
大模型技术深度解析:从LLM到Agent,Java开发者必备指南
前言
近两年来,大模型技术完成了从学术突破到工业化落地的快速跃迁,LLM、RAG、Agent、Skill这四个核心概念,已经成为每个技术人绕不开的话题。但我发现,行业内充斥着大量模糊解读、错误认知甚至玄学化的表述:有人把RAG等同于向量数据库,有人把Agent简单理解为LLM+工具调用,有人混淆了Skill与Function Calling的边界,更有很多Java开发者,看着Python生态的碎片化教程,不知道如何在熟悉的Java技术栈中落地这些技术。
第一章 正本清源:四大核心概念的边界与全景定位
在拆解细节之前,我们先通过全景架构图,明确四个概念的层级关系、依赖关系与协同逻辑,从根源上避免概念混淆。
从架构图可以清晰看到四个概念的核心定位:
- LLM是底层核心引擎:相当于汽车的发动机,所有理解、推理、决策能力都源于此,是其他三个概念的基础;
- RAG是知识增强组件:相当于给发动机配了高精度导航与专属知识库,解决LLM知识滞后、幻觉、专业知识不足的问题,让回答有权威依据;
- Skill是能力扩展组件:相当于汽车的功能配件(轮胎、刹车、货箱),解决LLM无法与外部系统交互、无法执行确定性任务的问题,让LLM从“能说”延伸到“能做”;
- Agent是顶层自主执行系统:相当于完整的自动驾驶汽车,以LLM为核心大脑,整合RAG的知识能力与Skill的执行能力,能自主理解目标、拆解任务、规划步骤、调用工具、迭代优化,最终完成复杂的多轮任务,无需用户逐步骤指令。
1.1 LLM(Large Language Model,大语言模型)
- 权威定义:基于Transformer架构,通过海量文本数据进行预训练,具备涌现性语言理解、生成与推理能力的大规模语言模型,核心是通过自监督学习掌握人类语言的统计规律与语义表示,实现基于上下文的token序列预测
- 通俗解读:LLM是经过海量文本训练的「超级语言规律预测机」——你给它一段上文,它能基于学到的语言规律,预测出下一个最合理的token,逐步生成完整、通顺、符合逻辑的文本。它的核心能力是语言理解、文本生成与逻辑推理,是整个大模型体系的「大脑核心」。
1.2 RAG(Retrieval-Augmented Generation,检索增强生成)
- 权威定义:一种将信息检索与文本生成相结合的技术框架,在LLM生成回答之前,先从外部知识库中检索与用户查询相关的权威信息,将检索结果作为上下文注入Prompt,引导LLM基于检索到的事实信息生成回答,从根源上减少大模型幻觉,提升回答的准确性与时效性
- 通俗解读:RAG是给LLM配的「专属图书馆+智能检索员」。LLM的知识是训练时固化的,遇到课本外、最新的、专业的知识就容易“瞎编”(幻觉),而RAG会在LLM回答前,先从你的专属图书馆中找到相关权威资料,让LLM严格基于资料回答,确保答案有根有据,不会胡说八道。
1.3 Skill(技能/工具调用)
- 权威定义:面向LLM封装的、具备明确输入输出规范、可被LLM自主理解并调用执行的标准化功能模块,核心是通过Function Calling机制,让LLM能够根据用户需求,自主选择并调用外部工具/函数,突破LLM的原生能力边界,实现与外部系统的交互和确定性任务执行
- 通俗解读:Skill是给LLM装的「专属APP」,或者说「可调用的工具包」。LLM本身只能“说话”,不能“做事”——算不对复杂数学题、拿不到实时天气、查不了业务数据库、发不了邮件。而每个Skill,就是你提前写好的、能完成特定任务的Java方法,LLM能看懂方法的用途,在需要时自动生成正确入参、调用方法、拿到执行结果,再基于结果给用户回答。Skill让LLM从「只能说」变成了「既能说,又能做」。
1.4 Agent(智能体)
- 权威定义:以LLM为核心大脑,具备自主感知、记忆、规划、推理、工具调用、反思优化能力,能够在无人工干预的情况下,自主理解用户的目标,拆解并执行复杂的多轮任务,最终达成预设目标的智能系统
- 通俗解读:Agent是「以LLM为核心的全自动任务执行者」,相当于你的专属AI项目经理。你只需要告诉它最终目标(比如“帮我做一份2026年Q2的Java团队招聘计划”),它会自主拆解任务:通过RAG检索行业薪资数据、调用Skill查询公司过往招聘数据、编写JD与面试流程、调用Skill生成Excel文件,整个过程无需你一步步指导,它会自主思考、规划、调用工具、修正错误,直到完成目标。
第二章 大模型的心脏:LLM(大语言模型)通俗全解
这一章我们彻底讲透LLM的底层逻辑,不用晦涩公式,只用Java开发者能懂的类比,让你真正理解LLM的工作原理,而不是只会调用API。
2.1 LLM的核心本质:不是“理解”,而是“预测”
首先纠正行业内最大的误区:LLM并不具备真正的“理解”能力,也没有意识,它的核心本质是基于海量文本训练出来的「token级概率预测模型」。这句话是理解所有LLM行为的基础,有权威学术与官方依据支撑。
什么意思?我们用最通俗的例子说明: 当你给LLM输入“上海的简称是”,LLM要做的不是“理解”这句话的含义,而是基于训练数据中学到的语言规律,计算下一个token出现的概率:
- “沪”:99.99%
- “申”:0.008%
- 其他字:0.002%
随后它会选择概率最高的“沪”输出,再把“上海的简称是沪”作为新的上文,继续预测下一个token,直到生成结束符或达到上下文长度上限。
再比如你输入“1+1=”,LLM输出“2”,不是因为它会做数学题,而是因为训练数据里“1+1=”后面跟着“2”的概率无限接近100%。
这就是LLM的核心本质:所有输出都是基于上文的token概率预测,一步一步生成的。它的所有“理解能力”“推理能力”“创作能力”,本质上都是这种概率预测能力在模型规模达到临界值后,涌现出来的效果。
2.2 LLM的底层架构:Transformer,一切的基础
所有主流LLM(GPT系列、豆包、通义千问、Llama系列)的底层核心架构都是Transformer,这个来自Google 2017年《Attention Is All You Need》的架构,是整个大模型时代的开山之作,没有Transformer,就没有今天的LLM。
2.2.1 Transformer的核心:自注意力机制(Self-Attention)
Transformer的核心是自注意力机制,这也是它能处理长文本、理解上下文语义的核心原因。
- 权威定义:自注意力机制是一种让模型在处理文本中的每个token时,能够自动计算并关注上下文中与该token语义相关的其他token,为其分配不同权重,从而捕捉文本中长距离依赖关系的机制。
- 通俗解读:自注意力机制让模型在处理每个词的时候,能自动关注上下文中和它相关的其他词,就像我们人读一句话时,会自动关联上下文理解指代关系。
举个Java开发者最熟悉的例子:
❝
“我把Java项目的jar包部署到了Linux服务器上,启动的时候发现它报错了。”
这句话里的“它”,人一眼就能看出指代的是“Java项目的jar包”,但传统模型很难理解这种指代关系。而自注意力机制会给每个词计算和“它”的关联权重:
- “Java项目的jar包”:权重0.95
- “Linux服务器”:权重0.03
- 其他词:权重0.02
这样模型在处理“它”时,就会把注意力主要放在“Java项目的jar包”上,正确理解指代对象。用Java代码类比,自注意力机制的核心逻辑如下:
/** * 自注意力机制的Java类比实现 * @param text 输入文本分词后的列表 * @param targetWord 目标词 * @return 每个词与目标词的关联权重 */public Map<String, Double> selfAttention(List<String> text, String targetWord) { Map<String, Double> weightMap = new HashMap<>(); // 1. 遍历文本,计算每个词与目标词的语义相似度 for (String word : text) { double similarity = calculateSemanticSimilarity(word, targetWord); weightMap.put(word, similarity); } // 2. 归一化权重,确保所有权重之和为1 weightMap = normalizeWeight(weightMap); // 3. 返回权重Map,模型根据权重重点关注高相关性内容 return weightMap;}
真实的自注意力机制通过Q(查询)、K(键)、V(值)三个矩阵实现,核心流程为:
- 将每个词转换为嵌入向量;
- 每个词的向量分别乘以Q、K、V三个矩阵,得到对应的Q、K、V向量;
- 用目标词的Q向量与所有词的K向量做相似度计算,得到每个词的权重;
- 将权重与每个词的V向量相乘后求和,得到该词最终包含上下文信息的向量表示。
2.2.2 Transformer的完整架构
Transformer架构整体分为两个核心部分:Encoder(编码器) 和 Decoder(解码器)。
- Encoder(编码器):负责“理解输入”,将输入文本转换为包含上下文语义的向量表示,核心是双向自注意力机制,能看到输入文本的所有内容;
- Decoder(解码器):负责“生成输出”,基于Encoder输出的语义向量,一步步预测下一个token,生成最终文本,核心是单向自注意力机制,只能看到已生成的上文内容,不能看到未来内容。
❝
注意:当前主流的生成式LLM(GPT系列、Llama系列、豆包等)均采用Decoder-only架构,仅保留解码器,更适合文本生成任务;而BERT等理解类模型采用Encoder-only架构,更适合文本分类、语义匹配等任务。
