
Claude Code 源码看 Agent 系统设计
前言
市面上讲 AI Agent 的文章很多,大多停留在"工具调用 + 循环"这个层面。但当你真正面对一个生产级 Agent 系统时,会发现从教学版到工业版之间,隔着一条巨大的鸿沟——权限系统、上下文压缩、流式处理、插件架构……这些细节,才是一个 Agent 能否真正可用的关键。
Anthropic 官方的 CLI 工具 Claude Code 是目前少有的、已开放编译产物的工业级 Agent 实现。它用 TypeScript + React 编写,编译为单个 13MB 的 cli.js,包含 45+ 内置工具、101 个命令、56 个子目录。本文基于其 v2.1.88 的源码结构,拆解它在架构上做了哪些值得学习的设计决策。
一、最核心的抽象:Agent = While Loop + Tools
这是它的一个核心执行流程: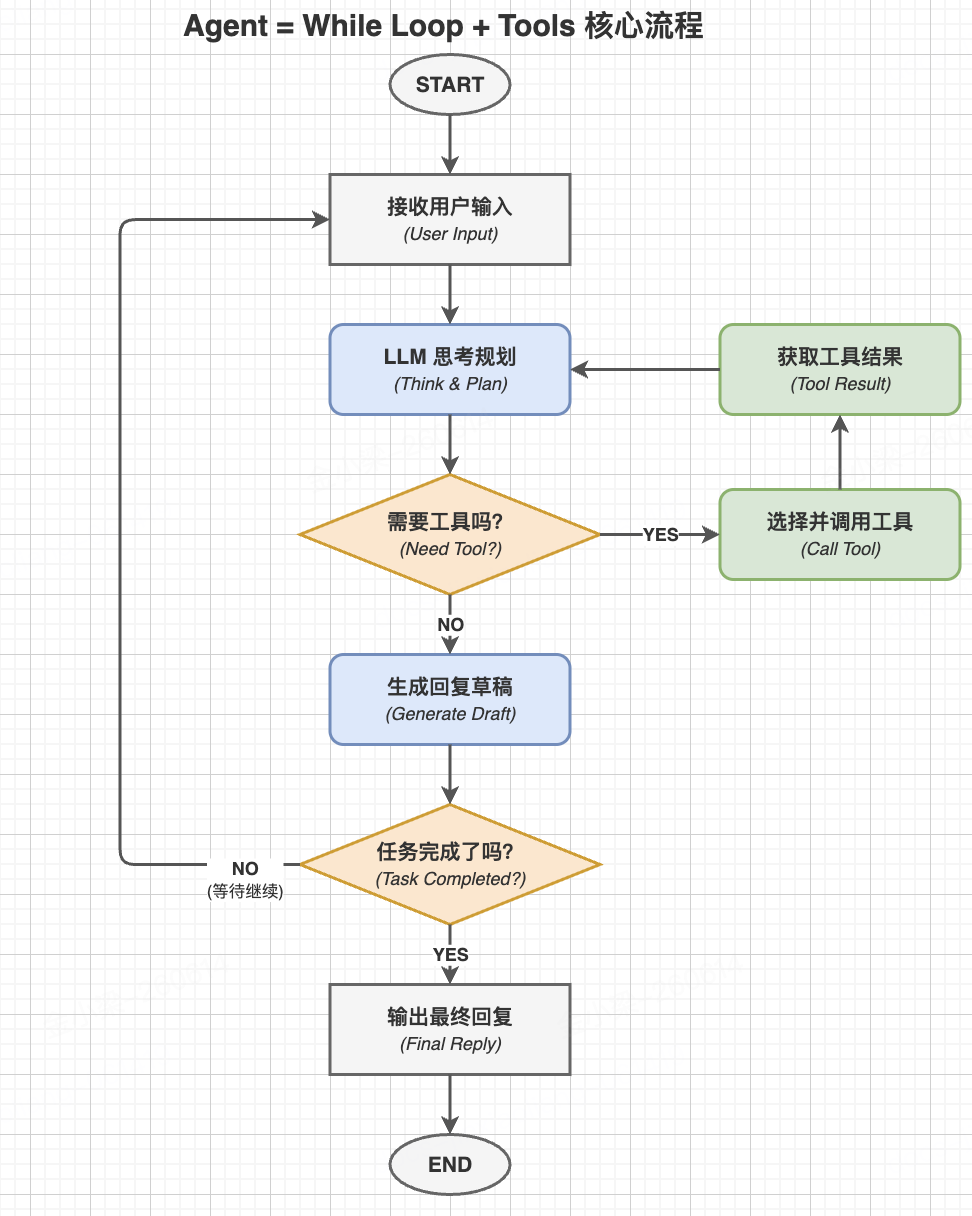
先把最本质的东西说清楚。无论一个 Agent 系统有多复杂,它的核心逻辑永远是这样一段伪代码:
while (stop_reason === "tool_use") {
response = await callLLM(messages)
toolResults = await executeTools(response.tool_calls)
