
LLM--RAG入门到实践
·
文章目录
看了b站视频,感觉还是得看论文才能看的比较懂。
论文精读
论文笔记这次记录在xmind中。
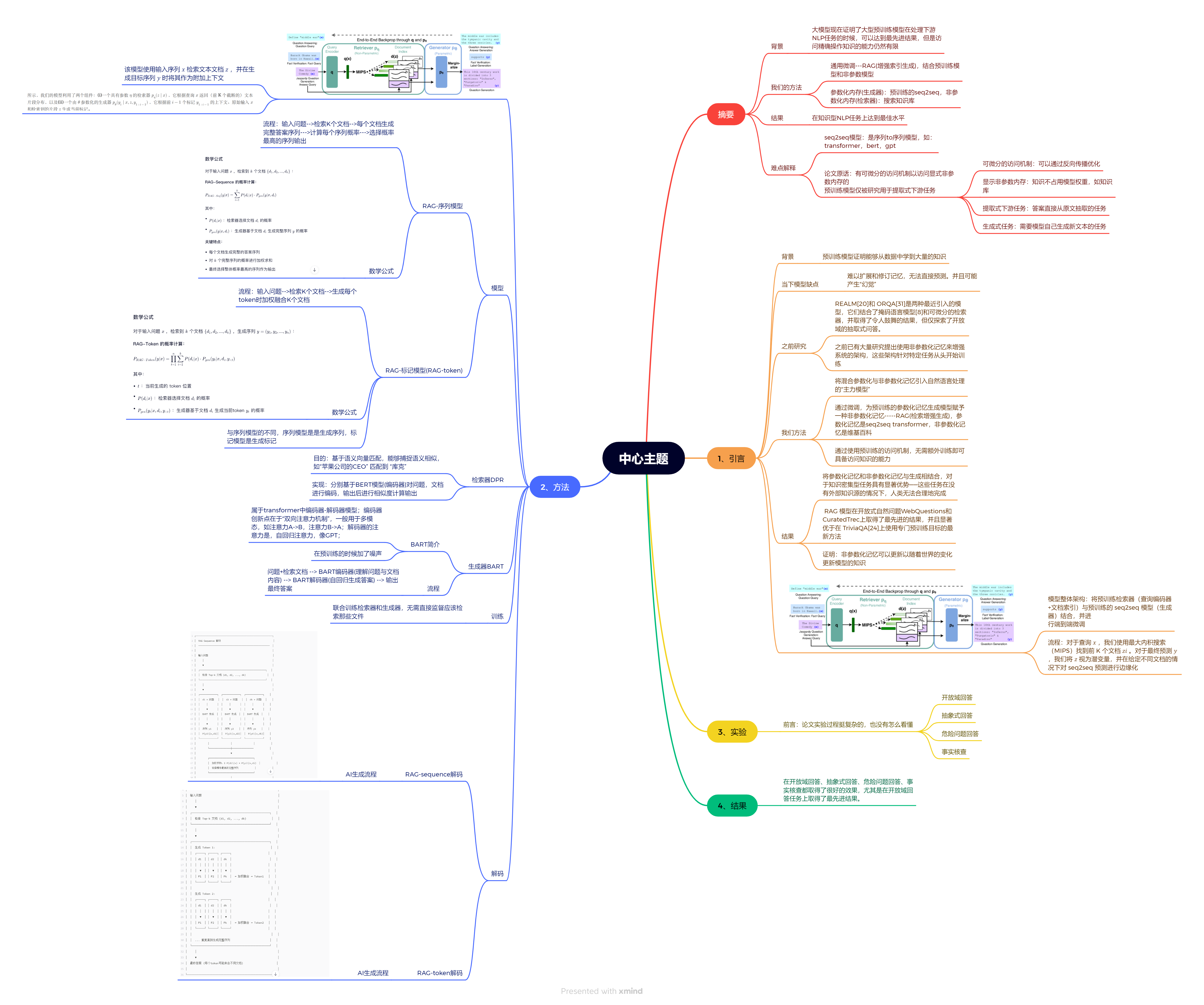
总的来说,RAG主要贡献是
- 统一框架,将检索与生产一起整合
- 知识更新,不需要重新预训练就可以更新知识
- 可解释性,可以追溯来源
举例
对于大模型来说,如果问他的问题它知道,则直接生成,不知道则先查资料在回答。
RAG流程解析
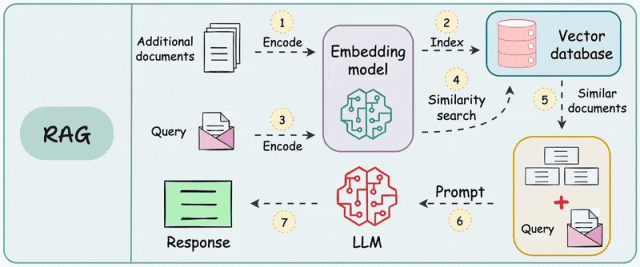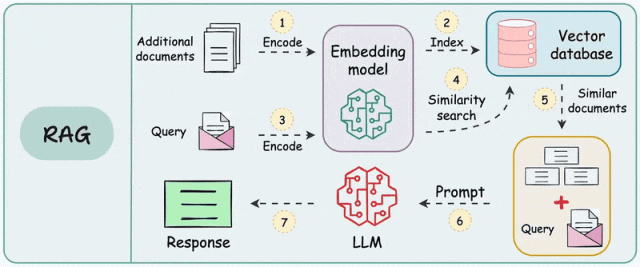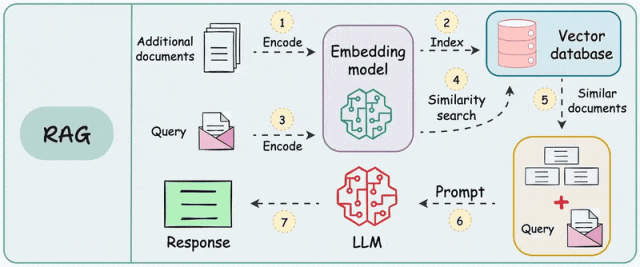
- 文本分块:按固定长度分块、按语义单元分块
- 向量化:使用Embedding模型,将每个分块都转化为高维向量
- 索引构建:使用向量数据库存储向量
- 检索:将用户问题转化为与文档向量通空间的查询向量
- 重排序:优化检索结果质量,排除无关或者过时信息
- 提示词工程:将筛选后的文档分块与用户问题进行拼接,完成提示词构建,引导LLM生成回答
Qwen + RAG实战入门
听再多,不如做一个RAG项目
本地部署Qwen
本地部署教程,链接:本地部署
Qwen + RAG
准备
- 读取PDF文件
import fitz
创建API
| API | 说明 | 示例 |
|---|---|---|
fitz.open() |
打开 PDF 文件 | doc = fitz.open("file.pdf") |
doc.close() |
关闭文档 | doc.close() |
len(doc) |
获取总页数 | page_count = len(doc) |
doc[i] |
获取第 i 页 | page = doc[0] |
doc.save() |
保存修改 | doc.save("output.pdf") |
Qwen + RAG实战
导入库
import fitz
import numpy as np
import json
import requests
读入私有数据
数据为pdf文档
def read_pdf(path):
data = fitz.open(path)
texts = "" # 存储文档所有数据
# 遍历每一页,读取每一页文字
for page_num in range(len(data)):
page = data[page_num] # 获取一页数据
text = page.get_text("text") # 获取每一页文字
texts += text # 存储文字
# 关闭
data.close()
return texts
path = "./data/AI_Information.pdf"
pdf_data = read_pdf(path)
文本分块
在RAG中,查询文本后需要分块 --> Embedding嵌入
# 文本分块,这里按找固定长度
def chunk_text(texts, n, overlap):
'''
texts: 文本
n: 每个文本块最大的长度
overlap: 相邻两个文本块重叠字符数, 这个有点像时间序列中构建时间序列数据
'''
chunks = []
for i in range(0, len(texts), n - overlap):
chunk = texts[i : i + n]
chunks.append(chunk)
return chunks
# 分割
text_chunks = chunk_text(pdf_data, 1000, 200)
print(len(text_chunks))
print("------------------------")
print(text_chunks[0])
42
------------------------
Understanding Artificial Intelligence
Chapter 1: Introduction to Artificial Intelligence
Artificial intelligence (AI) refers to the ability of a digital computer or computer-controlled robot
to perform tasks commonly associated with intelligent beings. The term is frequently applied to
the project of developing systems endowed with the intellectual processes characteristic of
humans, such as the ability to reason, discover meaning, generalize, or learn from past
experience. Over the past few decades, advancements in computing power and data availability
have significantly accelerated the development and deployment of AI.