我们用流程图展示Transformer的完整工作流程,这是所有LLM文本生成的底层逻辑:
2.3 LLM的训练过程:从空白模型到通用大模型
LLM的训练过程就像人的学习过程,分为三个核心阶段,每个阶段都有明确的目标与权威实现方案:
2.3.1 第一阶段:预训练(Pre-training)—— 寒窗苦读,学遍天下书
预训练是LLM最核心、最耗时、最耗算力的阶段,目标是让模型学会人类语言的基本规律、语法、语义与常识。
- 训练数据:万亿token级别的公开文本数据,包括书籍、网页、文章、代码等;
- 训练任务:自监督学习,核心是“下一个token预测”——给模型一段上文,让它预测下一个token,无需人工标注数据;
- 训练结果:预训练后的模型已经掌握了人类语言的所有规律,具备基础文本生成能力,但还不会“听人话”,无法按照用户指令输出符合要求的内容。
2.3.2 第二阶段:有监督微调(SFT,Supervised Fine-tuning)—— 专业集训,学会听指令
SFT阶段的目标是让预训练模型学会遵循用户指令,按照人类要求输出内容。
- 训练数据:几十万到几百万条人工标注的「指令-回答」配对数据,每条数据都是用户指令与对应的标准答案;
- 训练任务:让模型学习配对数据,掌握针对不同指令输出符合要求回答的能力;
- 训练结果:SFT后的模型能精准遵循用户指令,完成代码编写、文案创作、问题回答等任务,是对话大模型的基础。
2.3.3 第三阶段:人类反馈强化学习(RLHF)/直接偏好优化(DPO)—— 价值观对齐,学会做好人
这个阶段的目标是让模型的输出符合人类的价值观、偏好与伦理规范,减少幻觉与有害内容。
- RLHF:来自OpenAI的InstructGPT论文,核心分为三步:1. 人工给模型输出打分,训练奖励模型;2. 用强化学习让模型输出朝着高打分方向优化;3. 迭代优化直到符合人类偏好。
- DPO:来自斯坦福大学2023年的论文,是RLHF的替代方案,直接用人类偏好数据优化模型本身,无需单独训练奖励模型,更简单高效,目前已成为主流方案。
2.4 LLM的核心能力与关键指标
2.4.1 核心涌现能力
“涌现能力”是LLM的核心特性,来自Google Brain 2022年《Emergent Abilities of Large Language Models》,权威定义是:在小模型中不存在、但在大模型中突然出现的能力,无法通过外推小模型性能预测。通俗来说,就是模型规模达到临界值后,量变引起质变,突然具备了之前没有的能力。
LLM的核心涌现能力包括:
- 上下文理解能力:能处理几万甚至几十万token的长文本,理解长上下文的语义;
- 逻辑推理能力:能完成数学推理、常识推理、多步逻辑推理任务;
- 指令遵循能力:能精准理解用户的复杂指令,按照要求完成任务;
- 泛化能力:能将学到的知识应用到从未见过的新场景、新任务中;
- 工具使用能力:能理解工具用途,自主调用工具完成任务,是Skill调用的基础。
2.4.2 评估LLM的关键指标
评估LLM的好坏不能只看参数量,要关注这些核心指标,避免被营销话术误导:
| 指标 | 定义 | 业务意义 |
|---|---|---|
| 参数量 | 模型中可训练参数的数量,单位为B(十亿) | 模型能力的基础,但不是唯一决定因素 |
| 上下文窗口长度 | 模型能处理的最大token数量,包含输入与输出 | 决定模型能处理的文本长度与记忆能力 |
| 困惑度(PPL) | 评估模型语言建模能力的核心指标,值越低越好 | 反映模型预测的准确率,值越低生成的文本越通顺、逻辑越严谨 |
| 推理速度 | 模型每秒能生成的token数量(token/s) | 决定模型的响应速度,是业务落地的关键指标 |
| 基准测试得分 | MMLU、GSM8K、HumanEval等权威测试的准确率 | 客观反映模型在语言理解、数学推理、代码生成等领域的能力 |
2.5 Java开发者实战:基于Spring AI的LLM接入
Spring AI是Spring官方推出的大模型应用开发框架,与Spring Boot无缝集成,完全符合Java开发者的开发习惯,是Java生态接入LLM的首选方案。
2.5.1 环境准备
创建Spring Boot 3.2+项目,JDK 17+,引入Maven依赖:
<!-- Spring Boot 父依赖 --><parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.2.5</version> <relativePath/></parent><dependencies> <!-- Spring AI 核心依赖 --> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter</artifactId> <version>1.0.0</version> </dependency> <!-- Spring AI 字节跳动豆包大模型依赖 --> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-doubao-spring-boot-starter</artifactId> <version>1.0.0</version> </dependency> <!-- Spring Web 依赖 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- Lombok 依赖 --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency></dependencies><!-- Spring AI 官方仓库 --><repositories> <repository> <id>spring-milestones</id> <name>Spring Milestones</name> <url>https://repo.spring.io/milestone</url> <snapshots> <enabled>false</enabled> </snapshots> </repository></repositories>
在application.yml中配置豆包大模型:
spring: ai: doubao: api-key: 你的豆包API密钥(火山引擎控制台获取) chat: options: model: doubao-pro-32k temperature: 0.7 max-tokens: 2048
- temperature:温度系数,0-1之间,值越低输出越确定严谨,值越高输出越随机有创造性;
- max-tokens:模型生成的最大token数量。
2.5.2 基础LLM调用实现
创建Controller实现最简单的LLM对话接口:
package com.ken.llm.demo.controller;import lombok.RequiredArgsConstructor;import org.springframework.ai.chat.client.ChatClient;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;/** * LLM基础调用Controller * 作者:Ken */@RestController@RequestMapping("/llm")@RequiredArgsConstructorpublic class LlmController { // Spring AI 自动注入配置好的ChatClient private final ChatClient chatClient; /** * 基础LLM对话接口 * @param prompt 用户输入的提示词 * @return LLM生成的回答 */ @GetMapping("/chat") public String chat(@RequestParam String prompt) { return chatClient.prompt() .user(prompt) .call() .content(); }}
启动项目后,访问http://localhost:8080/llm/chat?prompt=用Java写一个冒泡排序算法,即可直接获取LLM生成的代码。
2.6 LLM的常见误区纠正
- 误区1:LLM有真正的理解能力和意识
- 纠正:100%错误。LLM的核心是token概率预测,没有真正的理解能力、意识与情感,所有相关表现都是概率预测生成的效果,这是图灵奖得主Yann LeCun、OpenAI官方多次明确的结论。
- 误区2:参数量越大,模型能力越强
- 纠正:错误。参数量是模型能力的基础,但训练数据质量、训练方法、架构设计、对齐效果都会影响最终能力。很多高质量小模型的能力,能超过参数量更大的模型,比如Llama 3 8B的能力超过了多数13B模型。
- 误区3:LLM能记住所有训练数据
- 纠正:错误。LLM的训练过程是学习数据中的语言规律,不是“背诵”所有训练数据,大量细节内容无法准确回忆,这是幻觉产生的核心原因之一,也是RAG技术的核心价值所在。
- 误区4:LLM能完成精确的数学计算和逻辑推理
- 纠正:部分错误。LLM的推理能力是涌现出来的,能完成简单的计算与推理,但对于复杂、多步的精确计算,很容易出错,因为它的核心是概率预测,不是确定性计算,这也是Skill技术的核心价值所在。
第三章 大模型的“外接硬盘”:RAG(检索增强生成)通俗全解
上一章我们讲了LLM的核心原理,这一章我们讲RAG,它是解决LLM幻觉、知识滞后、专业知识不足的核心方案,也是目前企业级大模型应用落地最成熟的技术。
3.1 为什么我们必须用RAG?
