
知识融合(Knowledge Fusion)是什么?多个知识源怎么整合?
知识融合(Knowledge Fusion)是什么?多个知识源怎么整合?
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
by @Laizhuocheng
一、简介
你有没有遇到过这种情况:在网上搜索一个人物,发现百度百科、维基百科、企业官网对他的介绍各不相同,有的写出生年份是1964年,有的写1965年,还有的只写"60年代"?或者在工作中,想整合多个部门的数据,发现A部门用"客户ID",B部门用"用户编号",C部门用"会员号",明明是同一个人却有三套不同的标识?
这些让人头疼的问题,就是知识融合要解决的。简单来说,知识融合就像一位超级翻译官兼调解员,它能听懂不同数据源的"方言",把它们整合成一本统一、准确、完整的"百科全书"。
二、什么是知识融合
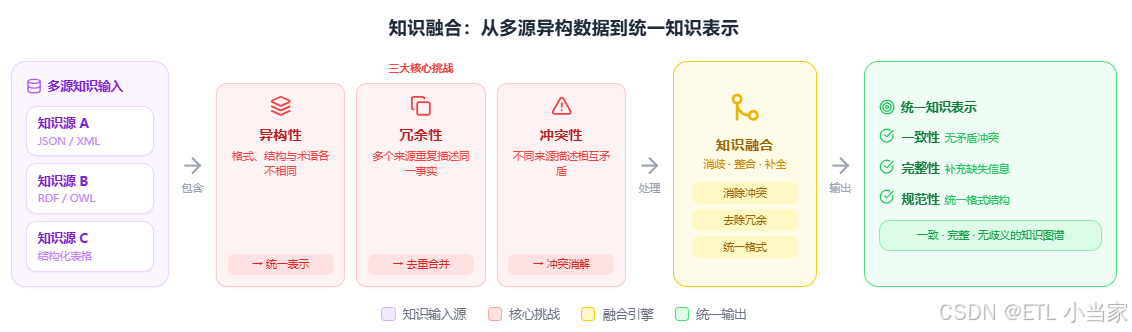
知识融合是指将来自多个异构知识源的信息进行统一整合,消除冲突、补充缺失信息,最终形成一致且完整的知识表示。
想象你在拼一幅巨大的拼图。每个知识源就像是一小堆拼图碎片,有的碎片边缘形状不同(异构性),有的碎片图案重复(冗余性),还有的碎片颜色冲突(矛盾性)。知识融合就是把这些碎片拼成一幅完整、清晰、没有重复和错误的图画。
这个过程要解决三个核心问题:
- 异构性:不同知识源用不同的格式、结构和术语表达相同的信息
- 冗余性:多个知识源重复描述同一个事实
- 冲突性:不同知识源对同一事实给出不同的描述
三、知识融合如何工作
知识融合不是简单的"复制粘贴",而是一个系统化的工程流程。让我们看看它到底是如何一步步把碎片化的知识变成结构化智慧的。
3.1 模式对齐:统一"语言规则"
模式对齐是知识融合的第一步,就像给不同国家的人制定一套共同的交流规则。
不同知识图谱的本体结构可能完全不同。比如,A图谱用"出生地"表示人的出生地点,B图谱用"birthPlace",C图谱用"P19"(维基百科的属性编码)。模式对齐就是建立这些异构属性之间的映射关系,把它们统一成同一个概念。
这个过程通常需要:
- 人工定义映射规则:由领域专家制定属性对照表
- 自动对齐工具:使用本体对齐算法自动学习映射关系
- 标准化转换:将所有数据转换为统一的目标模式
3.2 实体对齐:找到"同一个人"
实体对齐是知识融合的核心难点,目标是识别不同知识源中指向同一现实对象的实体。
举个例子:DBpedia里的"Beijing"、Wikidata里的"Q956"、百度百科里的"北京",虽然写法完全不同,但都是指中国的首都。实体对齐就是要自动发现这种等价关系。
判断两个实体是否相同,可以从三个维度入手:
1. 名称相似度
最直观的方法是看名字像不像。比如"苹果"和"Apple"看起来不同,但加上"苹果公司"这个上下文,就能建立联系。常用的算法包括编辑距离(Levenshtein Distance)、Jaccard相似度等。
// 字符串相似度计算(编辑距离)
private double stringSimilarity(String s1, String s2) {
int distance = levenshteinDistance(s1, s2);
int maxLen = Math.max(s1.length(), s2.length());
return maxLen == 0 ? 1.0 : 1.0 - (double) distance / maxLen;
}
2. 属性相似度
单纯看名字容易出错,还要对比实体的其他属性。比如两个"张三",如果出生日期、毕业院校、职业都高度相似,那很可能是同一个人。
// 基于属性计算相似度
private double attributeSimilarity(Map<String, String> attr1,
Map<String, String> attr2) {
int matchCount = 0;
int totalCount = 0;
for (String key : attr1.keySet()) {
if (attr2.containsKey(key)) {
totalCount++;
if (attr1.get(key).equals(attr2.get(key))) {
matchCount++;
}
}
}
return totalCount > 0 ? (double) matchCount / totalCount : 0.0;
}
3. 结构相似度
这招更高级——看两个实体的"朋友圈"像不像。如果实体A和实体B都与同样的一组其他实体有关系,那它们很可能是同一个。
// 基于结构计算相似度(共同邻居比例)
