
5万亿参数打通四大模态,GPT-6这次不是缝合怪
我上周试了一下让 AI 同时"看"一段产品演示视频、"听"里面的讲解、再对照 PDF 说明书写竞品分析。
结果呢?视频理解调一个模型,语音识别调另一个,文字处理又是第三个。三套 API 下来,光是处理数据格式对齐就花了两小时。中间还踩了个坑——视觉模型输出的 JSON 结构跟语言模型期望的格式对不上,排查了半天。
当时就想:这破玩意什么时候能一个模型全搞定?
答案是4月14号。OpenAI 确认 GPT-6——内部代号"Spud"(土豆)——将在那天全球同步发布。
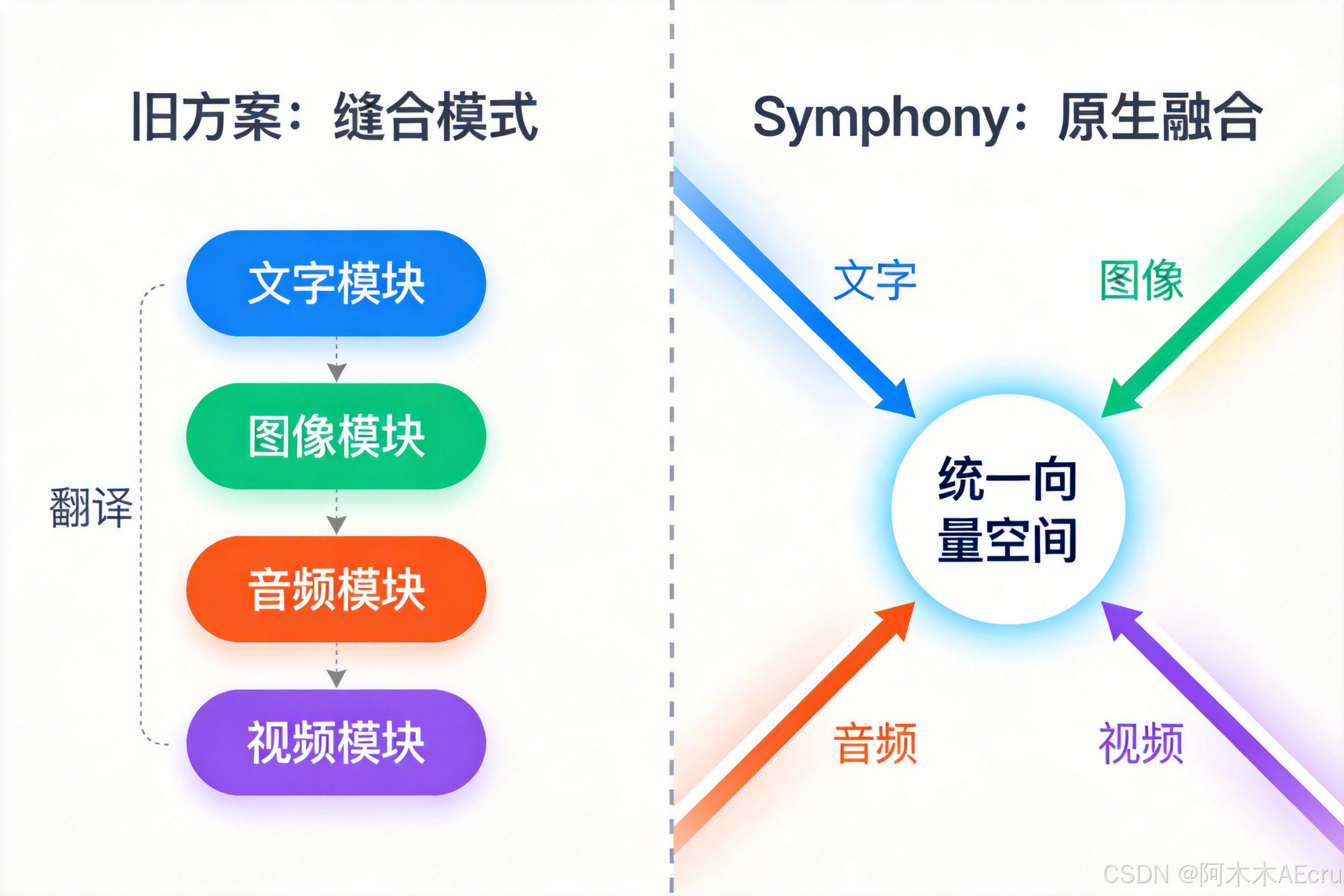
这次不一样:不是"缝合",是"融合"
之前的多模态模型怎么做的?简单粗暴——一个文本模型当大脑,外挂视觉模块、音频模块、视频模块。就像给一辆汽车硬焊上飞机翅膀和船桨,理论上能跑能飞能游,实际上哪个都不精。
GPT-6 换了个路子。它用了代号"Symphony"的底层架构,把文本、图像、音频、视频全部映射到同一个向量空间里。
什么意思?以前 AI 看到一张猫的图片,得先"翻译"成文字"这是一只猫",再把文字丢给语言模型处理。现在不用了——图片里的猫和文字里的"猫"在底层就是同一个数学表示,AI 天生就知道它们是同一个东西。
从"翻译官模式"升级到"母语模式"。
跨模态推理终于不靠"传话"了。
以前让 AI “看这个视频,回答音频里提到的问题”,它得先用视觉模型看画面,再用语音模型听声音,然后用语言模型把两者串起来。中间每一步都可能丢信息——就像你让三个人传一句话,传到第三个人耳朵里已经面目全非。
Symphony 架构下,视频画面里的产品外观、音频里的技术参数、文字文档里的规格表——在同一个空间里直接产生关联。不需要中转,不需要翻译,不丢信息。
据 Epsilla 4月5日发布的分析,这种"原生多模态"被行业视为 AGI 路上的关键一跳。因为真正的通用智能,本来就不该有"我只会处理文字"这种限制。
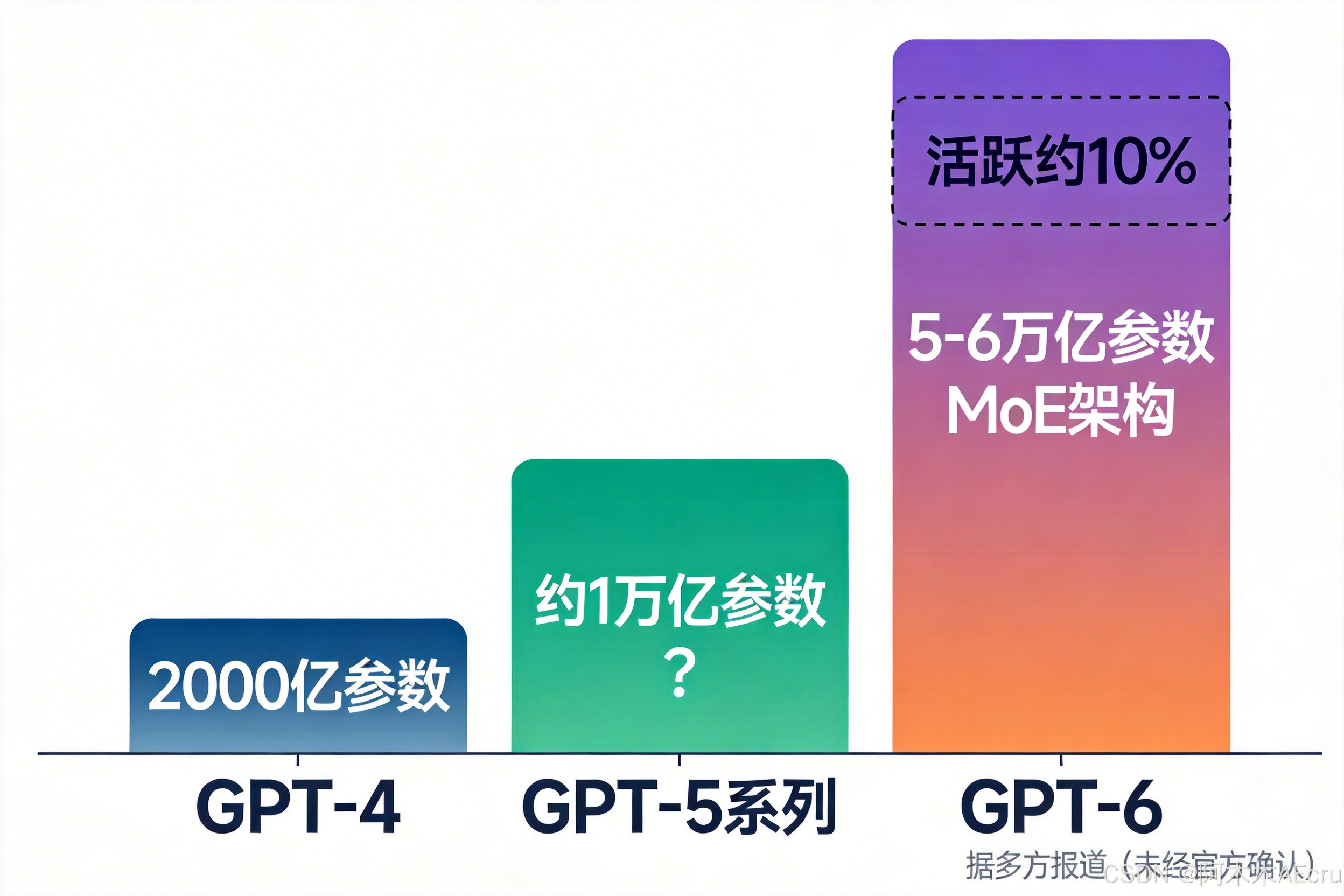
5到6万亿参数,但每次只用十分之一
GPT-6 的参数规模在5到6万亿之间。听着吓人——但它用的是 MoE 架构(Mixture of Experts,混合专家),每次推理只激活大约10%的参数。
打个比方:你有一个6万人的专家团队,但每次开会只叫相关的6000个人。不用全员到场,效率高,成本也低。
对比一下前几代的数字就更有感觉了:
GPT-4 大约2000亿参数。GPT-5系列参数规模没公开,但多方估计在万亿级。GPT-6 直接干到5-6万亿——活跃参数大约5000到6000亿,跟 GPT-4 全量参数一个量级,但每次推理的"大脑密度"远超前辈。
训练投入超过20亿美元,用了大约10万块 H100 GPU。这个烧钱速度,放眼全球也就 OpenAI 有这个底气——他们刚以8520亿美元估值完成史上最大私募融资,亚马逊一家就投了500亿美元。据 The Information 报道,其中350亿还绑定着 IPO 或 AGI 里程碑的条件。
200万 Token 上下文
GPT-6 的上下文窗口扩展到200万 Token。
200万 Token 大概是3000页英文文本,翻译成中文差不多是一部《三体》三部曲的体量。把整部小说丢进去,它还记得第一章里那个不起眼的伏笔。
对企业用户来说这意味着什么?你公司的全部产品文档、用户手册、API 文档、历史邮件——一股脑全塞进去,不会"忘"。之前用 RAG 做文档问答,经常因为检索不准答非所问。现在直接全塞上下文里,省了检索环节,准确性上一个台阶。
当然,200万 Token 的推理成本不会便宜。普通用户日常聊天大概率用不到这个上限,但对企业级场景——法律合同审查、代码仓库级重构、跨年份数据分析——这是刚需。
比 GPT-5.4 强40%是什么概念
据多家媒体报道,GPT-6 在主流基准测试上比 GPT-5.4 提升了约40%。
40%听起来不够炸?GPT-5.4 本身已经是当前最顶级模型之一。在这个基础上再提40%,相当于百米跑从9秒58进到8秒以内——到了这个级别,每0.01秒都难如登天。
具体到能力上:编程方面,据泄露的基准测试信息,GPT-6 在 SWE-bench 上的表现大幅领先前代;复杂逻辑链条的错误率显著下降;而多模态协同——看图写代码、听音频做总结、看视频写分析——这些跨模态任务的流畅度提升非常明显。
更关键的细节是,GPT-6 集成了 GPT-5.3-Codex 的编程能力,在电子表格、演示文稿和文档处理上也有明显加强。这不是"什么都能干但什么都一般"的万金油,而是在保持广度的同时往专业深度又挖了一层。
但 GPT-6 不是唯一的主角
4月6号,一个叫 Mythos 的模型匿名发布,直接叫板 GPT-6。还有个 Happy House,在视频生成领域把 Seedance 2.0 的垄断给破了——VideoGen 专业评分96.7分 vs 78.3分,不是小赢,是碾压。
