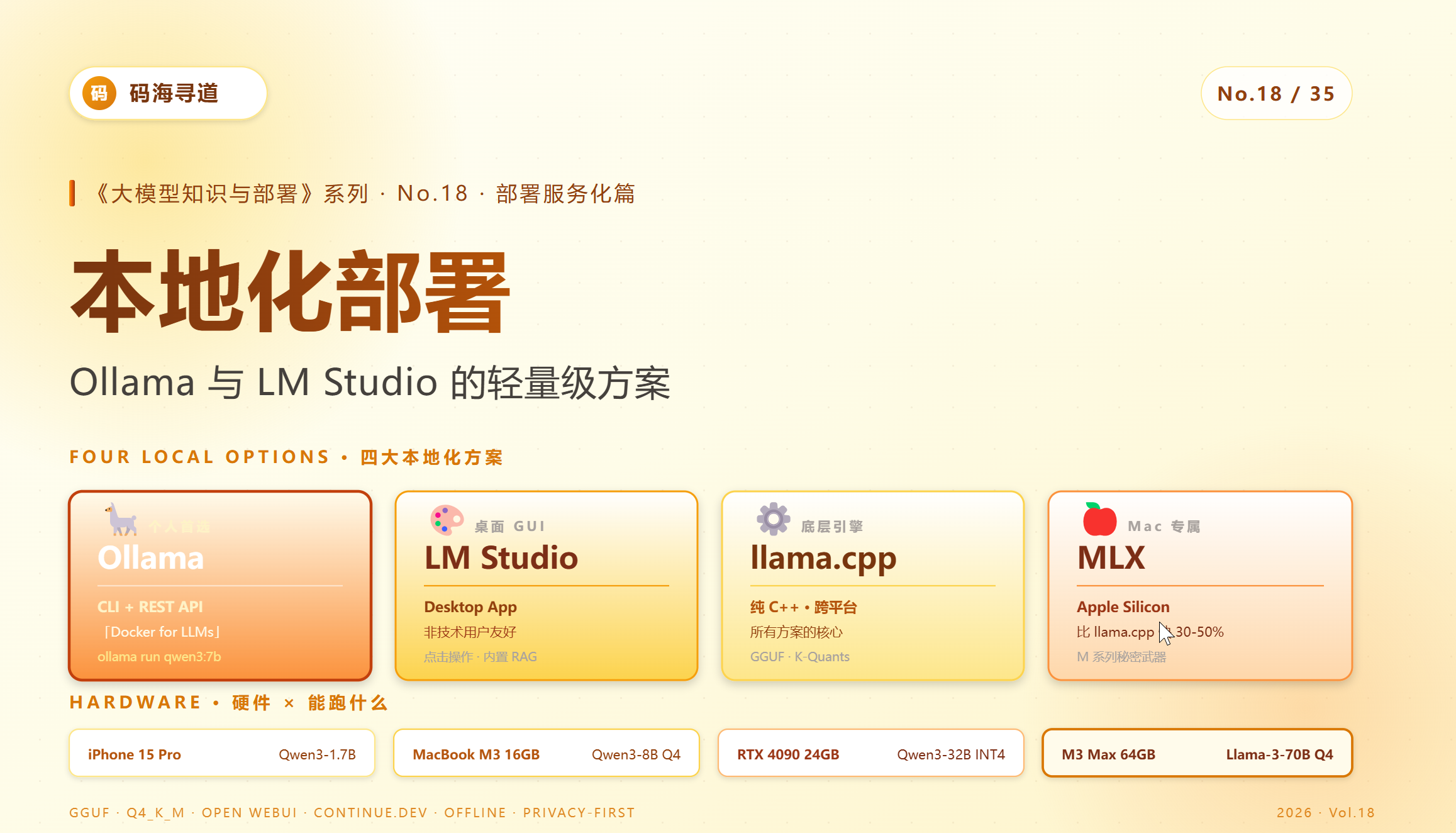
一、本地化部署的四大方案
1.1 总览
| 方案 | 类型 | 适合用户 | 当下地位 |
|---|---|---|---|
| Ollama | CLI + REST API | 开发者 | 个人最流行 ⭐ |
| LM Studio | 桌面 GUI | 非技术 / 体验 | 易用首选 |
| llama.cpp | C++ 库 / CLI | 底层定制 | 所有方案的底层 |
| MLX | Apple 框架 | Mac M 用户 | Apple 平台主流 |
它们之间的关系其实是这样的:
┌─────────────────────────────────────────────────┐
│ GUI 应用层 │
│ ┌─────────────┐ ┌─────────────┐ │
│ │ LM Studio │ │ Jan / Msty │ ... │
│ └─────────────┘ └─────────────┘ │
├─────────────────────────────────────────────────┤
│ CLI + API 层 │
│ ┌─────────────┐ ┌─────────────┐ │
│ │ Ollama │ │ llamafile │ │
│ └─────────────┘ └─────────────┘ │
├─────────────────────────────────────────────────┤
│ 推理引擎层(核心) │
│ ┌─────────────────────┐ ┌─────────────────┐ │
│ │ llama.cpp │ │ MLX │ │
│ │ (跨平台 C++) │ │ (Apple Silicon) │ │
│ └─────────────────────┘ └─────────────────┘ │
└─────────────────────────────────────────────────┘
关键认知:
- llama.cpp 是底层引擎——大多数本地工具的核心
- Ollama / LM Studio 是上层封装——让 llama.cpp 更易用