Historical Context
The idea of artificial intelligence has existed for centuries, often depicted in myths and fiction.
However, the formal field of AI research began in the mid-20th century. The Dartmouth Workshop
in 1956 is widely considered the birthplace of AI. Early AI research focused on problem-solving
and symbolic methods. The 1980s saw a rise in exp
文本Embedding嵌入
# 调用本地部署的大模型
def create_embedding(text):
reponse = requests.post(
"http://localhost:11434/api/embeddings",
json={
"model": "nomic-embed-text",
"prompt": text
}
)
# 检查是否异常
reponse.raise_for_status()
# 返回embedding嵌入
return reponse.json()["embedding"]
# 每一个文本分块都表示为一个embedding
chunks_embeddings = [create_embedding(text) for text in text_chunks]
# 检查,是否成功embedding嵌入
chunks_embeddings[1][:5]
[0.4595257639884949,
1.2543978691101074,
-3.3199832439422607,
-0.43832844495773315,
0.8358823657035828]
余弦相识度
def cos_similarity(vec1, vec2):
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
定于语义搜索
# 查找问题与文档那几个相似度最高
def semantic_search(query, texts, embeddings, k=5):
'''
query: 查询问题
texts: text_chunks
embeddings: chunks_embeddings
k: 返回与查询最相似的前5个
'''
# 查询embedding
query_embedding = np.array(create_embedding(query))
similarity_scores = [] # 文档内容与查询相似度
for i, chunk_embedding in enumerate(embeddings):
score = cos_similarity(chunk_embedding, query_embedding)
similarity_scores.append((i, score)) # 保存 (索引,相似度)
# 排序
similarity_scores.sort(key=lambda x: x[1], reverse=True)
# 返回前k个索引
index = [i for i, _ in similarity_scores[:k]]
# 返回
return [texts[i] for i in index]
Qwen3 + Rag实现
# ollama api
def generate_response(system_prompt, user_message):
'''
system_prompt: 系统提示词
user_message: 用户信息
'''
