
体系结构论文(八十九):ACCELOPT: A SELF-IMPROVING LLM AGENTIC SYSTEM FOR AI ACCELERATOR KERNEL OPTIMIZATION
ACCELOPT: A SELF-IMPROVING LLM AGENTIC SYSTEM FOR AI ACCELERATOR KERNEL OPTIMIZATION
这篇文章的核心
让 LLM 像“内核优化工程师”一样,自动给新型 AI 加速器写高性能 kernel,而且还能越做越会做。
具体来说,它提出了一个系统叫 AccelOpt。
目标是围绕已有 kernel 反复优化,自动探索更好的实现方式,尤其面向像 AWS Trainium 这种还没有成熟优化经验库的新型 AI 加速器。论文认为,这类硬件的 kernel 优化很难,原因是要同时考虑内存层次、并行方式、调度策略和硬件特性,而且人工积累经验慢、代价高。它的关键设计有两个:
1. Beam search 式迭代搜索
每一轮从一批候选 kernel 出发,先由 planner 生成多个优化计划,再由 executor 尝试实现这些计划,生成很多新 kernel,然后筛出更好的继续迭代。2. Optimization memory(优化记忆)
系统会把之前优化过程中出现的 slow-fast kernel pair(慢版本/快版本)以及总结出来的通用优化经验存下来,作为后续迭代的“经验库”。
这些经验既包括成功优化,也包括失败尝试,目的是让系统自己积累“什么改法通常有效、什么改法容易出问题”的知识,从而实现 self-improving。agent workflow
系统里有三个主要 agent:
- planner:根据当前 kernel、profile 信息和历史经验,提出优化计划
- executor:把计划改写成实际 kernel 代码
- summarizer:从慢/快 kernel 对中提炼出可迁移的优化经验,写回 memory
评测
作者还做了一个基准集 NKIBench,包含 14 个来自真实 LLM workload 的 Trainium NKI kernels,覆盖单算子、融合算子链和更大的模块,比如 Matmul、BatchMatmul、LoRA、Group Query Attention、Mamba block 等。这个 benchmark 不只看“相对原始版本提速多少”,还估计了接近硬件峰值吞吐的程度。
- 在 Trainium 1 上,平均 peak throughput 从 49% 提升到 61%
- 在 Trainium 2 上,从 45% 提升到 59%
- 效果基本能达到 Claude Sonnet 4 的水平
- 但如果用开源模型组合来做 AccelOpt,成本便宜 26×
另外,论文还证明它不只是会做局部小修小改,也能做跨循环、跨阶段的全局优化。例如在 fused BatchMatmul + Softmax 例子里,它先通过重算消除 spilling,再进一步调整结构,最终把延迟从 12.0 ms 降到 6.4 ms,并把 vector engine utilization 从 46% 提到 84%。
论文还拿两个有人工优化版本的例子做了对比:
- Mamba kernel:从 28.4% peak 提高到 54.6% peak,略高于最好人工版本 52.7%
- RoPE kernel:从人工版本基础上再做到 1.4× speedup
这说明它在某些 case 上已经能达到甚至超过专家手工优化的效果。
一、INTRO
1.1 论文要解决的问题
作者说,面对新型 AI 加速器,kernel 优化非常依赖专家经验,但这种经验往往是硬件专属的、难积累的、不可迁移的。
所以他们想做一个系统:不依赖人工提供硬件优化秘籍,也能自动优化 kernel。
1.2 它提出了什么
他们提出了 AccelOpt,一个 self-improving LLM agentic system。
- LLM agentic system:不是单次问模型写代码,而是一个多阶段 agent 工作流
- self-improving:不是一次性优化,而是会把以前优化得到的经验存起来,后面继续用
- kernel optimization:目标是优化加速器上的底层 kernel 实现,而不是上层模型结构
1.3 它怎么做
它通过 iterative generation(迭代生成)来探索优化空间,并且这个过程会被 optimization memory 引导。
也就是说,它不是“生成一次、测一次、结束”,而是:
生成候选 → profile 测性能 → 总结经验 → 写入 memory → 再生成下一轮。
为什么 kernel 很重要
大模型时代算力需求暴涨,所以 AI accelerator 越来越重要。
但加速器性能高不高,不只取决于芯片硬件本身,还很依赖 kernel 效率,因为 kernel 决定了算子怎样映射到硬件资源上。
如果 kernel 写得差,就会导致:
- 计算资源浪费
- 系统整体性能上不去
- 大规模部署时浪费很多钱
这里的意思很像你熟悉的 NPU 场景:
硬件峰值是一回事,真正能不能跑到高利用率,是 kernel/编译/调度共同决定的。
这里的 kernel 是什么
- 文中定义:kernel 是 “low-level implementations that determine how machine learning operators are mapped onto hardware resources”,也就是“把机器学习算子映射到硬件资源上的底层实现”。
- 换句话说,像 Matmul、Softmax、BatchMatmul、LoRA、Attention 这些算子,最终都要写成一段段真正调用加速器资源的程序,这些程序就是这里说的 kernel。
- 这篇文章优化的是 软件。更准确地说,是在优化:循环结构、张量布局、数据搬运方、并行划分、内存访问、调度与重算策略。这些都属于 kernel code / program transformation 层面的事。它并没有去修改 Trainium 芯片的硬件结构
为什么 kernel optimization 很难
即便是 GPU 这种成熟平台,kernel 优化都很难。原因是它要同时处理很多耦合因素:
- workload 特征
- memory hierarchy
- parallelism
- architecture-specific constraints
因此 kernel 优化本质上是一个巨大的经验驱动搜索问题。
对新型 AI accelerator 来说更难,因为这些平台不像 GPU 那样已经有成熟优化套路,开发者缺少“性能直觉”和现成 heuristics。
这其实是全文的问题定义:
新型加速器上,kernel 优化空间大、经验少、人工成本高。
为什么专门选 AWS Trainium
作者说他们聚焦 AWS Trainium 和它的 NKI 编程模型,原因不是它最常见,而是它很适合作为“新型加速器”的代表。
因为相比 GPU,Trainium 缺少成熟的优化经验库。
所以问题就变成:
LLM 能不能在几乎没有人类手工优化 recipe 的情况下,自己探索出高性能 kernel?
