
LLM推理引擎:主流框架深度解析与选型指南
当你向 ChatGPT 发送一句话、或者在本地跑一个开源模型时,背后有一套"推理引擎"在默默工作——它负责把模型从磁盘加载到显存,管理数千个请求的排队与调度,同时榨干每一块 GPU 的算力。这就是 LLM 推理框架做的事。
本文将逐个拆解当前主流的推理框架,用通俗语言讲清楚它们的核心原理,帮你建立完整的认知地图。
目录
一、先搞懂:推理框架在解决什么问题
二、核心概念速览
三、主流框架详解
-
vLLM — 用"虚拟内存"管理显存
-
SGLang — 用"前缀树"加速推理
-
TensorRT-LLM — NVIDIA 的性能核弹
-
llama.cpp — 在你的笔记本上跑大模型
-
DeepSpeed-MII — 微软的高吞吐方案
-
ExLlamaV2/V3 — 消费级显卡的性能极致
-
TGI (Text Generation Inference) — HuggingFace 的推理服务
-
LoRAX — 一个基座模型跑千个微调版本
四、横向对比
五、选型建议
六、总结
一、先搞懂:推理框架在解决什么问题
大模型推理的挑战可以概括为三个字:慢、贵、挤。
- 慢:生成一个 token 需要做一次完整的前向计算,而一段回答可能需要几百个 token。每多耗 1ms,用户体感就差一截。
- 贵:一块 H100 显卡要几十万人民币。能用更少的卡跑同样多的请求,就是直接省钱。
- 挤:生产环境中同时有成百上千个用户在请求。如何让这些请求高效共享 GPU,是框架的核心价值。
推理框架的本质就是一个调度系统 + 一堆底层优化,让模型在有限的硬件上跑得更快、服务更多人。
二、核心概念速览
在看具体框架之前,先统一几个关键概念:
KV Cache(键值缓存)
大模型的 Transformer 架构在生成每个新 token 时,需要回顾前面所有 token 的"注意力"。为了避免重复计算,系统会把前面 token 的 Key 和 Value 缓存起来,这就是 KV Cache。
类比:你在写一篇文章时,不需要每次都从头读一遍前面写的内容,而是把关键信息记在便签上。KV Cache 就是这些便签。
PagedAttention(分页注意力)
vLLM 团队提出的核心创新。传统方法为每个请求预分配一整块连续显存给 KV Cache,但实际生成长度不确定,导致大量显存浪费。PagedAttention 借鉴操作系统的虚拟内存分页思想,把 KV Cache 切成固定大小的"页"(page),按需分配、不连续存储。
类比:传统方式像给每个人发一本固定 100 页的笔记本,不管你写几页都占着整本。PagedAttention 像活页本,写一页加一页,空闲页可以给其他人用。
Continuous Batching(连续批处理)
传统批处理要等一个批次的所有请求都完成后才能开始下一个批次。Continuous Batching 则在任何一个请求完成生成后,立即把新请求插入批次,不让 GPU 闲着。
类比:餐厅传统模式是每桌点完菜、上齐、吃完才接待下一桌。连续批处理则是有空位就接客,不等别的桌吃完——更精确地说,就像火锅店的翻台率管理:吃完一桌立即翻台迎客,而不是等整层楼的桌都空了再统一打扫。
Speculative Decoding(推测解码)
用一个小模型(草稿模型)快速预测未来几个 token,然后用大模型一次性验证。如果猜对了,就省了好几次大模型前向计算。
类比:你口述一篇文章,打字员先根据上下文猜你接下来会说什么,猜对了就直接打出来,猜错了再改。速度比逐字听写快很多。
再打个比方:就像考试时先快速写个大概答案(小模型猜),老师批改时对了就跳过(大模型验证通过),错了才纠正。大部分人猜对的概率很高,所以整体速度快了一倍。
Tensor Parallelism / Pipeline Parallelism(张量并行 / 流水线并行)
- 张量并行:把模型的权重矩阵切分到多块 GPU 上,每块负责一部分计算。
