
LLM--GPT模型简介
文章目录
GPT-1:预训练与微调
GPT-1有openai在2018年发布的,基于transformer的大语言模型,在nlp领域有着重要影响,标志着“自监督预训练 + 有监督fine-tune”范式的重大突破。
自得监督模型,说白了就是用遮蔽自己一部分数据然后更具其他数据对遮蔽数据进预测。
严格概述:自监督学习(Self-Supervised Learning, SSL)是机器学习中一种重要的无需人工标注标签的学习范式,它通过从数据本身自动构造监督信号(即“伪标签”)来训练模型,从而学习通用、可迁移的表示。
设计思想
模式:“无监督预训练” + “有监督微调”相结合。
实现目标:在大规模的无标注文本数据上进行预训练,学习通用语言的语义,然后对少量带标签的数据进行预训练微调,使其能够适应特定任务。
模型结构
一句话:基于Transformer的**自回归模型,采用Transformer的解码器结构**。
🍔🍔从模型结构图来说,这个一个Transformer解码器的简化版(transformer在解码器中有两个多头注意力,“因果掩码注意力 + 交叉注意力”)。但是,这里一共12层,Transformer论文中,原始只有6层。具体结构还是三样:多头注意力、前馈神经网络、归一化与残差。
处理文本时候,GPT-1遵循流程:
- 输入编码:输入文本 --> 词向量 + 位置向量
- 多层编码:12层Transformer解码器,可以有效的不断提取文本的语义和语法信息。
- 输出与应用:更具输出的向量用在不同应用上。
训练过程
无监督预训练
目的:让模型学习到通用语言的规律,语义信息,能够根据前文预测下一个词。
实现:让模型大量的自我学习,通过随机“【mask】”词,让模型根据上下文进行预测遮蔽词的思想,不断地让模型进自我进化。
有监督微调
目的:让模型更好的应用于不同任务中。
实现:在预训练模型的基础上,运用少部分有标注数据对预训练模型进行微调,使其具有处理特定任务的能力。
参数量
GPT-1中参数量较小:1.17亿参数,但是为后面GPT模型奠定了基础。
GPT-2:规模扩展与零学习
特点
- 模型参数:约为15亿,远大于GPT-1的参数量
- 数据集:名为WebText的数据集,包含40G高质量的互联网文本
- 上下文处理能力:上下文窗口从GPT的512变为1024,具有更好的处理长文本能力。
- 初始化方法:考虑了深度模型残差的积累,将残差层的权重缩放因子变为
1/根号N - 归一化:改为输出子模块的后面
难点解析
- 上下文窗口(context window) 是指模型在一次前向传播中能够处理的最大 token 数量。
- **残差网络的缺点:**如果模型层数过多,如1000层,可能模型就会转向学习残差特征,而不是源数据本身,就会导致模型效果一直上不去,GPT2设置权重,很明显就是在弱化深层残差的效果。
- **层归一化:**pre-norm更容易训练,但是在最优模型下,post-norm效果最好,但是难以训练,现在大部分还是pre-norm
零样本学习
GPT-2一个创新点就是零样本学习**,零样本学习就是模型在没有经过任何训练的情况下,能够对新任务进预测和处理能力。这一点很明显的就会让人体会到“智能”。**
原因:在大规模预训练的情况下,学习到了丰富的语言、语义信息。
模型结构
基础结构:基于transformer解码器,这一点没有变过。
