
LazyLLM黑科技 | 同一个方法,结果却完全不同?问题竟然出在“谁调用”
问题:调用主体不明
在工程框架里,有一类很隐蔽但很常见的问题:同一个方法,看起来一样,结果却完全不同。
为什么?因为方法的语义,不只取决于“做了什么”,还取决于——谁在调用。
很多操作天然分两种:
- 类级操作:影响全局
- 实例级操作:只影响当前对象
但问题在于,这两种操作,写法往往是一样的,于是就很容易出现这种情况:本来只是想改当前对象,结果把全局改了;或者全局状态,被某个实例悄悄改掉。更麻烦的是,这类问题不会立刻报错,而是:
- 行为依赖调用顺序
- 别人复现不了
- bug很难定位
你看接口、看参数,都没问题。真正缺失的,是一件事:系统根本不知道是谁在调用这个方法。
一旦这种信息只能靠约定或文档维持,系统一复杂,这类问题就会逐渐演变成结构性风险。
难点:主体感知
针对这个问题,真正的难点,其实不在于实现两种行为,而在于如何在不增加接口复杂度的前提下,让系统能够感知调用主体。
常见的做法其实都有明显问题:
- 如果把全局操作和实例操作拆成两套方法,语义是清晰了,但接口会膨胀,命名负担变重,也更容易被误用
- 如果通过参数区分作用范围,比如传入 scope 或 global=True,本质上是把语义暴露到接口层,不够直观,也增加了使用成本
更关键的是,这些方案都没有解决核心问题:调用主体并不是方法参数,而是调用方式本身所隐含的信息。
从系统设计的角度看,理想状态应该是:
- 只暴露一个方法名
- 调用方式保持一致
- 行为分流由框架自动完成
这意味着一件很关键的事情:主体识别必须发生在调用之前,而不是参数解析之后。
也就是说,框架需要在方法被访问的那一刻,就已经知道当前是谁在调用,并据此决定后续执行路径。
问题的难点也正是在这里:如何在保持接口简洁的同时,让调用主体成为系统可感知的一等信息。
解决方案与代码示例
解决方案
为了解决调用主体不可感知的问题,LazyLLM 引入了 DynamicDescriptor,将调用主体识别前移到方法访问阶段,为方法引入了“调用者感知”的能力。
通过这一机制,同一个方法名在不同访问方式下,会自动绑定到不同的执行对象:
- 从类访问时,方法接收类本身,执行全局逻辑
- 从实例访问时,方法接收实例对象,执行局部逻辑
调用方式保持完全一致,区别只来自调用上下文本身。
下图展示的是 LazyLLM 中 Document 类的真实源代码:
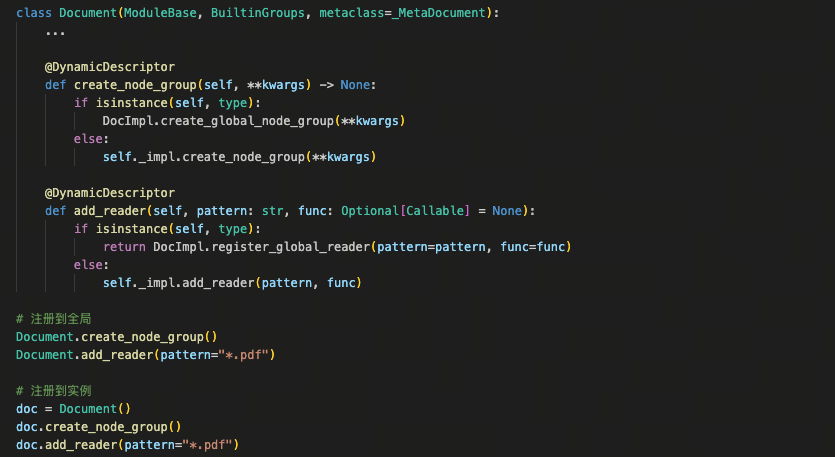
以 create_node_group 函数为例,在这两次调用中,create_node_group 并未通过参数区分作用范围,而是由框架在访问阶段自动判断调用主体:
- 使用 Document.create_node_group() 类调用 → 全局注册路径,把 node group 注册到全局注册表
- 使用 doc.create_node_group() 实例调用 → 实例内部路径,注册到当前 doc 实例内,不与其他实例共享
这种设计带来的效果是:
- 类级与实例级操作共享同一个接口
- 调用形式保持直觉一致
- 内部执行路径自动分流,无需额外参数或命名约定
对使用者而言,方法名只描述“做什么”,而不需要关心“在哪个层级生效”,作用范围由调用主体自然决定。
总而言之,DynamicDescriptor 让 LazyLLM 在不增加 API 数量的前提下,将“调用主体”这一关键信息纳入系统语义之中。
代码示例
除了上述真实代码示例之外,以下为一个简单的代码使用示例。
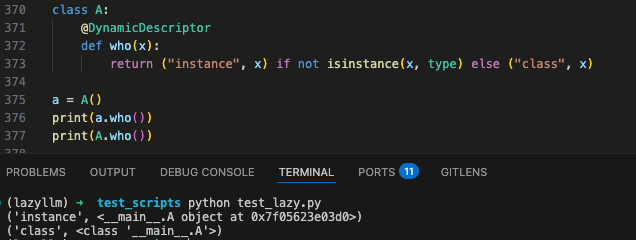
你可以为自定义的类函数使用 @DynamicDescriptor 装饰,可以看到,函数里根据传入的第一个参数是否为类对象判断返回不同的结果。调用 a.who() 时,会打印 instance 的结果;调用 A.who() 则会打印 class。
通过这个例子,你可以更直观的感受到 @DynamicDescriptor 在你的真实代码中能起到什么作用,可以充分利用它对调用者的感知能力,优化整体类和函数的设计。
技术剖析与源码细节
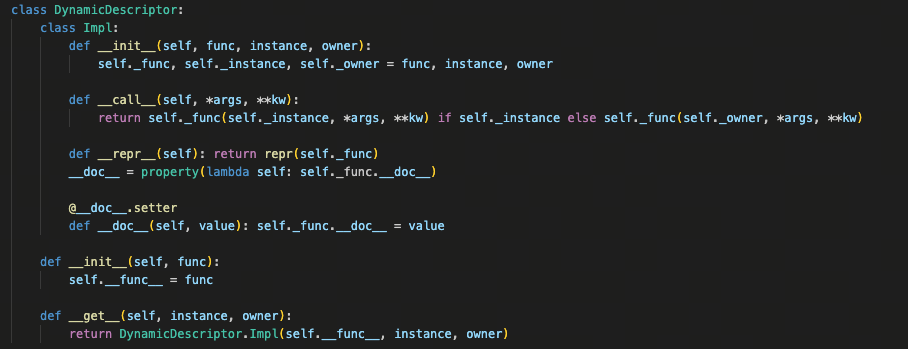
下图为 DynamicDescriptor 的类定义,接下来我们将针对源码进行深入的细节剖析。
访问阶段:捕获调用上下文
DynamicDescriptor 的第一步工作,发生在方法被访问时,而不是被调用时。
在 Python 中,当一个对象实现了_get_ ,它就会参与属性访问过程。无论是通过类访问还是实例访问,只要读取这个属性,解释器都会先进入_get_ 。

