
华盛顿大学发布 VFIG:复杂图表一键转 SVG,性能直逼 GPT-5.2

在科研和设计工作中,我们经常会遇到一个令人头疼的问题:好不容易在论文里看到一张精美的架构图或流程图,想要借鉴修改,却发现手头只有一张“糊掉”的位图(如 PNG 或 JPEG)。由于原始的矢量源文件丢失,我们不得不手动在 Visio 或 PPT 里一笔一画地重勾,这简直是效率杀手。
为了打破这一僵局,来自华盛顿大学、艾伦人工智能研究所(Allen Institute for Artificial Intelligence)以及北卡罗来纳大学教堂山分校(UNC-Chapel Hill)的研究团队提出了一套名为 VFIG 的解决方案,Vectorizing Complex Figures(复杂图表矢量化)的缩写,意在强调其能够将复杂的科学图表精准地转化为高保真、可编辑的 可缩放矢量图形(Scalable Vector Graphics, SVG) 代码。它不仅能“看懂”图表,还能写出结构清晰的代码,让位图重建成可编辑文件的过程变得自动化。

-
论文地址: https://arxiv.org/abs/2603.24575
-
项目主页: https://vfig-proj.github.io
为什么现有的模型搞不定复杂图表?
其实,将图像转为 SVG 并不是新鲜事。传统的轮廓追踪技术(如 VTracer)虽然能还原像素,但生成的代码全是密密麻麻的路径(Path),根本没法二次编辑。而最近兴起的 视觉语言模型(Vision-Language Models, VLMs) 虽然能写代码,但在面对复杂的科学图表时,往往会遇到“Token 爆炸”和“逻辑混乱”的问题:图表里的连线对不准、文字重叠、或者生成的代码太长导致模型直接罢工。
VFIG 的出现,正是为了解决这些痛点。它不仅仅是一个模型,更是一整套从数据构建到强化学习训练的完整方法论。
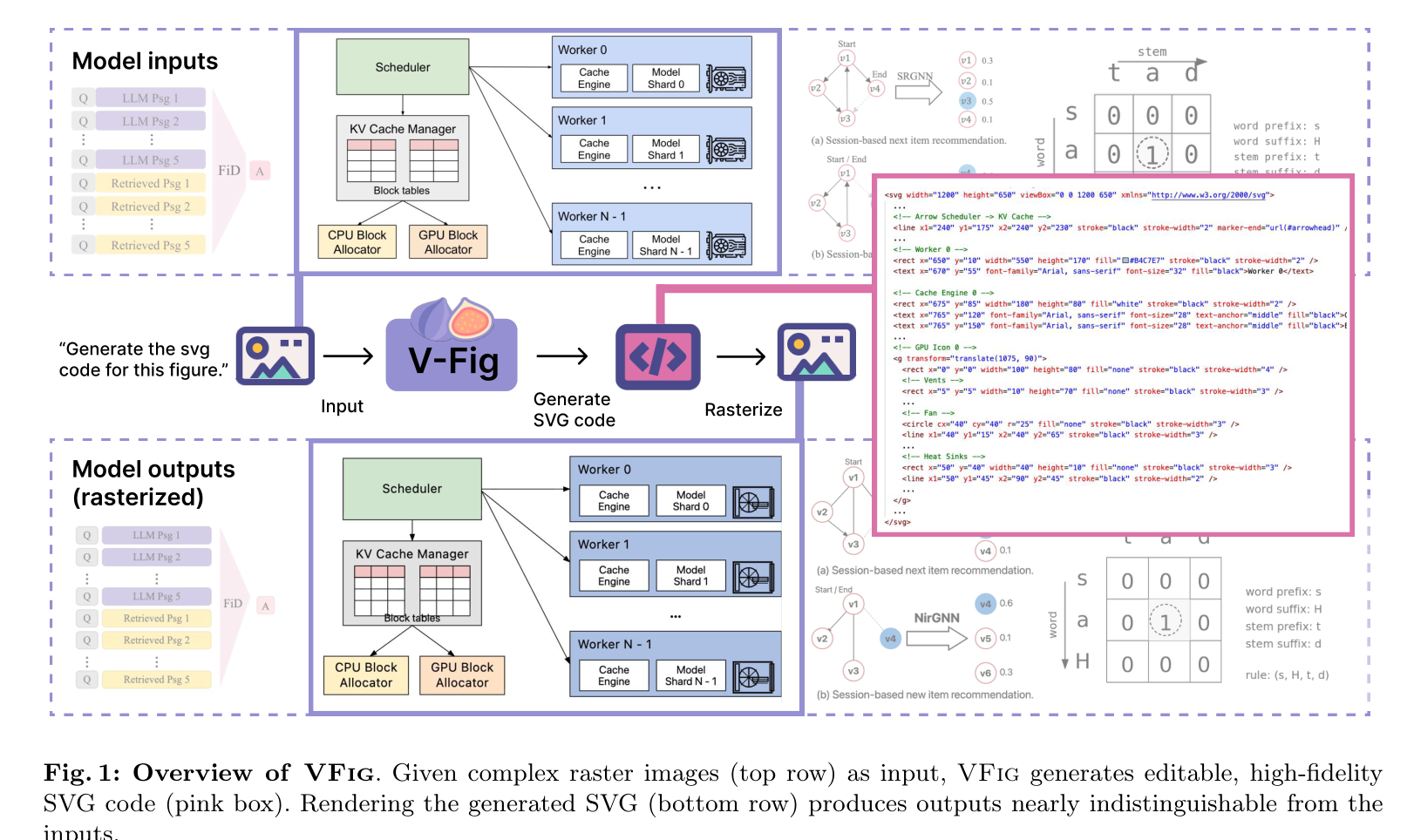
VFIG 概览:输入复杂的位图,输出高质量、可编辑的 SVG 代码
方法详解:从 6.6 万对高质量数据开始