核心挑战
挑战一:搜索空间太大
Trainium kernel 优化涉及:
- memory layout
- parallelization scheme
- scheduling strategy
这些组合起来,设计空间很大。
但每次调用 LLM 又很贵,所以不能盲目乱搜,必须兼顾搜索覆盖率和成本效率。
挑战二:系统要能自己积累经验
他们希望系统在探索过程中,能把优化 insight 自己积累下来,让后续轮次更聪明。
也就是从一次性优化器,变成一个会学习优化经验的系统。
这就是为什么标题里强调 self-improving。
方法
他们的回答是:
用 beam search 做搜索骨架
系统不是只保留一个当前最优 kernel,而是保留一批 candidate kernels。
每一轮:
- 对每个 candidate 生成多个优化 plan
- 每个 plan 再做多次实现尝试
- 从所有新结果里选出更好的 candidate 进入下一轮
这就是一个典型的 beam search / population-based search 思路。
好处是不会太早陷入单一路径。
这篇文章里的 beam search,本质上就是一种 保留前沿最优解并持续扩展 的搜索策略。论文原文说 “iteratively update the frontier of candidate kernels and surface the best ones for the next round of exploration”。也就是:每轮都更新一批候选 kernel,只把当前最值得继续探索的那几个留下来,进入下一轮。
放到 AccelOpt 里:
- 当前有 B 个 candidate kernels
- 对每个 candidate,planner 生成 N 个优化 plan
- 对每个 plan,executor 再做若干实现尝试,最终一轮会得到很多新 kernel
- 然后从“旧 candidates + 新生成 kernels”里,挑出下一轮继续探索的 B 个。
用 optimization memory 做经验积累
每轮优化后,系统会从“慢版本 kernel”和“快版本 kernel”的对比中,总结出:
- 哪段代码被改了
- 为什么这样改更快
- 这个优化有没有可迁移的模式
然后把这些内容写进 optimization memory。
之后 planner 再生成新计划时,会参考这些记忆。
每个 experience item 由两部分组成:
- 一个 slow-fast kernel pair
- 以及从这对 kernel 中提炼出的 generalizable optimization strategy。
这里的 slow-fast kernel pair,就是一对前后对照的 kernel:
- slow kernel:性能较差的版本
- fast kernel:性能更好的版本
它们一般做的是同一个算子/同一个功能,但是代码实现不同,所以速度不同。
论文说 slow-fast pairs 有两种来源:
第一种:正向优化(positive rewrites)
- baseline kernel
- generated faster kernel
也就是:从原始版本到更快版本。
第二种:负向重写(negative rewrites)
- generated slower kernel
- baseline kernel
也就是:某次改写失败了,变慢了。
系统不是只想知道“哪个版本快”,它更想知道:
- 代码具体改了什么
- 这个改动为什么会快