messages.push(response, toolResults)
}
这就是 Agent 的全部本质。
Claude Code 的 query.ts 就是这个循环的实现,对应 queryLoop 函数。它的全部复杂性,都是在这个最简单的 while 循环之上一层一层叠加出来的:权限检查、流式处理、上下文压缩、子代理……每一层都解决一个具体的工程问题。
理解了这一点,面对任何 Agent 系统,你都有了一个清晰的解析框架。
二、分层架构:七层清晰分离
Claude Code 的架构从上到下分为七层,每一层职责单一:
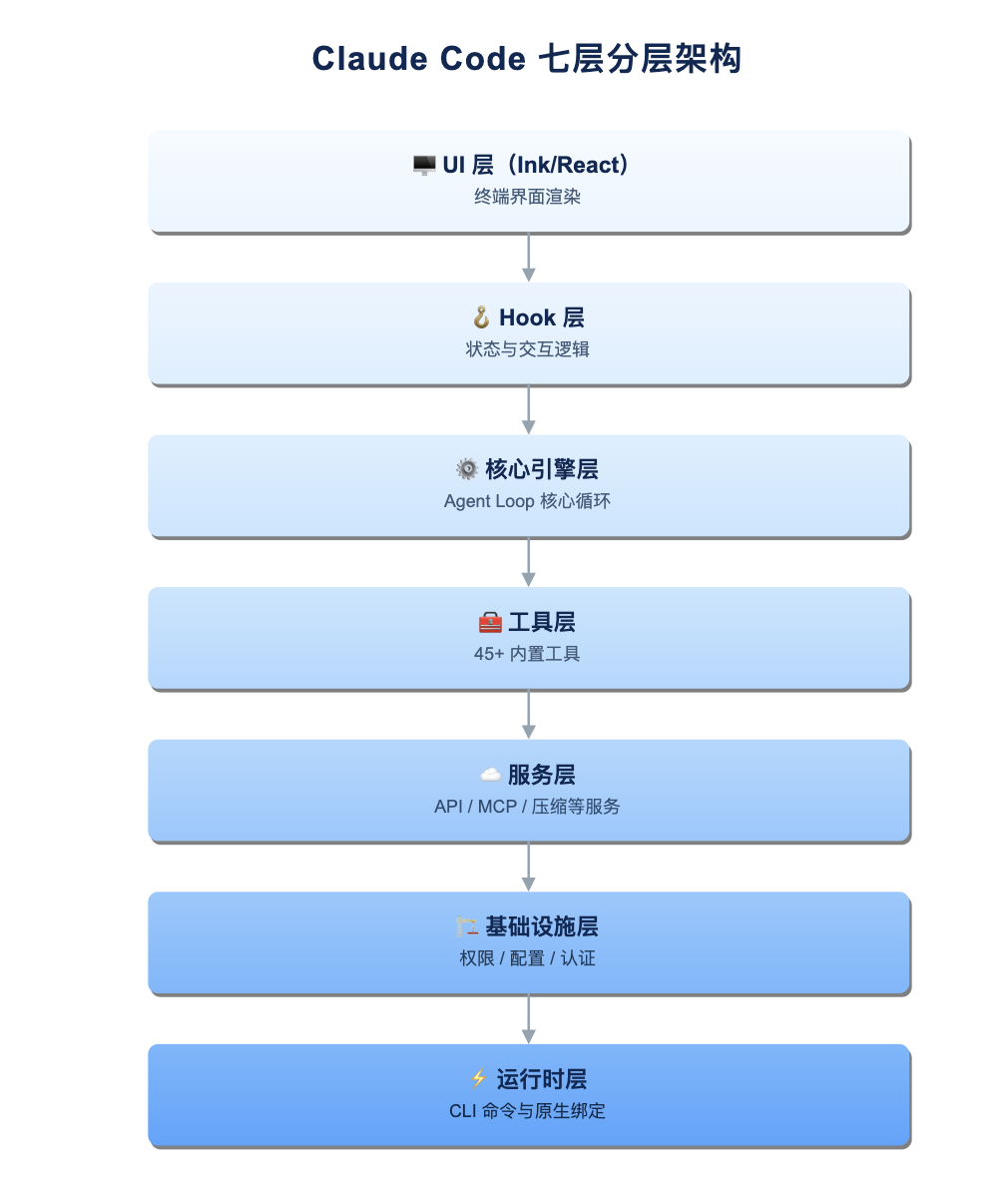
| 层级 | 内容 | 规模 |
|---|---|---|
| UI 层(Ink/React) | 终端 UI 组件 | 146 个组件 |
| Hook 层 | React Hooks | 87 个 |
| 核心引擎层 | QueryEngine + Agent Loop | query.ts / QueryEngine.ts |
| 工具层 | 内置工具 | 45+ |
| 服务层 | API 客户端、MCP、压缩 | 38 个服务模块 |
| 基础设施层 | 权限、配置、认证 | 331 个工具模块 |
| 运行时层 | 状态、命令、原生绑定 | 101 个命令 |
