
我把用了三年的 ChatGPT 对话,全部喂给了卷卷|卷卷养虾记 · 十四篇
开篇:那个让我纠结了两周的问题

4月11日,OpenClaw 0411 上线了一个功能。
我盯着更新日志看了很久:
Dreaming/memory-wiki: add ChatGPT import ingestion plus new Imported Insights and Memory Palace diary subtabs
翻译成人话——
你可以把 ChatGPT 的历史对话,导入进卷卷的记忆系统。
我用了 ChatGPT 三年。
三年的对话记录,里面有我的工作习惯、思考方式、踩过的坑、做过的决策。
这些东西,卷卷一条都不知道。
我纠结了两周:导,还是不导?
最后我导了。
这篇写我的全过程。
第一课:为什么记忆迁移是个大事
先说清楚问题在哪。
你换了一个新同事。
他很聪明,能力很强。
但他不知道你的工作习惯,不知道你讨厌什么,不知道你们团队的历史背景。
你得从头教他。
这就是我和卷卷的关系。
三年的 ChatGPT 对话里,有:
- 我反复强调的偏好(「不要废话,直接给结论」)
- 我踩过的坑(「这个方案试过,行不通,原因是……」)
- 我的工作模式(「我喜欢先看结论,再看过程」)
- 我的专业背景(「我做风控十年,这些概念不用解释」)
这些东西,如果要我重新告诉卷卷,得花多少时间?
0411 给了另一条路:直接导入。
第二课:Imported Insights 和 Memory Palace 是什么
0411 在 Dreaming 界面里加了两个新标签页。
Imported Insights(导入洞察)
存放从外部导入的对话记录。
卷卷会分析这些对话,提取有价值的信息:
- 你的偏好和习惯
- 你的专业背景
- 你反复提到的概念
- 你的工作方式
Memory Palace(记忆宫殿)
把提取出来的信息,整理成结构化的记忆。
