
Codex 模型如何选择,教你最省也最合适的的办法
GPT 和 Codex 模型越来越多,我现在不再所有任务都用同一个模型
最近看 GPT 和 Codex 相关消息,一个感觉很明显:
模型越来越多了。
有的偏日常问答,有的偏代码,有的偏长任务,有的速度更快,有的更适合复杂推理。
这对新手来说其实有点麻烦。
以前只要记住一个模型名就行。现在变成:
日常问题用哪个?
写代码用哪个?
大项目用哪个?
要不要都用更强的?
我一开始也偷懒,所有任务都填同一个模型。
后来发现不太划算。
这篇就写一下我现在的做法:把 GPT / Codex 按任务分开用。
先说结论
我现在一般分三类:
日常分析:用轻量一点的模型
项目开发:用适合代码的模型
重任务:用更强的模型
不是什么任务都上更强的模型。
因为有些问题根本不需要。
比如:
- 整理一段文档
- 分析一份视频文稿
- 生成一个文章提纲
- 看一眼项目目录
- 解释一个简单报错
这些任务用轻量模型就够了。
真正需要更强模型的,通常是:
- 大项目重构
- 复杂 bug 排查
- 多文件代码修改
- 长上下文项目分析
- 需要反复测试和修改的任务
我会怎么选模型
这里先说清楚:不同平台后台展示的模型名可能不一样,所以不要死记我这里的名字。
我的截图是我自己使用的站点(yunaicode.com)[https://cdn.yunaicode.com/sign-up?aff=kyw3]
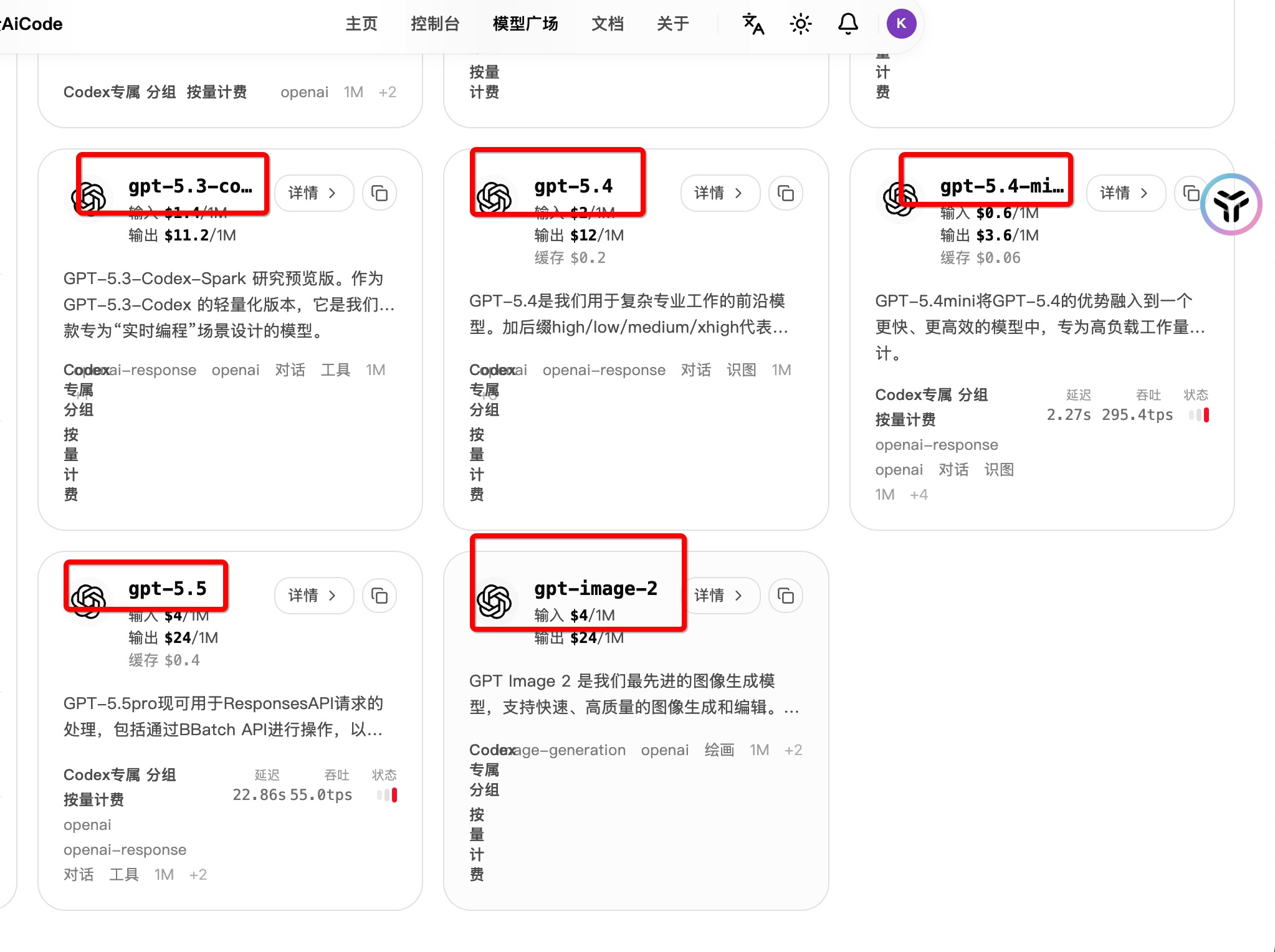
我的原则是按任务量级选。
轻量任务
适合:
- 文档总结
- 视频文稿提纲
- 简单问答
- 简单脚本思路
- 项目目录初步分析
- 文章标题和大纲
这类任务我一般会选轻量模型。
如果后台有类似这些模型,可以优先考虑:
gpt-5.5-instant
gpt-5.5-mini
gpt-5.4-mini
gpt-5.4-nano
这类模型的特点是速度快,适合日常分析,不适合让它长时间改复杂项目。
标准开发任务
适合:
- 修一个小 bug
- 改一个小功能
- 解释一段业务代码
- 补一两个测试
- 看一个中小项目结构
- 做普通代码 review
这类任务我会选偏代码能力的中档模型。
如果后台有类似这些模型,可以考虑:
gpt-5.5-codex
gpt-5.5
gpt-5.4-codex
gpt-5.4
这类适合日常开发,不一定每次都要上更贵、更重的模型。
重任务
适合:
- 大仓库分析
- 多文件重构
- 长上下文任务
- 复杂 bug 排查
- 需要多轮测试和修复
- 比较重要的代码修改
这类我会单独用更强的模型和单独的 Key。
如果后台有类似这些模型,可以考虑:
gpt-5.5-codex
gpt-5.5-thinking
gpt-5.5-pro
gpt-5.4-codex
gpt-5.4-thinking
这类模型不要乱用。它适合复杂任务,但日常小问题用它有点浪费。
简单记法
我自己会这样记:
日常资料:5.5 instant / 5.5 mini / 5.4 mini
普通开发:5.5 codex / 5.5 / 5.4 codex
复杂项目:5.5 thinking / 5.5 pro / 5.5 codex
最终还是以你后台真实可用模型名为准。
不要自己猜模型名,也不要直接复制别人文章里的模型名就用。
为什么不建议所有任务都用一个模型
所有任务都用一个模型,最省脑子。
但用久了会有几个问题:
- 日常小问题也消耗重模型额度
- 项目开发和资料分析混在一起,看不清用量
- 大任务容易把普通任务的额度也拖进去
- 后面出了问题,不知道是哪类任务消耗多
尤其是 Codex 这种 agent 工具,它不是简单问答。
你让它修一个问题,它可能会读文件、分析、修改、运行命令、再继续判断。
所以同样一句话,背后消耗可能比普通聊天高不少。
我的任务分法
我现在会这样分:
1. 日常分析
这类任务不一定是代码。
比如:
- 文档分析
- 视频文稿整理
- 股票资料拆解
- 文章提纲
- 运营选题
- 简单脚本思路
这类任务我一般用轻量模型。
重点是速度和够用。
2. 项目开发
这类任务开始和代码有关。
比如:
- 看项目结构
- 分析报错
- 修一个小 bug
- 改一个小功能
- 补一两个测试
这类我会用代码能力更好的模型。
3. 重任务
这类就比较耗了。
比如:
- 大仓库分析
- 多文件重构
- 复杂 bug
- 需要跑测试反复修
- 长时间 agent 任务
这种我会单独用一个更强的模型,也会单独给一个 Key。