LLM有四个原生痛点,是自身无法突破的,必须通过RAG解决:
- 知识滞后性:所有LLM的训练数据都有截止日期,对于截止日期之后的政策、产品文档、行业数据,LLM完全无法获取;
- 幻觉问题:当LLM遇到未知问题或记忆模糊的内容时,不会说“我不知道”,而是会编造看起来真实但完全错误的内容,在金融、法律、客服等企业级场景中,幻觉会带来巨大损失;
- 专业领域知识不足:通用LLM的训练数据以公开通用数据为主,对于企业内部业务知识、垂直领域专业知识,完全无法覆盖;
- 数据隐私与合规问题:企业的内部敏感数据不能用于微调LLM,否则有数据泄露风险,而RAG的所有私有数据都存储在企业自有系统中,无需传入模型训练环节,完全符合合规要求;
- 成本与迭代效率问题:用新数据微调模型成本极高、周期极长,而RAG只需要将新文档更新到知识库,即可立即生效,迭代效率提升几个数量级。
3.2 什么是RAG?权威定义与核心误区纠正
- 权威定义:RAG是一种将信息检索与文本生成相结合的端到端框架,它将预训练的检索器与预训练的生成器结合,在生成文本前,先从外部非结构化知识库中检索与当前查询相关的文档片段,将检索到的信息作为上下文补充到Prompt中,引导生成器基于真实权威的信息生成回答,显著提升知识密集型任务的性能,同时大幅减少模型幻觉(来源:Meta AI 2020《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》)。
- 通俗解读:RAG就是给LLM配了一个专属图书馆+智能检索员,让LLM在回答问题前,先去图书馆找到相关权威资料,再严格基于资料回答,从根源上避免胡说八道。
❝
行业最大误区纠正:RAG≠向量数据库。向量数据库只是RAG流程中的一个存储组件,RAG是包含文档处理、分块、向量化、检索、重排序、Prompt工程、LLM生成的完整端到端框架,向量数据库只是其中的一小部分。
3.3 RAG的完整工作流程与底层逻辑
RAG的完整流程分为两大阶段:离线数据预处理阶段(知识库构建)和在线查询生成阶段,70%的RAG效果问题都出在离线阶段。
3.3.1 离线阶段:知识库构建(RAG效果的核心基础)
离线阶段的目标是将原始文档处理成可被高效检索、可被LLM有效利用的格式,直接决定了RAG的最终效果。
步骤1:文档加载与解析将各种格式的原始文档转换为纯文本内容,Java生态中推荐使用Apache PDFBox处理PDF、Apache POI处理Office文档、Jsoup处理HTML网页,这些都是成熟稳定的工业级工具。解析时需尽量保留文档的标题、段落、表格等结构信息,对后续语义拆分与检索至关重要。
步骤2:文档清洗与预处理将解析后的文本处理成干净规范的高质量文本,核心操作包括:去重、去噪(去除页眉页脚、页码、乱码)、格式统一、长句拆分,文本质量越高,后续的向量化与检索效果越好。
步骤3:文档分块/Chunk拆分这是离线阶段最核心的步骤,目标是将长文本拆分成合适大小、语义完整的文本块。
- 核心原则:语义完整,大小合适。一个Chunk必须是一个完整的语义单元,不能将一个完整的知识点拆分到两个Chunk中,否则会导致检索到的信息不完整,LLM无法准确回答。
- 最佳实践:
- 通用场景:Chunk大小512-1024 token,重叠率10%-20%;
- 专业文档场景:Chunk大小1024-2048 token,重叠率20%;
- 短文本问答场景:Chunk大小256-512 token,重叠率10%;
- 拆分策略:优先使用基于语义的拆分(按段落、标题、章节拆分),其次使用固定大小+重叠拆分,避免语义截断。
**步骤4:文本向量化/嵌入(Embedding)**这个步骤是RAG实现语义检索的核心,目标是将文本块转换为固定长度的高维稠密向量。
- 权威定义:嵌入是将非结构化文本转换为高维稠密向量的技术,语义相似的文本,对应的向量在向量空间中的距离更近。
- 嵌入模型选择:
- 中文开源首选:bge-large-zh、M3E,支持本地部署,中文效果领先;
- 闭源API首选:豆包Embedding、通义千问Embedding,调用简单,效果稳定;
- 核心红线:整个RAG流程必须使用同一个嵌入模型,离线文档向量化和在线Query向量化必须使用同一个模型,否则向量空间不一致,检索结果完全错误。
步骤5:向量数据库存储将生成的向量与对应的原始文本块存储到向量数据库中,用于后续的快速相似性检索。
- 向量数据库的核心作用:通过ANN(近似最近邻)算法,实现百万/千万级向量的毫秒级相似性检索,常用算法包括HNSW、IVF_FLAT;
- Java生态推荐选型:
- 企业级海量数据场景:Milvus,开源分布式,Java SDK完善,性能领先;
- 中小规模场景:Redis Stack,无需额外部署新数据库,与现有Java项目无缝集成;
- 快速落地场景:Pinecone,云原生全托管,无需运维。
3.3.2 在线阶段:查询与生成
在线阶段的目标是接收用户Query,检索相关文档,让LLM基于权威资料生成无幻觉的准确回答。
步骤1:用户Query向量化与改写用和离线阶段同一个嵌入模型,将用户Query转换为向量。进阶优化可通过Query改写,让LLM将口语化、模糊的Query改写成适合检索的精准语句,大幅提升召回率。
步骤2:向量检索用Query向量从向量数据库中召回最相似的Top-N个文本块,核心算法为余弦相似度(取值-1到1,值越大语义越相似)。进阶优化可使用混合检索(Hybrid Search),将向量检索(语义检索)与关键词检索(全文检索)结合,同时覆盖语义匹配和关键词匹配,大幅提升召回率。
**步骤3:检索结果重排序(Reranker)**这是提升RAG准确率的关键进阶步骤,用专门的重排序模型,对召回的Top-N结果进行二次精排,过滤无关内容,只保留最相关的Top-K个结果给LLM。
- 核心价值:向量检索是近似检索,召回结果中会包含无关内容,重排序模型能精准计算Query与每个结果的匹配度,大幅提升最终内容的相关性;
- 最佳实践:先召回Top-20个结果,用重排序模型精排后,只保留Top3-Top5个最相关的结果给LLM,既能保证召回率,又能避免无关信息干扰。
步骤4:Prompt工程注入将检索到的权威文档、用户Query按照固定模板组装成Prompt,引导LLM只基于参考资料回答,从根源上避免幻觉。以下是经过生产验证的RAG专用Prompt模板,可直接使用:
你是一个专业、严谨的智能问答助手,只能基于下面提供的【参考资料】来回答用户的问题,必须严格遵守以下规则:1. 回答必须完全来自于【参考资料】中的内容,绝对不能编造【参考资料】中没有的信息、数据、结论;2. 如果【参考资料】中没有和用户问题相关的内容,或者相关内容不足以回答用户的问题,请直接回答:"非常抱歉,参考资料中没有相关内容,无法为您解答这个问题。",绝对不能编造内容;3. 回答必须准确、严谨、简洁,符合逻辑,不要添加【参考资料】中没有的额外内容;4. 禁止使用"根据参考资料"、"参考资料中提到"等类似话术,直接输出回答内容即可。【参考资料】{reference_content}【用户问题】{user_query}
步骤5:LLM生成回答将组装好的Prompt传给LLM,生成最终回答。RAG场景推荐将temperature设置为0-0.3,低温度能让LLM严格遵循参考资料,进一步减少幻觉。
3.4 Java开发者实战:基于Spring AI + Milvus的RAG完整实现
以下代码基于Spring AI 1.0.0正式版,实现完整的RAG知识库问答功能。
3.4.1 环境准备
Docker一键部署Milvus向量数据库(官方标准部署方式):
# 下载Milvus docker-compose配置文件wget https://github.com/milvus-io/milvus/releases/download/v2.4.0/milvus-standalone-docker-compose.yml -O docker-compose.yml# 启动Milvusdocker-compose up -d
Milvus启动后,默认服务地址为localhost:19530,可视化管理工具Attu地址为http://localhost:9000。
在之前的项目中新增Maven依赖:
<!-- Spring AI Milvus 向量存储依赖 --><dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-milvus-store-spring-boot-starter</artifactId> <version>1.0.0</version></dependency><!-- PDF文档解析依赖 --><dependency> <groupId>org.apache.pdfbox</groupId> <artifactId>pdfbox</artifactId> <version>2.0.32</version></dependency><!-- Office文档解析依赖 --><dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>5.2.5</version></dependency><dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>5.2.5</version></dependency>
在application.yml中新增Milvus与Embedding配置:
spring: ai: doubao: api-key: 你的豆包API密钥 chat: options: model: doubao-pro-32k temperature: 0.3 # RAG场景用低温度,保证严谨性 max-tokens: 2048 # 豆包Embedding模型配置 embedding: options: model: doubao-embedding-v1 # Milvus向量数据库配置 vectorstore: milvus: client: host: localhost port: 19530 database-name: default collection-name: rag_demo embedding-dimension: 1024 # 豆包embedding-v1的维度为1024 index-type: HNSW metric-type: COSINE
3.4.2 知识库构建服务实现