模型编码:还是一样,词嵌入向量 + 位置编码。
模型流程:编码 -> 多头注意力 -> 前馈神经网络 -> 输出
GPT-3:大模型与少样本学习
特点
模型规模:与GPT-2比,模型扩展n倍,参数量有1750亿。
训练数据:采用更加多元化、更大规模化数据进行训练。
模型结构:一样基于Transformer的Deocder,大体没有变过,但是提出了“稀疏注意力”:“sparse attention”。
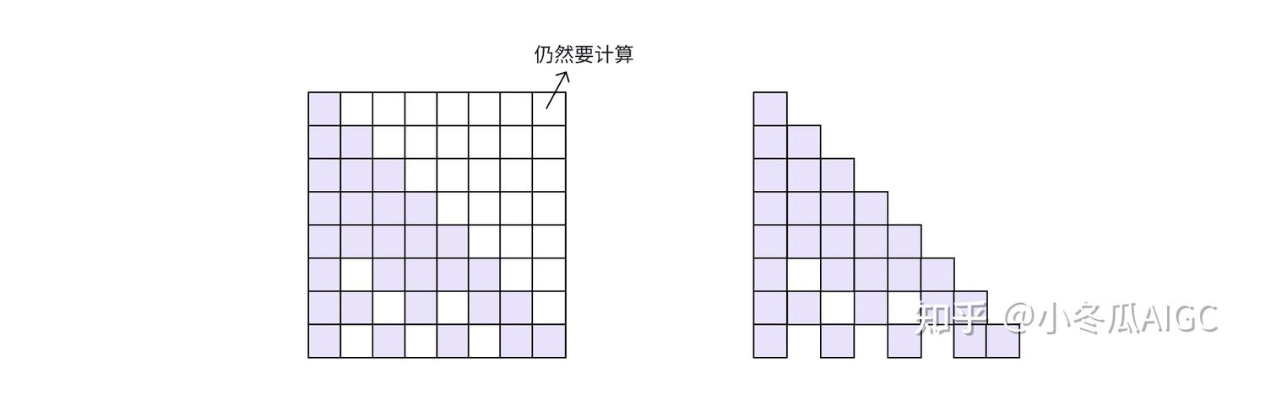
- 原来的transformer注意力属于**“Dense attention”**,每一个词需要和输入一句话其他所有词进行相关性计算,时间复杂度为O(n^2)
- 稀疏注意力**“Sparse attention”**,一 个词只需要和一句话一个子集合的词进行相关性计算,时间复杂度为O(nlogn)
- 稀疏注意力优点:
- 减少注意力计算复杂度,节约时间
- “局部性原理”:举例更近的关系更紧密,上下文关注更多,举例远的,上下文关注更小。
注意:
在GPU计算中,GPU不擅长做不规则计算,故“sparse attention”在计算的时候是“dense attention + mask”实现,但是真正用于模型训练数据变少了。参考知乎大佬
- 主推few-shot:GPT2采用零样本学习,GPT3拥有强大的零样本、少样本学习能力,但是GPT3主推少样本学习,效果很好,展现了很强大的泛化能力。
少样本学习:在预训练模型的基础上,采用少量数据样本进行再训练就可以得到很好效果的模型。
训练过程
数据:采用更大、更多元化数据,规模达4100亿标注数据,570GB数据量
优化器:Adam优化器
训练:采用并行计算提高效率。
少样本学习(Few-show learning)
GPT-3在少样本学习上取得了重大突破,在完形填空、句子补全、问答任务中取得了很好的效果,超过了之前的模型。
少样本学习概念:在预训练模型的基础上,用少量数据进行微调训练,就可以取得很好的效果。
从GPT-1 -> GPT-2 -> GPT-3来看,最大改变的就是训练数据,足以说明训练高质量的训练数据的重要性,同时也证明了,transformer的解码器在大规模的预训练下,可以学习到非常智能的语义理解能力。
GPT-4:多模态与能力飞跃
2023年ChatCPT4点燃了AI大模型热潮,一直到现在可以说LLM已经成为了算法工程师必学的知识点,真正让人们感觉到AI的力量的个人感觉就是GPT-4。
在23年初的时候,GPT4发布,互联网上流传一个概念:ai取代程序员;从听说到真正了解来看LLM技术来看,大模型其实就是一个计算机分支,一门领域,和之前C++、java后端一样,只不过智能了点,然后ai全面进入普通人的生活,还有很长的路需要走。
可惜的是GPT4没有发布具体模型架构,内容是什么,也不清楚,但是从使用来看,GPT4是一个强大的 多模型模型,是一个能让人们真正体会到“智能”而不是“智障”。
参考“K同学啊”总结可知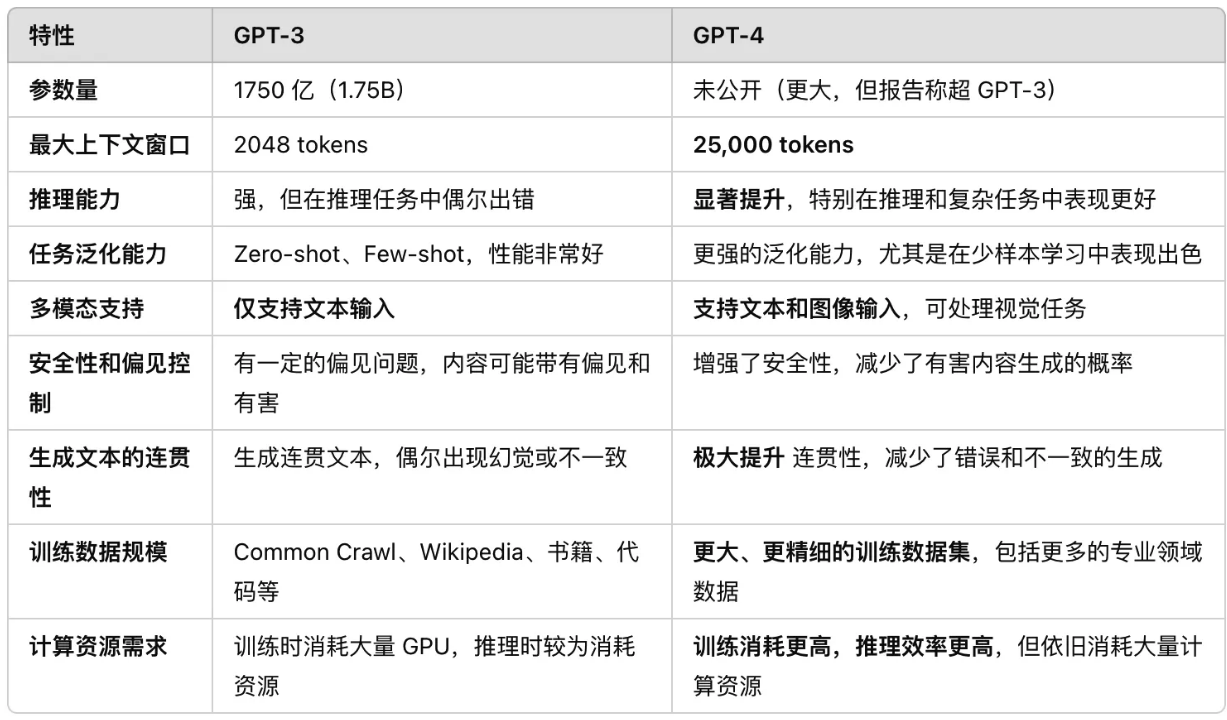

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 16
16 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)