# 发生给本地模型
response = requests.post(
"http://localhost:11434/api/chat",
json={ # 注意格式
"model": "qwen3:0.6b",
"messages": [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_message}
],
"stream": False
}
)
# 错误断言
response.raise_for_status()
return response.json()["message"]["content"]
# RAG
def rag_query(query, text_chunks, embeddings):
'''
query: 查询问题
text_chunks: 文本分块
embeddings: 分块嵌入
'''
top_chunks = semantic_search(query, text_chunks, embeddings, k=3) # 寻找与问题最相似的文档
# 定义提示词
system_prompt = (
"你是一个AI助手"
"严格根据给定的上下文进行回答。"
"如果无法直接从提供的上下文中得出答案,请回复:"
"【对不起WY,我没有足够的信息来回答这个问题。】"
)
user_prompt = ""
for i, chunk in enumerate(top_chunks, 1): # “先查答案”
user_prompt += f"Context {i}:\n{chunk}\n{'='*30}\n"
user_prompt += f"\nQuestion: {query}"
# 获取回答
answer = generate_response(system_prompt, user_prompt)
return answer
# 回答
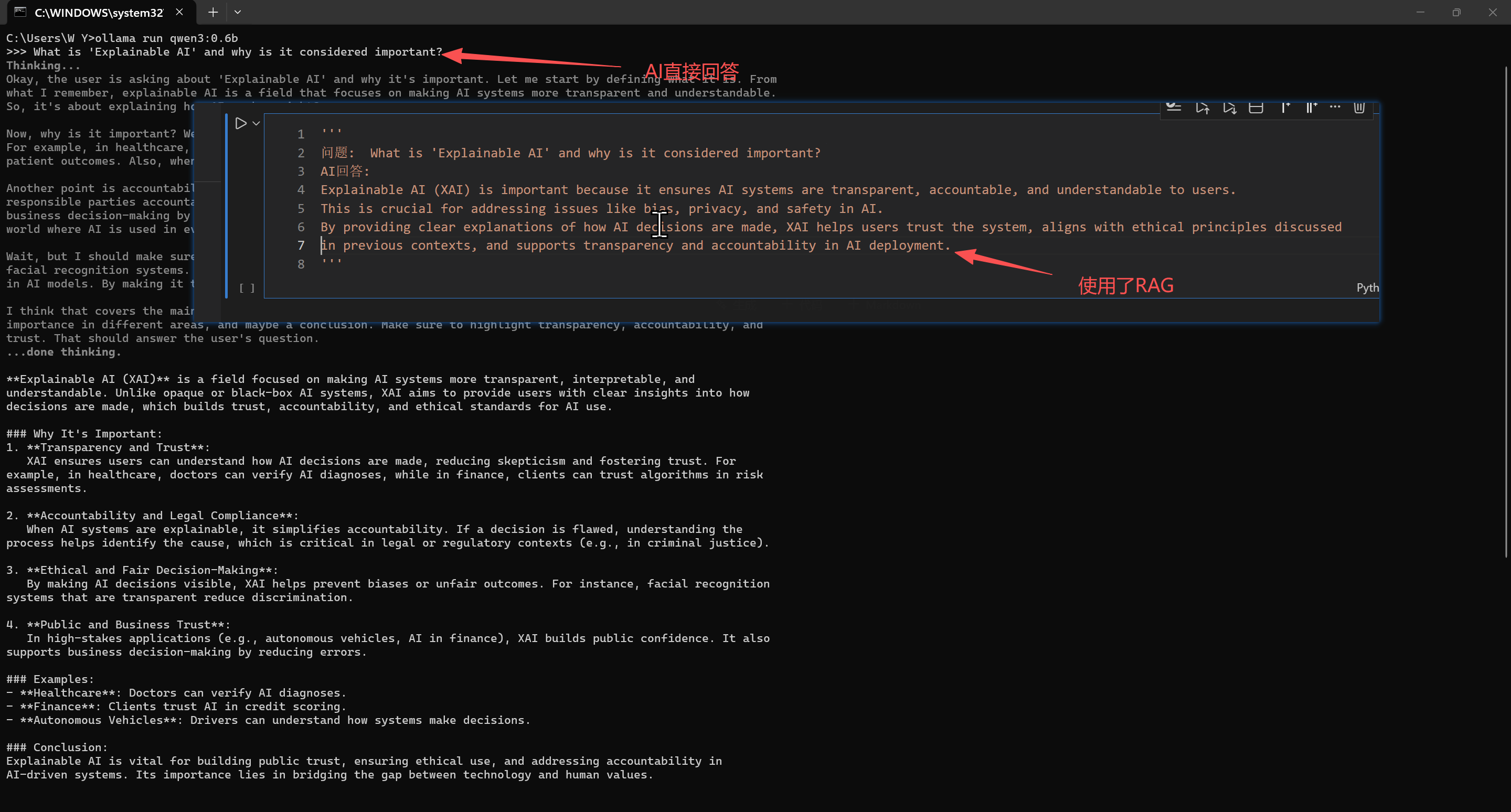
query="What is 'Explainable AI' and why is it considered important?"
answer = rag_query(query, text_chunks, chunks_embeddings)
print("问题: ", query)
print("AI回答: ")
print(answer)
问题: What is 'Explainable AI' and why is it considered important?
AI回答:
Explainable AI (XAI) is important because it ensures AI systems are transparent, accountable, and understandable to users.
This is crucial for addressing issues like bias, privacy, and safety in AI.
By providing clear explanations of how AI decisions are made, XAI helps users trust the system, aligns with ethical principles discussed
in previous contexts, and supports transparency and accountability in AI deployment.
**<font style="color:#DF2A3F;">注意</font>**
qwen3:0.6b模型太小,有时候效果不明显,如:让模型用中文回答,他可能理解不了。
用RAG和直接用LLM回答效果

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)