package com.ken.llm.demo.service;import lombok.RequiredArgsConstructor;import org.apache.pdfbox.pdmodel.PDDocument;import org.apache.pdfbox.text.PDFTextStripper;import org.apache.poi.xwpf.usermodel.XWPFDocument;import org.springframework.ai.document.Document;import org.springframework.ai.reader.TextReader;import org.springframework.ai.transformer.splitter.TokenTextSplitter;import org.springframework.ai.vectorstore.VectorStore;import org.springframework.stereotype.Service;import org.springframework.web.multipart.MultipartFile;import java.io.InputStream;import java.util.List;/** * RAG知识库服务 * 作者:Ken */@Service@RequiredArgsConstructorpublic class RagService { private final VectorStore vectorStore; // Token文本分块器,基于token拆分,自动处理语义重叠 private final TokenTextSplitter textSplitter = new TokenTextSplitter( 1024, // 每个Chunk的最大token数 200, // 相邻Chunk的重叠token数 true, true ); /** * 上传文档,解析并存储到向量数据库 * @param file 上传的文档,支持pdf、docx、txt、md * @return 存储结果 */ public String uploadDocument(MultipartFile file) throws Exception { String fileName = file.getOriginalFilename(); if (fileName == null) { return "文件名不能为空"; } // 1. 解析文档,提取文本内容 String content = ""; if (fileName.endsWith(".pdf")) { content = extractPdfContent(file.getInputStream()); } else if (fileName.endsWith(".docx")) { content = extractDocxContent(file.getInputStream()); } else if (fileName.endsWith(".txt") || fileName.endsWith(".md")) { TextReader textReader = new TextReader(file.getInputStream()); List<Document> documents = textReader.get(); content = documents.get(0).getContent(); } else { return "不支持的文件格式,仅支持pdf、docx、txt、md"; } // 2. 文本分块 Document document = new Document(content); List<Document> chunks = textSplitter.split(List.of(document)); // 3. 向量化并存储到Milvus vectorStore.add(chunks); return "文档上传成功,共拆分" + chunks.size() + "个文本块,已存储到向量数据库"; } /** * 解析PDF文档提取文本 */ private String extractPdfContent(InputStream inputStream) throws Exception { try (PDDocument document = PDDocument.load(inputStream)) { PDFTextStripper stripper = new PDFTextStripper(); return stripper.getText(document); } } /** * 解析DOCX文档提取文本 */ private String extractDocxContent(InputStream inputStream) throws Exception { try (XWPFDocument document = new XWPFDocument(inputStream)) { StringBuilder content = new StringBuilder(); document.getParagraphs().forEach(paragraph -> { content.append(paragraph.getText()).append("\n"); }); return content.toString(); } }}
3.4.3 RAG问答服务实现
package com.ken.llm.demo.service;import lombok.RequiredArgsConstructor;import org.springframework.ai.chat.client.ChatClient;import org.springframework.ai.document.Document;import org.springframework.ai.vectorstore.SearchRequest;import org.springframework.ai.vectorstore.VectorStore;import org.springframework.stereotype.Service;import java.util.List;import java.util.stream.Collectors;/** * RAG问答服务 * 作者:Ken */@Service@RequiredArgsConstructorpublic class RagChatService { private final ChatClient chatClient; private final VectorStore vectorStore; // 生产级RAG Prompt模板 private static final String RAG_PROMPT_TEMPLATE = """ 你是一个专业、严谨的智能问答助手,只能基于下面提供的【参考资料】来回答用户的问题,必须严格遵守以下规则: 1. 回答必须完全来自于【参考资料】中的内容,绝对不能编造【参考资料】中没有的信息、数据、结论; 2. 如果【参考资料】中没有和用户问题相关的内容,或者相关内容不足以回答用户的问题,请直接回答:"非常抱歉,参考资料中没有相关内容,无法为您解答这个问题。",绝对不能编造内容; 3. 回答必须准确、严谨、简洁,符合逻辑,不要添加【参考资料】中没有的额外内容; 4. 禁止使用"根据参考资料"、"参考资料中提到"等类似话术,直接输出回答内容即可。 【参考资料】 {reference} 【用户问题】 {query} """; /** * RAG问答接口 * @param query 用户问题 * @return 基于知识库的回答 */ public String ragChat(String query) { // 1. 检索Top5个相关文档,相似度阈值0.7,过滤无关内容 List<Document> relevantDocs = vectorStore.similaritySearch( SearchRequest.query(query) .withTopK(5) .withSimilarityThreshold(0.7) ); // 2. 拼接参考资料 String reference = relevantDocs.stream() .map(Document::getContent) .collect(Collectors.joining("\n\n")); // 3. 无相关内容直接返回默认话术 if (reference.isBlank()) { return "非常抱歉,参考资料中没有相关内容,无法为您解答这个问题。"; } // 4. 组装最终Prompt String finalPrompt = RAG_PROMPT_TEMPLATE .replace("{reference}", reference) .replace("{query}", query); // 5. 调用LLM生成回答 return chatClient.prompt() .user(finalPrompt) .call() .content(); }}
3.4.4 接口Controller实现
package com.ken.llm.demo.controller;import com.ken.llm.demo.service.RagChatService;import com.ken.llm.demo.service.RagService;import lombok.RequiredArgsConstructor;import org.springframework.web.bind.annotation.*;import org.springframework.web.multipart.MultipartFile;/** * RAG接口Controller * 作者:Ken */@RestController@RequestMapping("/rag")@RequiredArgsConstructorpublic class RagController { private final RagService ragService; private final RagChatService ragChatService; /** * 上传文档到知识库 */ @PostMapping("/upload") public String uploadDocument(@RequestParam("file") MultipartFile file) throws Exception { return ragService.uploadDocument(file); } /** * RAG问答接口 */ @GetMapping("/chat") public String ragChat(@RequestParam String query) { return ragChatService.ragChat(query); }}
启动项目后,先调用/rag/upload接口上传文档,再调用/rag/chat接口,即可基于上传的文档进行问答,完全不会出现幻觉。
3.5 RAG的常见误区纠正
- 误区1:Chunk拆分越小,检索效果越好
- 纠正:错误。Chunk太小会导致语义不完整,检索到的内容只是知识点碎片,LLM无法生成完整准确的回答,拆分的核心原则是语义完整,而非越小越好。
- 误区2:检索结果越多,LLM回答越准确
- 纠正:错误。过多的检索结果会引入大量无关信息,干扰LLM的判断,同时占用上下文窗口、增加调用成本。最佳实践是检索Top20个结果,重排序后只保留Top3-Top5个最相关的内容。
- 误区3:嵌入模型维度越高,效果越好
- 纠正:错误。嵌入模型的效果取决于训练质量与训练数据,而非维度。很多中文开源模型1024维度的效果,远超闭源模型3072维度的效果,同时低维度能降低存储与检索成本,提升速度。
- 误区4:RAG能完全解决LLM的幻觉问题
- 纠正:部分错误。RAG能大幅减少幻觉,但无法100%完全解决。需要结合严格的Prompt规则、低温度系数、重排序、结果校验等多个手段,形成完整的幻觉治理闭环。
第四章 大模型的“手脚与工具”:Skill(技能/工具调用)通俗全解
上一章我们讲了RAG,解决了LLM的知识问题,这一章我们讲Skill,解决LLM的执行问题,让LLM从“只能说”变成“既能说,又能做”。
4.1 为什么我们需要Skill?LLM的原生能力边界
LLM有四个原生能力边界,是自身无法突破的,必须通过Skill解决:
- 无法获取实时数据:LLM的训练数据有截止日期,无法获取实时天气、股票价格、新闻、物流等动态变化的数据;
- 无法完成精确的确定性计算:LLM的核心是概率预测,对于复杂的数学计算、财务计算、统计分析,很容易出错,而代码函数能100%准确完成;