要让模型学会画图,高质量的“教科书”必不可少。研究团队构建了一个名为 VFig-Data 的大规模数据集,包含约 6.6 万对图像-SVG 数据对。
1. 数据的“精挑细选”与“点石成金”
团队通过两个渠道获取数据,确保了图表的多样性与专业性:
-
真实论文图表(VFig-Data-Complex-Diagrams):从 25 万份 arXiv 论文中抓取真实图表。为了把位图转回高质量 SVG,他们设计了一个“先描述再生成”的流水线:先让 VLM 详细描述图表的结构,再根据描述生成代码。这种方式比直接生成要精准得多。
-
程序化合成(VFig-Data-Shapes-and-Arrows):为了让模型掌握基本功,团队用代码随机生成了各种形状、箭头和布局。这部分数据虽然简单,但属性标注极度精准,是模型打地基的关键。
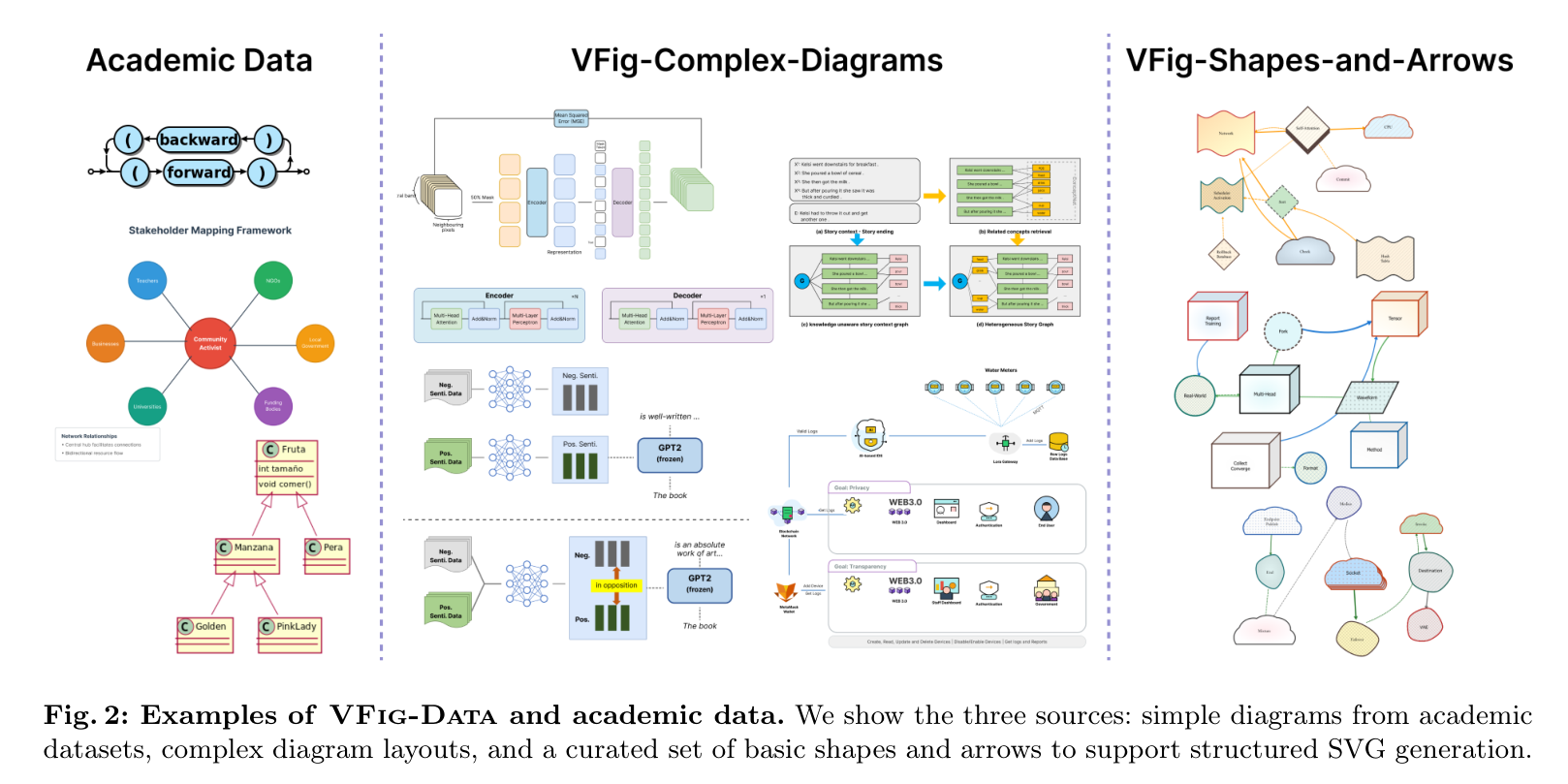
VFig-Data 数据集示例:涵盖了学术图表、复杂布局以及基础形状箭头