private double structuralSimilarity(Entity e1, Entity e2) {
Set<String> neighbors1 = getNeighborEntities(e1);
Set<String> neighbors2 = getNeighborEntities(e2);
Set<String> intersection = new HashSet<>(neighbors1);
intersection.retainAll(neighbors2);
Set<String> union = new HashSet<>(neighbors1);
union.addAll(neighbors2);
return union.isEmpty() ? 0.0 : (double) intersection.size() / union.size();
}
4. 嵌入方法(前沿技术)
现在流行用深度学习把实体映射到向量空间,通过计算向量距离判断相似度。比如用TransE模型训练知识图谱嵌入,让相似实体在向量空间中离得更近。
3.3 冲突消解:当知识源"打架"时
当多个知识源对同一事实有不同描述时,怎么办?比如一个人的出生日期,A源说是1964年9月10日,B源说是1964年10月15日。冲突消解就是解决这种"打架"情况的策略。
常见的策略有:
1. 基于可信度权重
给不同数据源设置不同的可信度。比如官方网站 > 维基百科 > 权威媒体 > 用户生成内容。当冲突发生时,选择可信度最高的那个。
private double getSourceTrust(String source) {
// 根据来源设置可信度权重
Map<String, Double> trustScores = Map.of(
"官方网站", 0.95,
"维基百科", 0.90,
"权威媒体", 0.85,
"用户生成", 0.60
);
return trustScores.getOrDefault(source, 0.50);
}
2. 基于时效性
对于动态变化的信息(如股价、天气),优先选择最新的数据。
3. 投票机制
当大多数知识源给出相同答案时,认为这个答案更可靠。这就像集成学习中的投票法。
4. 人工审核
对于高价值或高风险的实体(如医疗、金融),可以设置人工审核机制,由专家最终裁决。

3.4 知识补全:拼出完整图景
每个知识源都只覆盖了部分信息维度,知识补全就是把各源的互补信息整合起来,形成更丰富的知识表示。
比如,一个电商商品知识图谱可能有产品的基本属性(品牌、型号、价格),另一个图谱可能有用户的详细评论和评分,融合后就能得到既有商品信息又有用户反馈的完整视图。
这个过程还包括:
- 关系融合:整合实体的所有关系,如某个商品关联的评论、分类、标签等
- 属性补全:用一个源的信息填补另一个源的空缺
- 去重处理:避免重复信息的冗余存储
3.5 工程优化:处理大规模数据
当知识源达到千万级实体时,两两比对的复杂度是平方级的,根本算不过来。实际项目中会采用多种优化策略:
1. Blocking技术
先把明显不可能匹配的实体对过滤掉,比如只比较名称首字母相同的实体,或者用LSH(局部敏感哈希)把相似实体映射到同一个桶里。
// Blocking技术:按名称首字母分组
private Map<String, List<Entity>> createBlocks(List<KnowledgeSource> sources) {
Map<String, List<Entity>> blocks = new HashMap<>();
for (KnowledgeSource source : sources) {
for (Entity entity : source.getEntities()) {
String blockKey = entity.getName().substring(0, 1).toUpperCase();
blocks.computeIfAbsent(blockKey, k -> new ArrayList<>()).add(entity);
}
}
return blocks;
}
2. 分布式计算
用Spark等框架并行处理,把实体对分配到不同节点计算相似度。
3. 增量更新
知识源每天都在变化,融合后的知识库不能是静态的。通过监听变更日志,只处理新增、修改、删除的实体,实现增量更新。
private void scheduleIncrementalUpdate() {
// 每日定时任务监听源变化
ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);
scheduler.scheduleDaily(() -> {
List<Change> changes = detectChanges();