- 流水线并行:把模型的不同层分配到不同 GPU 上,像流水线一样依次处理。
类比:流水线并行像工厂里每个人负责一道工序;张量并行像每个人同时负责一道工序的"一部分"。
更形象地说:流水线并行 = 火锅店的备菜→下锅→上菜三个人各管一步;张量并行 = 三个人同时切同一棵大白菜,每人切三分之一,最后拼起来。前者适合"步骤多"的场景,后者适合"计算大"的场景。
Prefix Caching(前缀缓存)
很多请求共享相同的前缀(比如同一个系统提示词),Prefix Caching 可以把共享前缀的 KV Cache 缓存起来复用,避免重复计算。
类比:100 个学生都要做同一道大题的前两小问,老师可以把前两小问的答案提前印好,不用每个人单独算一遍。
更贴近业务的比喻:就像客服系统里,所有对话都以"您好,我是 XX 客服,很高兴为您服务"开头。这句话的计算结果缓存一次,1000 个客户共享,不重复算。
Quantization(量化)
把模型权重从 16 位浮点数压缩到 8 位、4 位甚至更低的精度,减少显存占用和计算量。
类比:用更少的笔画写字,字迹可能稍模糊,但书写速度快了,纸也省了。
再打个比方:就像照片的分辨率。16 位精度是 4K 照片,4 位精度是 720p。远看(大部分推理场景)差别不大,但 720p 文件小、加载快。而 EXL2 那种逐层量化,就像给照片的不同区域用不同分辨率——人脸区域保持 4K,背景用 720p,总文件大小不变但观感更好。
三、主流框架详解
💡 读前提示:每个框架下面都有「📖 一句话比喻」,帮你用生活场景秒懂技术原理。
1. vLLM — 用"虚拟内存"管理显存
📖 一句话比喻:vLLM 就像一个智能酒店管理系统——传统方式是客人一入住就给他整层楼不管住不住,vLLM 则是按房间(页)分配,住一间给一间,退房了立即给下一位客人。空房率极低,客人越多越划算。
一句话概括:通过 PagedAttention 技术,像操作系统管理内存一样管理显存,大幅提升吞吐量。
背景:由 UC Berkeley 的 Sky Computing Lab 开发(论文发表于 SOSP 2023),目前已发展为社区驱动的开源项目,是当前最受欢迎的推理框架之一。
🔗 官方链接
GitHub:
https://github.com/vllm-project/vllm
官方文档:
https://docs.vllm.ai
论文:
https://arxiv.org/abs/2309.06180
官方博客:
https://blog.vllm.ai
核心原理
传统方式:每个请求预分配固定大小的连续显存块┌──────────────────────────────────┐│ Request A: ████████░░░░░░░░░░░░░ │ ← 预分配了空间但只用了一半│ Request B: ██████░░░░░░░░░░░░░░░ │ ← 同样浪费└──────────────────────────────────┘vLLM (PagedAttention):按需分配固定大小的页┌──────────────────────────────────┐│ Page 1: A的KV Page 2: A的KV │ ← 按需分配│ Page 3: B的KV Page 4: 空闲 │ ← 空闲页可复用└──────────────────────────────────┘
vLLM 把每个请求的 KV Cache 切成固定大小的 block,用一张"映射表"记录哪些 block 属于哪个请求。这样:
- 不需要预估生成长度,按需分配
- 不同请求可以共享相同的 block(实现前缀缓存)
- 内存碎片大幅减少,显存利用率从 ~20% 提升到 ~90%
关键特性
- Continuous Batching:请求即来即走,不等待批次完成
- Prefix Caching:共享系统提示词的请求可以复用 KV Cache
- Speculative Decoding:支持投机解码加速生成