- MLX 是 Apple 自家的并行计算框架——Mac 上能比 llama.cpp 快 30-50%
1.2 硬件门槛
本地化部署的硬件远比想象中宽容:
| 硬件 | 能跑什么 |
|---|---|
| MacBook Air M2 8GB | Qwen3-1.7B、Phi-4-mini |
| MacBook Pro M3 16GB | Qwen3-7B INT4、Llama-3-8B Q4 |
| MacBook Pro M3 Max 64GB | Qwen3-32B INT4、Llama-3-70B Q4_K_M |
| iPhone 15 Pro 8GB | Qwen3-1.7B Q4 |
| PC RTX 4090 24GB | Qwen3-32B INT4、Llama-3-70B INT3 |
| PC RTX 5090 32GB | Qwen3-32B FP16、Qwen-MoE-A3B |
| PC 5950X + 64GB 内存(无 GPU) | Llama-3-8B Q4(CPU 推理) |
结论:本地跑大模型不需要多贵的设备。一台 M3 Mac 或 4090 主机已经够用。
二、Ollama:个人本地化首选
2.1 Ollama 是什么
Ollama 的设计哲学是**「Docker for LLMs」**——一切照搬 Docker 的体验:
ollama pull llama3.2 # 下载(类似 docker pull)
ollama run llama3.2 # 运行(类似 docker run)
ollama list # 列出模型
ollama serve # 后台服务
为什么这么火:
- 一行命令安装
- 自动管理模型权重(统一存储 / 删除)
- 内置 OpenAI 兼容 API
- 跨 Mac / Linux / Windows
- 完全免费开源
2.2 实战:5 分钟上手
# Mac / Linux 安装
curl -fsSL https://ollama.com/install.sh | sh
# Windows 用安装包:https://ollama.com/download/windows
# 拉个模型来跑
ollama run qwen3:7b-instruct
第一次跑会自动下载模型(约 4-5 GB),之后直接进入对话:
>>> 你好
你好!有什么可以帮你的吗?