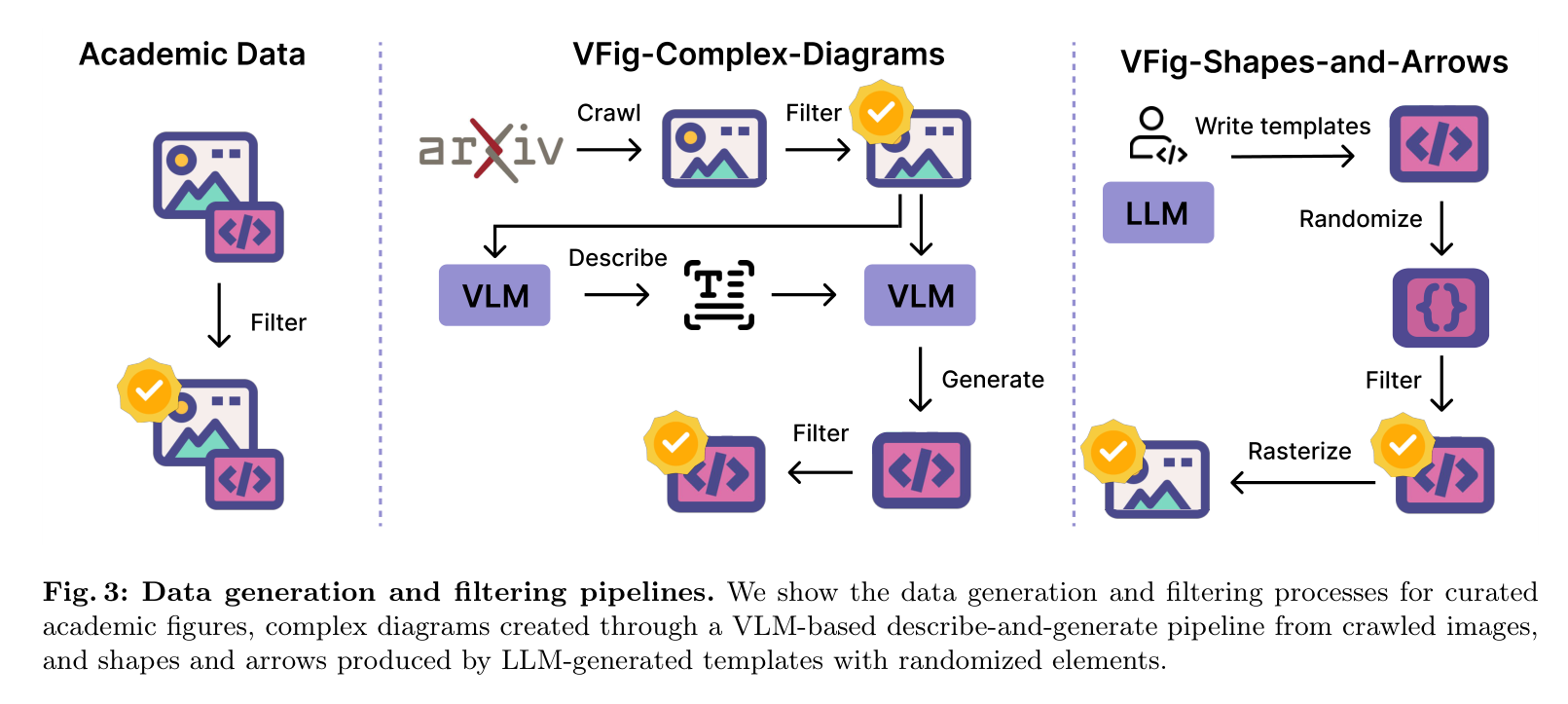
数据生成与过滤流水线:包含真实论文抓取和程序化合成
2. 拒绝“代码垃圾”:代码过滤机制
为了避免生成的 SVG 代码过于臃肿,VFIG 引入了严格的过滤机制。它优先使用几何原语(如 <rect>、<circle>)而不是自由路径(<path>)。
具体来说,团队设定了两条硬性规则:
-
基础形状和连接器的比例必须至少达到 40%。
-
复杂形状(如 path)的绝对数量不能超过 50 个。
这不仅让代码量减少了,还让生成的图表在视觉上更整洁,也更容易被人类编辑。
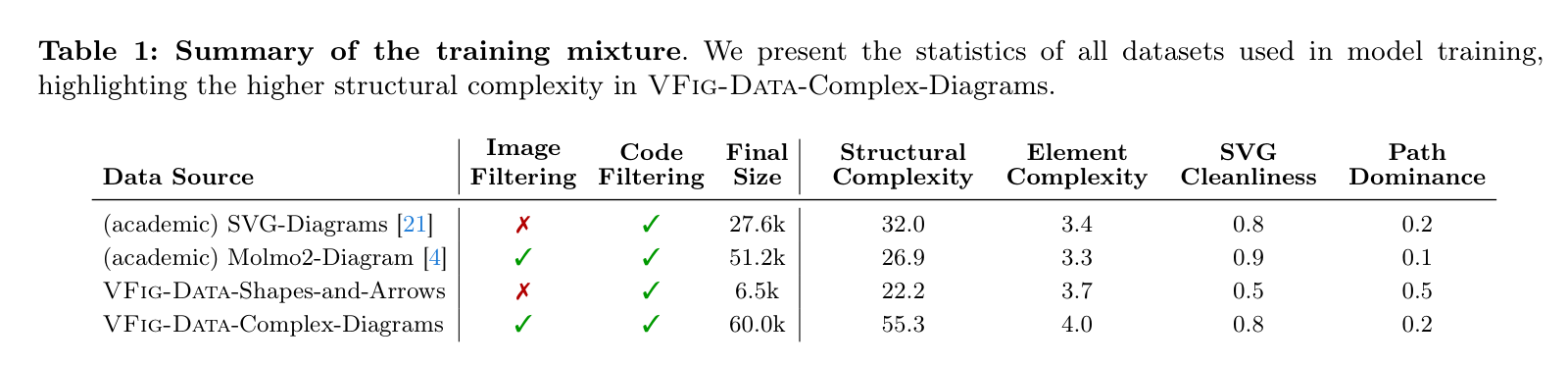
VFig-Data 数据集统计信息:展示了不同来源数据的复杂度与清洁度
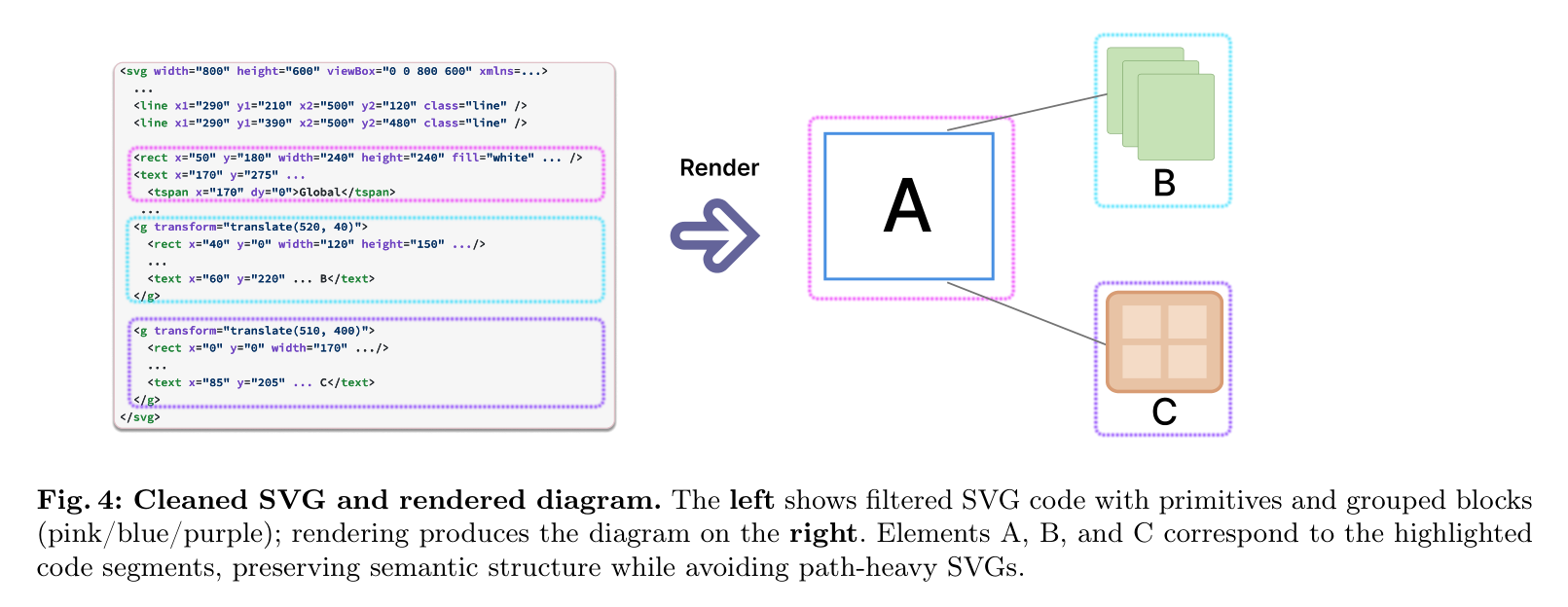
清洗后的 SVG 代码与渲染图对比,保留了语义结构并避免了路径堆砌
训练策略:两阶段课程学习与强化学习
VFIG 的训练过程,采用了“由易到难”的策略。
第一阶段:监督微调(SFT)
模型首先在简单的合成数据上学习如何画基础形状和连线,然后再过渡到复杂的真实论文图表。这种 课程学习(Curriculum Learning) 策略避免了模型在一开始就被复杂的布局搞晕。
其监督损失函数遵循标准的交叉熵损失:
其中 是输入图像,
是目标 SVG 代码。在硬件方面,这一阶段在 5 张 NVIDIA L40S GPU 上完成。
第二阶段:基于视觉反馈的强化学习(RL)
这是 VFIG 性能飞跃的关键。团队采用了 组相对策略优化(Group Relative Policy Optimization, GRPO) 算法,通过渲染后的视觉效果给模型打分。他们发现,传统的像素级指标(如 SSIM)并不好用,因为一个像素的偏差可能只是颜色深浅,但一个箭头的断开却是逻辑错误。
因此,他们引入了基于 VLM 裁判(使用 Gemini-3-Flash)的四维度评分奖励 :
-
存在性(Presence):该有的方块和文字是不是都在?