for (Change change : changes) {
processChange(change);
}
}, 0, 1, TimeUnit.DAYS);
}
四、知识融合的优缺点
| 优势 | 劣势 |
|---|---|
| 信息完整性:整合多个源,获得更全面的知识 | 技术复杂度高:需要处理异构、冲突、冗余等多重问题 |
| 准确性提升:通过冲突消解和多源验证,提高数据可信度 | 计算成本高:实体对齐等操作在大规模数据上非常耗时 |
| 消除冗余:识别重复信息,节省存储空间 | 质量评估难:难以自动评估融合结果的准确性 |
| 增强应用效果:为搜索、推荐、问答等应用提供更优质的数据基础 | 需要持续维护:知识源不断变化,需建立增量更新机制 |
| 构建知识资产:将碎片化信息转化为结构化知识 | 人工成本高:高质量融合需要大量人工审核和标注 |
五、知识融合的实际应用与发展趋势
5.1 搜索引擎的知识图谱
这是知识融合最经典的应用场景。当用户在百度搜索"马云"时,右侧会出现知识卡片,整合了维基百科、百度百科、企业官网、新闻报道等多个源的信息。
挑战示例:
- 实体名称不一致:“Jack Ma”、“马云”、“马云(阿里巴巴创始人)”
- 属性字段不同:维基百科用"born",百度百科用"出生日期"
- 信息冲突:净资产在福布斯、胡润榜单中有不同数字
- 时效性:企业信息、财富排名等动态数据需要及时更新
解决方案:
- 建立别名字典,通过跨语言链接、重定向页面抽取映射关系
- 设置可信度权重:官方数据 > 权威媒体 > 用户生成内容
- 优先采用最新数据,特别是动态信息
- 对核心实体进行人工复核
5.2 智能问答系统
智能客服需要融合产品手册、历史工单、FAQ库、用户论坛等多个知识源。
场景示例:用户问"这个产品怎么退货"
- 官方退货政策(结构化规则)
- 历史退货案例(非结构化文本)
- 用户讨论(论坛帖子)
- 客服聊天记录(实时对话)
系统需要识别不同源中关于"退货"的知识碎片,整合成完整的答案链路。
5.3 医疗知识整合
医疗领域需要整合不同医院的电子病历、医学文献、临床指南等。
挑战:
- 疾病编码体系不同(ICD-10、自定义编码)
- 患者实体对齐(同名患者、隐私保护)
- 诊疗记录融合(时间序列数据)
- 知识权威性(错误信息的风险极高)
5.4 企业数据整合
大型企业的数据分散在CRM、ERP、用户画像、第三方平台等多个系统中。
示例:用户画像融合
- CRM系统:客户基本信息、交易记录
- 客服系统:交互历史、投诉记录
- 营销平台:社交媒体行为、广告点击
- 第三方数据:消费能力、兴趣标签
融合后能形成360度用户视图,支持精准营销和个性化服务。
5.5 技术发展趋势
1. 神经符号融合
结合神经网络的学习能力和符号推理的可解释性,用深度学习发现实体关系,用规则引擎保证逻辑一致性。
2. 多模态知识融合
不只融合文本,还整合图像、视频、音频中的知识。在电商场景中,产品图片、说明书、评价视频可以形成更立体的商品知识库。
3. 主动学习与质量监控
对系统不确定的对齐结果进行人工标注,把审核结果作为训练样本反哺模型,持续提升准确率。同时建立核心实体白名单,确保高价值数据的质量。
4. 实时知识融合
随着流式数据的增长,实时或近实时的知识融合成为刚需。需要设计支持增量计算和在线更新的融合架构。
5. 联邦学习与隐私保护
在医疗、金融等敏感领域,如何在保护隐私的前提下实现跨机构的知识融合,成为重要研究方向。
六、总结与思考
知识融合的本质,是在信息爆炸的时代,帮助我们从碎片化、异构化、冗余化的数据中提炼出结构化、一致化、完整化的知识。它不仅是技术问题,更是认知问题——如何让机器像人一样理解"北京"、"Beijing"和"首都"指的是同一个地方。
关键启示:
- 没有完美的融合,只有权衡的选择:在精度与效率、自动与人工、完整与简洁之间找到平衡点
- 质量比规模更重要:与其盲目追求覆盖所有长尾实体,不如先把核心实体的融合质量做到极致
- 融合是持续过程:知识在不断更新,融合系统需要建立增量更新和质量监控机制
- 人机协作是关键:自动算法处理大规模数据,人工审核保证核心数据质量,形成闭环优化
未来展望:
随着大模型时代的到来,知识融合正从结构化数据走向非结构化文本,从静态图谱走向动态演化。未来的知识融合系统,或许能像人类一样,在阅读、观察、交流中不断整合新知识,构建起真正智能的知识体系。在这个过程中,我们不仅在教机器如何融合知识,也在重新理解人类自身是如何组织和运用知识的。
思考:当你下次在搜索引擎看到右侧的知识卡片,或在智能客服得到准确答案时,不妨想想,背后可能正有知识融合技术在默默工作,把散落在数字世界各个角落的信息碎片,拼成一幅完整的知识图景。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)