>>> /bye
退出
2.3 API 调用(OpenAI 兼容)
Ollama 后台服务默认监听 http://localhost:11434:
# 启动后台服务
ollama serve
# 用 curl 调用
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3:7b-instruct",
"messages": [{"role": "user", "content": "你好"}],
"stream": false
}'
OpenAI SDK 直接接:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama" # 任意字符串都行
)
response = client.chat.completions.create(
model="qwen3:7b-instruct",
messages=[{"role": "user", "content": "解释 KV Cache"}]
)
2.4 内置模型库
Ollama 维护了一个模型仓库(类似 Docker Hub),常用模型一键拉取:
ollama pull qwen3:7b-instruct # Qwen3 7B
ollama pull qwen3:32b-instruct-q4_K_M # Qwen3 32B(4bit 量化)
ollama pull llama3.3:70b # Llama 3.3 70B
ollama pull deepseek-r1:8b # DeepSeek R1 蒸馏版
ollama pull gemma3:7b # Google Gemma 3
ollama pull phi4:14b # 微软 Phi-4
ollama pull qwen3-coder:14b # 代码模型
ollama pull nomic-embed-text # Embedding 模型
ollama list
# NAME SIZE MODIFIED
# qwen3:7b-instruct 4.7 GB 2 days ago
# deepseek-r1:8b 4.9 GB 3 days ago
# ...
所有模型都是 GGUF 格式 + 多种量化——Ollama 帮你选好了"性价比最优"的量化级别。
2.5 自定义 Modelfile
类似 Dockerfile,可以基于现有模型定制:
# Modelfile
FROM qwen3:7b-instruct
# 修改参数
PARAMETER temperature 0.3
PARAMETER top_p 0.9
PARAMETER num_ctx 8192
# 自定义 system prompt
SYSTEM """
你是一名资深 Python 工程师。
回答问题时严格按照 Python 最佳实践。
代码必须有类型注解。
"""
# 加 LoRA 适配器
ADAPTER ./my-lora.gguf
构建并运行:
ollama create my-python-helper -f Modelfile
ollama run my-python-helper
2.6 高级:Multi-Modal 与 Tool Use
Ollama 0.4+ 支持多模态模型:
ollama run llava:13b
>>> 这张图里有什么?/image.jpg
Tool Use(Function Calling):
response = client.chat.completions.create(
model="qwen3:7b-instruct",
messages=[...],
tools=[{
"type": "function",
"function": {
"name": "get_weather",
"parameters": {...}
}
}]
)
2.7 Ollama 性能基线
实测 Apple M3 Pro(18GB 内存)上 Ollama 性能:
| 模型 | 量化 | 显存占用 | 速度 (tok/s) |
|---|---|---|---|
| Llama-3.2-3B | Q4_K_M | 1.9 GB | 65 |
| Qwen3-7B | Q4_K_M | 4.3 GB | 45 |
| Llama-3.1-8B | Q4_K_M | 4.7 GB | 42 |
| Qwen3-14B | Q4_K_M | 8.2 GB | 22 |
| Qwen3-32B | Q4_K_M | 18 GB | 8(极限) |
单笔记本可以跑 32B 模型——这是 2026 年的本地化能力。
三、LM Studio:桌面 GUI 友好
3.1 LM Studio 适合谁
如果你符合下列任何一条,LM Studio 比 Ollama 更适合:
- 不太想用命令行
- 想要可视化界面(聊天框、参数调节)
- 想直接浏览 / 下载 HuggingFace 模型
- 想给非技术同事推荐工具
3.2 实战
-
下载安装:https://lmstudio.ai/ —— Mac / Windows / Linux 都有
-
搜索模型:左侧 “Discover” tab,搜 “Qwen3” 或 “Llama-3”,选合适量化版本(推荐 Q4_K_M)
-
下载:自动从 HuggingFace 拉 GGUF 文件
-