- Chunked Prefill:将长 prompt 的计算切成小块,避免阻塞 decode 阶段
- 多硬件支持:NVIDIA GPU、AMD GPU、Intel GPU、TPU、CPU 等
- OpenAI 兼容 API:可以直接替代 OpenAI 的接口使用
- 量化支持:GPTQ、AWQ、FP8、INT4/INT8 等
- 分布式推理:支持张量并行、流水线并行、专家并行
适用场景:在线推理服务、需要高吞吐的生产环境、多租户共享 GPU 集群。
2. SGLang — 用"前缀树"加速推理
📖 一句话比喻:SGLang 就像一个超级图书管理员。别的图书馆每次借书都要从头找,而 SGLang 用一棵"分类树"把所有书按前缀组织好了。你来借"Python 入门",他发现前面已经有人借过"Python"这个前缀了,直接从那个分支继续找,省了一大半时间。而且不管多少人同时借书,管理员处理每个人的调度几乎是零延迟的——因为他把工作流程练成了肌肉记忆。
一句话概括:结合前缀树(RadixAttention)和零开销调度器,在结构化输出和复杂推理链场景下表现极致。

背景:由 LMSYS(UC Berkeley)团队开发,核心成员也是 Vicuna(羊驼)和 Chatbot Arena 的创建者。2025 年加入 PyTorch 生态系统,目前驱动着全球超过 40 万块 GPU。
🔗 官方链接
GitHub:https://github.com/sgl-project/sglang
官方文档:https://docs.sglang.io
LMSYS 博客:https://lmsys.org/blog
PyTorch 生态公告:https://pytorch.org/blog/sglang-joins-pytorch
核心原理
SGLang 的两大杀手锏是 RadixAttention 和 零开销 CPU 调度器。
RadixAttention(基数树注意力)
传统前缀缓存用哈希表来存储和查找共享前缀。SGLang 用一棵**基数树(Radix Tree)**来管理所有请求的 KV Cache:
Root / \ "System: You "System: You are a helpful are a code assistant..." assistant..." | | "User: Hello" "User: Write a | function..." "Bot: Hi! How "Bot: Sure, can I help?" here's..."
树的每个节点是一段 token 序列的 KV Cache。当新请求到来时,沿着树向下匹配,找到最长公共前缀,直接复用,不需要的节点被淘汰。
优势:
- 支持任意长度的前缀匹配,不只是精确匹配
- 淘汰策略灵活(LRU、FIFO 等)
- 多轮对话天然受益——每轮对话的前缀都是前几轮的延续
零开销 CPU 调度器
传统调度器在调度请求时需要做大量 Python 层面的操作(序列化、状态管理等),在高并发下 CPU 成为瓶颈。SGLang 把调度逻辑下沉到 C++ 层,实现"零开销"调度——CPU 调度时间趋近于零,GPU 几乎不等待。
其他亮点
- Prefill-Decode 分离:将计算密集的 prefill 阶段和带宽受限的 decode 阶段分开调度,各取所需
- 结构化输出加速:用压缩有限状态机(Compressed FSM)加速 JSON 等格式化输出,速度提升最高 7 倍
- Diffusion 模型支持:2026 年新增对图像/视频生成模型的加速
- RL/后训练集成:被 verl、AReaL 等主流强化学习框架用作推理后端
适用场景:复杂提示工程、多轮对话、结构化输出(JSON/XML)、强化学习推理。
3. TensorRT-LLM — NVIDIA 的性能核弹