- 这种经验能不能迁移到别的 kernel 上
所以 summarizer 会从这对 slow-fast kernels 中抽出关键优化片段,并总结成一个更通用的 insight,放进 optimization memory。
也就是说,memory 里存的不是整段原始代码,而是:
- 慢版本 → 快版本 的关键差异
- 以及对应的优化规律
三类 agent
系统里有三个 agent:
- Planner:提出优化计划
- Executor:把计划具体改成代码
- Summarizer:把优化前后差异总结成经验,写入 memory
所以它不是单 Agent,而是一个带闭环的 pipeline。
图 1
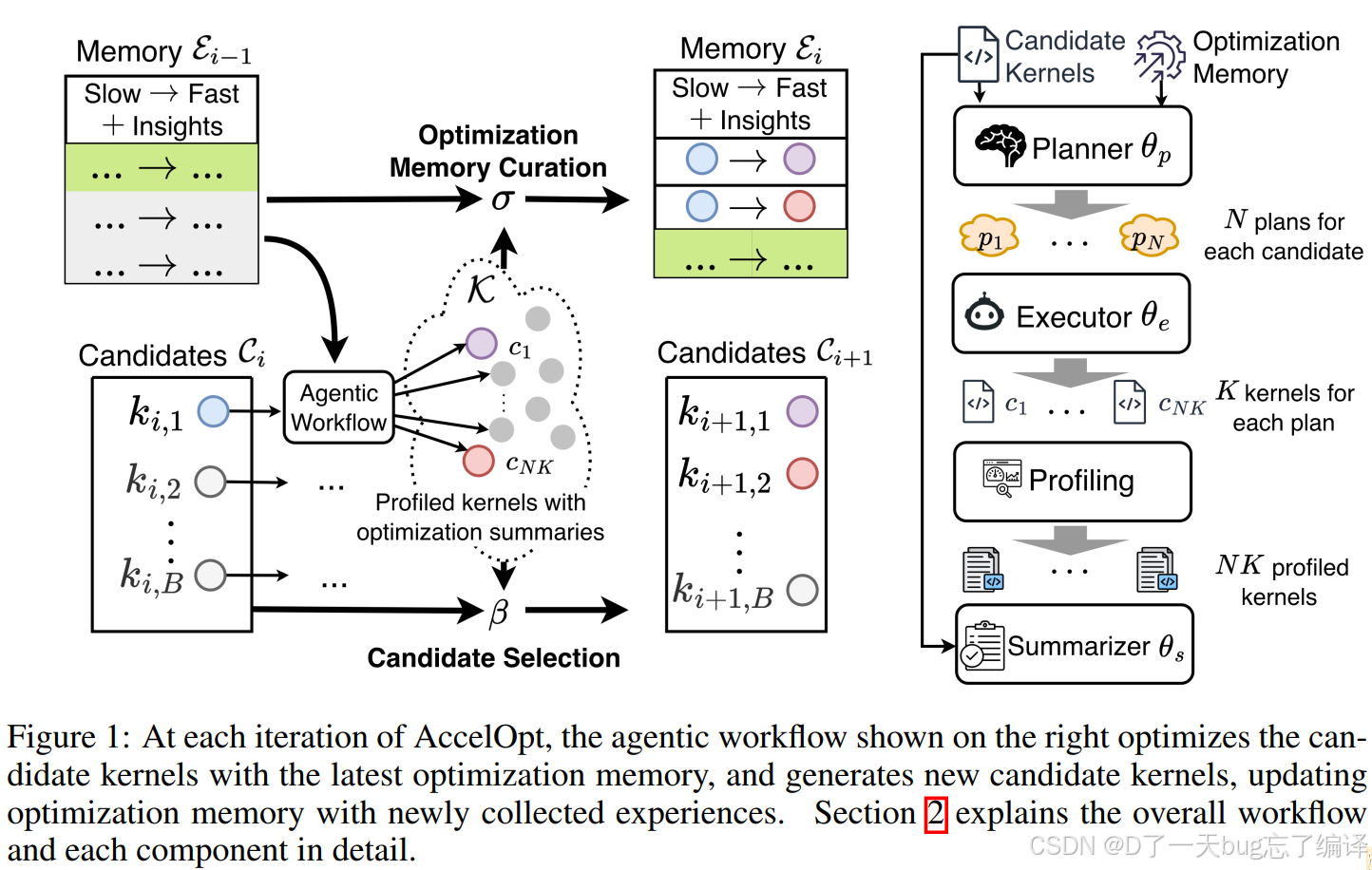
图 1 其实就是整套 AccelOpt 的总流程图。
左半边:迭代搜索的外循环
左图表示第 i 轮到第 i+1轮的演化过程:
- 输入:上一轮的 memory E_{i-1} 和当前候选 kernel 集合 C_i
- 中间:agentic workflow 生成大量新 kernel,并做 profiling
- 上方:根据这些结果更新 memory E_i
- 下方:从旧候选 + 新生成 kernel 中选出下一轮候选 C_{i+1}
你可以把它理解成两条并行更新链:
- 一条更新“候选解集合”
- 一条更新“经验知识库”
右半边:单轮内部的 agent 流程
右图表示一次迭代内部是怎么跑的:
- Planner 读取 candidate kernels 和 optimization memory
- 为每个 candidate 生成 N 个 plans
- Executor 对每个 plan 生成 K 个 kernel 实现
- 对所有生成的 kernel 做 profiling
- Summarizer 根据 profile 和代码差异,总结经验并写入 memory
二、方法
1. 一次 AccelOpt 迭代怎么跑

它描述的是第 i 轮优化流程。输入有两类:
- E_{i-1}:上一轮留下来的经验,也就是 optimization memory
- C_i:当前这一轮要继续优化的候选 kernels,数量是 B 个
这一轮里会做 4 件事:
(1) planner 先给每个 candidate kernel 出 N 个优化计划
也就是对同一个 kernel,不只想一种改法,而是想很多种。这样可以扩大搜索范围。
(2) executor 按每个 plan 去真正改代码
每个 plan 不只尝试一次,而是会生成若干实现版本。论文里记成总共会得到很多 profile 过的 kernels。
(3) profiler 给这些新 kernels 测性能
也就是不是只看“代码像不像合理”,而是直接跑 profile,拿真实性能反馈。
(4) 两个输出同时更新
- 用 σ 做 memory curation,得到新的经验库 E_i
- 用 β 从旧 candidates + 新生成 kernels 里,选出下一轮要继续探索的B 个 kernels,得到 C_{i+1}
所以 Algorithm 1 本质上就是:
候选 kernel → 生成多个优化计划 → 执行并 profile → 更新经验库 → 保留最值得继续探索的候选。
每轮搜索规模大概就是:B×N×K个新 kernel 版本。
这样做的意义是:
- 避免只押注单一路径
- 同时探索不同优化方向
- 即使某个 plan 写坏了、报错了、或者收益很差,也不至于整轮失败