值得注意的是:这里用 React + Ink 来构建 CLI 的 UI。Ink 是一个允许你用 React 组件来渲染终端界面的库。这个选择让 Claude Code 的 TUI 拥有了完整的组件化、状态驱动能力,87 个 React Hooks 也因此能在终端环境中复用前端开发模式。
对于后端同学来说,这是一个值得关注的技术选型——当 CLI 交互足够复杂时,用 React 来管理终端 UI 状态,比手写状态机要清晰得多。
三、一次用户输入的完整生命周期
从用户敲下回车,到 Agent 完成响应,中间经历了五个核心阶段:
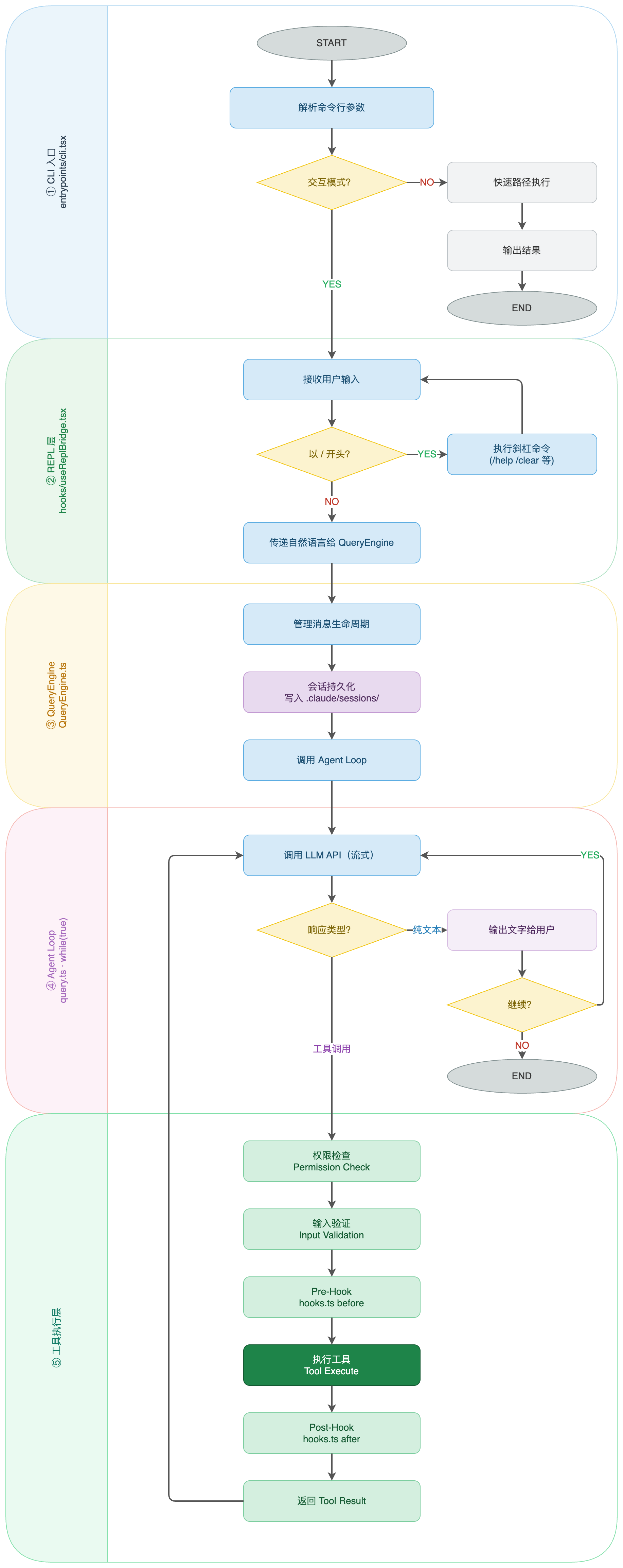
QueryEngine 是这里容易被忽视的关键角色:它管理的不仅是单次请求,而是整个对话的生命周期——消息累积、会话持久化、mutableMessages[] 的维护都在这里。 一个好的 Agent 系统,QueryEngine 这一层往往是最难设计的。
四、权限系统:不是事后加的安全层
教学版 Agent 通常会把权限检查做成一个"if 判断"塞在工具调用前。Claude Code 的做法截然不同——权限是从设计之初就融入架构的第一等公民。
以 BashTool 的权限检查为例,它有整整六个阶段:
| 阶段 | 名称 | 说明 |
|---|---|---|