聊天:点 “Chat” tab,加载模型,开聊
-
API 服务:点 “Local Server” tab,启动 OpenAI 兼容 API(默认端口 1234)
3.3 LM Studio 的优势
| 优势 | 详情 |
|---|---|
| 易上手 | 完全 GUI,不写一行代码 |
| 模型浏览 | 直接搜 HF,看下载量、点赞 |
| 参数调节 | 滑块调节 temperature 等 |
| 多模型对比 | 同时加载多个模型对比 |
| 内置 RAG | 直接拖文档作为知识库 |
3.4 LM Studio 的劣势
- 闭源(Ollama 完全开源)
- 启动比 Ollama 慢
- 不能轻松脚本化
- 模型管理不如 Ollama 优雅
四、llama.cpp:所有方案的底层
4.1 为什么要懂 llama.cpp
Ollama 和 LM Studio 底层都用 llama.cpp。如果你想极致优化、深度定制,必须懂这一层。
llama.cpp 的核心特性:
- 纯 C++ 实现:无依赖,跨平台
- 支持各种硬件:CPU / NVIDIA / AMD / Apple Silicon / Intel
- K-Quants 量化体系:从 Q2_K 到 Q8_0 全谱
- GGUF 格式:单文件包含权重 + tokenizer + 配置
- 极致优化:手写 SIMD / Metal / CUDA kernel
4.2 K-Quants 量化体系
llama.cpp 的 K-Quants 是端侧部署的事实标准:
| 量化 | 平均比特 | 显存占用 (7B) | 效果 | 推荐 |
|---|---|---|---|---|
| F16 | 16 | 14 GB | 基线 | 通用 |
| Q8_0 | 8.5 | 7.5 GB | 几乎无损 | 中高端 |
| Q6_K | 6.6 | 5.8 GB | 极小损失 | 平衡 |
| Q5_K_M | 5.7 | 5.1 GB | 小损失 | 推荐 |
| Q4_K_M | 4.85 | 4.4 GB | 甜蜜点 | 首选 ⭐ |
| Q4_K_S | 4.6 | 4.1 GB | 小损失 | 内存紧张 |
| Q3_K_M | 3.9 | 3.5 GB | 中等损失 | 极限 |
| Q2_K | 2.6 | 2.7 GB | 较大损失 | 试验 |
Q4_K_M 是端侧大模型部署的事实标准——精度损失约 1-2%,显存省 4×。
4.3 实战:直接用 llama.cpp
# 编译(Mac,使用 Metal 加速)
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make GGML_METAL=1
# 下载 GGUF 模型(从 HF 或 Ollama 缓存复制)
# 例如:qwen3-7b-instruct-q4_k_m.gguf
# 跑推理
./llama-cli \
-m qwen3-7b-instruct-q4_k_m.gguf \
-p "解释一下 KV Cache" \
-n 200 \
--gpu-layers 99 \
-c 8192
关键参数:
--gpu-layers 99:把多少层放 GPU(全放就是 99 / -1)-c 8192:上下文长度-t 8:CPU 线程数
4.4 llama.cpp 启动 OpenAI 兼容 server
./llama-server \
-m qwen3-7b-instruct-q4_k_m.gguf \
--port 8080 \
--gpu-layers 99 \
-c 8192 \
--host 0.0.0.0
调用:
curl http://localhost:8080/v1/chat/completions ...
五、MLX:Apple Silicon 的「秘密武器」
5.1 MLX 是什么
MLX 是 Apple 在 2023 年底开源的机器学习框架,专为 Apple Silicon(M1/M2/M3/M4) 优化。
它对大模型部署的意义:
- 比 llama.cpp 在 Apple 平台快 30-50%
- 内置统一内存模型(CPU + GPU 共享)
- 支持 4-bit 量化(精度比 Q4_K_M 略好)
- Python 接口,开发友好
实测对比(M3 Max 64GB 上跑 Qwen3-32B Q4):
| 框架 | 速度 (tok/s) |
|---|---|
| llama.cpp Metal | 22 |
| MLX | 34 ⭐ |
| Ollama | 21 |
M 系列 Mac 用户应该首选 MLX。
5.2 实战
# 安装
pip install mlx-lm
# 跑模型(自动下载 4-bit 量化版)
mlx_lm.generate \
--model mlx-community/Qwen3-32B-Instruct-4bit \
--prompt "你好,介绍一下你自己" \
--max-tokens 200
# OpenAI 兼容 server
mlx_lm.server \
--model mlx-community/Qwen3-32B-Instruct-4bit \
--port 8000
MLX 模型库:HuggingFace 的 mlx-community 组织提供大量 MLX 优化版本。
5.3 MLX 的工程优势