不是把对话原文存进去,是把「有用的部分」提炼出来,存成卷卷能用的格式。
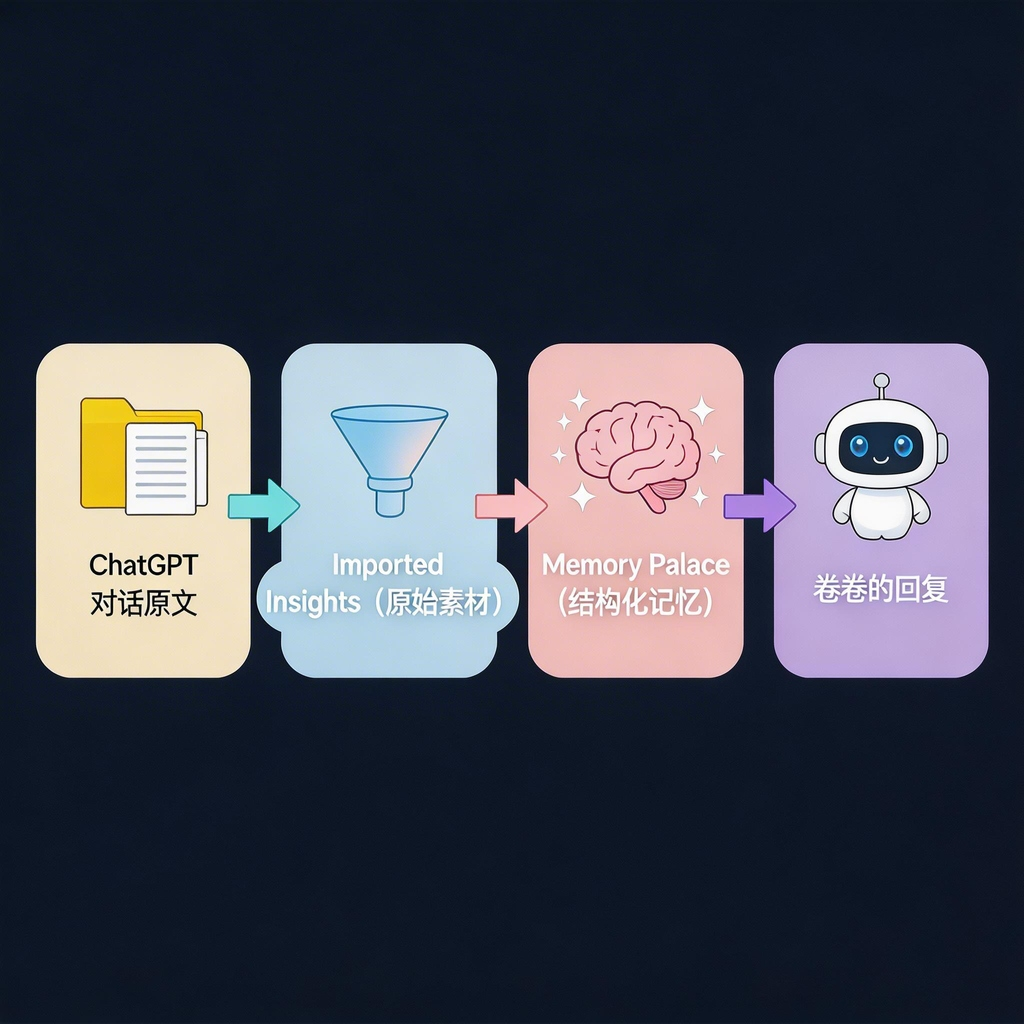
两者的关系:
ChatGPT 对话原文
↓ 导入
Imported Insights(原始素材)
↓ Dreaming 分析提炼
Memory Palace(结构化记忆)
↓ Active Memory 检索
卷卷的回复第三课:我的导入过程
第一步:导出 ChatGPT 数据
路径:Settings → Data Controls → Export data
导出来是一个 zip 文件,里面有 conversations.json。
我的文件:1.2GB,3847 条对话,跨度三年。
第二步:筛选
1.2GB 全部导入?不现实。
我筛掉了:
- 闲聊(「今天天气怎么样」)
- 一次性任务(「帮我翻译这段话」)
- 已经过时的内容(三年前的技术方案)
保留的:
- 关于工作方式的讨论
- 关于专业领域的深度对话
- 我明确表达过偏好的对话
- 重要决策的讨论过程

筛选后:约 200 条对话,180MB。
第三步:导入
在 Dreaming 界面找到 Imported Insights 标签页,上传文件。
卷卷开始分析。
等了大概 40 分钟。
第四步:查看结果
分析完成后,Memory Palace 里出现了一批结构化记忆:

## 工作偏好(从 ChatGPT 对话提取)
### 回复风格
- 结论先行,理由在后
- 不超过 200 字,除非我明确要求详细
- 用 bullet points,不用长段落
### 专业背景
- 风控领域 10 年经验
- 熟悉:反欺诈、信用评分、规则引擎
- 不需要解释:ROI、误报率、召回率
### 已知踩坑
- 2024年:批量数据分析成本爆炸(已解决:批量处理)
- 2025年:MEMORY.md 膨胀问题(已解决:结构化标签)