| Stage 1 | AST 解析(tree-sitter) | 将 Shell 命令解析为语法树,识别子命令 |
| Stage 2 | 语义检查 | 检测 eval、危险内建命令等 |
| Stage 3 | 沙箱自动允许 | 沙箱模式下的安全命令直接通过 |
| Stage 4 | 精确匹配 | 检查用户配置的精确规则 |
| Stage 5 | AI 分类器 | 用 LLM 判断命令是否匹配规则 |
| Stage 6 | 回退到 ask | 让用户手动决定 |
这个也给出清晰的图解: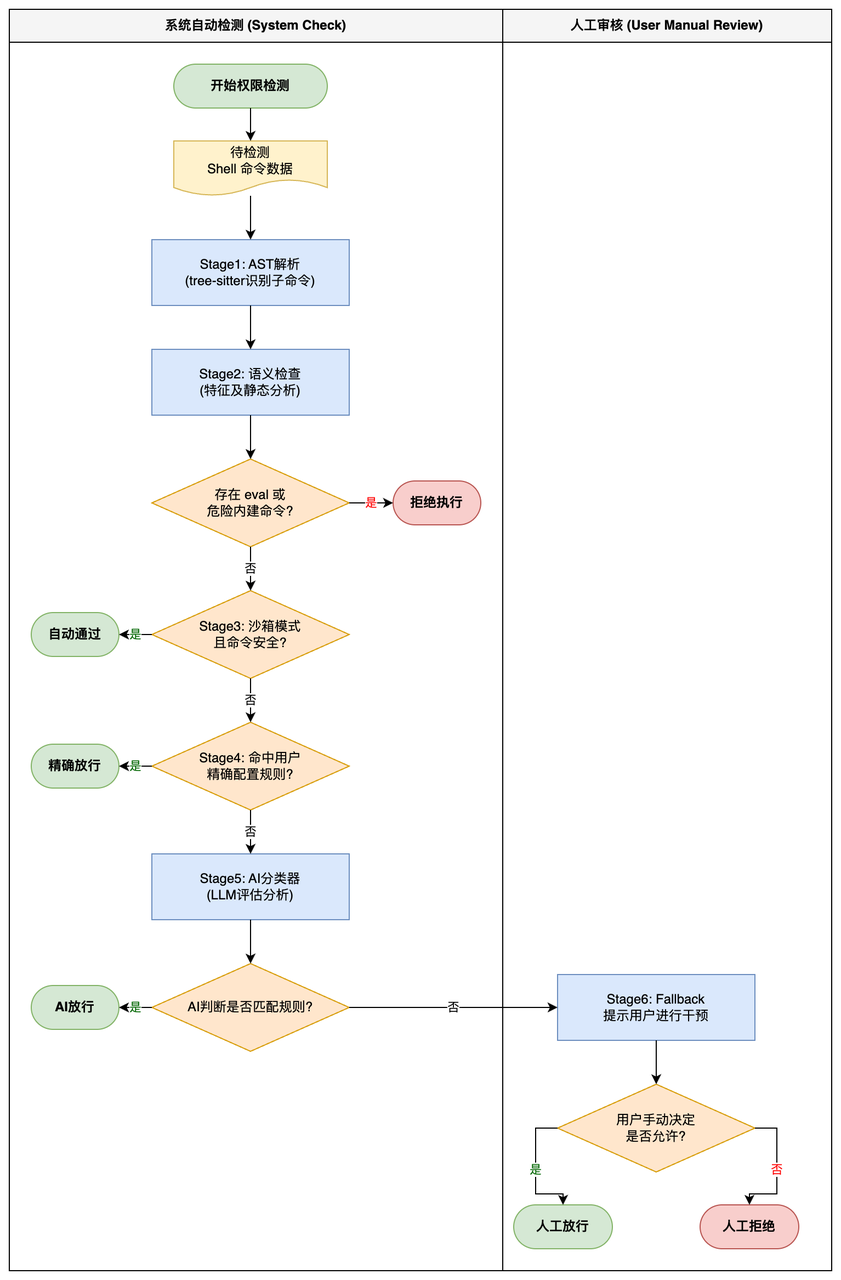
Stage 5 值得单独说:用一个 LLM 调用来判断"当前命令是否符合已配置规则",这是一个非常聪明的设计。规则是自然语言写的,人也是用自然语言思考的,让 LLM 来做这个匹配,比正则表达式或手写规则引擎灵活得多。
这六个阶段从静态分析 → 语义分析 → 沙箱 → 规则匹配 → AI 判断 → 人工兜底,构成了一个完整的纵深防御体系。
五、上下文压缩:三层策略精细管理 Token
Context Window 是 Agent 运行中最宝贵的资源。Claude Code 用三层压缩策略来管理它,三轮压缩机制从左往右依次递增:
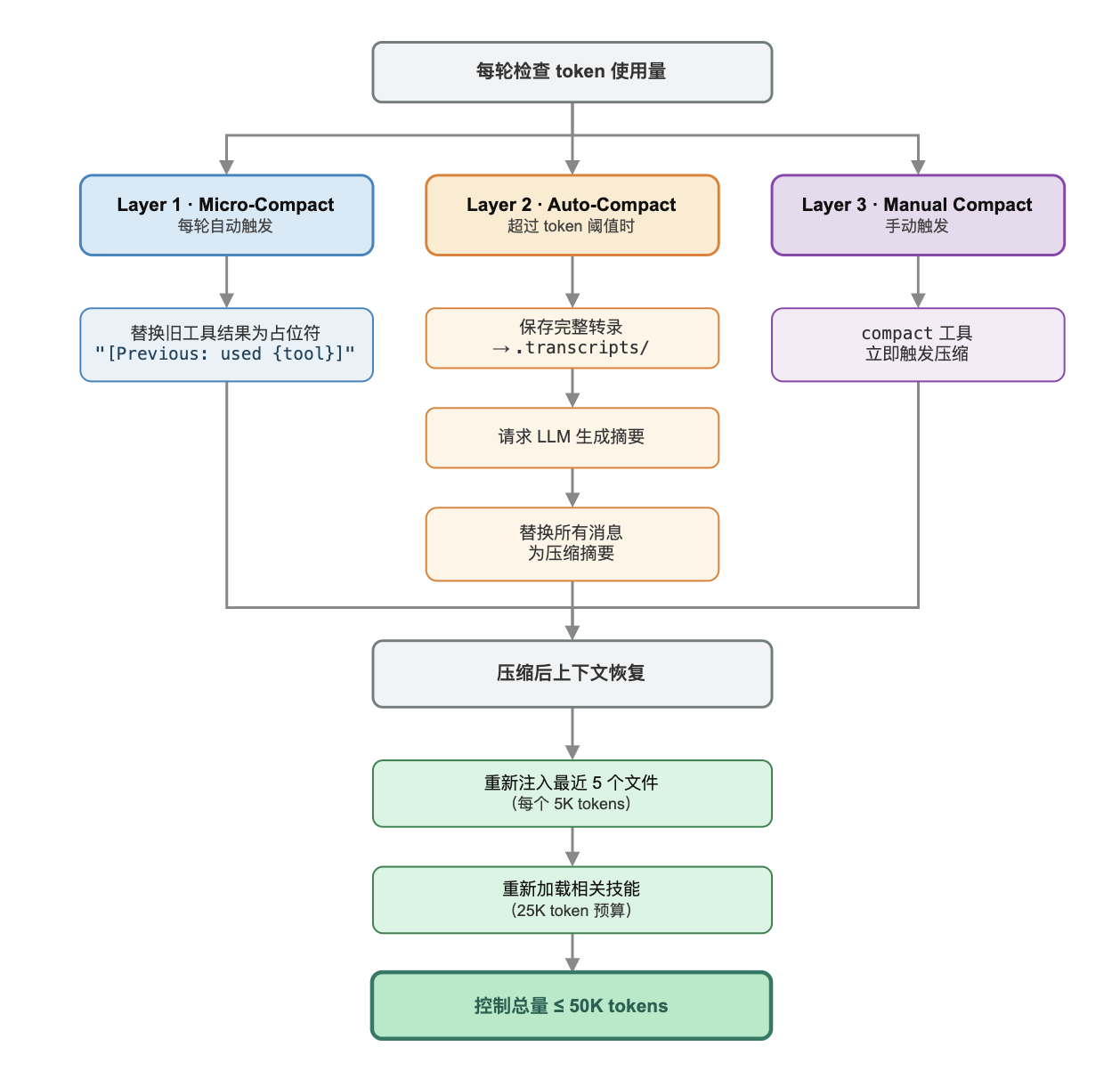
