
Qwen3-TTS 深度实测:在 BitaHub 快速搭建千问最新语音大模型
🚀 项目背景:AI 语音的新纪元 —— Qwen3-TTS
在 AI 生成领域,声音的自然度与实时性一直是技术攻关的难点。近日,通义千问团队发布了全新的 Qwen3-TTS 系列模型,这不仅是一次版本的迭代,更是语音合成(TTS)架构的一次大爆发。
💡 核心技术亮点
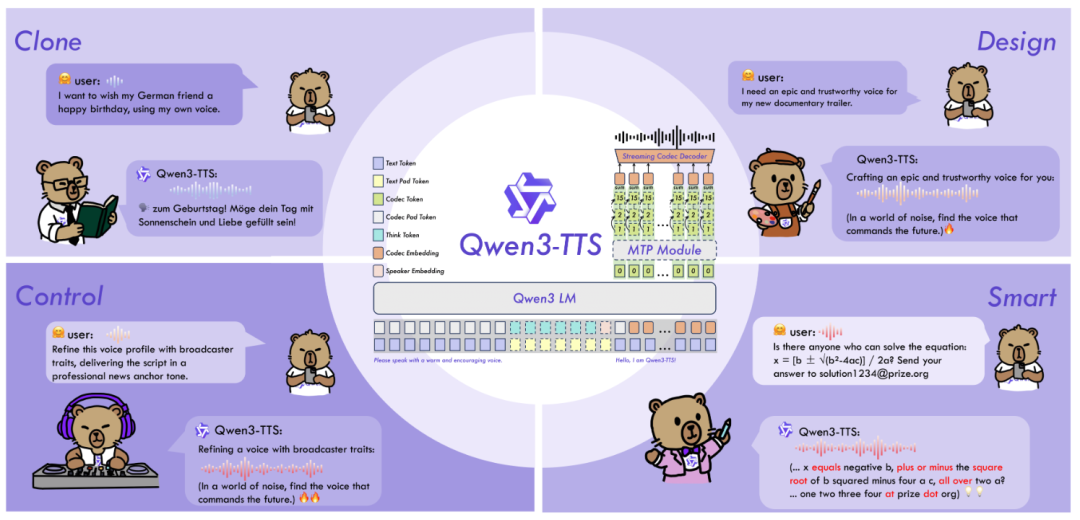
引自:https://github.com/QwenLM/Qwen3-TTS
-
全信息端到端架构: 不同于传统的“语言模型+扩散模型(LM+DiT)”方案,Qwen3-TTS 采用了离散多码本 LM 架构。这意味着它彻底告别了传统方案中的信息瓶颈和级联误差,让声音的生成更加丝滑、真实。
-
毫秒级极速响应: 凭借创新的 Dual-Track 双轨混合流式架构,Qwen3-TTS 实现了惊人的 97ms 端到端合成延迟。真正做到了“字出声随”,完美适配实时交互场景。
-
“所想即所听”的智能控制: 模型内置了强大的语义理解能力。你不再需要复杂的调参,只需通过自然语言指令(如“用温柔且轻快的语气说”),模型就能自动调整音色、情感和语速。
-
全球化语言支持: 原生支持包括中、英、日、韩、德、法、俄、葡、西、意在内的 10 种主流语言及多种方言。
📦 本次部署模型一览
在本教程中,我们将基于 BitaHub 环境,通过 ComfyUI 部署以下三款核心模型:
| 模型名称 | 核心功能 | 适用场景 |
|---|---|---|
| Qwen3-TTS-1.7B-VoiceDesign |
声音设计 |
通过描述文字“创造”出世界上独一无二的声音。 |
| Qwen3-TTS-1.7B-CustomVoice |
预设控制 |
提供 9 种涵盖不同性别、年龄和方言的高级优质音色。 |
| Qwen3-TTS-1.7B-Base |
声音克隆 |
仅需 3 秒参考音频,即可实现高保真度的快速克隆。 |
以上模型均已上传至 BitaHub 模型库。
🛠️ 部署实战:从零搭建 Qwen3-TTS 工作流
在 BitaHub 上部署 ComfyUI 并集成 Qwen3-TTS,主要分为文件准备、模型配置和环境初始化等四个阶段。
第一阶段:项目文件准备
-
克隆基础项目: 在本地或通过 BitaHub 终端克隆 ComfyUI 官方项目,并将其上传至 BitaHub 的文件存储中。
-
集成自定义节点: 由于官方 ComfyUI 尚未原生适配 Qwen3-TTS,我们采用了 HAIGC 大佬提供的开源适配项目。
-
项目地址:
