
【强化学习】用 PPO 微调 LLM,20W字总结(九)

😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔本文讲解【强化学习】用 PPO 微调 LLM,20W字总结(九),期待与你一同探索、学习、进步,一起卷起来叭!
🎯 把我的博客装进你的 Claude Code,它就是你的 AI 学习搭子
想随时搜我的文章、让 AI 帮你深度讲解甚至出面试题?复制下面这段提示词丢进你的 Claude Code——它会自动生成一个本地 SKILL,之后你直接说「搜一下强化学习的文章」就行。RSS 自动同步最新内容,不用手动存任何文件。
请为这个 CSDN 博客创建一个本地 SKILL(存到 .claude/skills/csdn-blog/SKILL.md): RSS 源:https://rss.csdn.net/m0_51517236/rss/map 支持三件事:① 列出最新文章(标题+链接+摘要);② 按关键词搜索; ③ 抓取指定文章全文,作为 AI 学习助手 / 面试官深度讲解并出题考核我。 SKILL.md 里写清楚 RSS URL、调用方式和示例。生成完就能用自然语言搜文章了。一键订阅,长期可用。🚀
上一篇我们概览了 RLHF 的三大对齐算法。这篇就上手最经典的那个——用 PPO 微调 LLM,把 ChatGPT 那套三步流程亲手跑一遍。
目标很具体:拿一个原始的 GPT-2,通过 SFT → 奖励模型 → PPO 三步,把它调教成一个只会输出正向情感电影评论的模型。原理和倒立摆一模一样,只是"环境"换成了"人类偏好"。
第一步:SFT,让模型先"会说"
先载入 GPT-2(124M 参数)这个"没打磨过的璞玉":
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = './gpt2'
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path)
直接让它生成文本,输出基本是胡言乱语——这就是预训练模型的原始状态。

用 sst2 电影评论数据集做 SFT。训练目标和预训练一样——预测下一个词,只不过数据换成了电影评论:
from datasets import load_dataset
ds = load_dataset('./sst2')
ds_train, ds_val = ds['train'], ds['validation']
def tokenize(batch):
return tokenizer(batch['sentence']) # 只用文本,不用情感标签
tokenized_dataset_train = ds_train.map(tokenize, batched=True, batch_size=512,
remove_columns=['idx', 'sentence', 'label'])
tokenizer.pad_token = tokenizer.eos_token # GPT2 没有pad,借eos用
用 DataCollatorForLanguageModeling 整理成"因果语言建模"(预测下一个词)的格式,然后标准训练循环跑 1 个 epoch:
from torch.utils.data import DataLoader
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False) # mlm=False → GPT风格
train_dataloader = DataLoader(tokenized_dataset_train, batch_size=16, collate_fn=data_collator)
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
for epoch in range(1): # SFT 一般就训 1 个 epoch
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.save_pretrained('./gpt2-sft')