这里最关键的并不是返回了什么,而是 _get_拿到了什么:
instance
🗝️类访问时为 None
🗝️实例访问时为当前对象
owner
🗝️不论访问对象是谁,总是所属的类
也就是说,在真正调用函数之前,框架已经准确知道:这次访问是来自类,还是来自某个实例。
DynamicDescriptor 并不急着执行逻辑,而是将以下三者封装成一个中间对象:
- 原始函数
- 当前实例(如果存在)
- 所属类
这一步的本质,是捕获调用上下文,并把它保存下来,为后续执行做准备。
调用阶段:延迟绑定执行对象
真正的语义分流,发生在第二阶段:即这个中间对象被调用时。Impl 本身是一个可调用对象:

_call_函数里做了一件非常明确的事:
- 如果访问来自实例,就把实例作为第一个参数
- 如果访问来自类,就把类作为第一个参数
因此,被 DynamicDescriptor 修饰的方法,可以统一写成如下写法,而不需要提前决定它是实例方法还是类方法。

这种“延迟绑定”的设计有两个关键优势:
- 语义分流发生在系统内部,调用者不需要传额外参数,也不需要理解内部规则
- 调用方式天然携带语义,类调用与实例调用,本身就是最可靠的上下文信息
最终效果是:方法名只描述“做什么”,而“在哪个层级生效”,由调用主体自然决定。
总结
LazyLLM 这次做的事情,其实是把一个大家都遇到过、但一直处理得不太优雅的问题,给彻底解决了:同一个操作,在不同层级下语义不一样,但接口层又很难自然表达。以前一般要么靠大家自己约定,要么干脆拆两套接口,最后不是变复杂,就是容易被误用。
DynamicDescriptor 给了一种更顺的解法:不改接口,不加参数,而是直接让系统在执行前就知道“是谁在调用”。这样一来,类级和实例级的行为可以自然分开,但对使用者来说,写法完全不变。
更重要的是,这件事把一个原本需要人脑判断的东西,变成了系统自动处理的能力。接口依然很简单,但行为更可控,也更不容易出错。
本质上,这是在做一件很工程的事情:不让使用者去记规则,而是让系统把正确的行为变成默认。
欢迎升级体验 LazyLLM 最新版本,请大家去 github 上点一个免费的 star,支持一下~技术讨论欢迎关注 “LazyLLM” gzh!
LazyLLM 项目仓库链接🔗:

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)