Layer 1
Micro-Compact 每轮自动执行
将旧的工具执行结果替换为占位符 [Previous: used ]。大量文件读取、命令输出的历史记录,对后续推理通常价值有限,替换为摘要即可。
Layer 2
Auto-Compact 超过阈值自动触发
先将完整转录保存到 .transcripts/,再请求 LLM 生成对话摘要,用摘要替换全部历史消息。压缩后重新注入最近 5 个文件内容(5K tokens/个),总量不超过 50K tokens。
Layer 3
Manual Compact 手动触发
通过 compact 工具手动触发立即压缩,作为用户可控的最终兜底手段。
这套三层策略的设计思路值得借鉴:分级处理,小代价的操作高频执行,大代价的操作按需触发,人工干预作为最终兜底。
六、"一切皆 Tool"的统一接口
Claude Code 中,文件读写、Shell 执行、网页抓取、子代理调用、MCP 服务器——全部统一为 Tool 接口。Tool.ts 定义了接口,tools.ts 维护注册表,所有工具实现统一的 call(input, context) 约定。
每一个工具调用都经过相同的流水线:
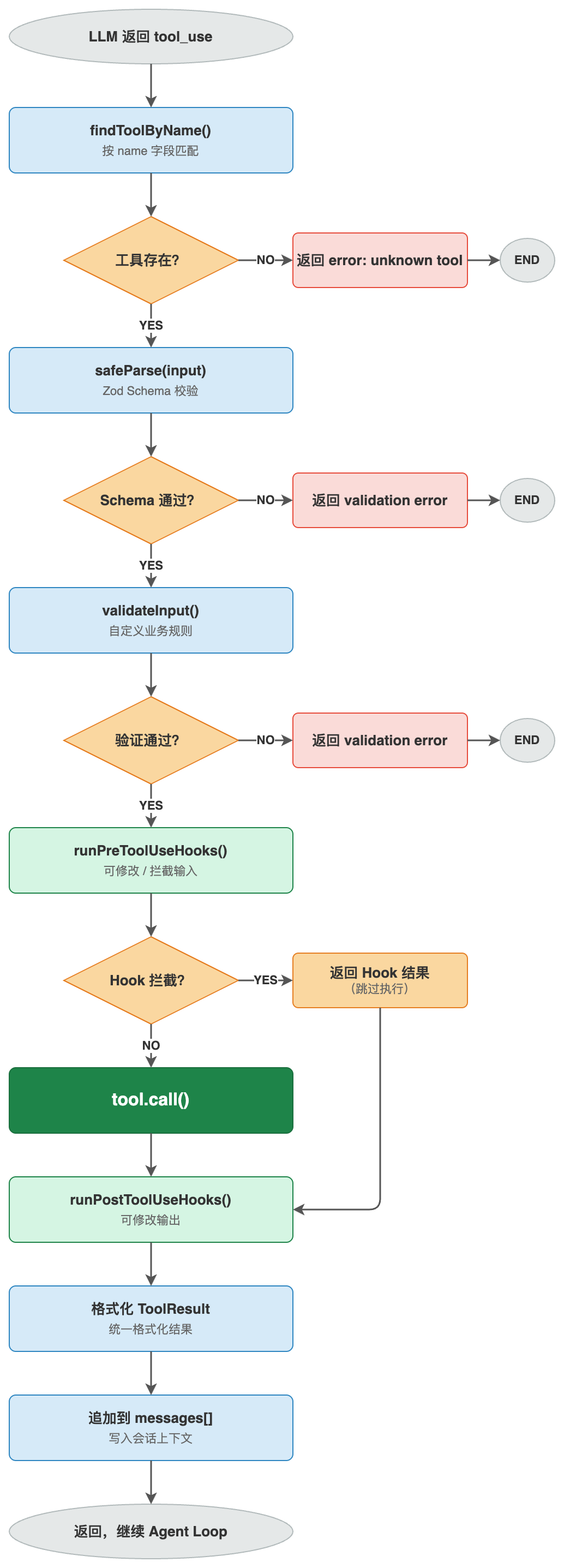
LLM 返回 tool_use
→ findToolByName() 查找工具