- 统一内存:M 系列芯片 CPU 和 GPU 共享同一块内存,省去 PCIe 复制
- Metal 后端:直接调用 Apple Metal API
- Python 友好:写代码体验和 PyTorch 类似
- MLX-LM 一键部署:和 Ollama 体验类似
六、实战:3 个典型本地化场景
6.1 场景 1:配置 VS Code / Cursor 用本地模型
目标:用 Qwen3-Coder 替代 GitHub Copilot,零成本 + 数据不出本地。
步骤:
- 启动 Ollama 服务:
ollama pull qwen3-coder:14b
ollama serve
-
VS Code 装 Continue 插件:https://continue.dev
-
配置
~/.continue/config.json:
{
"models": [{
"title": "Local Qwen3 Coder",
"provider": "ollama",
"model": "qwen3-coder:14b",
"apiBase": "http://localhost:11434"
}],
"tabAutocompleteModel": {
"title": "Local Tab Autocomplete",
"provider": "ollama",
"model": "qwen3-coder:1.5b"
}
}
- 重启 VS Code,按
Ctrl+L打开聊天,按Tab触发自动补全。
性价比:
- 替代 Copilot ($10/月) 和 Cursor Pro ($20/月)
- 数据完全本地
- 单次硬件投入 ~$2K(4090 主机或 M3 Mac)
- 一年回本
6.2 场景 2:搭一个小团队内网 LLM 服务
目标:10 人小团队用本地 LLM 替代 ChatGPT,数据合规、零月费。
架构:
团队员工 ──> 内网 Web UI (Open WebUI)
↓
Ollama 服务 (本地服务器)
↓
4090 / A100 GPU
步骤:
- 服务器准备(一台带 4090 / A100 的 Linux 机器):
# 安装 Ollama
curl -fsSL https://ollama.com/install.sh | sh
# 拉模型
ollama pull qwen3:32b-instruct-q4_K_M
- 开 systemd 服务(让 Ollama 监听 0.0.0.0):
# /etc/systemd/system/ollama.service
sudo systemctl edit ollama.service
# 添加环境变量
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
sudo systemctl restart ollama
- 部署 Open WebUI(开源 ChatGPT 风格界面):
docker run -d -p 3000:8080 \
-e OLLAMA_BASE_URL=http://localhost:11434 \
-v open-webui:/app/backend/data \
--name open-webui \
ghcr.io/open-webui/open-webui:main
- 访问 http://serverIP:3000,注册账号,开始对话。
特性:
- 支持多用户(带账号管理)
- 内置 RAG(上传文档作为知识库)
- 多模型切换
- 完全开源免费
6.3 场景 3:手机端跑大模型
目标:在 iPhone / Android 上跑大模型,完全离线。
方案:
iOS:使用 MLX Swift
- App 推荐:MLC Chat(开源)、Private LLM(付费但体验好)
- 推荐模型:Qwen3-1.7B、Phi-4-mini
- 速度:iPhone 15 Pro 跑 1.7B 模型约 20-30 tokens/s
Android:使用 llama.cpp Android 端口
- App 推荐:MLC Chat、Maid
- 同样推荐 1.7B-3B 规模模型
- 高端 Android 旗舰(骁龙 8 Gen 4)速度类似 iPhone
七、选型决策与避坑
7.1 选型决策树
你的角色 / 需求是什么?
│
├─ 个人开发者,命令行熟悉
│ └─ Ollama ⭐
│
├─ 非技术用户,想要桌面 App
│ └─ LM Studio
│
├─ 极致性能 + 定制(懂底层)
│ └─ llama.cpp 原生
│
├─ Mac M 系列用户,追求性能
│ └─ MLX(mlx-lm 命令行)
│
├─ 团队内网部署
│ └─ Ollama + Open WebUI
│
└─ 手机 / 端侧
└─ MLC Chat / llama.cpp Android
7.2 5 大常见坑
坑 1:选错量化级别
症状:模型跑起来,但效果差/卡。
对策:
- 首选 Q4_K_M——精度/速度的甜蜜点
- 内存够 → Q5_K_M 或 Q8_0
- 极限省内存 → Q3_K_M(不要再低了)
坑 2:上下文太长
症状:跑着跑着突然卡 / OOM。
原因:KV Cache 占用太大。
对策:
# Ollama
OLLAMA_NUM_CTX=4096 ollama serve
# llama.cpp
./llama-server -c 4096 ...