💡 代码解析:mlm=False 表示"因果语言建模"(GPT 风格的自回归),不是 BERT 那种掩码预测。SFT 后再让模型生成,输出变成了 "this is a movie you want to watch"——终于像电影评论了。但 SFT 只教它"该说什么",还管不住"不该说什么"。
第二步:训练奖励模型,当个裁判
倒立摆里,杆子不倒环境就给奖励 1,奖励是现成的。但 LLM 没有这种环境——怎么判断模型的输出"好不好"?得自己训一个裁判,这就是奖励模型。
我们的目标:让奖励模型对正向情感的评论打高分、负向打低分。做法是把 GPT-2 接上一个线性头,输出一个标量分数:
class RewardHead(nn.Module):
def __init__(self, config):
super().__init__()
self.reward = nn.Linear(config.hidden_size, 1) # 隐藏层 → 标量
def forward(self, hidden_states):
return self.reward(hidden_states)
class GPT2RewardHead(nn.Module):
def __init__(self, model_name):
super().__init__()
self.llm = AutoModelForCausalLM.from_pretrained(model_name)
self.reward_head = RewardHead(self.llm.config)
def forward(self, input_ids, attention_mask):
outputs = self.llm(input_ids=input_ids, attention_mask=attention_mask,
output_hidden_states=True)
last_hidden = outputs.hidden_states[-1]
reward = self.reward_head(last_hidden).squeeze(-1)
return torch.sigmoid(reward) # 压到 (0,1) 区间
💡 代码解析:奖励模型 = GPT-2 主体 + 一个线性头。取最后一个隐藏层,过一个线性层得到每个 token 位置的分数,再 sigmoid 压到 0~1。我们只取句末那个"reward token"位置的分数当作整句评分。
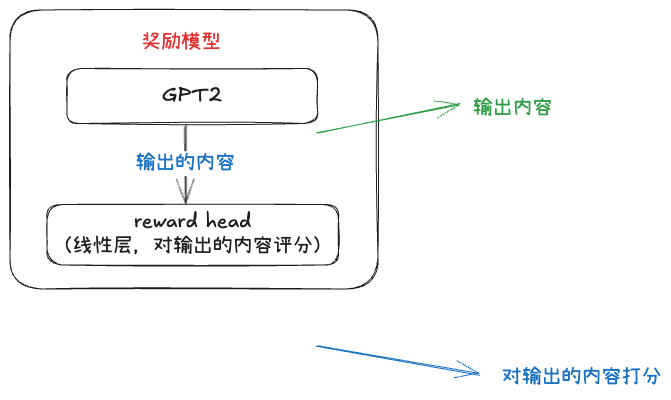
训练时用 BCE(二分类交叉熵)损失——正向情感标签为 1,负向为 0:
criterion = nn.BCELoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
for batch in train_dataloader:
scores = model(batch['input_ids'], batch['attention_mask'])
batch_indices = torch.arange(scores.shape[0])
score = scores[batch_indices, batch['score_index']] # 取reward token位置的分数
target = batch['score'] # 0 或 1
loss = criterion(score, target)
optimizer.zero_grad(); loss.backward(); optimizer.step()
torch.save(model.state_dict(), 'reward_model.pt')
训完看困惑矩阵,准确率不错(正负情感都能判对)。这个裁判可以上岗了。
第三步:PPO 微调,正式调教
万事俱备,上 PPO。核心流程是:让 SFT 模型生成回答 → 奖励模型打分 → 用 PPO 更新模型。
PPO 的损失函数(和第 6 篇的 clip 一脉相承):
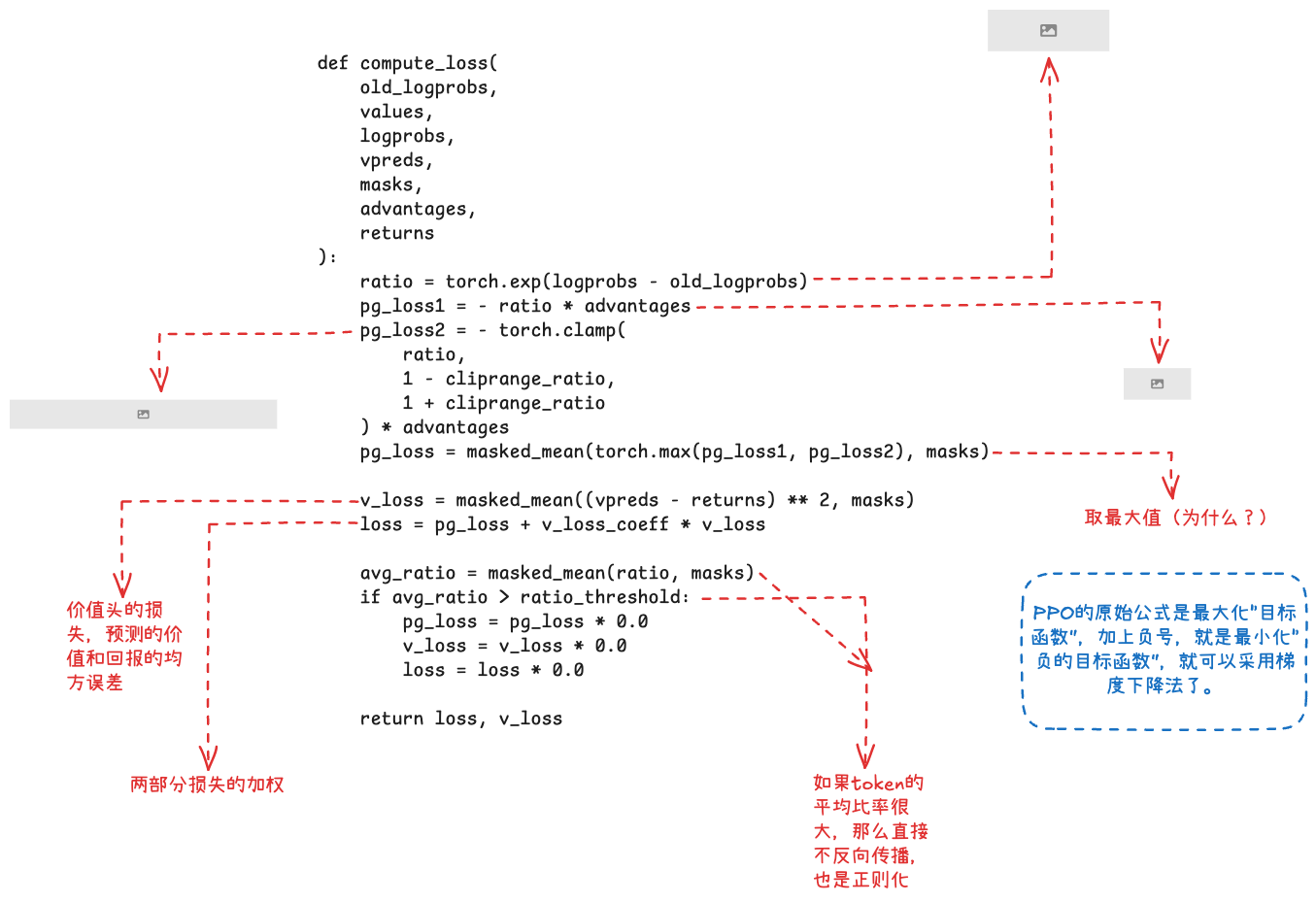