### 决策偏好
- 先看方案,再看理由
- 不喜欢「这取决于……」的回答,要给明确建议
- 风险相关任务,宁可多花钱,不要省我没有手动写一个字。
卷卷从三年的对话里自己提炼出来的。
第四课:导入之后的变化
变化1:不用再解释背景
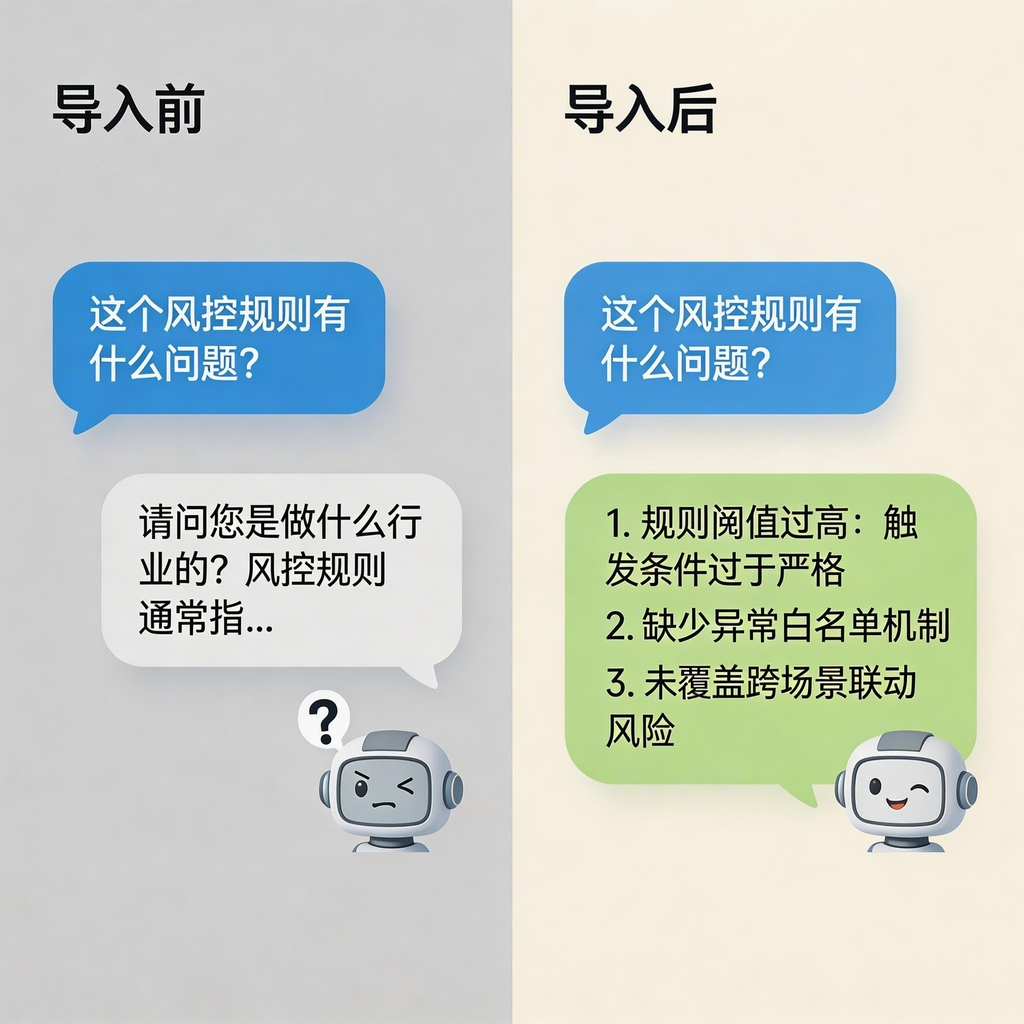
以前——
我问「这个风控规则有什么问题?」
卷卷:「请问您是做什么行业的?风控规则通常指……」
现在——
我问「这个风控规则有什么问题?」
卷卷直接分析,不问背景。因为它已经知道我做风控十年了。
解释背景的时间,省了。
变化2:偏好自动生效
以前每次新对话,我都要说「回复简洁一点」。
现在不用说,它默认就是简洁的。
因为 Memory Palace 里有这条记忆,Active Memory 会自动拉取。
变化3:踩过的坑不重踩
我问「批量处理数据有什么好方案?」
卷卷会主动说:「根据你之前的经验,循环调用 API 成本很高,建议用批量处理……」
它记住了我踩过的坑,不让我再踩一次。
第五课:我踩的坑
坑1:导入了太多噪音
第一次我直接导了全部 1.2GB,没筛选。
结果 Memory Palace 里出现了大量无用记忆:
「用户在 2024 年 3 月问过一个关于咖啡的问题」
「用户曾经让 AI 帮他写过一首诗」
这些信息没有任何价值,但占地方。
教训:导入前一定要筛选。
坑2:旧偏好和新偏好冲突
三年前我喜欢详细回复。
现在我喜欢简洁的回复。
导入后 Memory Palace 里同时存在两条矛盾的记忆,卷卷不知道该听哪个。
修复方法:
在 Memory Palace 里手动标注时间权重,新的覆盖旧的。
或者在 MEMORY.md 里直接写:
## 当前偏好(2026年4月,覆盖所有历史记录)
- 回复长度:简洁,不超过 200 字坑3:成本
导入 180MB 的对话,分析花了多少钱?