📖 一句话比喻:TensorRT-LLM 就像把普通菜谱翻译成米其林后厨的 SOP。别的厨师还在拿着菜谱一步步看(解释执行),TensorRT-LLM 已经把整个做菜流程精简成了:哪些步骤可以合并一起做(算子融合)、每道菜用什么火候最快(Kernel Auto-Tuning)、哪些调料可以提前配好(内存规划)。而且它只为 NVIDIA 的灶台优化——它比任何人都了解自家灶台的脾气。
一句话概括:NVIDIA 官方出品,深度榨干 NVIDIA GPU 的每一滴算力,性能天花板最高。

背景:基于 NVIDIA TensorRT(通用深度学习推理引擎)构建,专门针对 LLM 场景优化。2025 年 3 月完全开源。
🔗 官方链接
GitHub:
https://github.com/NVIDIA/TensorRT-LLM
官方文档:
https://nvidia.github.io/TensorRT-LLM
技术博客系列:
https://nvidia.github.io/TensorRT-LLM/blogs
DeepSeek R1 优化博客:
https://developer.nvidia.com/blog/nvidia-blackwell-delivers-world-record-deepseek-r1-inference-performance
核心原理
TensorRT-LLM 的核心思路是编译时优化 + 运行时调度。
编译时优化(Build Phase)
在模型部署前,TensorRT-LLM 会对模型做一次深度编译:
PyTorch 模型 (.bin/.safetensors) │ ▼┌─────────────────────────┐│ 图优化 (Graph Opt) │ ← 算子融合、常量折叠、冗余消除│ Kernel Auto-Tuning │ ← 根据 GPU 型号自动选择最优 kernel│ 量化 (Quantization) │ ← FP8/INT4/INT8 量化│ 内存规划 │ ← 预分配显存,避免运行时申请└─────────────────────────┘ │ ▼TensorRT Engine (.engine)
- 算子融合:把多个小算子合并成一个大算子,减少 GPU kernel 启动次数。比如把 LayerNorm + Add + GELU 融合成一个 kernel。
- Kernel Auto-Tuning:同一操作可能有十几种实现方式(不同 tile 大小、不同算法)。TensorRT-LLM 会自动 benchmark 选出最快的。
- FP8 量化:针对 NVIDIA Hopper/Blackwell 架构的 FP8 Tensor Core 做专门优化。
运行时调度
- Disaggregated Serving(分离部署):Prefill 和 Decode 阶段可以在不同 GPU 上执行,各自独立扩缩容
- Expert Parallelism(专家并行):针对 MoE 模型(如 DeepSeek-V3),把不同专家放到不同 GPU 上,减少每块 GPU 的计算量
- Sparse Attention(稀疏注意力):跳过不重要的注意力计算,加速长序列推理
为什么性能最高
- NVIDIA 自己的 GPU,自己最了解怎么压榨
- 所有 kernel 都是手写 CUDA,而不是依赖通用框架
- 针对 Blackwell(B200/GB200)架构有专门优化,性能比通用方案高 2-5 倍
关键特性
- Day-0 支持最新模型(DeepSeek-V3.2、Llama 4、GPT-OSS 等)
- 支持 N-Gram Speculative Decoding
- Tensor/Pipeline/Expert/Data 四种并行策略
- KV Cache 重用优化
- Triton Inference Server 集成
适用场景:追求极致性能的 NVIDIA GPU 集群、大规模在线推理服务、对延迟敏感的场景。
劣势:绑定 NVIDIA 硬件,不支持 AMD/Intel GPU;部署复杂度较高。
4. llama.cpp — 在你的笔记本上跑大模型