这其实很像编译器 autotuning + program search,只是这里把“提优化策略”和“写代码”交给了 LLM agents。
memory 是怎么整理出来的
作者不是把所有尝试都存下来,而是要做 curation(筛选和提炼)。

它的输入是:
- K:本轮生成并测过性能的一堆 kernels
- E_{i-1}:上一轮已有 memory
然后做几步:
(1) 按“candidate + 对应的 plan”分组
也就是:同一个原始 kernel、同一个优化思路下产生的尝试归成一组。
(2) 找正样本和负样本
- 如果某组里最快版本相比原候选提升超过阈值 t_{pos},就记为 positive rewrite
- 如果某组里最好版本仍然明显更差,低于 1/t_{neg},就记为 negative rewrite
(3) summarizer 把 slow-fast pair 提炼成经验项
经验项不只是“这个版本更快”,而是会总结出:
- 关键代码改动
- 一般化的优化 insight
- 可迁移的模式描述
(4) 经验库容量受 ExpN 限制
新的经验项加到前面,旧的保留到容量上限,超了就丢掉更老的。
所以 optimization memory 本质上是一个有容量上限的经验队列。
- TopK:每轮最多往 memory 里加多少条新经验
- ExpN:memory 总容量上限
- t_{pos}:判定“这是成功优化”的速度提升门槛
- t_{neg}:判定“这是失败优化”的退化门槛
Figure 2

Figure 2 是一个非常典型的 “从一次具体优化中抽取通用经验” 的例子。
它展示了四块内容:
(1) Plan
planner 先提出一个优化计划:
把 LHS transpose 移出 reduction loop。
原因是 profile 发现:
- HFU 很低
- memory writes 很高
- 同一块 LHS 数据被重复转置了很多次
说明这是 memory-bound 的低效写法。
(2) Candidate kernel
这是当前待优化版本。
问题是:在 i1 循环内部,v7 -> v8 -> v9 这串转置/复制反复执行,存在重复计算。
(3) Optimized kernel
优化后把这部分提到循环外,先算一次,再让后面循环复用。
这就是典型的 loop invariant code motion。
(4) Experience item
最关键的不是“这一次变快了”,而是总结出一个可复用的经验:
如果某段 LHS matrix transposition 对内层循环索引不变,那么就可以外提到循环外,并放到 global buffer 复用,从而减少重复计算和内存带宽消耗。
这条经验以后就能喂给 planner,帮助它在别的 kernel 上也想到类似优化。
三、测评系统
作者不只做了一个 agent 系统,还专门搭了一个评测体系,来回答两个问题:
- 这个系统到底能不能把真实 kernel 优化好?
- 优化后的 kernel,离硬件“理论上最好能跑多快”还有多远?
NKIBench
NKIBench 是作者专门构造的一个 benchmark。
它收集的是 从真实 LLM workload 里抽出来的 Trainium NKI kernels,用来评测 AccelOpt。
论文这里说,NKIBench 一共选了 14 个代表性的 NKI kernels,覆盖不同复杂度和不同类型的任务。
这 14 个 kernel 覆盖了哪些东西
作者强调它覆盖范围很宽,包括:
- 单算子:例如 Matmul、BatchMatmul