- 无法与外部系统交互:LLM本身是封闭系统,无法与企业业务系统、数据库、第三方API、硬件设备交互,无法完成查询订单、发送邮件、操作文件等任务;
- 无法完成结构化标准化任务:很多业务任务有严格的流程规范,需要确定性的执行逻辑,而LLM的生成是概率性的,容易出现偏差,必须通过标准化的函数执行。
4.2 什么是Skill?权威定义与核心误区纠正
- 权威定义:Skill是面向LLM封装的、具备明确功能描述、标准化输入输出规范、可被LLM自主理解并调用执行的功能模块,核心是通过Function Calling机制,让LLM能够根据用户需求,自主判断是否需要调用工具、调用哪个工具、生成工具所需的正确入参,通过执行外部工具函数,突破LLM的原生能力边界。
- 通俗解读:Skill就是你给LLM写的一个个Java方法,每个方法都能完成一个特定的确定性任务,你给方法写好详细的注释说明用途与入参,LLM能看懂这些说明,在需要的时候自动生成正确入参、调用方法、基于返回结果给用户回答。
❝
行业最大误区纠正:Skill≠Function Calling。Function Calling是LLM的一种能力,是实现Skill的底层技术机制;而Skill是基于Function Calling封装的完整功能模块,包括函数定义、业务逻辑、入参校验、异常处理、安全管控、幂等性保证等,Function Calling只是Skill的一小部分。
4.3 Skill的底层核心逻辑:Function Calling工作原理
很多人好奇,LLM是怎么知道什么时候要调用工具、怎么生成正确入参的?其实Function Calling的底层原理完全符合LLM的核心本质——token概率预测。
4.3.1 Function Calling的训练原理
LLM的Function Calling能力,是在SFT(有监督微调)阶段训练出来的。训练时,工程师会给模型喂大量的「用户需求-工具调用-执行结果-最终回答」配对数据,让模型学习:
- 什么样的需求需要调用工具;
- 不同的需求应该调用哪个工具;
- 怎么生成符合格式要求的工具入参;
- 怎么基于工具执行结果生成最终回答。
经过大量训练,模型就掌握了Function Calling能力,能自主判断并正确调用工具。
4.3.2 Function Calling的完整工作流程
核心细节:Skill的定义是每次调用LLM时,和用户需求一起传给模型的,不是提前写到模型里的。你可以随时新增、修改、删除Skill,不需要微调模型,只要在调用时把最新的Skill定义传给LLM,它就能理解并使用,这是Skill灵活性的核心原因。
4.3.3 Skill的标准定义规范
所有主流LLM都支持JSON Schema格式的Skill定义,一个标准的Skill定义包含以下核心部分:
name:Skill的名称,必须清晰直观,让LLM一眼看懂用途;description:函数的详细描述,说明功能、用途、适用场景,是LLM判断是否调用的核心依据;parameters:入参定义,用JSON Schema描述每个参数的名称、类型、描述、是否必填;required:必填参数列表。
标准的天气查询Skill定义示例:
{ "type": "function", "function": { "name": "getCurrentWeather", "description": "查询指定城市的实时天气情况,包括天气状况、温度、风力、湿度等信息", "parameters": { "type": "object", "properties": { "city": { "type": "string", "description": "要查询的城市名称,比如:上海、北京、广州,必须是中文的城市名称" }, "province": { "type": "string", "description": "城市所在的省份,可选参数,当城市名称有重名时传入" } }, "required": ["city"] } }}
4.4 Java开发者实战:基于Spring AI的Skill完整实现
Spring AI 1.0.0对工具调用提供了原生支持,通过@Tool注解即可快速定义Skill,框架会自动处理工具定义、LLM工具调用指令解析、函数执行、结果回传的完整流程,无需手动处理底层细节。
4.4.1 定义Skill工具类
package com.ken.llm.demo.skill;import dev.langchain4j.agent.tool.Tool;import org.springframework.stereotype.Component;import java.util.List;import java.util.Random;/** * Agent可用的工具类 * 作者:Ken */@Componentpublic class AgentTools { /** * 查询指定城市的实时天气 * @param city 要查询的城市名称 * @return 天气信息 */ @Tool("查询指定城市的实时天气情况,包括天气状况、温度、风力、湿度等信息") public String getCurrentWeather(String city) { System.out.println("LLM调用天气查询Skill,查询城市:" + city); Random random = new Random(); String[] weathers = {"晴", "多云", "阴", "小雨", "中雨", "大雨"}; int minTemp = 10 + random.nextInt(10); int maxTemp = minTemp + 5 + random.nextInt(10); return String.format("城市:%s,天气:%s,温度:%d-%d℃,风力:东风%d级,湿度:%d%%", city, weathers[random.nextInt(weathers.length)], minTemp, maxTemp, 1 + random.nextInt(5), 50 + random.nextInt(30)); } /** * 生成Excel文件 * @param fileName Excel文件名称,不需要带后缀 * @param headers Excel表头列表 * @param data Excel数据行列表 * @return 生成结果 */ @Tool("生成Excel文件,支持自定义表头和数据,返回生成的文件保存路径") public String generateExcel(String fileName, List<String> headers, List<List<String>> data) { System.out.println("LLM调用Excel生成Skill,生成文件:" + fileName); try { String filePath = "D:/excel/" + fileName + ".xlsx"; // 实际业务中替换为EasyExcel生成逻辑 Thread.sleep(1000); return "Excel文件生成成功,保存路径:" + filePath; } catch (Exception e) { return "Excel文件生成失败:" + e.getMessage(); } }}
4.4.2 实现支持Skill调用的对话接口
package com.ken.llm.demo.controller;import com.ken.llm.demo.skill.AgentTools;import lombok.RequiredArgsConstructor;import org.springframework.ai.chat.client.ChatClient;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;/** * Skill工具调用Controller * 作者:Ken */@RestController@RequestMapping("/skill")@RequiredArgsConstructorpublic class SkillController { private final ChatClient chatClient; private final AgentTools agentTools; /** * 支持Skill调用的对话接口 * @param prompt 用户输入的需求 * @return LLM的最终回答 */ @GetMapping("/chat") public String skillChat(@RequestParam String prompt) { return chatClient.prompt() .user(prompt) .functions(agentTools) // 注册可用的Skill .call() .content(); }}
启动项目后,访问http://localhost:8080/skill/chat?prompt=今天上海的天气怎么样?,即可看到LLM自动调用天气查询Skill,返回准确的天气信息;访问http://localhost:8080/skill/chat?prompt=帮我生成一个订单数据报表Excel,表头是订单号、用户名称、订单金额、下单时间,数据是3条测试数据,即可看到LLM自动调用Excel生成Skill,完成文件生成。
4.5 Skill开发的核心规范与最佳实践
- Skill的描述必须精准、无歧义
- 函数的
description必须清晰说明功能、适用场景与不适用场景,参数的description必须详细说明含义、格式要求与示例,描述越精准,LLM调用的准确率越高。
- Skill的职责必须单一,粒度合适
- 每个Skill只做一件事,不要把多个不相关的功能封装到一个Skill里,职责越单一,LLM越容易理解,调用准确率越高;粒度不能太细也不能太粗,避免LLM选择困难或入参错误。
- 必须做严格的入参校验与异常处理
- LLM生成的入参可能存在格式错误、非法值,必须在Skill中做严格的入参校验;同时必须处理所有异常,给LLM返回清晰的错误信息,让它能修正入参重新调用。
- 必须保证Skill的幂等性
- 同一个请求调用一次和多次的结果必须一致,不会产生副作用。尤其是写操作的Skill(发送邮件、修改数据库),必须做幂等控制,避免LLM重复调用导致业务异常。
- 必须做严格的安全管控
- 绝对不要把数据库直接操作、Shell脚本执行等高危操作封装成Skill,避免SQL注入、服务器入侵等安全风险;所有Skill都必须做权限控制、参数白名单、操作范围限制,重要操作必须有二次确认机制。
- 控制单次调用的Skill数量
- 一次LLM调用传入的Skill数量不要超过10个,太多的Skill会让LLM出现选择困难,导致调用错误。可根据场景动态传入当前需要的Skill,而非所有Skill。
4.6 Skill的常见误区纠正
- 误区1:LLM能100%正确调用Skill,不会出错
- 纠正:错误。LLM的工具调用能力是概率性的,可能会选错工具、生成错误入参、重复调用工具,必须通过精准的描述、严格的入参校验、异常处理来提升稳定性。
- 误区2:Skill的描述越详细越好,参数越多越好
- 纠正:错误。Skill的描述要精准简洁,只保留核心信息,过多无关内容会干扰LLM的判断;参数要尽量精简,只保留必填的核心参数,参数越多,LLM生成错误入参的概率越高。
- 误区3:所有业务逻辑都应该封装成Skill给LLM调用
- 纠正:错误。Skill只适合封装LLM本身做不到的、确定性的、结构化的任务,对于需要灵活处理的、非结构化的、需要语义理解的任务,应该交给LLM本身,不要过度封装Skill,失去大模型的灵活性。