📖 一句话比喻:llama.cpp 就像一辆手动挡的越野车。别的框架需要豪华配置(高端 GPU、Python 环境、CUDA 工具链),llama.cpp 什么路况都能跑——在你的 MacBook 上跑、在树莓派上跑、甚至在服务器 CPU 上跑。它把模型压缩成 GGUF 格式,就像把大行李压缩成真空袋,体积小了、功能没丢。你甚至可以把模型的"头"放 GPU 上、"身体"放 CPU 上,自动协调工作——就像一辆车前轮有发动机、后轮有人推,也能跑起来。
一句话概括:纯 C/C++ 实现,零依赖,让大模型在任何设备上都能跑——从手机到树莓派。

背景:由 Georgi Gerganov 于 2023 年发起,现在是 ggml 组织的核心项目。定义了 GGUF 模型格式,成为边缘推理的事实标准。
🔗 官方链接
GitHub:
https://github.com/ggml-org/llama.cpp
GGUF 格式说明:
https://github.com/ggml-org/llama.cpp/blob/master/gguf.md
HuggingFace GGUF 模型库:
https://huggingface.co/models?library=gguf
VS Code 插件:
https://github.com/ggml-org/llama.vscode
核心原理
llama.cpp 的设计哲学是极致的可移植性和最小的依赖。
GGUF 格式
传统格式 (.bin/.safetensors)├── 需要 Python + PyTorch + Transformers├── 需要 GPU(至少 16GB 显存)└── 部署复杂GGUF 格式 (.gguf)├── 单文件,自包含(模型 + 配置 + 词表)├── 量化权重直接内嵌└── 零依赖加载
GGUF 把模型的所有信息打包成一个文件,内置量化权重,可以在没有任何 Python 依赖的情况下被 C++ 代码直接加载。
量化策略
llama.cpp 支持的量化精度极其丰富:
| 量化类型 | 每权重位数 (bpw) | 7B 模型大小 | 质量损失 |
|---|---|---|---|
| Q8_0 | 8.5 | ~7.5 GB | 几乎无损 |
| Q5_K_M | 5.5 | ~4.8 GB | 轻微 |
| Q4_K_M | 4.8 | ~4.1 GB | 可接受 |
| Q3_K_M | 3.9 | ~3.3 GB | 明显 |
| Q2_K | 3.4 | ~2.8 GB | 严重 |
其中 K 系列使用了 k-quant 方法,对不同层使用不同精度——敏感层用高精度,不敏感层用低精度,比一刀切的量化效果好很多。
硬件加速
- Apple Silicon:一等公民,使用 Metal/Accelerate 框架,M 系列芯片性能出色
- x86 CPU:AVX/AVX2/AVX512/AMX 指令集加速
- NVIDIA GPU:自定义 CUDA kernel
- AMD GPU:HIP 后端
- Vulkan:跨平台 GPU 加速
- CPU+GPU 混合推理:模型太大塞不进显存?把一部分层放 GPU,一部分放 CPU,自动协调
适用场景:本地部署、边缘设备、笔记本/手机推理、不想装 CUDA 环境的场景。
劣势:单机推理为主,不擅长高并发在线服务;性能比不上 GPU 专用优化框架。
5. DeepSpeed-MII — 微软的高吞吐方案
📖 一句话比喻:Dynamic SplitFuse 就像快餐店的出餐策略。假设有一桌客人点了 20 个汉堡,传统做法是厨师全力做完这 20 个才做下一位客人的单。Dynamic SplitFuse 则是把大单拆成"先做 5 个",穿插做下一位客人的 1 个汉堡,再回来做 5 个……所有人都不用等太久,整体出餐效率更高。
一句话概括:微软出品,用 Blocked KV Caching + Dynamic SplitFuse 技术实现高吞吐推理。