- 多算子链:例如 Matmul + others、LoRA
- 更大的 building block:例如 Group Query Attention、Mamba block
而且既有 inference kernels,也有 training kernels。
这点很重要,因为说明它不是只针对某一个很窄的 case 做优化。
Figure 3
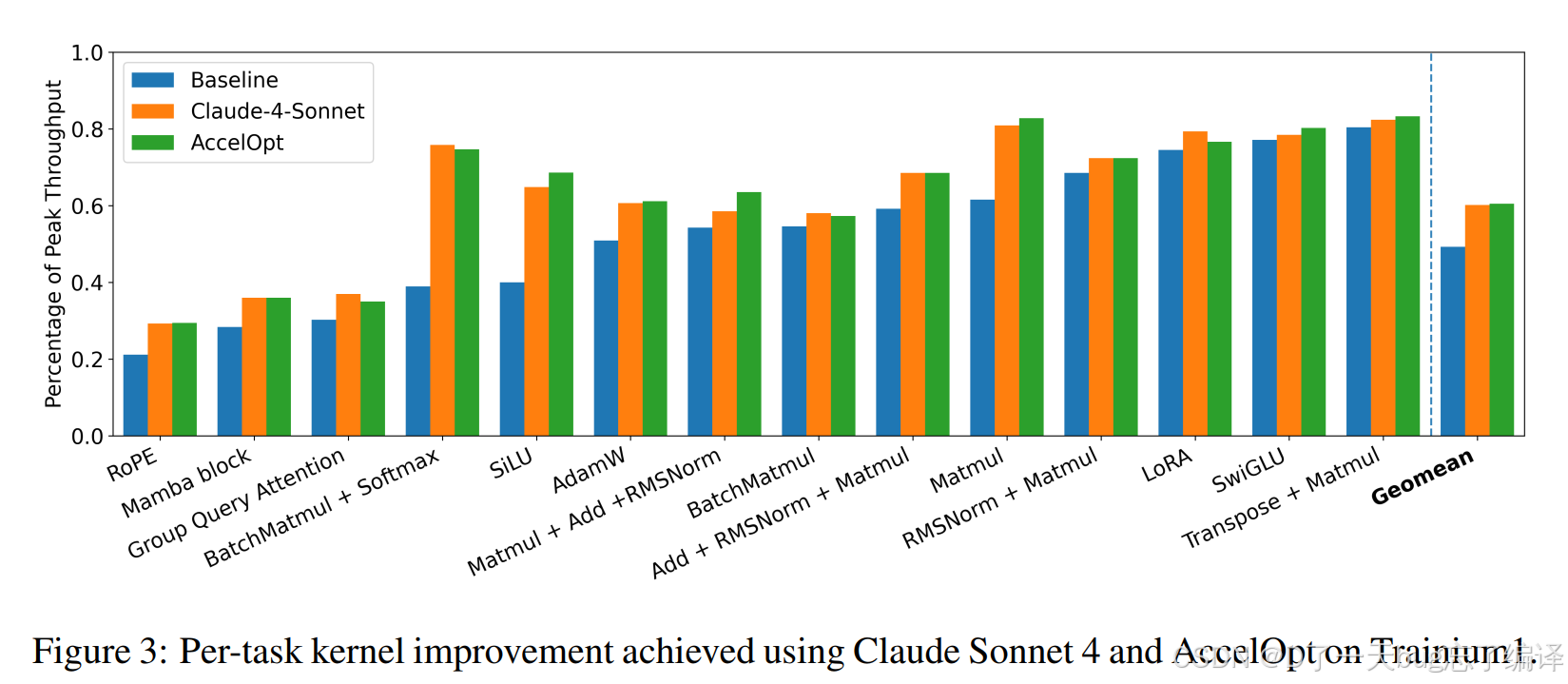
这张图是在比较 Baseline / Claude-4-Sonnet / AccelOpt 在 Trainium 1 上每个任务的表现。纵轴是:
Percentage of Peak Throughput
也就是:实际达到的吞吐 / 估计的硬件峰值吞吐。
从图上能直接看出两个信息:
第一,绝大多数任务上,绿色都明显高于蓝色。
说明 AccelOpt 相比初始 kernel 基本都有提升。
第二,绿色和橙色整体非常接近。
说明用开源模型驱动的 AccelOpt,效果大体能追平 Claude Sonnet 4。论文后面总结成:
在 Trainium 1 上平均从 49% 提升到 61%,在 Trainium 2 上从 45% 提升到 59%。
Overall Performance
这里先说明了实验设置:
- Claude Sonnet 4 的对比方式是 repeated sampling,也就是对同一个 prompt 多次采样
- AccelOpt 用的是一个 agent 系统:Qwen3-Coder-480B 做 executor,gpt-oss-120b 做其他 agents
- 关键参数包括 tpos=1.04 t_{neg}=1.15, TopK=8, ExpN=16, B=6, N=12, T=16。
核心结果是(fig3 & tab3):
- 在 Trainium 1 上,平均从 49% peak throughput 提升到 61%
- 在 Trainium 2 上,从 45% 提升到 59%
- 效果基本匹配 Claude Sonnet 4
- 但成本 便宜 26×。
2. 实验基础设施
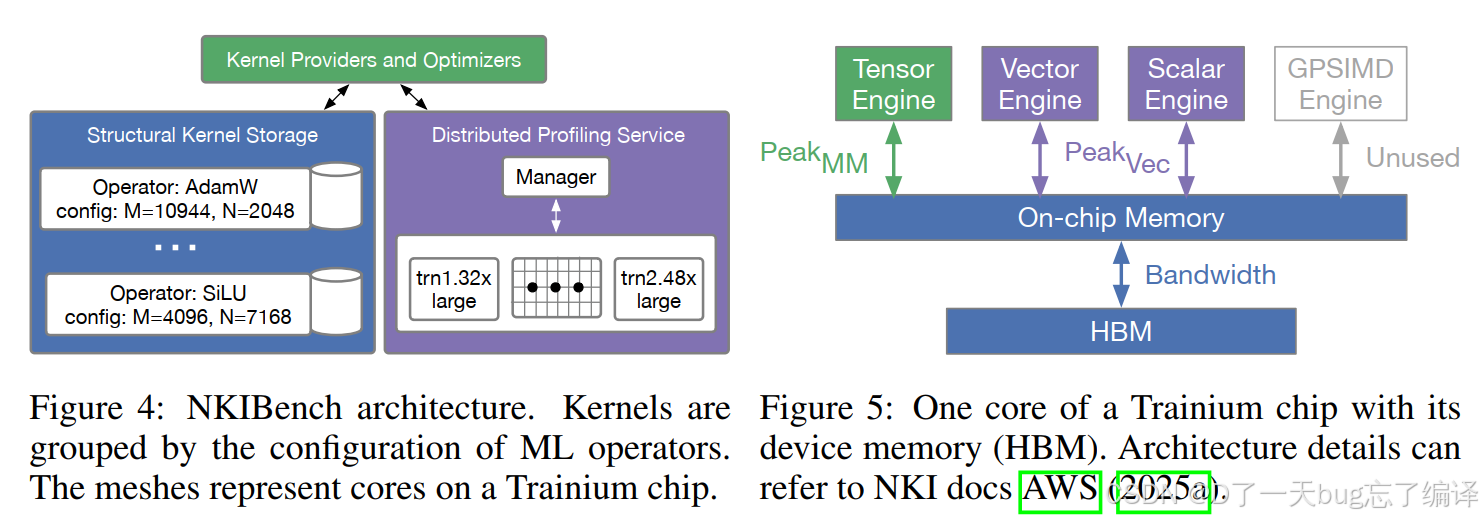
Figure 4:NKIBench architecture
- 左边是 structural kernel storage,按算子和配置存 kernel
- 右边是 distributed profiling service
- 中间有 manager,把 profiling 任务分发到不同 Trainium 实例上去跑。
这说明作者不是手工单点测几个 case,而是做了一个能批量执行、批量 profile 的工程化系统。
Figure 5:Trainium 单核抽象
- 一个核里有 tensor engine
- vector engine
- scalar engine
- 通过片上内存和 HBM 交互。
26× cheaper

这张图横轴是 cost (USD),纵轴是 percentage of peak throughput。
比较的是:
- AccelOpt
- Claude Sonnet 4 repeated sampling
- 初始 kernels baseline。
图里的关键点:
- 在 Trainium 1,AccelOpt 到了 0.606
- Claude Sonnet 4 也大约是 0.602
- 在 Trainium 2,AccelOpt 达到 0.589