这三件事凑在一起,其实画出两条路:
全能通用派以 GPT-6 为代表,先把基础能力做到极致,什么都能干。代价是某个细分领域可能不如专门优化的模型。
专业垂直派以 Mythos、Claude Opus 4.6 为代表,只在一个领域做到极致。Claude Opus 4.6 聚焦金融、法律、代码,定价是 GPT 系列的两倍,付费用户却翻番了——市场愿意为"专业"买单。Seedance 2.0 聚焦视频生成,单月营收超3亿,企业 API 最低消费1000万一年,照样排队。
所以呢?短期看,垂直模型在特定领域确实更香。但长期看,当通用模型的基础能力足够强,"专业优势"会被逐步侵蚀。就像 iPhone 的相机不一定比单反好,但90%的场景已经够用了。
GPT-6 最大的杀手锏不是5万亿参数,是 Symphony 架构——四种模态底层打通,意味着它可以同时看、听、读、写,而且这些能力之间不再是各自为战,而是会互相增强。
“AGI最后一公里”?先别开香槟
OpenAI 内部把 GPT-6 定位为"AGI 的最后一公里"。OpenAI 总裁 Greg Brockman 最近公开说:“我觉得我们已经到70-80%了,非常接近了。还有一两年就能实现 AGI。”
我持保留意见。
“最后一公里"这个说法在 AI 圈已经被用了至少三年。每次新一代模型出来,都有人说"AGI 快了”。但 AGI 的定义本身就模糊——如果标准是"能在大多数认知任务上达到人类水平",GPT-6 确实迈了一大步。但如果标准是"真正理解世界而不只是模式匹配",那我们离终点可能比 OpenAI 愿意承认的更远。
OpenAI CEO Sam Altman 2月份在印度 AI 峰会上说 OpenAI “基本上已经构建了 AGI”。CFO Sarah Friar 却公开表示公司还没达到上市所需的合规和治理透明度标准。内部口径都不统一,AGI 就先别急着宣布了。
有一件事倒是确定的:Symphony 架构解决了多模态 AI 最根本的问题——不同感官之间的"语言障碍"。这是正确方向上的一大步。至于 AGI 到底什么时候来,我赌2028年之前没人敢真正宣布"我们做到了"——不是因为技术不够,是因为没人敢下这个定义。
4月14号 GPT-6 就发布,到时候自己去试。你觉得 Symphony 的四模态底层融合是真突破还是噱头?评论区扣1(真货)扣2(噱头),我押1。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)