
LLM--LLama简介
·
背景:Mate发布的大模型
LLama-1
2023年2月发布
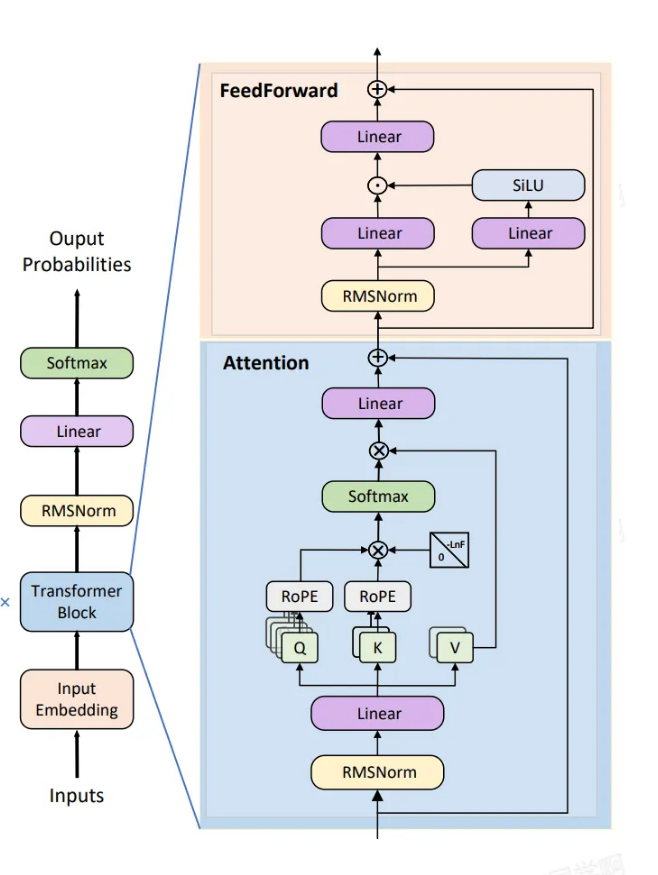
简介:采用Transformer解码器架构,且采用自回归的方式进行文本生成。
模型训练:采用多个领域的大规模数据进行预训练。
特点技术:
- RMSNorm归一化
RMSNorm归一化,也称为“均方根归一化”,其数学原理如下: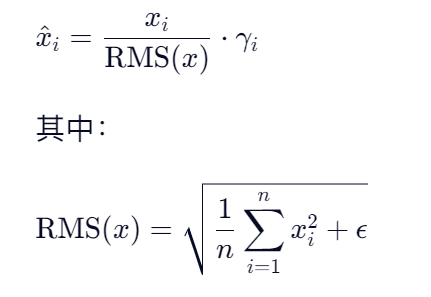
注意两个特别参数:

- SwiGLU激活函数
这个激活函数比较复杂,数学原理:
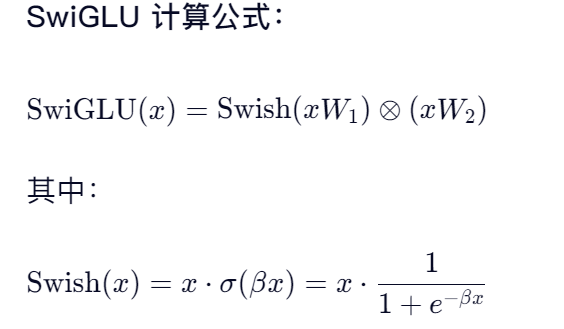
这里相当于在Swish(自适应搜索)基础上进行优化,其中W1,W2都是可学习参数。
Swish在pytorch基础系列中算子系列有讲解。
- 旋转位置编码
用相对位置表示绝对位置。
这个在大模型基础系列中基础知识中位置编码有讲。
性能:作为LLama系列的开山之作,性能表现也是优异的,在多个任务中超越GPT3
LLama-2
在2023年7月发布,与LLama相隔3个月,说实话,很短,所以提示没有很大,更多是优化LLama1
- 训练数据,采用更有质量的数据,同时训练token扩展为2万亿个token。
- 上下文扩展,从2028扩展到4096,更好处理上下文语义。
- GQA优化多头注意力,这里重新比较大
GAQ是现在很常用的一种优化,主要在于优化Q,K,V内存,传统的Q,K,V是一一对应的,也就是说一个Q,对应一个K,一个V,但是GAQ是:
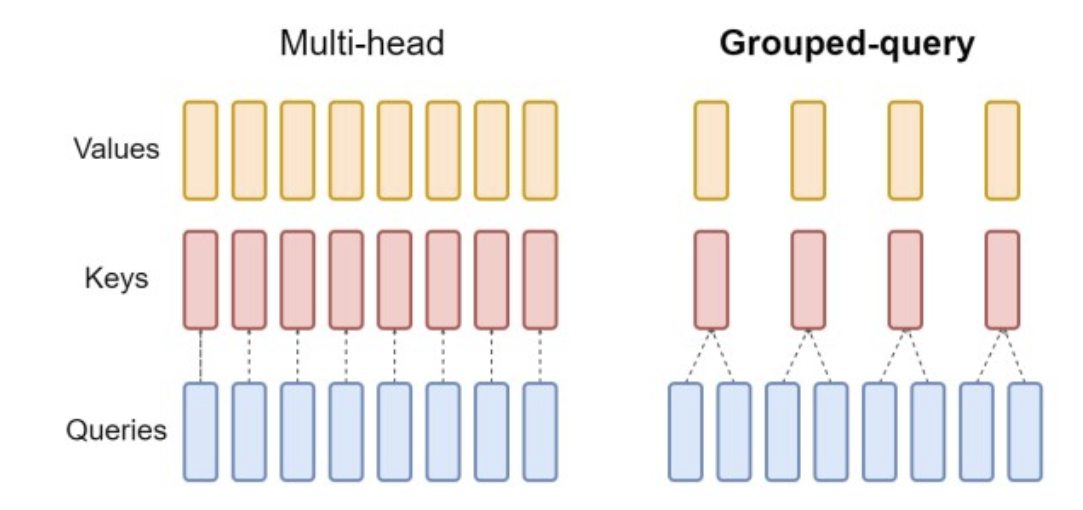
GQA使我们能够随着模型的增大而保持带宽和容量的相同比例减少,但是要注意,GQA只适用于解码器,不适用与编码器。
- 强化学习,这个是现在LLM核心的知识点之一,也是现在最前沿的知识点之一,但同时也是难度很大的知识点,这一部分小编现在还很弱,只知道强化学习是通过引入正负反馈得分对行为进行打分,目的是让总得分最大。
- 表现:能堪比GPT-3.5
LLama-3
在24年4月发布,我感觉这一版本有点像“暴力出奇迹了”。
- 结果,性能好于GPT-3.5
- 训练参数,比LLama-2大了7倍。
- 架构,依然采用LLama1的编码器架构,LLama2的GQA优化,但是采用了更高效的tokenization,扩大了词表大小,进一步扩大了上下文序列长度。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)