- Claude Sonnet 4 是 0.573 左右。
也就是说,性能非常接近,甚至在图上某些点还略高。
但图上标了一个大箭头:26x cheaper。
beam search 和 memory
纵轴是 best speedup 的几何平均值,横轴是 cost。比较四种策略:
- Search + Memory, B=6, N=12
- Search + Memory, B=4, N=8
- Search only, B=6, N=12
- Search only, B=4, N=8
- 以及 Repeated Sampling。
图里给了两个非常关键的结论:
第一,beam search 明显优于 repeated sampling。
论文明确写了:
beam search 胜过 repeated sampling,因为它每一轮都建立在之前最好的 kernel 上继续优化,而不是每次都从头随机采样。
第二,Search + Memory 比 Search only 更省钱。
- search-only 通常要跑满 T=16 轮
- Search + Memory 可以在 13 轮左右 达到类似 speedup
- 节省 16%–17% cost。
Optimization Case Study

论文这里重点拿了一个 BatchMatmul + Softmax 的例子,也就是 Figure 7。
Figure 7(a):baseline 的问题
- 原始 kernel 里,tiles
v和p要跨两个 loops 存活 - 这导致了 memory spilling。
指标上看:
- latency = 12.0 ms
- off-chip / spill = 2.62 GB / 1.5 GB
- vector engine utilization = 46%。
这说明原始版本有明显的片外流量和 spill 问题。
Figure 7(b):第一步优化
LLM agents 先想到一个办法:
- 通过 recompute v′ 去去掉 spilling。
这样做的效果:
- spill 去掉了
- off-chip 变成 1.11 GB / 0 GB
- latency 从 12.0 ms 降到 8.2 ms
- vector engine utilization 提高到 57%。
但这个版本也有代价:
它在 exp 前多做了一次 matrix multiplication。
Figure 7(c):第二步更全局的优化
接着 agents 继续推理,意识到:
- matmul 在 tensor engine 上跑
- exp 在 vector engine 上跑
- 单纯用 recomputation 去掉 spill 虽然有效,但引入了额外 matmul,还不够好。
于是它进一步把多余的 recomputation 和额外的 m loop 去掉,得到更好的全局结构。结果是:
- latency 进一步降到 6.4 ms
- off-chip / spill 仍然是 1.11 GB / 0 GB
- vector engine utilization 提高到 84%。
这一段很重要,因为它说明:
AccelOpt 不是只会做 peephole optimization,而是能做跨阶段、跨循环的 non-local / global optimization。
Comparison with human experts
这部分是非常亮眼的结果。
作者挑了两个有人类优化参考版本的 kernel:Mamba 和 RoPE。
(1) Mamba