这样就算它用量高,也不会影响日常任务。
配置思路:不同任务用不同 profile
如果你用的是 Codex CLI,可以用 profile 来分。
这里要先去站点新建不同的key,我是在我自己常用的站点新建了不同的任务key.所以后面的截图都是我自己常用的站点截图
yunaicode.com
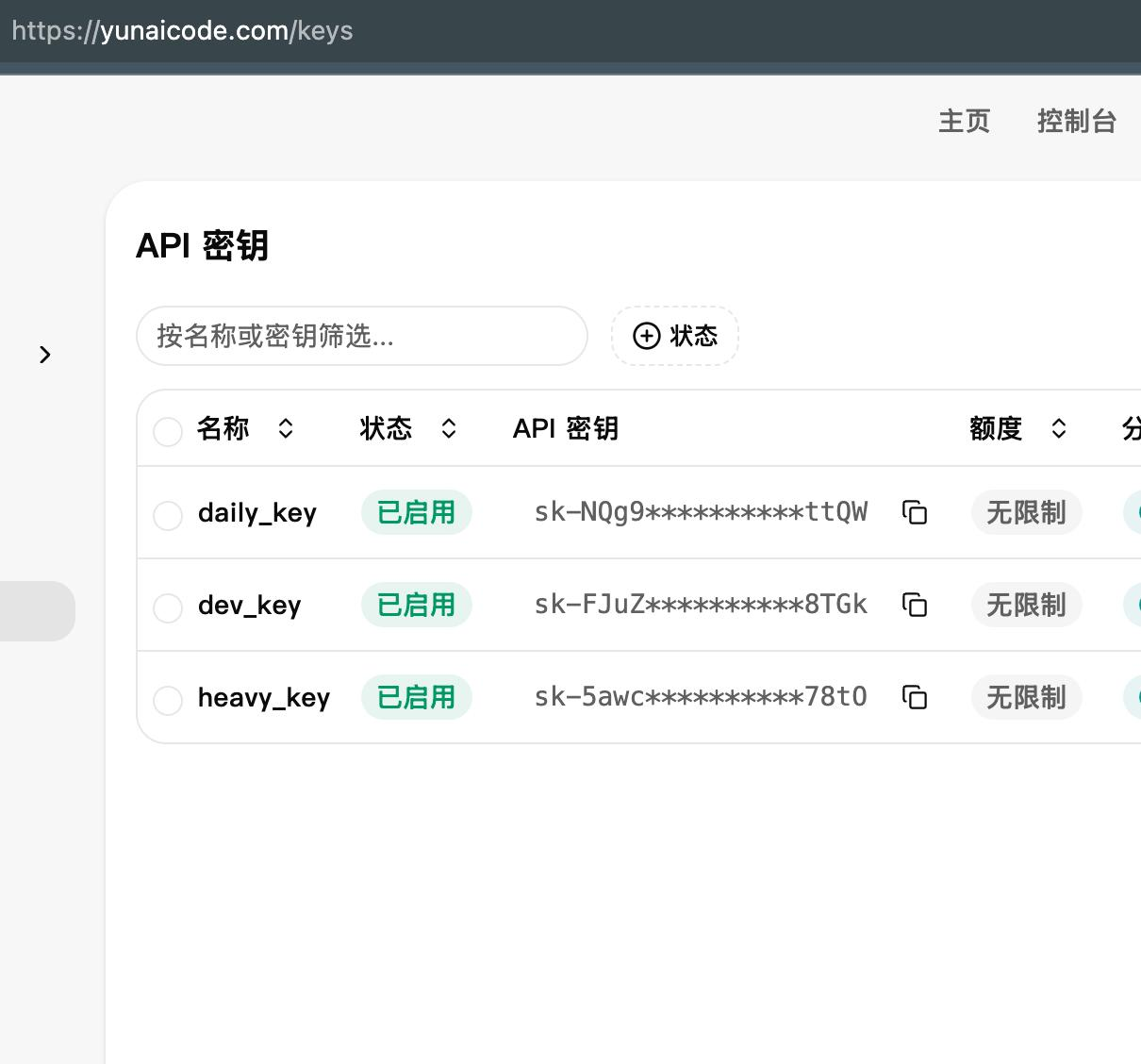
大概是这样:
daily:日常分析
dev:项目开发
heavy:重任务
对应不同模型和不同 API_KEY。
启动时这样选:
codex --profile daily
codex --profile dev
codex --profile heavy
这比每次手动改 config.toml 省事很多。
先配置 provider
主配置文件一般在:
~/.codex/config.toml
Windows 一般在:
C:\Users\你的用户名\.codex\config.toml
可以这样写:
[model_providers.daily]
name = "Daily API"
base_url = "https://cdn.yunaicode.com/v1"
env_key = "API_KEY_DAILY"
wire_api = "responses"
[model_providers.dev]
name = "Dev API"
base_url = "https://cdn.yunaicode.com/v1"
env_key = "API_KEY_DEV"
wire_api = "responses"
这里的重点是 env_key。
它不是写真实 Key,而是告诉 Codex 去读哪个环境变量。
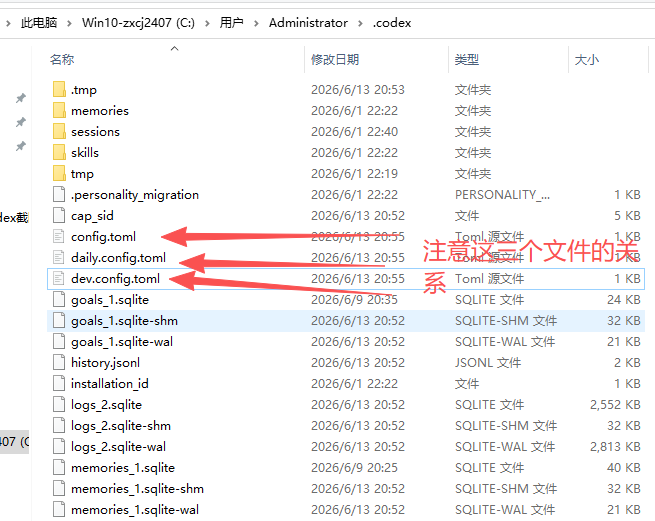
再配置 profile
然后在 .codex 目录里建三个 profile 文件。
daily.config.toml:
model = "gpt-5.4-mini"
model_provider = "daily"
dev.config.toml:
model = "gpt-5.4"
model_provider = "dev"
heavy.config.toml:
model = "gpt-5.5"
model_provider = "heavy"
模型名不要自己猜。
去站点的模型广场复制可用模型名。
API_KEY 怎么放
Mac / Linux:
echo 'export API_KEY_DAILY="日常分析 Key"' >> ~/.zshrc
echo 'export API_KEY_DEV="项目开发 Key"' >> ~/.zshrc
echo 'export API_KEY_HEAVY="重任务 Key"' >> ~/.zshrc
source ~/.zshrc
Windows:
setx API_KEY_DAILY "日常分析 Key"
setx API_KEY_DEV "项目开发 Key"
setx API_KEY_HEAVY "重任务 Key"
Windows 设置完记得重新打开 PowerShell。
重点不是一定要用哪个入口,而是要把模型、Key、用途分清楚。
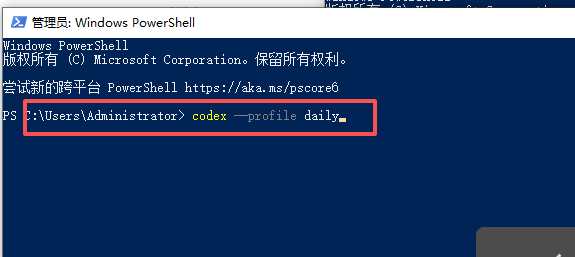
我平时怎么用
日常文档分析:
codex --profile daily
项目开发:
codex --profile dev
大项目或重任务:
codex --profile heavy
这样用下来,我自己会更清楚:
哪类任务用得多
哪个模型适合哪类事
哪个 Key 需要单独停掉
哪个任务不值得上重模型
不要一开始就分太细
新手刚开始不用分五六种。
先分两种就行:
daily:日常分析
dev:项目开发
等你真的开始跑大仓库,再加:
heavy:重任务
配置太多,自己也容易忘。
最后说一下
GPT 和 Codex 模型越来越多,不是让我们每个都追。
更实际的做法是:
小任务用轻量模型
开发任务用代码模型
重任务单独用更强模型
不同任务用不同 Key
用 profile 来切换
这样不只是省用量,也更方便后面排查问题。
新手先从 daily 和 dev 两个 profile 开始,基本就够用了。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 16
16 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)