第五章 大模型的“大脑与决策者”:Agent(智能体)通俗全解
前面三章我们分别讲了LLM、RAG、Skill三个核心组件,这一章我们讲Agent,它是把三个组件整合起来,实现真正自主智能的终极形态。
5.1 为什么我们需要Agent?
我们先举一个例子,就能明白Agent的核心价值: 用户需求:“帮我做一份2026年Q2上海浦东地区Java开发工程师的团队招聘计划,要求包括:1. 初级、中级、高级三个岗位的JD;2. 每个岗位的薪资范围,参考行业平均水平;3. 招聘渠道和预算;4. 完整的面试流程;5. 最终生成可直接使用的Excel招聘计划表。”
完成这个需求,需要做这些事情:
- 理解最终目标,拆解成多个子任务;
- 通过RAG检索2026年上海浦东Java开发的行业薪资数据、招聘渠道成本;
- 调用Skill查询公司过往的招聘数据、面试流程规范;
- 基于数据编写JD、制定薪资范围、招聘渠道、预算、面试流程;
- 调用Skill生成规范的Excel招聘计划表;
- 检查计划的完整性、合理性,修正错误,最终交付。
纯LLM、RAG、Skill都无法完成这个需求:纯LLM没有实时数据、无法生成Excel;RAG只能解决知识检索;Skill只能完成单个工具调用,无法自主拆解任务、多轮迭代。而Agent能完美解决这个问题,它的核心价值是:把用户的最终目标,变成可执行的任务计划,自主调用LLM、RAG、Skill,一步步执行、迭代优化,最终完成目标,无需用户逐步骤指令和干预。
简单来说:
- LLM是“能说话的顾问”;
- RAG是给顾问配了“图书馆”;
- Skill是给顾问配了“工具包”;
- Agent是让顾问变成了能自主规划、执行、优化的“项目经理”。
5.2 什么是Agent?权威定义与核心误区纠正
- 权威定义:Agent是以LLM为核心大脑,具备自主感知、记忆、规划、推理、工具调用、反思优化能力,能够在无人工干预的情况下,自主理解用户的目标,拆解并执行复杂的多轮任务,最终达成预设目标的智能系统(来源:斯坦福大学2023《Generative Agents: Interactive Simulacra of Human Behavior》、Google 2022《ReAct: Synergizing Reasoning and Acting in Language Models》)。
- 通俗解读:Agent是一个以LLM为核心的全自动任务执行者,你只需要告诉它最终想要什么,它会自己思考、拆解任务、规划步骤、调用工具、修正错误,直到完成目标,整个过程无需人工干预。
❝
行业最大误区纠正:Agent≠LLM+工具调用。工具调用只是Agent的一个模块,Agent的核心是自主的规划、推理、反思、迭代能力,是「思考-动作-观察-反思」的完整闭环。没有规划和反思能力的系统,就算能调用工具,也不是真正的Agent,只是一个自动化脚本。
5.3 Agent的核心架构与底层逻辑
目前行业内最主流、最成熟、落地最广泛的Agent架构,是Google提出的ReAct架构,几乎所有主流Agent框架(LangChain、Spring AI、Semantic Kernel)都是基于这个架构实现的。
5.3.1 ReAct架构:推理与动作协同的核心闭环
ReAct的全称是Reasoning + Acting,核心思想是模拟人类解决问题的方式:先思考(推理),然后行动,然后观察行动结果,再基于结果进一步思考,再行动,直到完成目标。
ReAct架构的核心闭环是四步,循环执行直到完成目标:
- Thought(思考/推理):基于当前目标和已有信息,思考下一步要做什么,为什么要这么做;
- Action(动作/执行):基于思考结果,执行对应的动作,比如调用RAG检索知识、调用Skill工具;
- Observation(观察/反馈):获取动作执行的结果,也就是环境的反馈;
- Reflection(反思/优化):基于观察结果,反思刚才的动作对不对,结果有没有用,接下来要怎么调整,然后进入下一轮思考。
5.3.2 Agent的六大核心模块
一个完整的Agent包含六大核心模块,缺一不可,架构图如下:
- 核心大脑:LLM大语言模型
- 职责:Agent的“大脑”,负责所有的思考、推理、决策、规划、内容生成,是整个Agent的核心,模型的推理能力越强,Agent的表现越好。
- 感知模块
- 职责:接收用户输入、理解最终目标、获取环境反馈与工具执行结果,转换成LLM能理解的格式。
- 记忆模块
- 职责:存储Agent的所有历史信息,包括目标、每一轮的思考、动作、观察结果、过往经验;
- 分为两类:短期记忆(上下文窗口中的工作记忆)、长期记忆(向量数据库存储的历史经验与知识)。
- 规划模块
- 职责:将用户的大目标拆解成多个可执行的小任务,制定执行计划,安排任务顺序,调度任务执行,常用策略包括Chain of Thought(思维链)、Tree of Thoughts(思维树)、Plan-and-Execute(先规划后执行)。
- 工具调用模块
- 职责:管理Agent能使用的所有工具(RAG、Skill),基于规划选择合适的工具,生成正确入参,执行工具,获取执行结果,是Agent与外部世界交互的核心。
- 反思与优化模块
- 职责:评估每一步的执行结果,判断是否正确、是否能推进目标完成,修正错误,调整计划,沉淀经验到长期记忆中,是Agent能自我修正、自主优化的核心。
5.3.3 Agent的完整工作流程
5.4 Java开发者实战:基于LangChain4j的ReAct Agent完整实现
目前Spring AI的Agent支持还在完善中,而LangChain4j是Java生态最成熟的大模型应用开发框架,对Agent的支持非常完善,以下代码基于LangChain4j 0.32.0。
5.4.1 环境准备
引入Maven依赖:
<!-- LangChain4j 核心依赖 --><dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j</artifactId> <version>0.32.0</version></dependency><!-- LangChain4j 豆包大模型支持 --><dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-doubao</artifactId> <version>0.32.0</version></dependency><!-- Lombok --><dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional></dependency>
5.4.2 定义 Agent 工具类
package com.ken.llm.demo.agent;import dev.langchain4j.agent.tool.Tool;import org.springframework.stereotype.Component;import java.math.BigDecimal;import java.util.*;/** * Agent可用的工具类 * 作者:Ken */@Componentpublic class AgentTools { /** * 查询指定城市、指定岗位的实时行业薪资范围 */ @Tool("查询指定城市、指定技术岗位的行业平均薪资范围,单位为元/月,返回初级、中级、高级三个级别的薪资区间") public String getIndustrySalaryRange(String city, String jobPosition) { System.out.println("Agent调用薪资查询工具,城市:" + city + ",岗位:" + jobPosition); // 生产环境对接第三方薪资调研平台API/企业内部薪酬数据库 Map<String, Map<String, String>> salaryData = new HashMap<>(); // 上海Java开发岗位薪资数据 Map<String, String> javaSalary = new HashMap<>(); javaSalary.put("初级", "8000-15000元/月"); javaSalary.put("中级", "15000-25000元/月"); javaSalary.put("高级", "25000-40000元/月"); salaryData.put("上海Java开发工程师", javaSalary); String key = city + jobPosition; if (salaryData.containsKey(key)) { return city + jobPosition + "行业薪资范围:" + salaryData.get(key); } return "暂无该城市该岗位的薪资数据"; } /** * 查询指定岗位的标准JD模板 */ @Tool("获取指定技术岗位的标准JD模板,包含岗位职责、任职要求的规范框架") public String getStandardJdTemplate(String jobLevel) { System.out.println("Agent调用JD模板工具,岗位级别:" + jobLevel); Map<String, String> templateMap = new HashMap<>(); templateMap.put("初级", """ 岗位职责: 1. 参与项目的功能开发与单元测试,保障代码质量 2. 配合资深工程师完成技术方案落地,解决开发过程中的基础问题 3. 编写项目相关的技术文档与注释 任职要求: 1. 本科及以上学历,计算机相关专业 2. 掌握Java基础语法与面向对象编程思想 3. 了解Spring Boot、MyBatis等主流框架 4. 具备良好的代码规范与学习能力 """); templateMap.put("中级", """ 岗位职责: 1. 负责业务模块的设计与开发,独立完成核心功能实现 2. 参与系统架构设计与技术方案评审,提出优化建议 3. 解决项目中的复杂技术问题,保障系统稳定性 4. 指导初级工程师,参与代码评审与技术分享 任职要求: 1. 本科及以上学历,计算机相关专业,3年以上Java开发经验 2. 精通Java核心技术,熟悉JVM原理、多线程编程 3. 精通Spring Cloud微服务架构,有分布式系统开发经验 4. 熟悉MySQL数据库优化、Redis缓存中间件使用 5. 具备良好的问题排查能力与技术攻坚能力 """); templateMap.put("高级", """ 岗位职责: 1. 负责系统整体架构设计与技术选型,保障系统高可用、高性能、可扩展 2. 主导核心技术难题攻坚,制定技术规范与开发标准 3. 参与技术团队建设与人才培养,推动技术能力提升 4. 对接业务需求,制定技术落地路线,把控项目技术风险 任职要求: 1. 本科及以上学历,计算机相关专业,5年以上Java开发经验,2年以上架构设计经验 2. 精通Java分布式系统架构设计,有大型微服务项目落地经验 3. 深入理解JVM底层原理、MySQL内核、分布式事务、高可用架构设计 4. 具备丰富的线上问题排查与性能优化经验 5. 具备良好的团队管理能力与技术前瞻性 """); return templateMap.getOrDefault(jobLevel, "暂无该级别的JD模板"); } /** * 查询指定城市的主流招聘渠道与成本数据 */ @Tool("查询指定城市的主流招聘渠道、收费模式与人均招聘成本数据") public String getRecruitmentChannelInfo(String city) { System.out.println("Agent调用招聘渠道查询工具,城市:" + city); return """ 上海地区主流招聘渠道信息: 1. 