- 官方人类教程给了三个 progressively faster 版本
- 分别到 28.4% / 30.1% / 52.7% of peak throughput
- AccelOpt 从同样 baseline 28.4% 出发,做到 54.6%
- 也就是 1.04× best expert result。
而且论文还说:
它得到的 kernel loop order 跟最好的人类版本还不一样。
这说明它不是简单复现已有套路,而是真的找到了一条不同的高性能实现路径。
(2) RoPE
- 人类参考版本起点是 21.1% of peak
- AccelOpt 提升到 29.6%
- 相当于 1.4× human reference。
Ablation Study
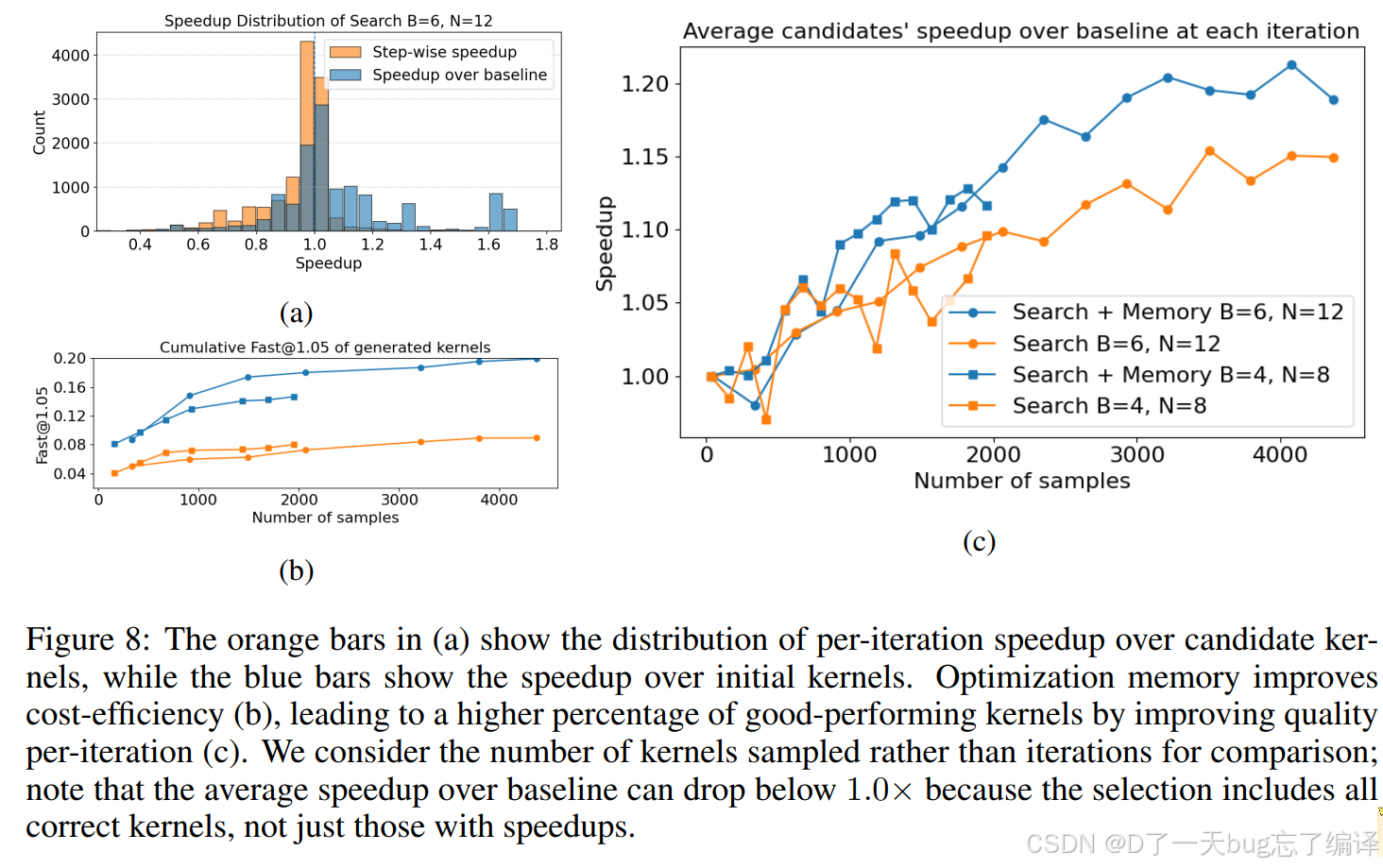
Figure 8(a):速度分布
论文说:
- 橙色柱子:每一轮相对 candidate kernel 的 speedup
- 蓝色柱子:相对 initial kernel 的 speedup。
作者的解读是:
- 橙色很多聚在 1.0× 附近
- 蓝色中有更多明显超过 1.0× 的情况。
这说明一件事:
单轮看,每一步未必都暴涨;但 beam search 持续建立在前面最优 kernel 上,会形成累计增益。
这就是“迭代进化”比“独立采样”更强的地方。
Figure 8(b):Fast@p
这里用的是 cumulative Fast@p。论文定义为:
到当前为止生成的所有 kernels 中,正确且 speedup 超过阈值 ppp 的比例。
你可以把它理解成:
这个系统“产出高质量 kernel”的命中率。
论文结论是:
optimization memory 会提高这个指标,也就是:
memory 让系统更容易生成“快 kernel”。
Figure 8(c):平均候选质量
这张图画的是:
- 每轮 candidate kernels 相对 baseline 的平均 speedup。
论文说:
- Search + Memory 的曲线整体更高
- 说明 memory 能产生更强的 candidate pool
- 进而让最终 best speedup 更高,或以更少轮数达到相近效果。
四、附录
A.1 Profiling Service Details
这里讲的是 AccelOpt 背后的 distributed profiling service。
核心思想是:
AccelOpt 每轮会生成很多 kernel,需要并行 profile,所以它同时利用了两层并行性:
- task-level parallelism:不同问题实例彼此独立
- sample-level parallelism:对同一个问题,一轮里最多可以同时 profile B×N×K 个 kernels。
工程上,它把多台 Trainium 机器通过共享网络文件系统连起来,再由一个 centralized manager 统一分发 profiling 请求和回收结果。为了缓解机器长时间运行后的性能漂移,作者还会定期轮换 core。
correctness checking
kernel 优化很容易“跑得快但结果错”。
作者的做法是:
- 用多个随机种子生成输入做检查
- 以 CPU 全精度参考实现 作为 ground truth
- 正确性判据是
∥output−cpuref∥<tol×∥cpuref∥,其中每个任务的tol单独设定。
为什么不用 GPU/别的 accelerator 当参考?