-
布局(Layout):位置和对齐准不准?
-
连通性(Connectivity):箭头是不是连对了地方?(这对流程图至关重要)
-
细节(Details):字体、颜色和描边是否还原?
强化学习阶段在 4 张 NVIDIA L40S GPU 上运行了约 30 小时,通过不断采样并比较不同生成的 SVG 效果,模型学会了如何生成更符合逻辑的图表结构。
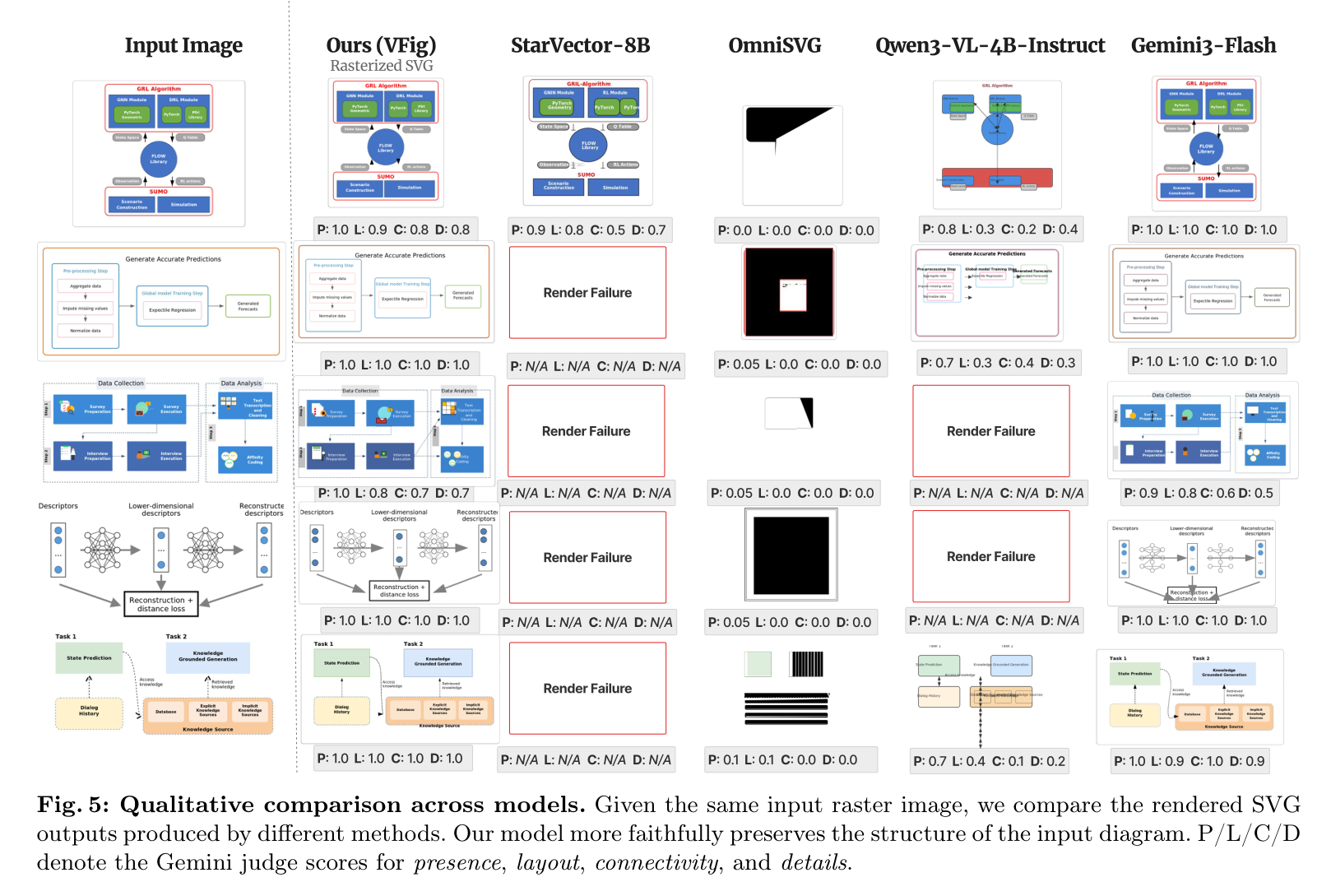
不同模型生成的 SVG 渲染效果对比,VFIG 在结构和连通性上表现更优
实验结果:开源界的最强选手
研究团队在自建的 VFig-Bench 以及 Molmo2、StarVector 等多个基准测试上进行了评估。
结果显示,VFig-4B (SFT+RL) 在各项指标上全面超越了现有的开源模型(如 OmniSVG、StarVector)。更令人惊喜的是,它的表现已经可以与闭源巨头 GPT-5.2 和 Gemini-3-Pro 掰掰手腕。