招聘网站:BOSS直聘、智联招聘、前程无忧,年费3000-10000元/账号,人均招聘成本800-1500元 2. 内推渠道:公司内部员工推荐,人均招聘成本1000-2000元(推荐奖金),候选人匹配度最高 3. 猎头渠道:中高端岗位招聘,收费为候选人年薪的20%-25%,适合高级岗位 4. 校园招聘:高校双选会、校企合作,人均成本500-1000元,适合初级岗位校招 """; } /** * 生成招聘计划Excel文件 */ @Tool("生成招聘计划Excel文件,传入招聘岗位列表、薪资范围、招聘渠道、预算等信息,返回文件保存路径") public String generateRecruitmentExcel( @dev.langchain4j.agent.tool.P("招聘岗位列表,包含岗位名称、级别、招聘人数") List<Map<String, Object>> jobList, @dev.langchain4j.agent.tool.P("招聘总预算,单位:元") BigDecimal totalBudget, @dev.langchain4j.agent.tool.P("招聘周期,单位:天") Integer cycleDays ) { System.out.println("Agent调用Excel生成工具,生成招聘计划文件"); try { String filePath = "D:/recruitment/2026_Q2_Java团队招聘计划.xlsx"; // 生产环境替换为EasyExcel/POI的真实生成逻辑 Thread.sleep(1000); return "招聘计划Excel文件生成成功,共包含" + jobList.size() + "个岗位,总预算" + totalBudget + "元,招聘周期" + cycleDays + "天,文件保存路径:" + filePath; } catch (Exception e) { return "Excel文件生成失败:" + e.getMessage(); } } /** * 查询实时天气工具(保留基础工具,兼容多场景) */ @Tool("查询指定城市的实时天气情况,包括天气状况、温度、风力、湿度等信息") public String getCurrentWeather(String city) { System.out.println("Agent调用天气查询工具,查询城市:" + city); Random random = new Random(); String[] weathers = {"晴", "多云", "阴", "小雨", "中雨", "大雨"}; int minTemp = 10 + random.nextInt(10); int maxTemp = minTemp + 5 + random.nextInt(10); return String.format("城市:%s,天气:%s,温度:%d-%d℃,风力:东风%d级,湿度:%d%%", city, weathers[random.nextInt(weathers.length)], minTemp, maxTemp, 1 + random.nextInt(5), 50 + random.nextInt(30)); }}
5.4.3 ReAct Agent 核心实现
基于LangChain4j官方标准的ReAct Agent实现,完全符合Google ReAct论文的规范,支持自主规划、工具调用、多轮迭代,代码可直接运行。
package com.ken.llm.demo.agent;import dev.langchain4j.model.chat.ChatLanguageModel;import dev.langchain4j.model.doubao.DoubaoChatModel;import dev.langchain4j.agent.tool.ToolSpecification;import dev.langchain4j.agent.tool.Tools;import dev.langchain4j.service.AiServices;import dev.langchain4j.service.SystemMessage;import dev.langchain4j.service.UserMessage;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import java.util.List;/** * ReAct Agent 核心配置与实现 * 作者:Ken */@Configurationpublic class ReActAgentConfig { // 豆包API密钥,从火山引擎控制台获取 private static final String API_KEY = "你的豆包API密钥"; // 豆包模型名称,推荐使用推理能力强的pro版本 private static final String MODEL_NAME = "doubao-pro-32k"; /** * 注册LLM模型实例 */ @Bean public ChatLanguageModel chatLanguageModel() { return DoubaoChatModel.builder() .apiKey(API_KEY) .modelName(MODEL_NAME) .temperature(0.3) // Agent场景用低温度,保证规划的稳定性 .maxTokens(4096) .build(); } /** * Agent服务接口,定义Agent的能力 */ public interface RecruitmentAgent { @SystemMessage(""" 你是一名专业的企业招聘专家,也是一个具备自主规划、工具调用、迭代优化能力的智能Agent。 你的核心任务是根据用户的招聘需求,完成完整的招聘计划制定,必须严格遵守以下规则: 1. 先理解用户的最终招聘目标,拆解成可执行的子任务,制定清晰的执行计划; 2. 所有薪资数据、招聘渠道信息、JD模板,必须通过调用对应的工具获取,绝对不能编造; 3. 每完成一个子任务,要检查结果是否符合要求,再进行下一个步骤; 4. 所有工具调用必须严格按照参数要求传入正确的参数,禁止传入非法值; 5. 最终必须生成完整的招聘计划,包含JD、薪资范围、招聘渠道、预算、面试流程、Excel文件生成; 6. 执行过程中要清晰说明每一步的执行情况,最终结果要专业、完整、可直接落地使用。 """) String executeRecruitmentPlan(@UserMessage String userDemand); } /** * 注册Agent实例,绑定LLM模型与工具 */ @Bean public RecruitmentAgent recruitmentAgent(ChatLanguageModel chatLanguageModel, AgentTools agentTools) { // 扫描工具类中的@Tool注解,生成工具规范 List<ToolSpecification> toolSpecifications = Tools.toolSpecificationsFrom(agentTools); // 构建Agent实例 return AiServices.builder(RecruitmentAgent.class) .chatLanguageModel(chatLanguageModel) .tools(toolSpecifications, agentTools) .build(); }}
5.4.4 Agent 对外接口Controller
package com.ken.llm.demo.controller;import com.ken.llm.demo.agent.ReActAgentConfig;import lombok.RequiredArgsConstructor;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;/** * Agent 对外接口Controller * 作者:Ken */@RestController@RequestMapping("/agent")@RequiredArgsConstructorpublic class AgentController { private final ReActAgentConfig.RecruitmentAgent recruitmentAgent; /** * 执行招聘计划Agent任务 * @param demand 用户的招聘需求 * @return Agent的最终执行结果 */ @GetMapping("/recruitment/plan") public String executeRecruitmentPlan(@RequestParam String demand) { return recruitmentAgent.executeRecruitmentPlan(demand); }}
启动项目后,访问接口:http://localhost:8080/agent/recruitment/plan?demand=帮我做一份2026年Q2上海浦东地区Java开发工程师的团队招聘计划,需要招初级2人、中级3人、高级1人,招聘周期60天
Agent会自动完成以下操作:
- 拆解招聘计划的子任务,制定执行流程;
- 调用工具获取上海Java开发三个级别的薪资范围;
- 调用工具获取三个级别的标准JD模板,适配需求;
- 调用工具获取上海的招聘渠道与成本数据,制定渠道方案;
- 计算招聘总预算,制定完整的面试流程;
- 调用工具生成招聘计划Excel文件;
- 整合所有内容,生成完整的、可落地的招聘计划,返回给用户。
整个过程无需人工干预,Agent自主完成所有步骤,完美实现复杂任务的全自动执行。
5.5 Agent 企业级落地的核心最佳实践
基于大量生产级Agent项目落地经验,总结出Java开发者必须遵守的8条核心规范,直接决定Agent的稳定性与落地效果:
- 优先选择成熟的规划策略,拒绝过度设计
- 简单多轮任务:使用基础ReAct架构,轻量稳定,调试成本低;
- 复杂结构化任务:使用Plan-and-Execute架构,先制定完整计划,再分步执行,避免任务跑偏;
- 超高复杂度任务:使用多Agent协作架构,拆分不同职责的子Agent(规划Agent、执行Agent、校验Agent),各司其职,降低单Agent的复杂度。
- 权威依据:LangChain官方2025年Agent架构最佳实践白皮书明确指出,80%的企业级场景,基础ReAct架构即可满足需求,过度设计会导致稳定性大幅下降。
- 严格管控Agent的工具边界,拒绝万能Agent
- 单次Agent执行,注册的工具数量不要超过10个,工具越多,LLM选择错误的概率越高;
- 按场景动态注册工具,比如招聘场景只注册招聘相关工具,天气查询场景只注册天气工具,避免无关工具干扰;
- 工具职责必须单一,粒度合适,禁止把多个不相关的功能封装到一个工具中。
- 完善的记忆管理,避免上下文溢出与信息丢失
- 短期记忆:使用滑动窗口机制,只保留最近的10轮交互,避免上下文窗口溢出;
- 长期记忆:使用RAG架构,把Agent的历史执行经验、成功案例、业务知识存储到向量数据库,需要时检索注入;
- 关键信息持久化:把任务目标、核心数据、执行结果持久化到数据库,避免LLM上下文丢失导致任务失败。