https://github.com/HAIGC/Comfyui-HAIGC-QwenTTS -
操作: 将该项目下载/克隆后,上传至
ComfyUI/custom_nodes/路径下。
-
第二阶段:模型转存与路径规范
Qwen3-TTS 系列模型体积较大,建议利用 BitaHub 的模型库转存功能,直接将模型秒速同步至个人存储。请务必保持以下目录结构,以确保节点能够正确识别模型:
ComfyUI/
└── models/
└── qwen-tts/
├── Qwen3-TTS-12Hz-1.7B-VoiceDesign/ # 声音设计模型
├── Qwen3-TTS-12Hz-1.7B-CustomVoice/ # 预设声音模型
└── Qwen3-TTS-12Hz-1.7B-Base/ # 基础/克隆模型
第三阶段:创建开发环境任务
完成文件准备后,我们需要在 BitaHub 上正式启动开发环境。请按照以下步骤进行配置:
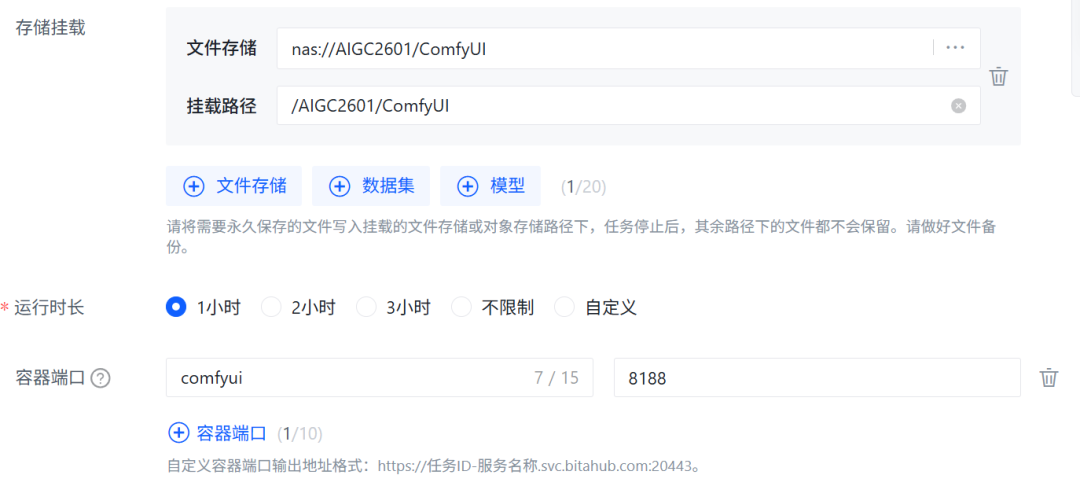
1. 任务创建与端口映射
-
挂载数据: 在创建“开发环境”任务时,务必选择挂载存放了上述
ComfyUI文件夹的存储路径。 -
定义端口: 在自定义端口处添加
8188。这是访问 ComfyUI Web 界面的默认服务端口。
2. 进入终端环境
-
启动 Jupyter: 任务状态变为“运行中”后,点击界面上的 Jupyter 入口。
-
打开终端: 在 Jupyter 界面选择
Terminal,进入命令行操作模式。
3. 虚拟环境配置 (推荐)
为避免依赖冲突,建议创建专属 Python 环境:
# 创建虚拟环境
python3 -m venv comfy_env# 激活环境
source comfy_env/bin/activate
4. 安装核心依赖与 Qwen3 专有库
进入项目根目录,依次安装 ComfyUI 基础依赖及 Qwen3-TTS 节点所需的特定环境:
# 1. 安装节点专有依赖
cd custom_nodes/Comfyui-HAIGC-QwenTTS
pip install -r requirements.txt
# 2. 安装音频处理及加速扩展库
pip install sox onnxruntime librosa soundfile accelerate
5. 项目启动与访问
回到 ComfyUI 根目录,运行启动指令:
# 返回根目录
cd ../../
# 启动服务
python main.py --listen 0.0.0.0 --port 8188
-