-
性能数字:在 VFig-Bench 上,VFIG 取得了 0.829 的 VLM-Judge 分数,远高于 Qwen3-VL-4B 的 0.466。
-
渲染成功率:得益于强化学习对语法规范的约束,VFIG 生成的代码渲染成功率高达 96% 以上。
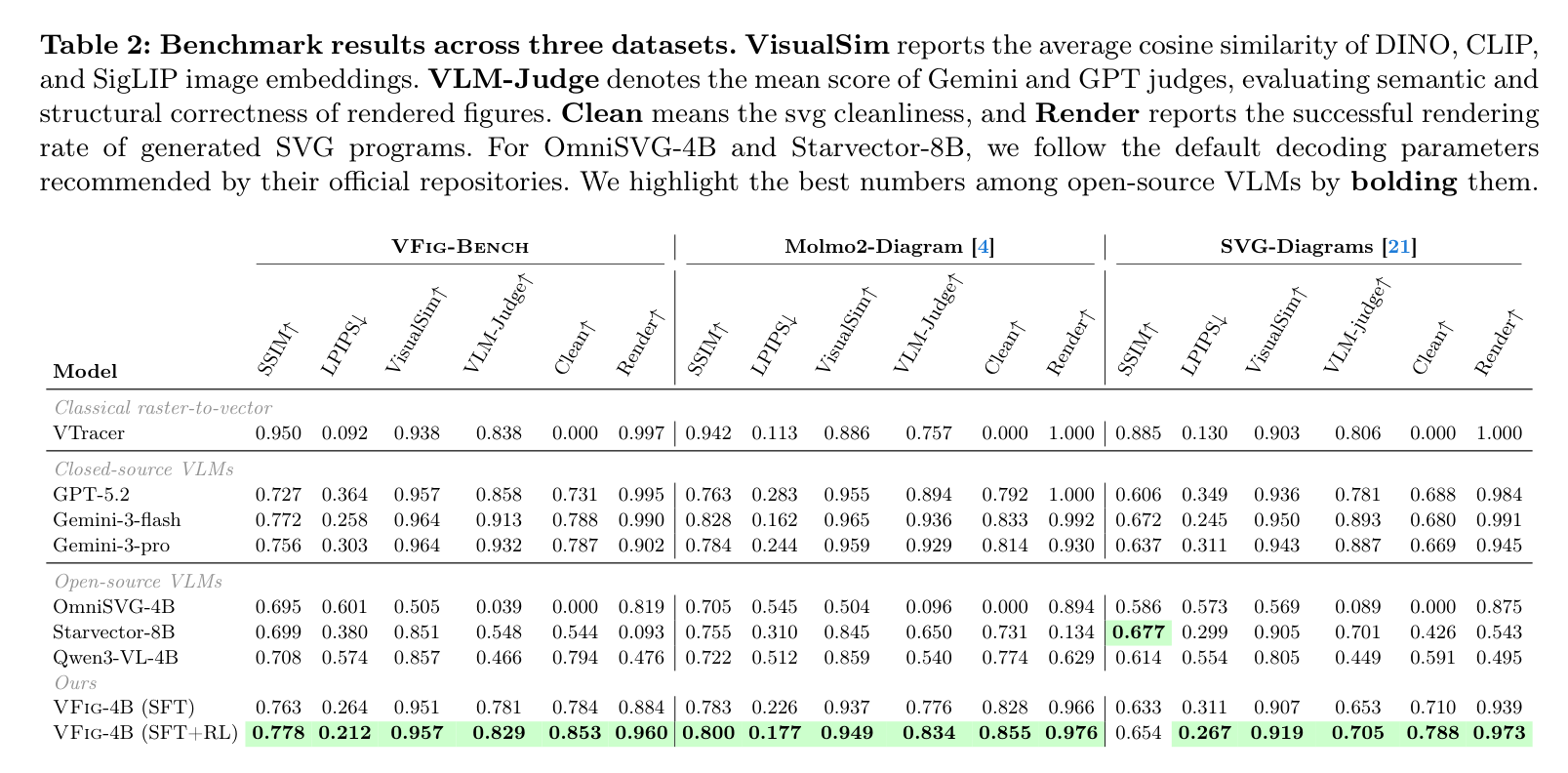
基准测试结果:VFIG 在多个数据集上均取得开源模型中的 SOTA
在消融实验中,团队还发现,使用 Qwen3-VL 作为底座的效果显著优于 InternVL 或 Qwen2.5-VL,这说明强大的视觉理解能力是矢量化的基础。
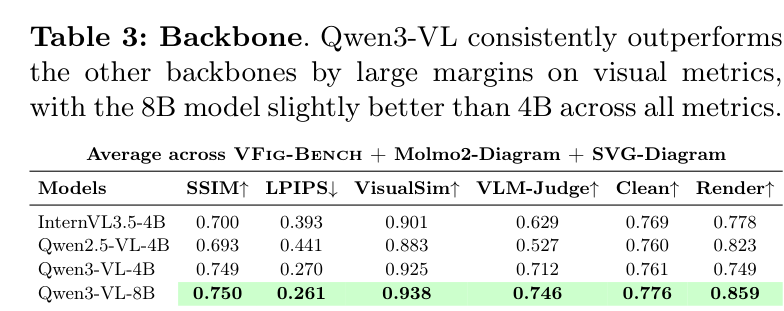
不同底座模型的性能对比,Qwen3-VL 表现突出
写在最后
VFIG 证明了一个观点:对于像 SVG 生成这样高度结构化的任务,高质量的领域数据 和 针对性的强化学习反馈 比单纯堆参数量更有效。通过引入“结构化奖励”,VFIG 克服了传统 VLM 在几何布局上的短板。
目前,该项目 6.6 万条训练数据已开放下载,期待代码、模型开源。对于经常需要处理论文图表的同学来说,这无疑是一个福音。虽然它在处理极细微的纹理或复杂的 3D 效果时仍有提升空间,但作为一款开源工具,它已经为自动矢量化树立了一个新的标杆。
你是否也曾为重画论文架构图而抓狂?或许 VFIG 就是那个能帮你省下几个小时摸鱼时间的“黑科技”。

入群加好友(v:xiao-ma-baoli),请备注你感兴趣的技术方向

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)