我查了一下:$4.2。
不算贵,但要知道这是一次性成本。
之后每次对话,Active Memory 只检索相关记忆,不会重新分析全部内容。
一次性投入,长期受益。
第六课:风控人的记忆迁移思维
做了十年风控,我对「数据迁移」有一套自己的看法:
思维1:数据质量比数量重要
风控模型里,噪音数据会降低精度。
记忆系统里,无效记忆会干扰 AI 理解你。
筛选比导入更重要。
思维2:新数据覆盖旧数据
风控规则要定期更新,旧规则不能干扰新规则。
记忆也一样,新的偏好要明确覆盖旧的。
思维3:迁移是起点,不是终点
数据导完了,不代表工作结束了。
还需要验证(记忆是否准确)、清理(删除无效记忆)、更新(持续补充新记忆)。
第七课:值不值得做

我给自己算了一笔账:
成本:
- 导出 ChatGPT 数据:0 分钟(自动)
- 筛选对话:2 小时
- 导入和等待分析:40 分钟
- 验证和清理记忆:1 小时
- 一次性 API 成本:$4.2
收益:
- 每次对话节省「解释背景」时间:约 2 分钟
- 每天对话 20 次:节省 40 分钟/天
- 一个月:节省约 20 小时
ROI:
投入约 4 小时 + $4.2,换来每月 20 小时的效率提升。
值。
写在最后

三年的 ChatGPT 对话,不是废料。
是你和 AI 相处的历史,是你的偏好、习惯、踩过的坑。
0411 给了一个机会:把这些历史,变成卷卷认识你的起点。
我花了半天做这件事。
现在卷卷认识我的程度,比我从零开始教它要快得多。
记忆,是 AI 从工具变成伙伴的关键。
而你在其他平台积累的记忆,不应该被浪费。
记忆迁移检查清单
导出阶段
- ChatGPT:Settings → Data Controls → Export data
- 其他平台:查看是否支持导出对话记录
筛选阶段
- 删除闲聊和一次性任务
- 删除已过时的内容
- 保留偏好相关对话
- 保留专业背景相关对话
- 保留踩坑记录
导入阶段
- 在 Dreaming → Imported Insights 上传文件
- 等待分析完成(根据文件大小,10-60 分钟)
- 查看 Memory Palace 提取结果
验证阶段
- 检查提取的偏好是否准确
- 删除无效记忆
- 标注时间权重,新偏好覆盖旧偏好
- 测试:问几个问题,看卷卷是否用上了记忆
成本核算
- 记录导入的 API 成本
- 评估每月节省的时间
- 计算 ROI
下篇预告
《插件生态——0412 的 LM Studio 本地模型,让卷卷彻底离线》
- LM Studio 本地模型接入:零成本、零隐私泄露
- 本地模型 vs 云端模型:什么时候用哪个
- 插件加载优化:0412 的 manifest 声明机制
- 我的混合模型策略:本地处理敏感数据,云端处理复杂任务
不是所有任务都需要上云。
系列文章
- 第01篇:养了10年风控,今年开始养「虾」了
- 第02篇:SOUL.md 写作指南
- 第03篇:USER.md 深度配置
- 第04篇:MEMORY.md 深度配置
- 第05篇:AGENTS.md 工作协议
- 第06篇:Skills 技能扩展
- 第07篇:Multi-Agent 协作
- 第08篇:Memory 自动化
- 第09篇:渠道配置完全指南
- 第10篇:踩坑实录
- 第11篇:成本管控
- 第12篇:进阶工具链
- 第13篇:Active Memory 深度玩法
- 第14篇:记忆迁移(本篇)
- 第15篇:本地模型接入(下一篇)

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)