不要默认设 32K,先 4K 跑起来再说。
坑 3:CPU 模式忘了启用 GPU
症状:明明有 4090,速度才 5 tokens/s。
对策(llama.cpp):
./llama-server -m model.gguf --gpu-layers 99
^^ 必须设置!
Ollama 通常自动检测,但有时需要:
OLLAMA_GPU=1 ollama serve
坑 4:模型选错语言
症状:跑 Llama 模型,中文回答语法错乱。
对策:
- 中文场景优先:Qwen3 系列、DeepSeek、GLM
- 英文场景:Llama、Phi
- 代码场景:Qwen3-Coder、DeepSeek-Coder
坑 5:拿生产 API 当本地替代
症状:本地模型在某些复杂任务上效果远不如 Claude。
残酷的事实:
- 本地 7B/13B 模型 ≠ Claude / GPT-5
- 本地模型适合:通用对话、简单代码、文档总结
- 本地模型不适合:复杂推理、专业知识问答、多步 Agent
正确认知:本地模型是 API 的补充,不是替代。
八、扩展话题与下一篇预告
8.1 还有哪些值得关注
| 工具 | 特点 |
|---|---|
| Jan | 类似 LM Studio 的开源桌面 App |
| GPT4All | 跨平台开源,含 RAG |
| Msty | 优雅的对话界面 |
| Open WebUI | Ollama 的官方推荐 Web UI |
| AnythingLLM | 内置文档 RAG 的桌面 App |
| llamafile | 单文件可执行的极致便携方案 |
8.2 性能再榨
如果想从本地硬件再榨性能:
- vLLM 本地模式:装 vLLM 在本地,性能比 Ollama 高 30-50%
- TensorRT-LLM Personal:N 卡用户的极致性能(编译麻烦)
- MLX 微调:直接在 Mac 上微调小模型
8.3 端侧大模型的未来
2026 年端侧大模型的趋势:
- iPhone 16 Pro / 17 系列:原生大模型 SDK,3-5B 模型流畅
- Copilot+ PC:Windows 高通 X Elite 笔记本,40 TOPS NPU
- 小模型革命:Phi-5、Qwen3-Tiny 等小模型能力快速接近大模型
👉 详见 系列第 33 篇:端侧大模型。
8.4 下一篇预告
- 第 19 篇:OpenAI 兼容 API 服务化 —— 我们前面反复提到 OpenAI 兼容 API,这一篇会深入讲它的设计、扩展、与多家框架的差异。如果你要做一个 LLM 中台或 Gateway,这一篇必读。
之后是分布式推理(第 20 篇),部署服务化篇就完整收官。
结语:让 AI 真正"私有化"
读完本文你应该明白:
- Ollama 是个人本地化首选——Docker for LLMs 的体验
- LM Studio 适合非技术用户——纯 GUI 体验
- llama.cpp 是所有方案的底层——懂它能极致优化
- MLX 是 Mac 用户的秘密武器——比 llama.cpp 快 30-50%
- Q4_K_M 是端侧量化的事实标准——精度/速度甜蜜点
- 本地模型 ≠ Claude/GPT——是补充不是替代
下一篇我们继续:
- 第 19 篇:OpenAI 兼容 API 服务化 —— 当你的团队同时用 vLLM、SGLang、Ollama、Claude API,怎么统一成一套接口?怎么做计费、限流、缓存?
我们下篇见。
📮 关于「码海寻道」
这里是一个聚焦 AI 工程化、大模型部署、后端架构实战的技术专栏。
写最一线的踩坑经验,做最务实的技术拆解。如果这篇文章对你有启发,欢迎点赞、转发、关注。我们下篇见。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)