def compute_loss(old_logprobs, values, logprobs, vpreds, masks, advantages, returns):
ratio = torch.exp(logprobs - old_logprobs)
pg_loss1 = -ratio * advantages
pg_loss2 = -torch.clamp(ratio, 1 - cliprange_ratio, 1 + cliprange_ratio) * advantages
pg_loss = masked_mean(torch.max(pg_loss1, pg_loss2), masks) # PPO clip 损失
v_loss = masked_mean((vpreds - returns) ** 2, masks) # 价值网络损失
return pg_loss + v_loss_coeff * v_loss, v_loss
💡 代码解析:ratio 是新旧策略概率比,pg_loss1/pg_loss2 就是未裁剪/裁剪两项,取 max(因为加了负号,等价于原始 PPO 的 min)。再加一个价值网络的 MSE 损失。和倒立摆那篇的 PPO 损失本质相同,只是作用对象从"推车动作"变成了"生成 token"。
训练循环的主干——生成、打分、算优势、K 步微批次更新:
mini_batch_size = 4
ppo_epochs = 4 # 一批数据训 4 轮
cliprange_ratio = 0.2 # ε
for batch in train_dataloader:
query_tensors = batch['input_ids']
# ① 让 SFT 模型生成回答
query_response = model.generate(input_ids=query, **generation_kwargs)
# ② 奖励模型给这条回答打分
with torch.no_grad():
score = reward_model(query_response_score, attention_mask)[-1]
score = 2 * (score - 0.5) # 映射到 (-1, 1)
# ③ 算奖励和优势
logprobs, rewards, values, masks = compute_rewards(input_data, query_tensors,
response_tensors, score_tensors)
advantages, returns = compute_advantage(rewards, values, masks)
# ④ K 步微批次 PPO 更新
mini_batch_train()
💡 代码解析:四步循环——生成回答、奖励打分(2*(score-0.5) 把 0~1 的分数映射到 -1~1,让"差回答"得负分)、算优势、PPO 更新。mini_batch_train 内部对同一批数据重复训 ppo_epochs=4 轮,每轮切小批次——这就是 PPO"一批数据榨干再用"的特性。

跑完之后,模型生成的评论会明显偏向正向情感——PPO 调教生效了。
小结
这篇把 RLHF 三步流程跑通了:
| 步骤 | 做什么 | 关键 |
|---|---|---|
| SFT | 监督微调,让模型"会说" | 预测下一个词 |
| 奖励模型 | 训练一个裁判打分 | GPT2 + 线性头,BCE 损失 |
| PPO 微调 | 用奖励当信号调教模型 | clip 损失 + K 步微批次 |
一句话记:倒立摆的奖励是环境给的,LLM 的奖励得自己训一个裁判。PPO 就是拿着裁判的分数去调教模型的那只手。
这套 PPO 流程强大,但有点重——得单独训个奖励模型,训练时还得在线采样。下一篇的 DPO 就来简化它:干掉奖励模型,把 RL 问题直接变成分类问题。
📌 [ 笔者 ] 文艺倾年
📃 [ 更新 ] 2026.06.14
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)