论文给出的理由是:像 exponential 这类特殊函数没有统一 IEEE 标准,而 CPU 全精度实现虽然慢,但保真度更高,通常被接受为 ground truth。
这个设计其实挺合理:
对于 kernel optimization,“快”必须建立在“语义不变”之上,否则优化就没有意义。
性能
附录里说得很具体:
- 只测 execution time
- 不包含 compilation latency
- 每轮有 2 次 warmup
- 再做 10 次 repeated runs
- 为了压制波动,还会做多轮,然后选相对差异最小、或第一个落入预设阈值的结果。
此外,作者还设了平台相关的稳定性门限:
- Trainium 1:性能差异阈值 1%
- Trainium 2:性能差异阈值 4%。
这说明论文对性能测量不是“一次跑完就算”,而是比较注意波动控制和可重复性。
A.2 Cost Analysis
这一节是对 TopK / ExpN / 模型选择 做成本收益分析。
先说结论,论文写得非常明确:
增大 memory capacity(ExpN)比增大 memory update eagerness(TopK)更划算。
原因是:
- ExpN 大,memory 能保留更多历史经验
- TopK 大,每轮能塞进更多当前经验
两者都可能有用,但在相近成本下,作者发现增大 ExpN 带来的 speedup 提升更明显,所以主实验里采用了 TopK=8, ExpN=16。
这和正文里的结论是一致的:
memory 主要改善的是 cost-efficiency,而不是把最好速度上限猛拉高。
不同模型和窗口参数的 trade-off
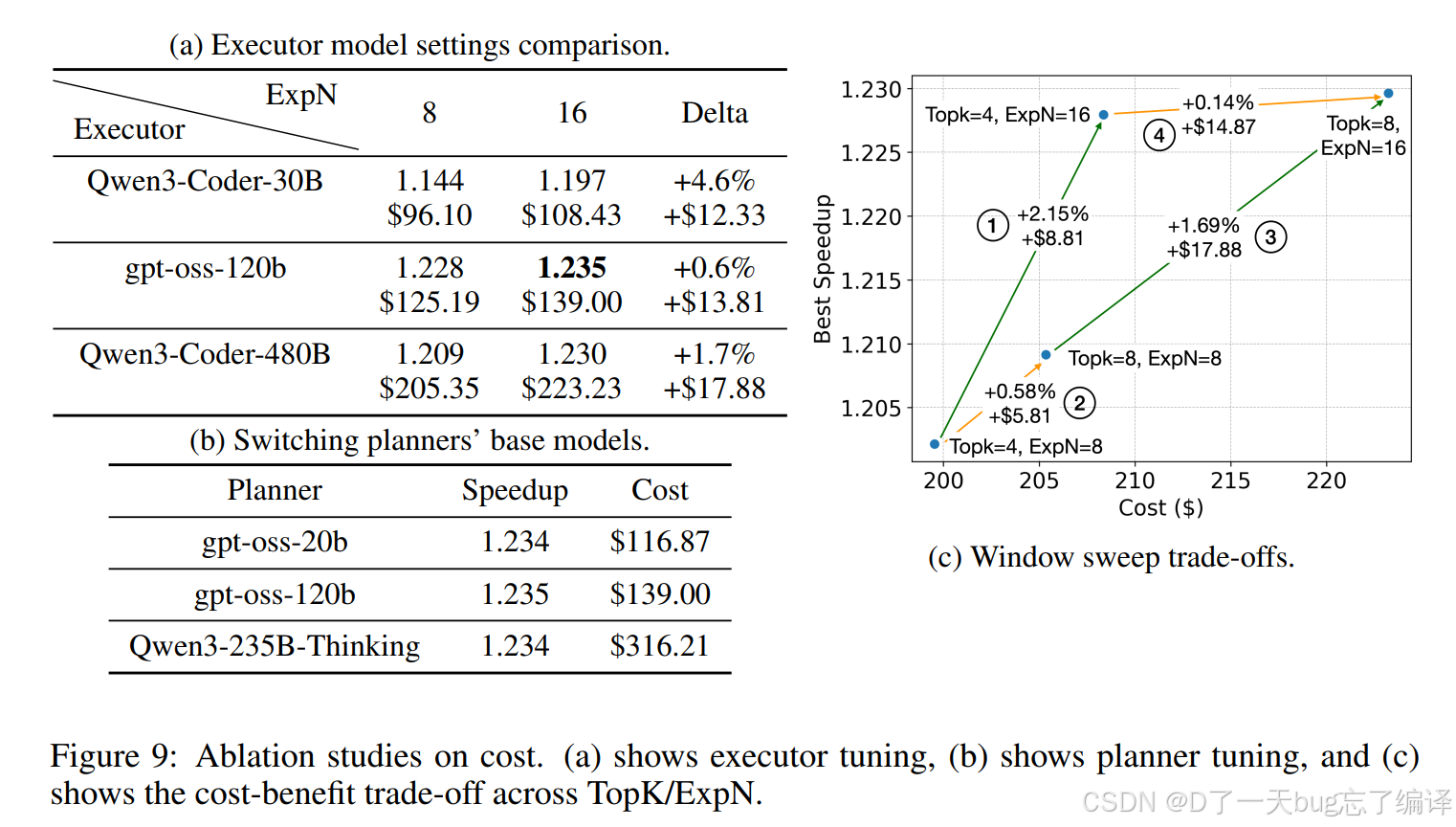
Figure 9 分三块:
(1) Executor model settings comparison
这里比较的是不同 executor 模型在 ExpN 从 8 增加到 16 时,speedup 和 cost 怎么变化。结果是:
- Qwen3-Coder-30B:speedup 从 1.144 到 1.197,增幅 4.6%,额外成本 $12.33
- gpt-oss-120b:从 1.228 到 1.235,只增 0.6%,额外成本 $13.81
- Qwen3-Coder-480B:从 1.209 到 1.230,增 1.7%,额外成本 $17.88。
这说明:
增加 memory 容量的收益,跟底层模型能力有关。
小一点的 coder 模型更“吃 memory”,强模型本身已经比较强,再喂更多历史经验,边际收益没那么大。
(2) Switching planners’ base models
这里换 planner,发现速度差别其实很小:
- gpt-oss-20b:1.234
- gpt-oss-120b:1.235
- Qwen3-235B-Thinking:1.234。
论文据此给出的结论是:
后续性能提升,更该优先增强 executor,而不是 planner。
(3) Window sweep trade-offs
这一小图是在扫 TopK / ExpN 的组合。
作者用它来说明:在类似成本增长下,增 ExpN 的收益普遍比增 TopK 更明显。
A.3 Peephole Optimization
这部分补的是“正文没展开的局部优化案例”。
论文说 AccelOpt 能做一些典型的 peephole optimization,例如:
- 代数化简
- 硬件级 intrinsic fusion
- 识别并替换常见 instruction patterns。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)