背景:由微软 DeepSpeed 团队开发,底层基于 DeepSpeed-Inference。宣称比 vLLM 有最高 2.5 倍的吞吐提升。
🔗 官方链接
GitHub(MII):
https://github.com/deepspeedai/DeepSpeed-MII
GitHub(DeepSpeed):
https://github.com/deepspeedai/DeepSpeed
官方文档:
https://www.deepspeed.ai
FastGen 博客:
https://github.com/deepspeedai/DeepSpeed/tree/master/blogs/deepspeed-fastgen
核心原理
Blocked KV Caching
和 vLLM 的 PagedAttention 类似,DeepSpeed-MII 也把 KV Cache 切成块来管理,但实现细节有所不同。MII 把 block 大小固定为 token 粒度,在 prefill 和 decode 阶段使用不同的 block 分配策略。
Dynamic SplitFuse(动态分割融合)
这是 MII 最独特的技术。
传统方式下,一个长 prompt 的请求会独占 GPU 资源,导致短请求排队等待。Dynamic SplitFuse 的做法:
长请求 (prompt 1000 tokens)├── 第 1 步:处理 256 tokens├── 第 2 步:处理 256 tokens ├── 第 3 步:处理 256 tokens└── 第 4 步:处理剩余 tokens + 开始 decode同时插入短请求 (prompt 50 tokens)└── 在步骤之间的缝隙中穿插处理
它把长 prompt 拆成固定大小的"片段",分多步处理,每一步的计算量是恒定的。这样短请求可以在步骤间的"缝隙"中被处理,不会被长请求阻塞。
类比:餐厅不再让一桌点 20 道菜的客人独占厨房,而是把大订单拆成小份,穿插着做其他桌的菜,所有桌都更快上菜。
适用场景:多租户推理服务、请求长度差异大的场景。
注意:项目最近更新频率降低,社区活跃度不如 vLLM 和 SGLang。
6. ExLlamaV2/V3 — 消费级显卡的性能极致
📖 一句话比喻:EXL2 量化就像给博物馆的每幅画配不同精度的画框。蒙娜丽莎用金框(高精度),走廊上的装饰画用普通框(低精度),总预算不变,但视觉效果最大化。别的量化方式是"全部用一样的框",EXL2 则逐层精细调配——这就是为什么它能在 4GB 显存里跑出别人 6GB 的效果。
一句话概括:在消费级 GPU(如 RTX 3090/4090)上实现极致推理速度。

背景:由 turboderp 开发,ExLlamaV2 已归档,后续开发转向 ExLlamaV3。
🔗 官方链接
ExLlamaV2 GitHub(已归档):
https://github.com/turboderp-org/exllamav2
ExLlamaV3 GitHub(开发中):
https://github.com/turboderp-org/exllamav3
TabbyAPI(推荐后端):
https://github.com/theroyallab/tabbyAPI
ExUI(Web 界面):
https://github.com/turboderp/exui
核心原理
ExLlamaV2 的核心是 EXL2 量化格式和动态批处理器。
EXL2 量化
与 GPTQ/AWQ 不同,EXL2 允许在模型的每一层、甚至每一个 attention head 上使用不同的量化精度:
Layer 1 (敏感层): 6.0 bpw ← 高精度Layer 2-10 (普通): 4.0 bpw ← 中等精度 Layer 11-20 (不敏感): 3.0 bpw ← 低精度Layer 32 (输出层): 5.0 bpw ← 中高精度
这种逐层精细调优的方式,可以在固定的模型大小预算下获得最佳质量。
动态批处理器
ExLlamaV2 的动态生成器支持:
- 智能 prompt 缓存(相似 prompt 自动复用)
- KV Cache 去重
- 异步流式生成
- 推测解码
性能参考(RTX 4090):
- Llama 7B GPTQ:205 tokens/s
- Llama2 7B EXL2 4.0bpw:211 tokens/s
- CodeLlama 34B EXL2 4.0bpw:50 tokens/s
适用场景:个人本地部署、消费级 GPU 用户、追求极致单卡速度。
7. TGI (Text Generation Inference) — HuggingFace 的推理服务
📖 一句话比喻:TGI 就像一位已经培养出优秀学生的老师,功成身退了。它开创了很多推理优化的标准做法(Paged Attention、连续批处理),现在这些技术已经被 vLLM 和 SGLang 继承并发扬光大。HuggingFace 说:“我推荐大家用这两个学生。”
一句话概括:HuggingFace 官方推理引擎,与 HuggingFace 生态深度集成,但已进入维护模式。
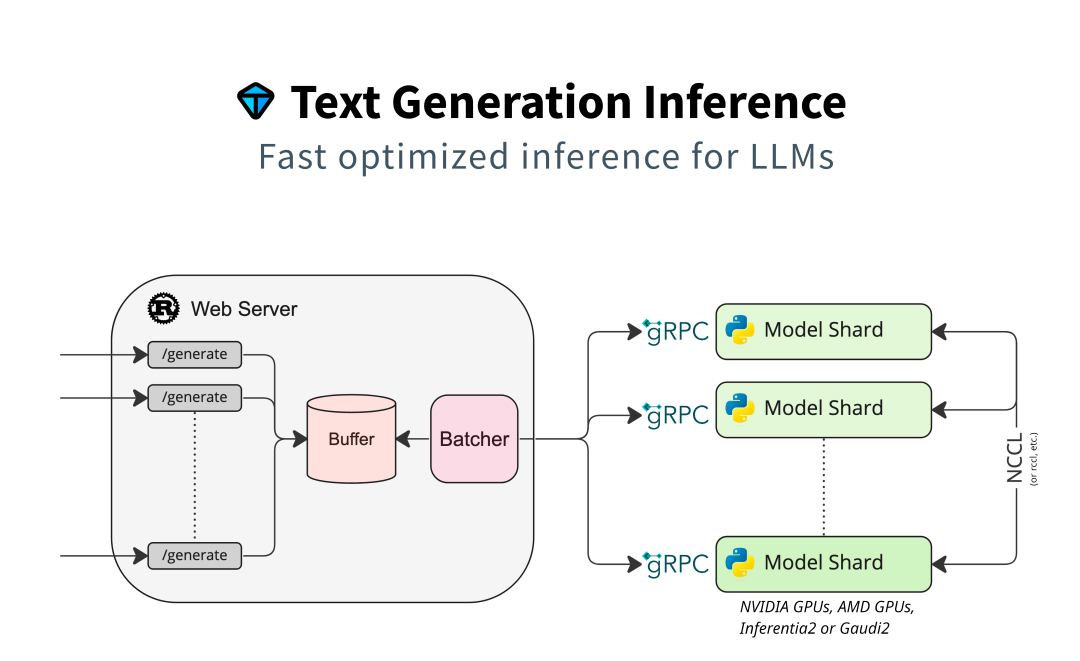
背景:由 HuggingFace 用 Rust + Python 开发,曾是 HuggingFace Inference API 和 Inference Endpoints 的底层引擎。
🔗 官方链接
GitHub:
https://github.com/huggingface/text-generation-inference
官方文档:
https://huggingface.co/docs/text-generation-inference
迁移公告(推荐 vLLM/SGLang):GitHub README 中声明
现状:HuggingFace 已宣布 TGI 进入维护模式,推荐用户迁移到 vLLM 或 SGLang。这是一个重要的信号——HuggingFace 认为这两个社区项目已经足够成熟,值得直接贡献和推荐。
核心特性(仍有参考价值)
- OpenAI 兼容 API
- 张量并行 + 连续批处理
- Flash Attention + Paged Attention
- 量化支持(bitsandbytes、GPTQ、AWQ、FP8)
- 结构化输出 / JSON 模式
- 推测解码
建议:新项目不建议使用 TGI,直接选择 vLLM 或 SGLang。
8. LoRAX — 一个基座模型跑千个微调版本
📖 一句话比喻:LoRAX 就像一个只有 1 套房子但有 1000 把钥匙的房东。传统做法是每个租客(LoRA 适配器)各租一套房——1000 个租客需要 1000 套房(1000 块 GPU)。LoRAX 的做法是:大家共住一套房(基座模型),每个租客来的时候带上自己的装饰品(LoRA 权重),用完带走。下一个租客来了,换上自己的装饰品。一套房服务千人。
一句话概括:专为 LoRA 微调模型设计的推理服务器,一个基座模型同时服务数千个 LoRA 适配器。

景:由 Predibase 开发,Apache 2.0 开源。
🔗 官方链接
GitHub:
https://github.com/predibase/lorax
官方文档:
https://predibase.github.io/lorax
LoRA 适配器指南:
https://predibase.github.io/lorax/models/adapters
核心原理
如果你有 100 个基于 Llama-7B 的 LoRA 微调版本,传统做法是每个版本加载一个模型实例,需要 100 块 GPU。LoRAX 的做法是:
一块 GPU 上:┌─────────────────────────────┐│ Llama-7B 基座模型 │ ← 共享,只加载一次├─────────────────────────────┤│ LoRA A LoRA B LoRA C ... │ ← 按需动态加载/卸载└─────────────────────────────┘