→ safeParse(input) Zod 输入验证
→ validateInput() 自定义验证
→ runPreToolUseHooks() Pre-Hook(可修改输入)
→ checkPermissions() 权限检查
→ tool.call() 执行
→ runPostToolUseHooks() Post-Hook
→ 格式化结果 → 追加到 messages[]
Builder 模式用于工具的构造,让工具定义更声明式,也让测试和 Mock 更容易。
七、异步生成器:流式处理的核心范式
Claude Code 大量使用 async function*(异步生成器)。从 Anthropic API 的流式响应,到工具执行的中间结果,流式处理贯穿始终。
这个选择的好处是双重的:
- 实时性:用户能看到 LLM 逐 token 输出,而不是等待完整响应
- 惰性求值:工具结果按需消费,不必全部 buffer 在内存中
对于 TypeScript 开发者来说,如果你的项目涉及 LLM 集成,异步生成器是一个值得掌握的核心模式。
八、多进程架构
Claude Code 不只是一个命令行工具,它支持多种运行模式:
| 进程类型 | 入口 | 用途 |
|---|---|---|
| 交互式 REPL | claude | 标准 CLI 使用 |
| 远程控制 | claude remote-control | 从云端控制本地机器 |
| 守护进程 | claude daemon | 后台任务监督 |
| 后台会话 | claude --bg | 后台执行任务 |
| MCP 服务器 | –claude-in-chrome-mcp | Chrome 扩展集成 |
同时,Bun 的编译时 feature flag 机制实现了死代码消除:同一份代码库可以构建出功能裁剪的多个版本,而不必维护多个分支。
总结:五条工业级 Agent 设计原则
- Agent 本质是循环,复杂性是在循环上叠加的,不要一开始就把架构搞复杂
- 权限是第一等公民,不是事后补丁,要从设计之初就融入每个工具调用
- 上下文是稀缺资源,需要主动的、分级的压缩策略,而非被动等待 OOM
- 统一的 Tool 接口带来极强的扩展性,一切能力都应该可以用工具来表达
- 流式处理从一开始就要设计进去,异步生成器是 TypeScript 实现流式 Agent 的首选范式
参考来源:
https://nangongwentian-fe.github.io/learn-claude-source/overview.html
感兴趣的宝子可以关注一波,后续会更新更多有用的知识!!!

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)