- 强制的结果校验与错误重试机制
- 每一步工具执行后,必须让Agent校验结果是否符合预期,不符合则重新执行;
- 工具调用设置最大重试次数(推荐3次),避免无限循环调用;
- 异常结果必须返回清晰的错误信息,引导Agent修正入参或调整方案,禁止返回空值或模糊的错误提示。
- 严格的安全管控,杜绝业务风险
- 绝对禁止给Agent开放数据库写权限、Shell执行权限、服务器操作权限等高危操作;
- 所有写操作工具必须增加人工二次确认机制,Agent生成执行指令后,必须经过人工审批才能执行;
- 所有工具调用必须做参数白名单、操作范围限制、权限校验,避免越权操作;
- 全链路日志审计,记录Agent的每一轮思考、工具调用、执行结果,满足合规要求。
- 完善的可观测性,快速定位问题
- 必须记录Agent的全链路执行日志:目标拆解、思考过程、工具调用、入参、执行结果、异常信息;
- 监控核心指标:任务成功率、工具调用准确率、平均执行时长、异常率;
- 提供可视化的执行链路追踪,快速定位Agent执行失败的环节与原因。
- 明确的任务边界,给Agent设置“刹车机制”
- 必须给Agent设置最大执行轮次(推荐10轮),避免无限循环执行;
- 必须明确任务的终止条件,让Agent清楚知道什么时候算完成目标;
- 禁止给Agent开放模糊的、无边界的任务,所有任务必须有明确的目标、范围、约束条件。
- 优先使用Java生态成熟框架,避免重复造轮子
- 企业级落地优先选择LangChain4j、Spring AI两大Java生态主流框架,社区活跃、文档完善、安全更新及时;
- 不要自己从零实现Agent的ReAct循环、工具解析、记忆管理等核心逻辑,重复造轮子会带来大量隐藏bug与安全风险。
5.6 Agent 的常见误区纠正
- 误区1:Agent越复杂、能力越多,效果越好
- 纠正:完全错误。Agent的核心是稳定完成特定场景的任务,而非功能越多越好。功能越多、工具越多,Agent的决策复杂度越高,出错概率呈指数级上升,稳定性大幅下降。企业级落地的最佳实践是:单Agent单职责,只做一件事,做到极致稳定。
- 误区2:Agent能完全替代人工,实现全自动化
- 纠正:错误。目前的LLM Agent还处于弱人工智能阶段,只能完成结构化、边界清晰、规则明确的任务,无法替代人工处理非结构化、高风险、需要主观判断的复杂场景。企业级落地的最佳实践是人机协同:Agent完成重复性、标准化的基础工作,人工负责审核、决策、处理异常情况,既能提升效率,又能控制风险。
- 误区3:所有场景都应该用Agent,不用Agent就是落后
- 纠正:错误。Agent是解决复杂多轮任务的方案,不是万能钥匙。简单问答场景用LLM+RAG即可,单工具调用场景用LLM+Skill即可,强行使用Agent会增加系统复杂度、提升维护成本、降低响应速度,完全是过度设计。技术选型的核心是匹配业务场景,而非盲目追新。
- 误区4:Agent的效果只取决于LLM的能力
- 纠正:错误。LLM的推理能力是Agent的基础,但Agent的最终效果,70%取决于工具定义的精准度、规划策略的合理性、记忆管理的完善度、错误处理机制的健壮性。很多开发者用同一个LLM,别人的Agent稳定可用,自己的Agent频繁出错,核心原因就是工程化落地的细节不到位。
第六章 四大核心技术的协同架构与落地选型指南
前面我们分别拆解了LLM、RAG、Skill、Agent的核心原理与实战,这一章我们讲清楚四个技术的协同关系,以及不同业务场景下的选型策略,让Java开发者面对业务需求时,能快速做出正确的技术选型,避免过度设计与选型错误。
6.1 四大核心技术的层级协同架构
四个技术不是孤立的,而是从下到上的层级依赖关系,形成完整的企业级大模型应用技术栈,我们用架构图清晰展示:
核心协同逻辑:
- LLM是整个技术栈的核心底座:所有组件的能力都依赖LLM的推理、理解、生成能力,没有LLM,其他组件都无法运行;
- RAG和Skill是LLM的两大扩展组件:RAG解决LLM的知识问题,Skill解决LLM的执行问题,两者是LLM能力的延伸,也是Agent的核心能力来源;
- Agent是四大技术的集大成者:Agent以LLM为核心大脑,整合RAG的知识能力与Skill的执行能力,是大模型应用的最高层级形态,负责完成复杂的、多轮的、自主化的业务任务;
- Java基础设施是所有技术的落地载体:Spring生态、存储组件、监控运维,是企业级大模型应用稳定运行的基础保障。
6.2 不同业务场景的选型指南
我们整理了Java开发者最常遇到的8类业务场景,给出明确的技术选型方案,避免踩坑:
| 业务场景 | 核心需求 | 推荐技术选型 | 不推荐选型 |
|---|---|---|---|
| 企业内部知识库问答 | 基于内部文档、产品手册、规章制度,实现精准问答,无幻觉 | LLM + RAG | 纯LLM、Agent(过度设计) |
| 智能客服 | 基于产品知识库,回答用户问题,解决售后咨询 | LLM + RAG + 简单Skill(订单查询工具) | 全功能Agent(复杂度高,稳定性不足) |
| 代码生成/优化 | Java代码生成、代码评审、Bug修复、注释生成 | 纯LLM + 代码优化Skill | RAG(无特殊知识库需求无需使用)、Agent |
| 数据查询与报表生成 | 自然语言转SQL,查询业务数据库,生成数据报表 | LLM + Skill(SQL生成/查询/Excel生成) | 纯LLM(无法查询数据库)、复杂Agent |
| 内容创作 | 文案、文档、报告、公众号文章创作 | 纯LLM + RAG(行业知识增强) | Skill、Agent(无执行需求无需使用) |
| 自动化运维 | 自然语言指令执行服务器监控、日志查询、服务重启等运维操作 | LLM + Skill(运维工具) + 严格的安全管控 | 无人工审核的全自动Agent(风险极高) |
| 复杂业务流程自动化 | 完整的招聘计划、项目管理、合同审核、财务报销等多步骤业务流程 | Agent + RAG + Skill | 纯LLM、零散工具调用(无法完成多轮任务) |
| 个人助手 | 日程管理、待办提醒、信息查询、内容整理 | Agent + 基础Skill + 轻量RAG | 复杂架构(个人场景无需过度设计) |
6.3 选型的核心黄金法则
- 能简单解决的,绝对不要复杂化:能用纯LLM解决的,不要加RAG;能用LLM+RAG解决的,不要加Skill;能用LLM+RAG+Skill解决的,不要上Agent。技术复杂度越高,维护成本越高,稳定性越难保障。
- 优先解决核心痛点,不要追求大而全:先解决最核心的业务问题,比如知识库问答先解决幻觉问题,再逐步优化体验,不要一开始就追求全功能、全场景覆盖,导致项目周期无限拉长,最终无法落地。
- 优先成熟方案,不要盲目追新:企业级落地优先选择Spring AI、LangChain4j等成熟框架,不要自己从零实现核心逻辑;优先选择国内主流闭源大模型,不要盲目部署开源小模型,避免踩坑。
- 安全与合规优先,再谈功能体验:所有技术选型都必须优先考虑数据安全、隐私合规、业务风险,尤其是涉及企业内部敏感数据、写操作的场景,绝对不能为了功能体验牺牲安全。
第七章 企业级大模型应用落地的10条黄金避坑法则
基于我多年Java开发与大模型应用落地的经验,总结出10条Java开发者必须遵守的黄金法则,避开90%的落地坑,让你的项目从demo快速走向生产级落地:
- 绝对不要用微调解决知识更新问题,优先用RAG很多开发者一上来就想微调大模型,把企业内部数据喂给模型,这是最大的坑。微调不仅成本极高、周期极长,而且无法解决知识实时更新的问题,还会带来数据泄露风险。企业内部知识场景,RAG是首选方案,成本低、迭代快、安全可控,只有通用能力优化、风格对齐的场景,才需要考虑微调。
- 不要迷信大参数量模型,优先选择匹配场景的模型不是模型参数量越大、价格越贵,效果越好。简单的文案生成、知识库问答场景,7B/13B的开源模型或轻量闭源模型完全能满足需求,价格只有大模型的1/10;只有复杂的逻辑推理、Agent规划场景,才需要用大参数量的pro模型。选型的核心是匹配场景,而非盲目追求大模型。
- Prompt工程是所有大模型应用的基础,必须做扎实很多开发者忽略Prompt工程,随便写一句话就调用LLM,导致输出效果差、幻觉多、工具调用错误。80%的大模型应用问题,都可以通过优化Prompt解决。企业级落地必须制定标准化的Prompt规范,针对不同场景打磨专用Prompt模板,做好版本管理与效果测试。
- 生产环境必须做限流、重试、降级,不能直接裸调大模型API大模型API不是100%稳定的,会出现超时、限流、报错等异常情况。Java开发者必须用Resilience4j、Sentinel等组件,给大模型调用添加超时控制、重试机制、熔断降级、限流保护,避免大模型接口异常导致整个业务系统崩溃。
- 所有大模型交互必须做日志持久化,全链路可追溯生产环境必须把每一次大模型的调用:Prompt、返回结果、耗时、Token消耗、异常信息,全部持久化到数据库中。这不仅是排查问题的核心依据,也是合规审计的硬性要求,同时还能积累Prompt优化、模型选型的一手数据。
- 绝对不要相信LLM的输出,必须做结果校验无论LLM的输出看起来多么合理,都不能直接写入数据库、直接发送给用户、直接执行。必须针对不同场景做结果校验:代码生成要做语法校验,SQL生成要做语法校验与权限校验,数值计算要做二次核对,敏感内容要做安全审核,从根源上避免幻觉带来的业务风险。
- 不要把大模型当成数据库,不要传入超长上下文很多开发者把整个文档、整个数据库表都传入LLM上下文,不仅会导致Token成本飙升,还会让LLM出现注意力衰减,找不到关键信息,输出效果大幅下降。正确的做法是用RAG检索最相关的内容,只把核心信息传入上下文,控制上下文长度,兼顾效果与成本。
- 成本管控从一开始就要做,避免上线后成本失控大模型API的调用成本是持续的,很多项目demo阶段没问题,上线后用户量上来,Token成本直接失控。必须从一开始就做好成本管控:控制上下文长度、优化Prompt减少Token消耗、缓存高频问题的回答、设置单用户单日调用上限、选择性价比高的模型,避免上线后成本爆炸。
- Java生态有完善的大模型开发工具链,不要硬转Python很多Java开发者觉得大模型开发Python是主流,硬转Python开发,导致开发效率低、运维成本高、无法和现有Java业务系统集成。现在Java生态的大模型开发框架已经非常成熟,Spring AI、LangChain4j完全能覆盖所有企业级场景,和现有Spring生态无缝集成,Java开发者完全可以用熟悉的技术栈完成大模型应用开发。
- 大模型应用的核心是业务价值,而非技术炫技很多开发者盲目堆砌技术,为了用Agent而用Agent,为了用RAG而用RAG,忽略了业务本身的需求。大模型应用的核心是解决业务问题、创造业务价值,技术只是工具。永远要围绕业务需求做技术选型,而不是为了炫技盲目上复杂技术,最终做出一个技术很牛但没人用的项目。
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
市场对这一职业的高度认可,直接体现在薪资待遇上。
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
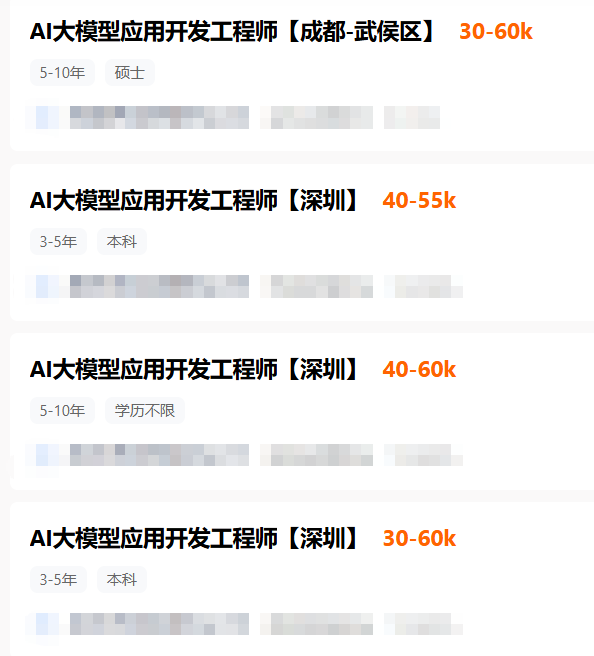
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 8
8 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)