- 动态适配器加载:请求到来时即时加载对应 LoRA 权重,不阻塞其他请求
- 异构连续批处理:同一 batch 中可以包含不同 LoRA 适配器的请求
- 适配器交换调度:在 GPU 和 CPU 内存之间异步预取和卸载适配器
适用场景:大量 LoRA 微调模型的统一服务、SaaS 平台多租户、需要同时部署数百个定制模型的场景。
四、横向对比
| 特性 | vLLM | SGLang | TensorRT-LLM | llama.cpp | DeepSpeed-MII | ExLlamaV2/V3 | LoRAX |
|---|---|---|---|---|---|---|---|
| 开发方 | Berkeley | LMSYS | NVIDIA | 社区 | Microsoft | 社区 | Predibase |
| 语言 | Python/C++ | Python/C++ | C++/Python | C/C++ | Python/C++ | Python/C++ | Rust/Python |
| 硬件 | 多平台 | 多平台 | NVIDIA only | 全平台 | NVIDIA | NVIDIA | NVIDIA |
| 核心创新 | PagedAttention | RadixAttention | 编译优化 | GGUF格式 | SplitFuse | EXL2量化 | 多LoRA调度 |
| 在线服务 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 边缘部署 | ⭐⭐ | ⭐⭐ | ⭐ | ⭐⭐⭐⭐⭐ | ⭐ | ⭐⭐⭐⭐ | ⭐⭐ |
| MoE 支持 | ✅ | ✅ (优秀) | ✅ (优秀) | ✅ | ❌ | ❌ | ❌ |
| 活跃度 | 🔥 非常活跃 | 🔥 非常活跃 | 🔥 活跃 | 🔥 非常活跃 | 📉 降温中 | 🔄 转向V3 | 📉 较低 |
五、选型建议
你有 NVIDIA 集群,追求极致性能? └→ TensorRT-LLM你要开箱即用的高吞吐在线服务? └→ vLLM 或 SGLang(都很成熟,二选一)你有很多结构化输出 / 多轮对话场景? └→ SGLang(RadixAttention + FSM 加速)你只有笔记本 / 没有 GPU / 边缘设备? └→ llama.cpp你有几百个 LoRA 微调版本要同时服务? └→ LoRAX你有 AMD GPU? └→ vLLM 或 SGLang(两者都支持 AMD)你想在消费级显卡(3090/4090)上跑? └→ ExLlamaV3 + TabbyAPI
六、总结
2026 年的 LLM 推理框架格局已经非常清晰:
- vLLM 和 SGLang 是在线推理服务的两大主流选择,社区最活跃,功能最全面
- TensorRT-LLM 是 NVIDIA 生态的性能天花板,适合对延迟和吞吐有极致要求的场景
- llama.cpp 是边缘推理的绝对王者,让大模型走进了每一个设备
- TGI 已功成身退,其理念被 vLLM 和 SGLang 继承
- LoRAX 在多 LoRA 服务场景有独特价值
技术在快速演进。关注这些项目的 GitHub 和官方博客,跟上节奏,才能在选型时做出最合适的决策。
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
市场对这一职业的高度认可,直接体现在薪资待遇上。
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
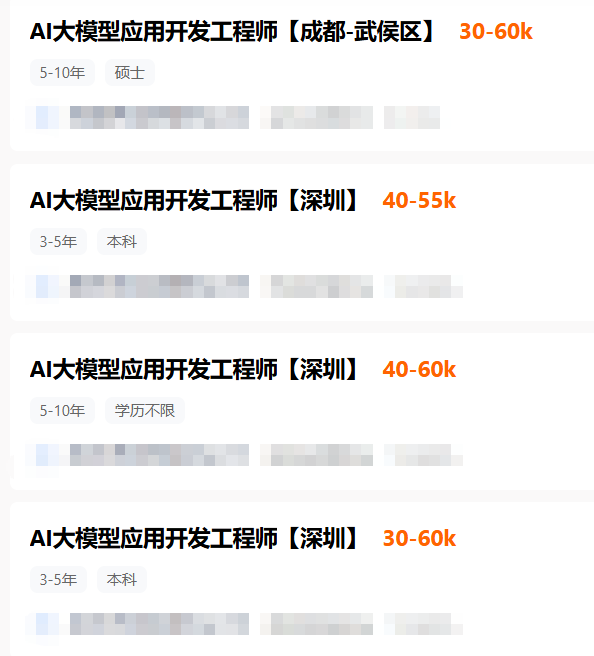
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 9
9 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)