如何访问: 启动成功后,回到 BitaHub 开发环境任务页面,复制外部访问链接到浏览器中打开,即可进入 ComfyUI 操作界面。
第四阶段:实战演练 —— 三大模块详解
在成功启动 ComfyUI 界面后,我们即可导入精心设计的 Qwen3-TTS 工作流。Qwen3-TTS 的强大之处在于它将多种语音能力集成到了统一的架构中。在本次使用的 HAIGC-QwenTTS 插件中,我们通过三个核心工作流板块,完整覆盖了从“虚构声音”到“克隆真人”的所有场景
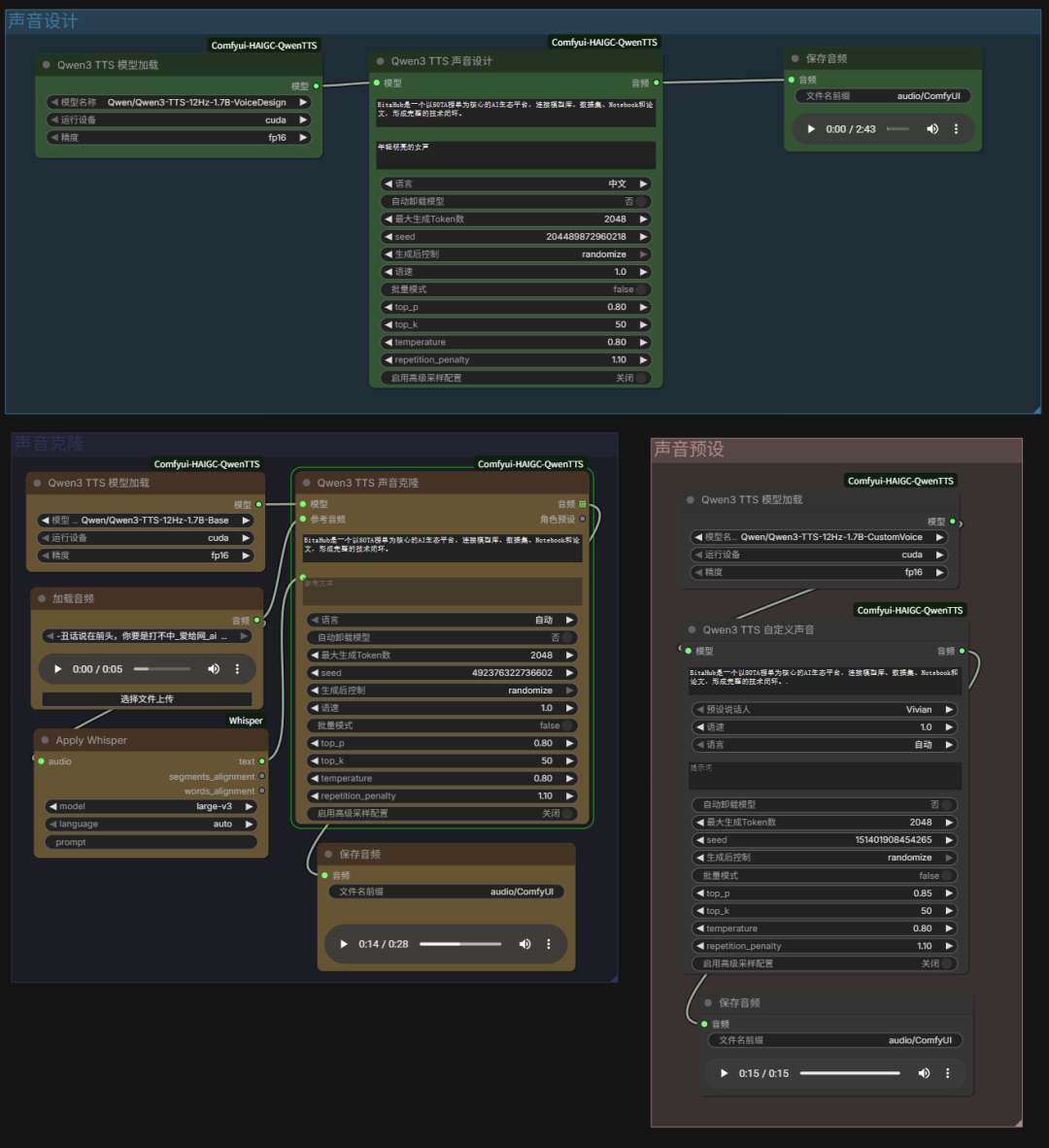
🎨 板块一:声音设计(Voice Design)
—— 凭空创造独一无二的声音
-
模型加载: 选择
Qwen3-TTS-12Hz-1.7B-VoiceDesign。 -
指令驱动: 输入 Prompt,如:“一个非常有磁性的中年男性声音,语速稍快,带着自信的语气”。
-
参数调节: 调整 Seed 改变特征,调整 Temperature 控制情感波动。
👥 板块二:声音克隆(Voice Clone)
—— 3秒素材,完美复刻
-
模型加载: 必须使用
Qwen3-TTS-12Hz-1.7B-Base。 -
Whisper 协同: 引入
Apply Whisper节点自动识别参考音频文本,反馈给引擎以大幅提升还原度。 -
操作要点: 上传 3-10 秒人声音频,输入新文本,点击运行。
🎭 板块三:自定义预设语音(Custom Voice)
—— 精品音色一键即用
-
模型加载: 选择
Qwen3-TTS-12Hz-1.7B-CustomVoice。 -
预设说话人: 内置 9 种精品音色(如 Vivian 等),覆盖全年龄段。
-
流式生成: 双轨架构支持秒级导出音频,适合长文本。
🌟 结语:开启你的 AI 创作新声代
从环境配置的“基建”到三大实战模块的“精修”,我们已经在 BitaHub 上完成了 Qwen3-TTS 的完整部署。这套工作流不仅展示了通义千问在语音领域深厚的技术底蕴,更为每一位创作者提供了将“想象”转化为“听觉”的强大工具。
Qwen3-TTS 的发布,标志着 AI 语音正式进入了高保真、低延迟且具备深度语义理解的新阶段。无论是制作极具感染力的短视频配音,还是构建毫秒级响应的智能交互助手,这套在 BitaHub 上跑通的方案都将成为你最有力的技术后盾。
技术不应是有门槛的秘密,而是触手可及的生产力。 现在,算力已经就绪,工作流已经跑通,接下来的舞台属于你的创意。希望这篇教程能帮助你在 AI 声音进化的浪潮中,先人一步抢占高地。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)